JUC中的原子操作类及其原理
昨天简单的看了看Unsafe的使用,今天我们看看JUC中的原子类是怎么使用Unsafe的,以及分析一下其中的原理!
一.简单使用AtomicLong
还记的上一篇博客中我们使用了volatile关键字修饰了一个int类型的变量,然后两个线程,分别对这个变量进行10000次+1操作,最后结果不是20000,现在我们改成AtomicLong之后,你会发现结果始终都是20000了!有兴趣的可以试试,代码如下
package com.example.demo.study;
import java.util.concurrent.atomic.AtomicLong;
public class Study0127 {
//这是一个全局变量,注意,这里使用了一个原子类AtomicLong
public AtomicLong num = new AtomicLong();
//每次调用这个方法,都会对全局变量加一操作,执行10000次
public void sum() {
for (int i = 0; i < 10000; i++) {
//使用了原子类的incrementAndGet方法,其实就是把num++封装成原子操作
num.incrementAndGet();
System.out.println("当前num的值为num= "+ num);
}
}
public static void main(String[] args) throws InterruptedException {
Study0127 demo = new Study0127();
//下面就是新建两个线程,分别调用一次sum方法
new Thread(new Runnable() {
@Override
public void run() {
demo.sum();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
demo.sum();
}
}).start();
}
}
二.走近AtomicLong类
在java中JDK 1.5之后,就出现了一个包,简称JUC并发包,全称就是java.util .concurrent,其中我们应该听说过一个类ConcurrentHashMap,这个map挺有意思的,有兴趣可以看看源码!还有很多并发时候需要使用的类比如AtomicInteger,AtomicLong,AtomicBoolean等等,其实都差不多,这次我们就简单看看AtomicLong,其他的几个类也差不多
public class AtomicLong extends Number implements java.io.Serializable {
//获取Unsafe对象,上篇博客说了我们自己的类中不能使用这种方式的原因,但是官方的这个类为什么可以这样获取呢?因为本类AtomicLong
//就是在rt.jar包下面,本类就是用Bootstrap类加载的,所以就可以用这种方式
private static final Unsafe unsafe = Unsafe.getUnsafe();
//value这个字段的偏移量
private static final long valueOffset;
//判断jvm是否支持long类型的CAS操作
static final boolean VM_SUPPORTS_LONG_CAS = VMSupportsCS8();
private static native boolean VMSupportsCS8();
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicLong.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
//这里用了volatile使的多线程下可见性,一定要分清楚原子性和可见性啊
private volatile long value;
//两个构造器不多说
public AtomicLong() {
}
public AtomicLong(long initialValue) {
value = initialValue;
}
然后我们看看AtomicLong的+1操作,可以看到使用的还是unsafe这个类,只需要看看getAndAddLong方法就可以了

方法getAndAddLong里面就是进行了CAS操作,可以看成如果同时有多个线程都调用incrementAndGet方法进行+1,那么同一时间只有一个线程会去进行操作,而其他的会不断的使用CAS去尝试+1,每次尝试的时候都会去主内存中获取最新的值;
public final long getAndAddLong(Object o, long offset, long delta) {
long v;
do {
//这个方法就是重新获取主内存的值,因为使用了volatile修饰了那个变量,所以缓存就没用了
v = getLongVolatile(o, offset);
//这里就是一个dowhile无限循环,多个线程不断的调用compareAndSwapLong方法去设置值,其实就是CAS,没什么特别好说的吧,
//当某个线程CAS成功就跳出这个循环,否则就一直在循环不断的尝试,这也是CAS和线程阻塞的区别
} while (!compareAndSwapLong(o, offset, v, v + delta));
return v;
}
//这个CAS方法看不到,c实现的
public final native boolean compareAndSwapLong(Object o, long offset,long expected,long x);
有兴趣的可以看看AtomicLong的其他方法,很多都一样,CAS是核心
三.CAS的不足以及认识LongAdder
从上面的例子中,我们可以知道在多线程下使用AtomicLong类的时候,同一个时刻使用那个共享变量的只能是一个线程,其他的线程都是在无限循环,这种循环也是需要消耗性能的,如果线程比较多,很多的线程都在各自的无限循环中,或者叫做多个线程都在自旋;每个线程都在自旋无数次真的是比较坑,比较消耗性能,我们可以想办法自旋一定的次数,线程就结束运行了,有兴趣的可以了解一下自旋锁,其实就是这么一个原理,很容易,哈哈哈!
