survival analysis 生存分析与R 语言示例 入门篇
原创博客,未经允许,不得转载。
生存分析,survival analysis,顾名思义是用来研究个体的存活概率与时间的关系。例如研究病人感染了病毒后,多长时间会死亡;工作的机器多长时间会发生崩溃等。 这里“个体的存活”可以推广抽象成某些关注的事件。 所以SA就成了研究某一事件与它的发生时间的联系的方法。这个方法广泛的用在医学、生物学等学科上,近年来也越来越多人用在互联网数据挖掘中,例如用survival analysis去预测信息在社交网络的传播程度,或者去预测用户流失的概率。 R里面有很成熟的SA工具。 本文介绍生存分析的基本概念和一些公式,以及R语言应用示例。
相比于logistics regression, survival analysis有个很大的优点是可以处理缺失数据(censored data, 只有个体的部分数据)。比如说医生想研究病人在服药后的健康状况,跟踪期为2015一整年。有些人接近2015年底才开始服药,那么他就只有很短的数据。如果在一年内知道病人死亡了,那么这个病人的数据是完全的;而健康的病人的数据到2015年末就是缺失的了(right censored),因为假如病人在一年后死亡了,我们并不知道这个事。或者说病人在一年内突然失联了,那么他的数据也是缺失。

用T表示事件的发生时刻
存活函数 :
S(t)= Pr(T>t) = 1-F(t)
表示个体在t时刻还活着的概率,即事件在t时刻还未发生的概率。S(0)=1, S(无穷大) = 0, 并且S(t)是单调非增函数。实际数据中,t通常取离散值,例如天,周等。
风险函数:

(2) 模型
2.1 如果每个个体都遵循相同的规律,即个体间没有差异,那么问题比较简单。Kaplan-Meier是一种无参数的模型,它在每个兴趣时间点做一次存活统计,估计存活函数. 令 表示第i时刻还存活的个体数, 表示第i时刻发生事件的个体数量,那么:
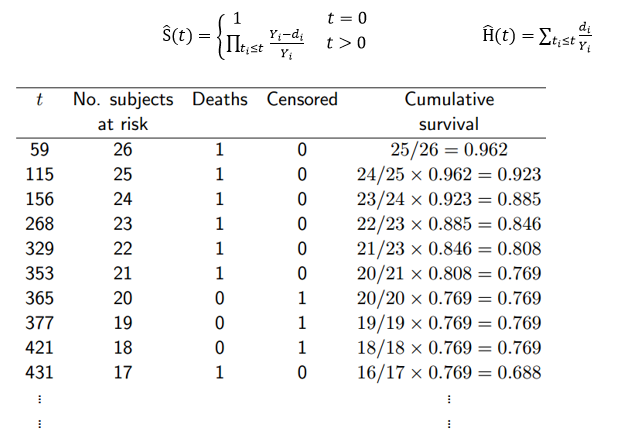
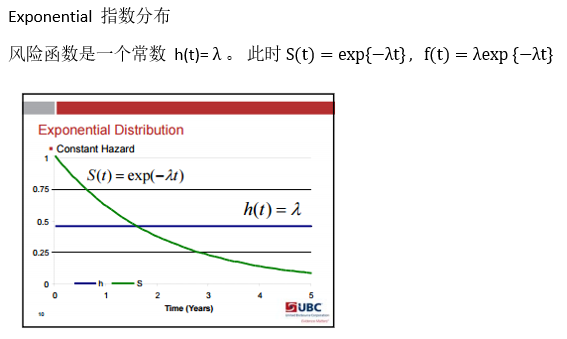
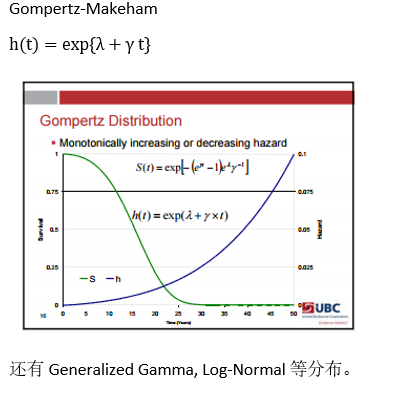
这种方法学出来的S(t)是不平滑的。 带参数的模型会假设模型服从某个分布,使学得的函数平滑。常用的有:

install.packages("OIsurv")
library(OIsurv)
data(tongue)
attach(tongue)
my.surv<-Surv(time[type==1], delta[type==1])
my.fit<-survfit(my.surv~1) #Kaplan-Meier
summary(my.fit)
plot(my.fit)
#比较type=1和type=2这两个组的存活函数
my.fit1<-survfit(Surv(time,delta)~type)
plot(my.fit1)
#计算风险函数
H.hat<--log(my.fit$surv)
H.hat<-c(H.hat, tail(H.hat,1))
print(my.fit, print.rmean=TRUE)
#检验两个存活函数是否有区别
survdiff(Surv(time, delta) ~ type) # output omitted
detach(tongue)
2.2 Cox proportional hazards model

# cox PH model
data(burn)
attach(burn)
my.surv <- Surv(T1, D1)
coxph.fit <- coxph(my.surv ~ Z1 + as.factor(Z11), method="breslow")
detach(burn)
预测新数据的值感觉比较不正规,因为survival analysis本身不是针对预测的:
risk = function(model, newdata, time) {
as.numeric(1-summary(survfit(model, newdata = newdata, se.fit = F, conf.int = F), times = time)$surv)
}2.3 extended Cox model
