【图文详解】scrapy安装与真的快速上手——爬取豆瓣9分榜单
写在开头
现在scrapy的安装教程都明显过时了,随便一搜都是要你安装一大堆的依赖,什么装python(如果别人连python都没装,为什么要学scrapy….)wisted, zope interface,pywin32………现在scrapy的安装真的很简单的好不好!
代码我放github上了,可以参考:
https://github.com/hk029/doubanbook
为什么要用scrapy
我之前讲过了requests,也用它做了点东西,(【图文详解】python爬虫实战——5分钟做个图片自动下载器)感觉它就挺好用的呀,那为什么我还要用scrapy呢?
因为:它!更!好!用!就这么简单,你只要知道这个就行了。
我相信所有能找到这篇文章的人多多少少了解了scrapy,我再copy一下它的特点来没太多意义,因为我也不会在这篇文章内深入提。就像你知道系统的sort函数肯定比你自己编的快排好用就行了,如果需要知道为什么它更好,你可以更深入的去看代码,但这里,你只要知道这个爬虫框架别人就专门做这件事的,肯定好用,你只要会用就行。
我希望每个来这里的人,或者每个在找资料的朋友,都能明确自己的目的,我也尽量将文章的标题取的更加的明确。如果这是一篇标题为《快速上手》的文章,那你可能就不要太抱希望于能在这篇文章里找到有关scrapy架构和实现原理类的内容。如果是那样,我可能会取标题为《深入理解scrapy》
好了废话说了那么多,我们就上手把?