在JDK8之后,提供了一个更好的类取代AtomicLong,那就是LongAdder,上面说过同一时间只有一个线程在使用那个共享变量,其他的线程都在自旋,那么如果可以把这个共享变量拆开成多个部分,那么是不是可以多个线程同时可以去操作呢?然后操作完之后再综合起来,有点分治法的思想,分而治之,最后综合起来。
那么我们怎么把那个共享变量拆成多个部分呢?
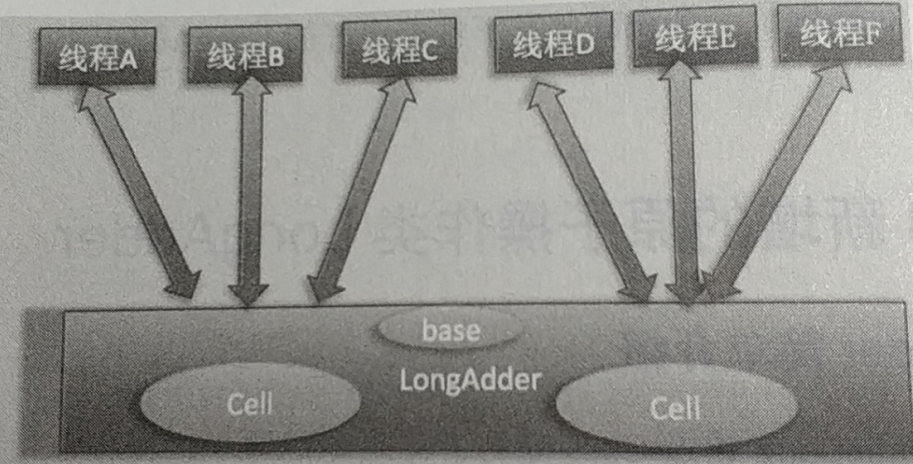
在LongAdder中是这样处理的,把那个变量拆成一个base(这个是long类型的,初始值为0)和一个Cell(这个里面封装了一个long类型的值,初始值为0),每个线程只会去竞争很多Cell就行了,最后把多个Cell中的值和base累加起来就是最终结果;而且一个线程如果没有竞争到Cell之后不会傻傻的自旋,直接想办法去竞争下一个Cell;
下图所示
四.简单使用LongAdder
用法其实和AtomicLong差不多,有兴趣的可以试试,最后的结果始终都是20000
package com.example.demo.study;
import java.util.concurrent.atomic.LongAdder;
public class Study0127 {
//这里使用LongAdder类
public LongAdder num = new LongAdder();
//每次调用这个方法,都会对全局变量加一操作,执行10000次
public void sum() {
for (int i = 0; i < 10000; i++) {
//LongAdder类的自增操作,相当于i++
num.increment();
System.out.println("当前num的值为num= "+ num);
}
}
public static void main(String[] args) throws InterruptedException {
Study0127 demo = new Study0127();
//下面就是新建两个线程,分别调用一次sum方法
new Thread(new Runnable() {
@Override
public void run() {
demo.sum();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
demo.sum();
}
}).start();
}
}
五.走进LongAdder
从上面可以看到base只能是一个,而Cell可能有多个,而且Cell太多了也是很占内存的,所以一开始的时候不会创建Cell,只有在需要时才创建,也叫做惰性加载。
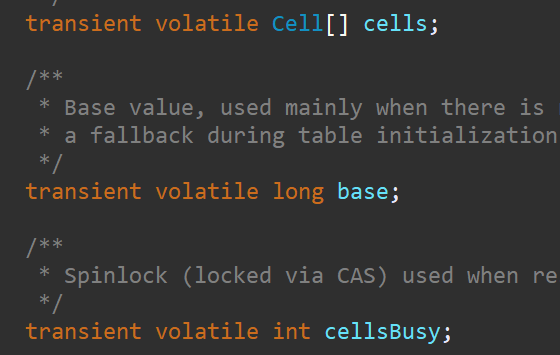
我们可以知道LongAdder是继承自Striped64这个类的

而Striped64类中有三个字段,cells数组用于存放多个Cell,一个是base不多说,还有一个cellsBusy用来实现自旋锁,状态只能是0或1(0表示Cell数组没有被初始化和扩容,也没有正在创建Cell元素,反之则为1),在创建Cell,初始化Cell数组或者扩容Cell数组的时候,就会用到这个字段,保证同一时刻只有一个线程可以进行其中之一的操作。
1.我们简单看看Cell的结构
从下面代码中可以很清楚的看到所谓的Cell就是对一个long类型变量的CAS操作
@sun.misc.Contended //这个注解的作用是为了避免伪共享,至于什么伪共享,后面有机会再说说
static final class Cell {
//每个Cell类中就是这个声明的变量后期要进行累加的
volatile long value;
//构造函数
Cell(long x) { value = x; }
//Unsafe对象
private static final sun.misc.Unsafe UNSAFE;
//value的偏移量
private static final long valueOffset;
//这个静态代码块中就是获取Unsafe对象和偏移量的
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
//CAS操作,没什么好说的
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
}
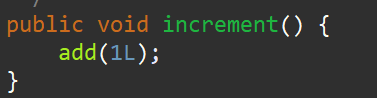
2.LongAdder类自增方法increment()
我们可以看到increment()方法其实就是调用了add方法,我们需要关注add方法干了一些什么;
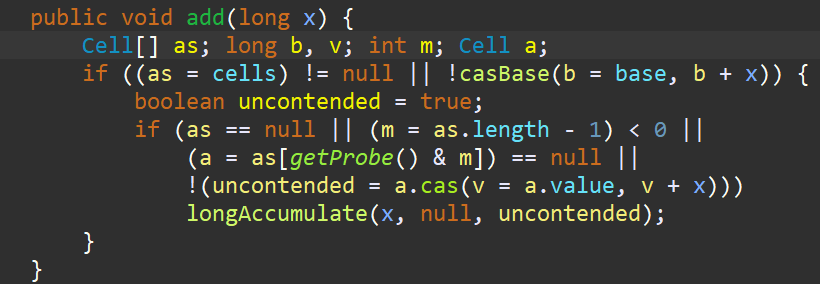

public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
//这里的cells是父类Striped64中的,不为空的话就保存到as中,然后调用casBase方法,就是CAS给base更新为base+x,也就是每次都新增x,