如果Cox PH Model中的变量会随时间变化,那么就成了extended Cox model,此时HR不再是一个常量。很简单的例子,如果病人的居住地也是一个变量,病人有可能会搬家,例如在北京吸霾了5年,再跑去厦门生活,那么他旧病复发的概率肯定会降低。所以住所这个变量是和时间相关的。一种简单的做法是,按照变量改变的时刻,把时间切割成区间,使得每个区间内的变量没有变化。然后再套用Cox PH模型。
# extended cox
data(relapse)
N <- dim(relapse)[1]
t1 <- rep(0, N+sum(!is.na(relapse$int))) # initialize start time at 0
t2 <- rep(-1, length(t1)) # build vector for end times
d <- rep(-1, length(t1)) # whether event was censored
g <- rep(-1, length(t1)) # gender covariate
i <- rep(FALSE, length(t1)) # initialize intervention at FALSE j <- 1
for(ii in 1:dim(relapse)[1]){
if(is.na(relapse$int[ii])){ # no intervention, copy survival record
t2[j] <- relapse$event[ii]
d[j] <- relapse$delta[ii]
g[j] <- relapse$gender[ii]
j <- j+1
} else { # intervention, split records
g[j+0:1] <- relapse$gender[ii] # gender is same for each time
d[j] <- 0 # no relapse observed pre-intervention
d[j+1] <- relapse$delta[ii] # relapse occur post-intervention?
i[j+1] <- TRUE # intervention covariate, post-intervention
t2[j] <- relapse$int[ii]-1 # end of pre-intervention
t1[j+1] <- relapse$int[ii]-1 # start of post-intervention
t2[j+1] <- relapse$event[ii] # end of post-intervention
j <- j+2 # two records added
}
} mySurv <- Surv(t1, t2, d) # pg 3 discusses left-trunc. right-cens. data
myCPH <- coxph(mySurv ~ g + i)
参考文献:
http://www.stat.columbia.edu/~madigan/W2025/notes/survival.pdf
http://www.openintro.org/stat/down/Survival-Analysis-in-R.pdf
http://www.ispor.org/congresses/Spain1111/presentations/W29_Ishak-Jack.pdf
http://data.princeton.edu/pop509/ParametricSurvival.pdf
survival analysis 生存分析与R 语言示例 入门篇的更多相关文章
- 生存分析与R
生存分析与R 2018年05月19日 19:55:06 走在码农路上的医学狗 阅读数:4399更多 个人分类: R语言 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blo ...
- R语言重要数据集分析研究——R语言数据集的字段含义
R语言数据集的字段含义 作者:马文敏 选择一种数据结构来储存数据 将数据输入或导入到这个数据结构中 数据集的概念 数据集通常是有数据结构的一个矩形数组,行表示规则,列表示变量. 不同的行业对数据集的行 ...