安装scrapy
一条命令解决所有问题
pip install scrapy
好吧,我承认如果用的是windows一条命令可能确实不够,因为还要装pywin32
https://sourceforge.net/projects/pywin32/files/pywin32/
现在sourceforge变的很慢,如果你们不能打开,我在网盘上也放一个64位的,最新220版本的:
链接: http://pan.baidu.com/s/1geUY6Dd 密码: z2ep
然后就结束了!!结束了!!好不好!就这么简单!
豆瓣读书9分书榜单爬取
我们考虑下做一个什么爬虫呢?简单点,我们做一个豆瓣读书9分书:
https://www.douban.com/doulist/1264675/
建立第一个scrapy工程
把scrapy命令的目录加入环境变量,然后输入一条命令
scrapy startproject doubanbook
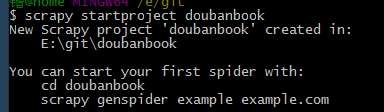
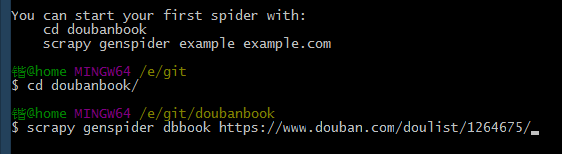
然后你的目录下就有一个文件夹名为doubanbook目录,按照提示,我们cd进目录,然后按提示输入,这里我们爬虫取名为dbbook,网址就是上面的网址
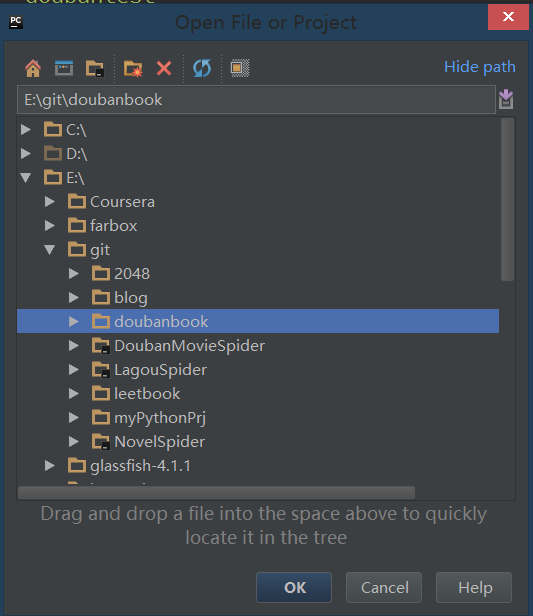
打开pycharm,新建打开这个文件夹
关于pytharm的安装配置:Pycharm的配置和使用