//在这里由于add(1L)传入的参数是1,也就是每次就是加一
//如果CAS成功之后就不说了,就完成操作了,如果CAS失败,则进入到里面去
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
//这个if判断条件贼长,我们把这几个条件分为1,2,3,4部分,前三部分都是用于决定线程应该访问Cell数组中哪一个Cell元素,最后一个部分用于更新Cell的值
//如果第1,2,3部分都不满足,也就是说Cell数组存在而且已经找到了确定的Cell元素,那就到第四部分,更新对应的Cell中的值(在Cell类中的cas方法已经看过了)
//如果第1,2,3部分满足其中一个,那也就是说Cell数组根本就不存在或者线程找不到对应的Cell,就执行longAccumulate方法
if (as == null || (m = as.length - 1) < 0 || (a = as[getProbe() & m]) == null || !(uncontended = a.cas(v = a.value, v + x)))
//后面仔细看看这个方法,这是对Cell数组的初始化和扩容,很有意思
longAccumulate(x, null, uncontended);
}
}
//一个简单的CAS操作
final boolean casBase(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);
}
对于上面的,有兴趣的可以看看是怎么找到指定的Cell的,在上面的a = as[getProbe() & m]中,其中m=数组的长度-1,其实这里也是一个取余的运算,而getProbe()这个方法是用于获取当前线程的threadLocalRandomProb(当前本地线程探测值,初始值为0),其实也就是一个随机数啊,然后对数组的长度取余得到的就是对应的数组的索引,首次调用这个方法是数组的第一个元素,如果数组的第一个元素为null,那么就说明没有找到对应的Cell;
对于取余运算,举个简单的例子吧,我也有点忘记了,比如随机数9要对4进行取余,我们可以9&(4-1)=9&3=1001&0011=1,利用位运算取余了解一下;
现在我们重点看看longAccumulate方法,代码比较长,单独提取出来看看
3.longAccumulate方法
//此方法是对Cell数组的初始化和扩容,注意有个形参LongBinaryOperator,这是JDK8新增的函数式编程的接口,函数签名为(T,T)->T,这里传进来的是null
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {
int h;
//初始化当前线程的threadLocalRandomProbd的值,也就是生成一个随机数
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
//这里表示初始化完毕了
if ((as = cells) != null && (n = as.length) > 0) {
//这里表示随机数和数组大小取余,得到的结果就是当前线程要匹配到的Cell元素的索引,如果索引对应在Cell数组中的元素为null,就新增一个Cell对象扔进去
if ((a = as[(n - 1) & h]) == null) {
//cellsBusy为0,表示当前Cell没有进行扩容、初始化操作或者正在创建Cell等操作,那么当前线程可以对这个Cell数组为所欲为
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
//看下面的Cell数组初始化,说的很清楚,主要是设置cellsBusy为1,然后将当前线程匹配到的Cell设置为新创建的Cell对象
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
//将cellsBusy重置为0,表示此时其他线程又可以对Cell数组为所欲为了
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
} else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash //Cell元素存在就执行CAS更新Cell中的值,这里fn是形参为null
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; //当Cell数组元素个数大于CPU的个数
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
//是否有冲突
else if (!collide)
collide = true;
//扩容Cell数组,和上面两个else if一起看
//如果当前Cell数组元素没有达到CPU个数而且有冲突就新型扩容,扩容的数量是原来的两倍Cell[] rs = new Cell[n << 1];,为什么要和CPU个数比较呢?