- 线性函数拟合R语言示例
线性函数拟合(y=a+bx) 1. R运行实例 R语言运行代码如下:绿色为要提供的数据,黄色标识信息为需要保存的. x<-c(0.10,0.11, 0.12, 0.13, 0.14, ...
- R语言学习 第九篇:plyr包
在数据分析中,整理数据的本质可以归纳为:对数据进行分割(Split),然后应用(Apply)某些处理函数,最后将结果重新组合(Combine)成所需的格式返回,简单描述为:Split - Apply ...
- R语言简单入门
一.运行R语言可以做哪些事? 1.探索性数据分析(将数据绘制图表) 2.统计推断(根据数据进行预测) 3.回归分析(对数据进行拟合分析) 4.机器学习(对数据集进行训练和预测) 5.数据产品开发 二. ...
- R语言学习 第一篇:变量和向量
R是向量化的语言,最突出的特点是对向量的运算不需要显式编写循环语句,它会自动地应用于向量的每一个元素.对象是R中存储数据的数据结构,存储在内存中,通过名称或符号访问.对象的名称由大小写字母.数字0-9 ...
- 【计理05组01号】R 语言基础入门
R 语言基本数据结构 首先让我们先进入 R 环境下: sudo R 赋值 R 中可以用 = 或者 <- 来进行赋值 ,<- 的快捷键是 alt + - . > a <- c(2 ...
- R语言快速入门上手
导言: 较早之前就听说R是一门便捷的数据分析工具,但由于课程设计的原因,一直没有空出足够时间来进行学习.最近自从决定本科毕业出来找工作之后,渐渐开始接触大数据行业的技术,现在觉得是时候把R拿下 ...
- R语言快速入门
R语言是针对统计分析和数据科学的功能全面的开源语言,R的官方网址:http://www.r-project.org/ 在Windows环境下安装R是很方便的 R语言的两种运行模式:交互模式和批处理模 ...
随机推荐
- 编写一个Java项目,定义包,在包下定义包含main方法的类,在main方法中声明8种基本数据类型的变量并赋值,练习数据类型转换。
- 最小安装centos 7 无GUI静默安装 oracle 12c,打造轻量linux化服务器
CentOS 7 下载地址:http://mirrors.opencas.cn/centos/7/isos/x86_64/CentOS-7-x86_64-Everything-1511.iso 一.安 ...
- QQ JS省市区三级联动
如下图: 首先写一个静态的页面: <!DOCTYPE html> <html> <head> <title>QQ JS省市区三级联动</title ...
- 烂泥:centos6.4服务器添加新硬盘
本文由秀依林枫提供友情赞助,首发于烂泥行天下. 公司FTP服务器的空间又不够了,唉,没有办法只能新加硬盘了.因为以前没有给Linux服务器添加过硬盘,所以只能先在虚拟机中进行模拟. 新加硬盘的操作步骤 ...
- centos7 + php7 lamp全套最新版本配置,还有mongodb和redis
我是个懒人,能yum就yum啦 所有软件的版本一直会升级,注意自己当时的版本是不是已经更新了. 首先装centos7 如果你忘了设置swap分区,下面的文章可以教你怎么补一个上去: http://ww ...
- Linux命令的类型
1.内建命令: 由shell程序自带的命令,最常见的有cd.pwd等. 使用type命令即可查看命令属于哪种,比如: #type cd cd is a shell builtin ————>看到 ...
- linux硬链接与软链接
在linux操作系统中的文件数据除了实际的内容外,还会含有文件权限(rwx)与文件属性(owner,group,other等),文件系统通常会将这两部分的数据存放在不同的区块,文件权限与文件属性放置在 ...
- 深度优先搜索 codevs 1064 虫食算
codevs 1064 虫食算 2004年NOIP全国联赛提高组 时间限制: 2 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题目描述 Description 所 ...
- (转)priority_queue的用法
priority_queue调用 STL里面的 make_heap(), pop_heap(), push_heap() 算法实现,也算是堆的另外一种形式.先写一个用 STL 里面堆算法实现的与真正的 ...
- uGUI VS NGUI
前言 这篇日志的比较是根据自己掌握知识所写的,请各路大神多多指教. 引擎版本: Unity 4.6 beta 两者区别 1.uGUI的Canvas 有世界坐标和屏幕坐标 2.uGUI的Button属性 ...