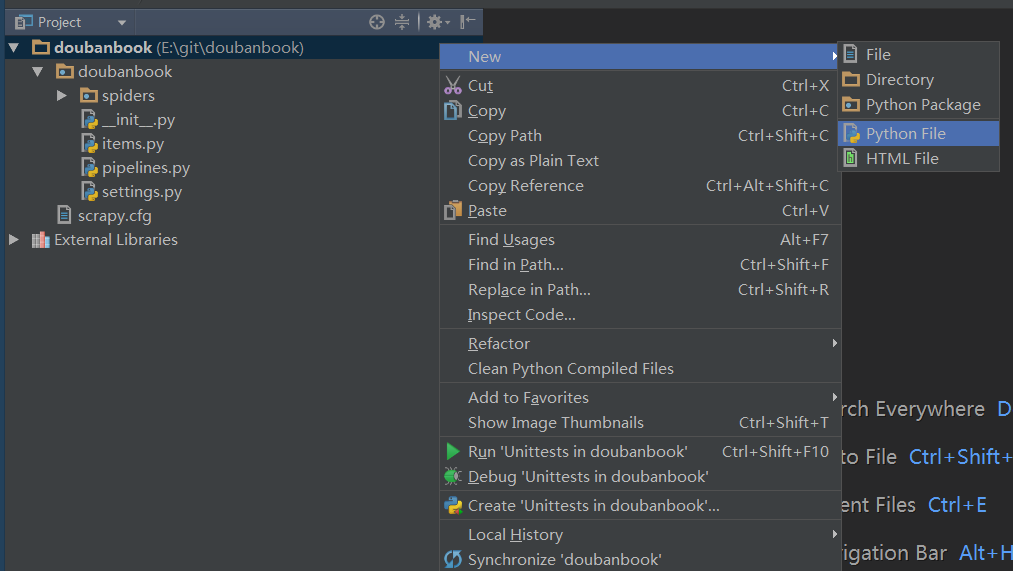
打开后,我们在最顶层的目录上新建一个python文件,取名为main,这是运行的主程序(其实就一行代码,运行爬虫)
输入
from scrapy import cmdline
cmdline.execute("scrapy crawl dbbook".split())
然后我们进入spider-dbbook,然后把start_urls里面重复的部分删除(如果你一开始在命令行输入网址的时候,没输入http://www.那就不用改动)然后把allowed_domains注掉
并且,把parse里面改成
print response.body
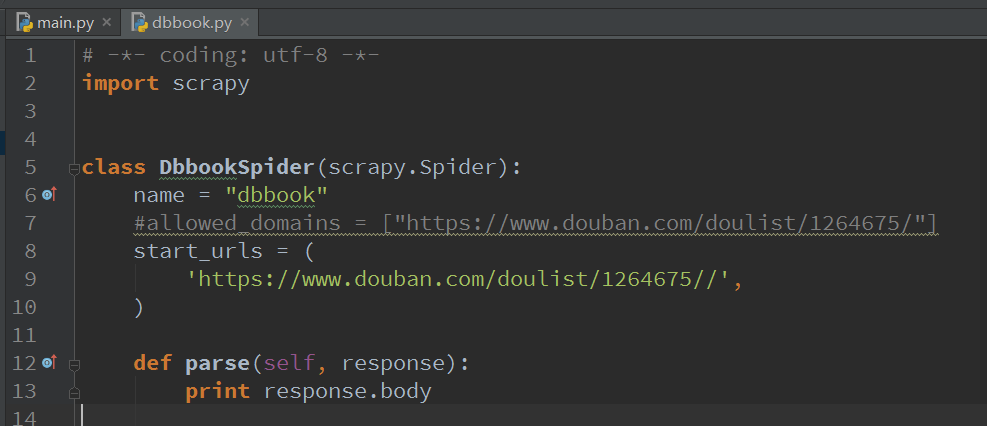
好了,到此第一个爬虫的框架就搭完了,我们运行一下代码。(注意这里选择main.py)
运行一下,发现没打印东西,看看,原来是403

说明爬虫被屏蔽了,这里要加一个请求头部,模拟浏览器登录
在settings.py里加入如下内容就可以模拟浏览器了
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
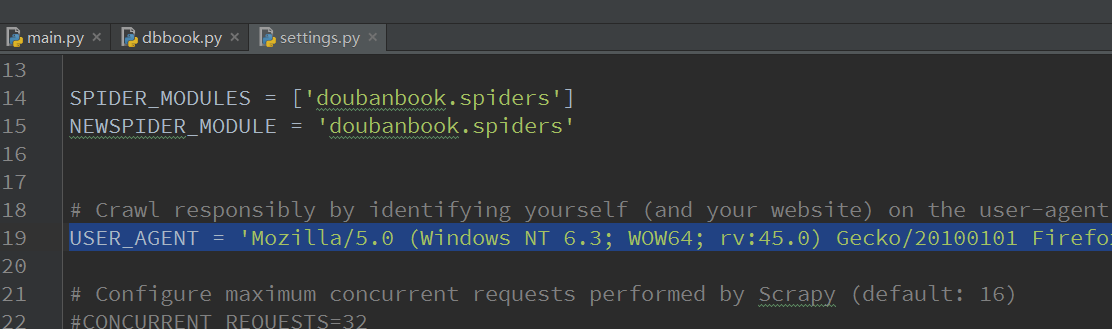
我们再运行,发现网页内容已经被爬取下来了
好了,我们的scrapy教程结束!
如果真这样结束,我知道你会打我。。
编写xpath提取标题名和作者名