//因为当Cell数组元素和CPU个数相同的时候,效率是最高的,因为每一个线程都是一个CPU来执行,再来修改其中其中一个Cell中的值
//这里还是利用cellsBusy这个字段,在下面初始化Cell数组中的用法一样,就不多说了
else if (cellsBusy == 0 && casCellsBusy()) {
try {
//这里就是新建一个数组是原来的两倍,然后将原来数组的元素复制到新的数组,再改变原来的cells的引用指向新的数组
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
//使用完就重置为0
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
//这里的作用是当线程找了好久,发现所有Cell个数已经和CPU个数相同了,然后匹配到的Cell正在被其他线程使用
//于是为了找到一个空闲的Cell,于是要重新计算hash值
h = advanceProbe(h);
} //初始化Cell数组
//记得上面好像说过cellsBusy这个字段是能是0或者是1,当时0的时候,说明Cell数组没有初始化和扩容,也没有正在创建Cell元素,
//反之则为1,而casCellsBusy()方法就是用CAS将cellsBusy的值从0修改为1,表示当前线程正在初始化Cell数组,其他线程就不能进行扩容操作了
//如果一个线程在初始化这个Cell数组,其他线程在扩容的时候,看上面扩容,也会执行casCellsBusy()方法进行CAS操作,会失败,因为期望的值是1,而不是0
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
//这里首先新建一个容量为2的数组,然后用随机数h&1,也就是随机数对数组的容量取余的方式得到索引,然后初始化数组中每个Cell元素
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
//初始化完成之后要把这个字段重置为0,表示此时其他线程就又可以对这个Cell进行扩容了
cellsBusy = 0;
}
if (init)
break;
}
//将base更新为base+x,表示base会逐渐累加Cell数组中每一个Cell中的值
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
其实longAccumulate方法就是表示多线程的时候对Cell数组的初始化,添加Cell元素还有扩容操作,还有就是当一个线程匹配到了Cell元素,发现其他线程正在使用就会重新计算随机数,然后继续匹配其他的Cell元素去了,没什么特别难的吧!别看这个方法很长,就是做这几个操作
六.总结
这一篇核心就是CAS,我们简单的说了一下原子操作类AtomicLong的自增,但是当线程很多的情况下,使用CAS有很大的缺点,就是同一时间是会有一个线程在执行,其他所有线程都在自旋,自旋会消耗性能,于是可以使用JDK提供的一个LongAdder类代替,这个类的作用就是将AtomicLong中的值优化为了一个base和一个Cell数组,多线程去竞争的时候,假设线程个数个CPU个数相同,那么此时每一个线程都有单独的一个CPU去运行,然后单独的匹配到Cell数组中的某个元素,如果没有匹配到那么会对这个Cell数组进行初始化操作;如果匹配到的Cell数组中的元素正在使用,那么久判断是否可以新建一个Cell丢数组里面去,如果数组已经满了,而且数组数量小于CPU个数,那么久进行扩容;扩容结束后,还是匹配到的Cell数组中的位置正在使用,那么就是冲突,就会重新计算,通过一个新的随机数和数组的取余,得到一个新的索引,再去访问该对应的Cell数组的位置。。。。
仔细看看还是挺有意思的啊!
JUC中的原子操作类及其原理的更多相关文章
- java中的原子操作类AtomicInteger及其实现原理
/** * 一,AtomicInteger 是如何实现原子操作的呢? * * 我们先来看一下getAndIncrement的源代码: * public final int getAndIncremen ...
- Java中的原子操作类
转载: <ava并发编程的艺术>第7章 当程序更新一个变量时,如果多线程同时更新这个变量,可能得到期望之外的值,比如变量i=1,A线程更新i+1,B线程也更新i+1,经过两个线程操作之后可 ...
