python实例:自动爬取豆瓣读书短评,分析短评内容
思路:
1、打开书本“更多”短评,复制链接
2、脚本分析链接,通过获取短评数,计算出页码数
3、通过页码数,循环爬取当页短评
4、短评写入到txt文本
5、读取txt文本,处理文本,输出出现频率最高的词组(前X)----通过分析得到其他结果可自由发散
用到的库:
lxml 、re、jieba、time
整个脚本如下
# -*-coding:utf8-*-
# encoding:utf-8
#豆瓣每页20条评论 import requests
from lxml import etree
import re
import jieba
import time firstlink = "https://book.douban.com/subject/30193594/comments/" def stepc(firstlink):#获取评论条数
url=firstlink
response = requests.get(url=url)
wb_data = response.text
html = etree.HTML(wb_data)
a = html.xpath('//*[@id="total-comments"]/text()')
return(a)
a=stepc(firstlink)
c=re.sub(r'\D', "", a[0])#返回评论数筛选数字
d=int(int(c)/20+1)#通过评论数计算出页码数,评论数/20+1
print("当前评论有"+ str(d) +"页,请耐心等待") def stepa (firstlink,d):#读取评论内容
content=[]
for page in range(1,d):
url=firstlink+"hot?p"+str(page)
response = requests.get(url=url)
wb_data = response.text
html = etree.HTML(wb_data)
a = html.xpath('//*[@id="comments"]//div[2]/p/span/text()')
content.append(a)
return(content)
a=stepa (firstlink,d) def stepb(a):#写入txt
for b in a:
for c in b:
with open('C:/Users/Beckham/Desktop/python/2.txt', 'a',encoding='utf-8') as w:
w.write('\n'+c)
w.close()
stepb(a)
print("完成评论爬取,接下来分析关键字")
time.sleep(5) def stepd():#分析评论
txt=open("C:\\Users\\Beckham\\Desktop\\python\\2.txt","r", encoding='utf-8').read() #打开倚天屠龙记文本
exculdes={} #创建字典,主要用于存储非人物名次,供后面剔除使用
words=jieba.lcut(txt) #jieba库分析文本
counts={}
for word in words: #筛选分析后的词组
if len(word)==1: #因为词组中的汉字数大于1个即认为是一个词组,所以通过continue结束点读取的汉字书为1的内容
continue
else:
word=word
counts[word]=counts.get(word,0)+1 #对word出现的频率进行统计,当word不在words时,返回值是0,当rword在words中时,返回+1,以此进行累计计数
for word in exculdes:#如果循环读取到的词组与exculdes字典内的内容匹配,那么过滤掉(不显示)这个词组
del(counts[word])
items=list(counts.items())#字典到列表
items.sort(key=lambda x:x[1],reverse=True)#lambda是一个隐函数,是固定写法,以下命令的意思就是按照记录的第2列排序
for i in range(15):#显示前15位数据
word,count=items[i]
print("{0:<10}{1:>10}".format(word,count)) #0:<10左对齐,宽度10,”>10"右对齐
stepd()
print("分析完成")
执行结果

需要注意的是,如果频繁执行这个脚本,豆瓣会认为ip访问过多,弹出需要登录的页面
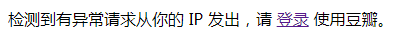
其他解析,在脚本内有注释
python实例:自动爬取豆瓣读书短评,分析短评内容的更多相关文章
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- python爬虫:利用正则表达式爬取豆瓣读书首页的book
1.问题描述: 爬取豆瓣读书首页的图书的名称.链接.作者.出版日期,并将爬取的数据存储到Excel表格Douban_I.xlsx中 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目 ...
- 如何手动写一个Python脚本自动爬取Bilibili小视频
如何手动写一个Python脚本自动爬取Bilibili小视频 国庆结束之余,某个不务正业的码农不好好干活,在B站瞎逛着,毕竟国庆嘛,还让不让人休息了诶-- 我身边的很多小伙伴们在朋友圈里面晒着出去游玩 ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫爬取豆瓣读书
一,准备工作. 工具:win10+Python3.6 爬取目标:爬取图中红色方框的内容. 原则:能在源码中看到的信息都能爬取出来. 信息表现方式:CSV转Excel. 二,具体步骤. 先给出具体代码吧 ...
- 【python数据挖掘】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- Python爬虫8-ajax爬取豆瓣影榜
GitHub代码练习地址:https://github.com/Neo-ML/PythonPractice/blob/master/SpiderPrac12_ajax.py 了解ajax 是一种异步请 ...
随机推荐
- MFC_对话框_访问控件_7种方法_A
访问对话框控件的七种方法 方法一. GetDlgItem()->GetWindowText(); GetDlgItem()->SetWindowText(); 方法二. GetDlgIte ...
- DEVOPS技术实践_16:使用Centos容器作为salve的报错offline的问题
上一篇创建了一个centos的容器,而且已经安装了openssh [root@node6 ~]# docker ps -a f2320c5d3c54 centos minutes ago Exited ...
- 原生JS数组方法实现(一)————push()、unshift()、pop()和shift()
push 向数组末尾添加一个或多个元素,并返回数组新的长度 ```javascript function push(){ for(let i=0;i<arguments.length;i++){ ...
- Python学习3月10号【python编程 从入门到实践】---》笔记
第11章 测试代码 11.1.2 可通过的测试 name_function.py ###创建一个简单的函数,他接受名和性并返回整洁的姓名 def get_formatted_name(first,la ...
- 浅谈Linux下/etc/passwd文件
浅谈Linux 下/etc/passwd文件 看过了很多渗透测试的文章,发现在很多文章中都会有/etc/passwd这个文件,那么,这个文件中到底有些什么内容呢?下面我们来详细的介绍一下. 在Linu ...
- 一文MyBatis-Plus快速入门
目录 一.依赖及配置 1.在idea中创建一个SpringBoot项目,在pom.xml中添需要的依赖 2.配置数据库连接 3.在启动类中添加注解 @MapperScan 扫描Mapper接口包 4. ...
- CF1277A. Happy Birthday, Polycarp! 题解 枚举/数位DP
题目链接:http://codeforces.com/contest/1277/problem/A 题目大意: 求区间 \([1,n]\) 范围内有多少只包含一个数字的数. 比如:\(1,77,777 ...
- 洛谷P1036 选数 题解 简单搜索/简单状态压缩枚举
题目链接:https://www.luogu.com.cn/problem/P1036 题目描述 已知 \(n\) 个整数 \(x_1,x_2,-,x_n\) ,以及 \(1\) 个整数 \(k(k& ...
- 学了java,我才发现台球还可以这样玩!
桌球小游戏的尝试 桌球是人们日常生活中都能接触到的一种娱乐活动,随着互联网技术的发展,手机上也有了很多桌球小游戏,让人们随时随地都能打两把. 今天分享一个用java编写的桌球小游戏 代码如下: ...
- Go合集,gRPC源码分析,算法合集
年初时,朋友圈见到的最多的就是新的一年新的FlAG,年末时朋友圈最多的也是xxxx就要过去了,你的FLAG实现了吗? 这个公众号2016就已经创建了,但截至今年之前从来没发表过文章,现在想想以前很忙, ...