这里我们就要得分,标题名和作者名
观察网页源代码,用f12,我们可以快速找到,这里不细讲怎么找信息的过程了,具体过程,参考上一个教程【图文详解】python爬虫实战——5分钟做个图片自动下载器
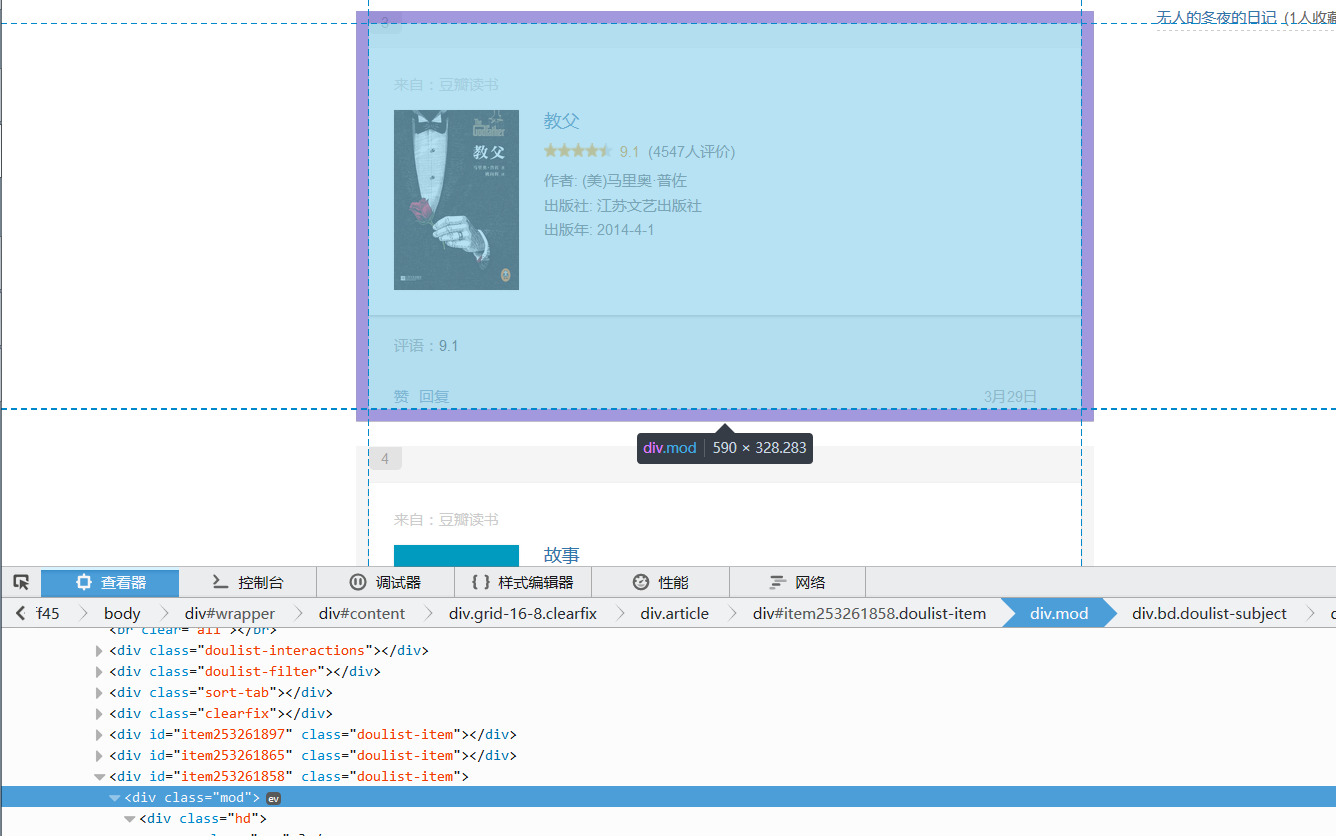
根据先大后小的原则,我们先用bd doulist-subject,把每个书找到,然后,循环对里面的信息进行提取

提取书大框架:
'//div[@class="bd doulist-subject"]'
提取题目:
'div[@class="title"]/a/text()'
提取得分:
'div[@class="rating"]/span[@class="rating_nums"]/text()'
提取作者:(这里用正则方便点)
'<div class="abstract">(.*?)<br'
编写代码
经过之前的学习,应该很容易写出下面的代码吧:作者那里用正则更方便提取
selector = scrapy.Selector(response)
books = selector.xpath('//div[@class="bd doulist-subject"]')
for each in books:
title = each.xpath('div[@class="title"]/a/text()').extract()[0]
rate = each.xpath('div[@class="rating"]/span[@class="rating_nums"]/text()').extract()[0]
