防止或减少过拟合的方式(二)——Dropout
当进行模型训练的时候,往往可能错过模型的最佳临界点,即当达到最大精度的时候再进行训练,测试集的精度会下降,这时候就会出现过拟合,如果能在其临界点处提前终止训练,就能得到表达力较强的模型,从而也避免了过拟合,这种方法就叫early stopping,但是这种方法多依靠人的经验和感觉去判断,因为无法准确的预测后面还有没有最佳临界值,所以这种方法更适合老道的深度学习人员,而对于初学者或者说直觉没有那么准的人,则有一种更简便的方法——dropout,它的大致意思是在训练时,将神经网络某一层的单元(不包括输出层的单元)数据随机丢失一部分。
具体而言,使用dropout集成方法需要训练的是从原始网络去掉一些不属于输出层的单元后形成的子网络,如图:
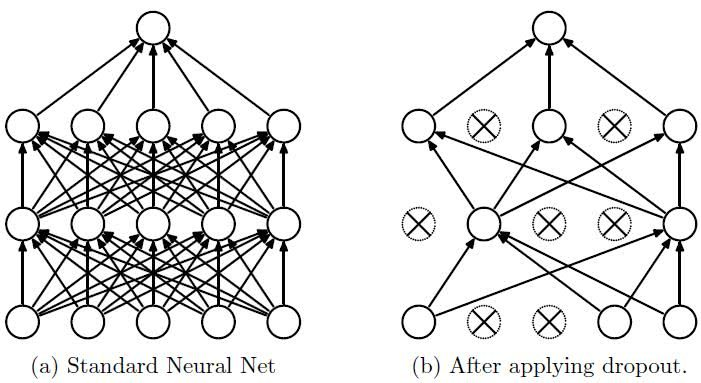
可以将每次的单元丢弃都理解为是对特征的一种再采样,这种做法实际上是等于创造出了很多新的随机样本,以增大样本量,减少特征量的方法来防止过拟合。
在使用复杂的卷积神经网络训练大型的图像识别神经网络模型时使用dropout方法会得到显著的效果,我们可以把dropout的过程想象成随机将一张图片(或某个网络层)中一定比例的数据删除调(即这部分数据都变为0,在图像中0代表黑色),这样就模拟了将图像中某些位置涂成黑色,此时人眼很有可能辨认出这张图片的内容,当然,模型也可以用其进行训练。
tensorflow中提供了很简单的使用方法:
network = keras.Sequential([
keras.layers.Dense(256,activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(128,activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(64,activation='relu'),
keras.layers.Dense(32,activation='relu'),
keras.layers.Dense(10)
])
在使用dropout之后,在前向传播时必须声明training参数,因为模型的train和test的策略是不一样的,所以需要人为的做区分,区分方法就是给定training参数的值(True或False),以此来指定当前状态。
代码如下:
for step,(x,y) in enumerate(db_train):
# train
with tf.GradientTape() as tape:
x = tf.reshape(x,(-1,28*28))
out = network(x,training=True)
# …… # test
out = network(x,training=False)
防止或减少过拟合的方式(二)——Dropout的更多相关文章
- Spring面向切面编程(AOP)方式二
使用注解进行实现:减少xml文件的配置. 1 建立切面类 不需要实现任何特定接口,按照需要自己定义通知. package org.guangsoft.utils; import java.util.D ...
- 自学Python4.8-生成器(方式二:生成器表达式)
自学Python之路-Python基础+模块+面向对象自学Python之路-Python网络编程自学Python之路-Python并发编程+数据库+前端自学Python之路-django 自学Pyth ...
- Java实现购物车功能:方式一:存放在session中.方式二:存储在数据库中
//将购物车产品加入到cookie中,方式同浏览记录.Java实现购物车,方式一(简易版):存储在session中.这种方式实现还不严谨,大家看的时候看思路即可.(1). JSP页面中,选择某一款产品 ...
- Cookie实现商品浏览记录--方式二:JS实现
使用Cookie实现商品浏览记录:方式二:JS方法实现cookie的获取以及写入.当某一个产品被点击时,触发JS方法.利用JS方法判断一下,此产品是否在浏览记录中.如果不存在,则将产品ID加入到coo ...
- spring boot整合mybatis方式二
方式二: pom文件导入maven依赖: <dependency> <groupId>org.springframework.boot</groupId> < ...
- H5 66-清除浮动方式二
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 教师信息管理系统(方式一:数据库为oracle数据库;方式二:存储在文件中)
方式一: 运行截图 数据库的sql语句: /*Navicat Oracle Data TransferOracle Client Version : 12.1.0.2.0 Source Server ...
- Android MVP模式简单易懂的介绍方式 (二)
Android MVP模式简单易懂的介绍方式 (一) Android MVP模式简单易懂的介绍方式 (二) Android MVP模式简单易懂的介绍方式 (三) 上一篇文章我们介绍完了Model的创建 ...
- md5加密+盐方式二
这类md5+盐加密是属于自定义盐值的简单方法! 1.导入架包 2.调用方法 DigestUtils.md5Hex(password);//加密方法 举例 方式一: password=DigestUti ...
随机推荐
- 关于2D渲染的一些小想法
原文地址 概述 . 这个项目最初的目的是为了尝试解析现有的UI编辑器(MyGUI)导出的UI布局信息,通过ImGUI还原UI渲染.但是在开发过程中,我发现可以借此实现一个编辑器,一个我不断的寻找,但始 ...
- Java 设计模式之抽象工厂模式
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂.该超级工厂又称为其他工厂的工厂.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式. 在抽 ...
- Django部署--uwsgi配置--nginx服务器配置
uwsgi.ini文件 [uwsgi] #使用nginx连接时使用,Django程序所在服务器地址 socket=127.0.0.1:8000 #直接做web服务器使用,Django程序所在服务器地址 ...
- 学习Qt的资源-网站、论坛、博客等
来自<零基础学Qt 4编程>一书的附录 附录C Qt资源 C.1 Qt 官方资源 全球各大公司以及独立开发人员每天都在加入 Qt 的开发社区.他们已经认识到了Qt 的架构本身便可加快应用程 ...
- 视觉slam十四讲ch5 joinMap.cpp 代码注释(笔记版)
#include <iostream> #include <fstream> using namespace std; #include <opencv2/core/co ...
- python 2 计算字符串 余弦相似度
def get_ord_list(str): return [ord(i) for i in str] def calcu_approx(str1,str2): def dot(A,B): retur ...
- POJ_2185_二维KMP
http://poj.org/problem?id=2185 求最小覆盖矩阵,把KMP扩展到二维,行一次,列一次,取最小覆盖线段相乘即可. #include<iostream> #incl ...
- Window下,Jenkins忘记密码解决方法
没有修改过密码的情况下找回初始密码(或者第一次部署的时候) 进入目录 D:\jenkins\secrets ,找到文件 initialAdminPassword 在jenkins页面,输入登录名adm ...
- 【C++】应用程序无法正常启动0xc000007b
在Windows平台编程时,或运行应用程序时,偶尔会遇到“应用程序无法正常启动0xc000007b”或“缺少***.dll”的问题, 首先需要考虑的就是程序相关联的dll有没有放到系统环境中,dll通 ...
- tar命令详解及使用实例
tar命令 [root@linux ~]# tar [-cxtzjvfpPN] 文件与目录 …. 参数: -c :创建压缩文件 -x :解开压缩文件 -t :查看tar包里面的文件! 上面3个参数只能 ...