- 【Java并发】Java中的原子操作类
综述 JDK从1.5开始提供了java.util.concurrent.atomic包. 通过包中的原子操作类能够线程安全地更新一个变量. 包含4种类型的原子更新方式:基本类型.数组.引用.对象中字段 ...
- JUC学习笔记--JUC中并发工具类
JUC中并发工具类 CountDownLatch CountDownLatch是我目前使用比较多的类,CountDownLatch初始化时会给定一个计数,然后每次调用countDown() 计数减1, ...
- 基于接口回调详解JUC中Callable和FutureTask实现原理
Callable接口和FutureTask实现类,是JUC(Java Util Concurrent)包中很重要的两个技术实现,它们使获取多线程运行结果成为可能.它们底层的实现,就是基于接口回调技术. ...
- 24.Java中atomic包中的原子操作类总结
1. 原子操作类介绍 在并发编程中很容易出现并发安全的问题,有一个很简单的例子就是多线程更新变量i=1,比如多个线程执行i++操作,就有可能获取不到正确的值,而这个问题,最常用的方法是通过Synchr ...
- 第七章 Java中的13个原子操作类
当程序更新一个变量时,如果多线程同时更新这个变量,可能得到期望之外的值,比如变量i = 1:A线程更新i + 1,B线程也更新i + 1,经过两个线程操作之后可能i不等于3,而是等于2,.因为A和B线 ...
- 【多线程与并发】Java中的12个原子操作类
从JDK1.5开始,Java提供了java.util.concurrent.atomic包,该包中的原子操作类提供了一种使用简单.性能高效(使用CAS操作,无需加锁).线程安全地更新一个变量的方式. ...
- JUC原子操作类与乐观锁CAS
JUC原子操作类与乐观锁CAS 硬件中存在并发操作的原语,从而在硬件层面提升效率.在intel的CPU中,使用cmpxchg指令.在Java发展初期,java语言是不能够利用硬件提供的这些便利来提 ...
随机推荐
- Linux 内核块 urb
块 urb 被初始化非常象中断 urb. 做这个的函数是 usb_fill_bulk_urb, 它看来如此: void usb_fill_bulk_urb(struct urb *urb, struc ...
- vue-learning:25 - component - 概念-定义-注册-使用-命名
概念 Vue遵循Web Component规范,提供了自己的组件系统.组件是一段独立的代码,代表页面中某个功能块,拥有自己的数据.JS.样式,以及标签.组件的独立性是指形成自己独立的作用域,不会对其它 ...
- ZR8.2 DP
DP 1CF1101D 我们发现,最终答案一定和质因数有关 我们发现\(w_i <= 2*10^5\)级别的树,他的素因子的个数不会非常多(\(<=10\)) 然后我们就设 gcd是\(d ...
- Linux 内核探测和去连接的细节
在之前章节描述的 struct usb_driver 结构中, 驱动指定 2 个 USB 核心在合适的时候 调用的函数. 探测函数被调用, 当设备被安装时, USB 核心认为这个驱动应当处理; 探测 ...
- 【23.91%】【hdu 4694】Important Sisters("支NMLGB配树"后记)(支配树代码详解)
Time Limit: 7000/7000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others) Total Submission( ...
- linux c函数参考手册
一.字符测试 isalnum(测试字符是否为英文字母或数字) isalpha(测试字符是否为英文字母) isascii(测试字符是否为ascii码字符) isblank(测试字符是否为空格字符) is ...
- Linux下搭建实现HttpRunnerManager的异步执行、定时任务及任务监控
前言 在之前搭建的HttpRunnerManager接口测试平台,我们还有一些功能没有实现,比如异步执行.定时任务.任务监控等,要完成异步执行,需要搭建 RabbitMQ 等环境,今天我们就来实现这些 ...
- JavaScript | 值传递、引用传递的区别
值传递 JavaScript值传递的数据类型:字符串(String).数字(Number).布尔(Boolean).空(Null).未定义(Undefined), 这五种数据类型是按值访问的,因为可以 ...
- 宣布一件事,通过写博客,挣到了人生的第一个 10w
今天是 2019 年的最后一天,对于我来说,2019 年可以说是我高考进入大学以来,最重要的一年了.这一年,也是我收获最多的一年,其中最重要的收获应该就是『找工作』和『运营公众号』以及『挣到了人生的第 ...
- jsp中获取页面的相对路径
1.在jsp页面的上方加上这段java代码 <%// request.getContextPath() 返回当前页面所在的应用的名字:// request.getSc ...