author = re.search('<div class="abstract">(.*?)<br',each.extract(),re.S).group(1)
print '标题:' + title
print '评分:' + rate
print author
print ''关键这个代码在哪里编写呢?答案就是还记得大明湖……不对,是还记得刚才输出response的位置吗?就是那里,那里就是我们要对数据处理的地方。我们写好代码,这里注意:
- 不是用etree来提取了,改为scrapy.Selector了,这点改动相信难不倒聪明的你
- xpath如果要提取内容,需要在后面加上.extract(),略为不适应,但是习惯还好。
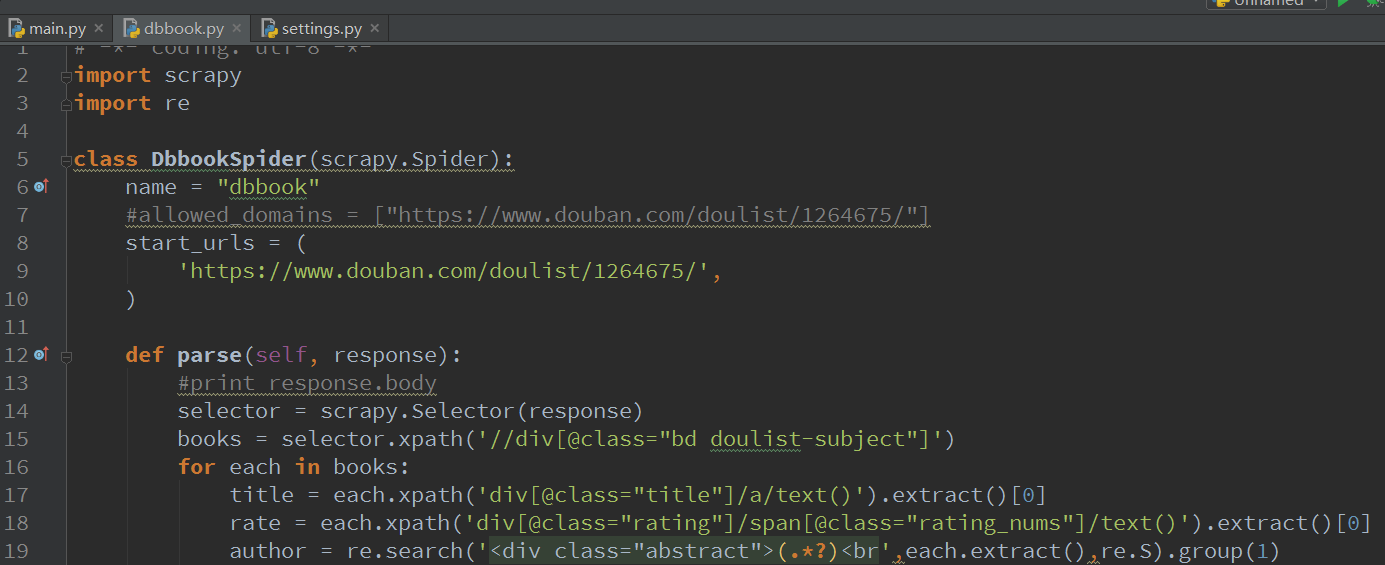
我们看看结果,不好看,对于注重美观的我们来说,简直不能忍
加入两条代码:
title = title.replace(' ','').replace('\n','')
author = author.replace(' ','').replace('\n','')再看看结果,这才是我们想要的嘛
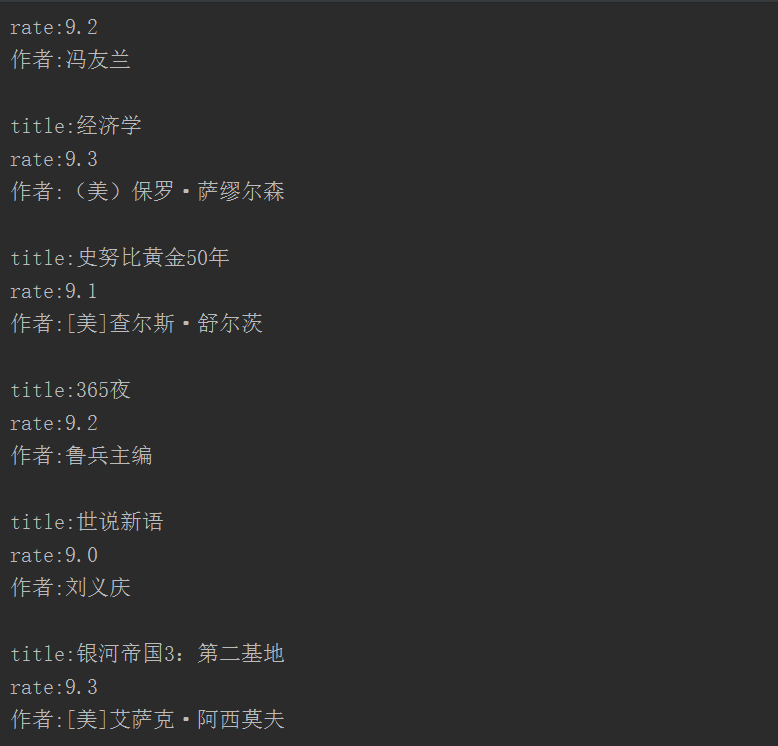
好了,剩下的事情就是如何把结果写入文件或数据库了,这里我采用写入文件,因为如果是写入数据库,我又得花时间讲数据库的一些基本知识和操作,还是放在以后再说吧。
items.py
好了,我们终于要讲里面别的.py文件了,关于这个items.py,你只要考虑它就是一个存储数据的容器,可以考虑成一个结构体,你所有需要提取的信息都在这里面存着。
这里我们需要存储3个变量,title,rate,author,所以我在里面加入三个变量,就这么简单:
title = scrapy.Field()
rate = scrapy.Field()
author = scrapy.Field()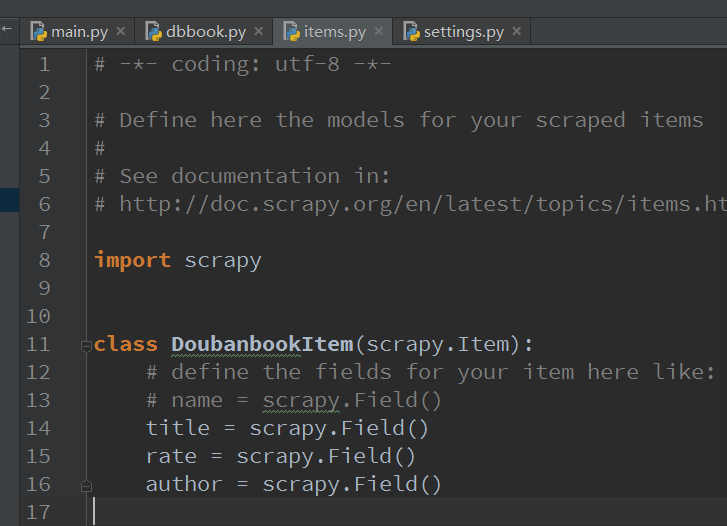
pipelines.py
一般来说,如果你要操作数据库什么的,需要在这里处理items,这里有个process_item的函数,你可以把items写入数据库,但是今天我们用不到数据库,scrapy自带了一个很好的功能就是Feed exports,它支持多种格式的自动输出。所以我们直接用这个就好了,pipelines维持不变
settings.py
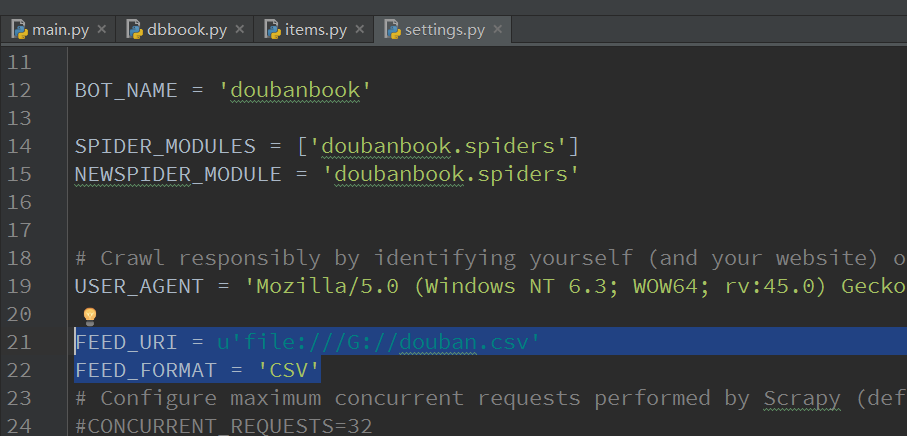
Feed 输出需要2个环境变量:
FEED_FORMAT :指示输出格式,csv/xml/json/
FEED_URI : 指示输出位置,可以是本地,也可以是FTP服务器
FEED_URI = u'file:///G://douban.csv'
FEED_FORMAT = 'CSV'FEED_URI改成自己的就行了
dbbook.py修改
其实也就加了3条命令,是把数据写入item
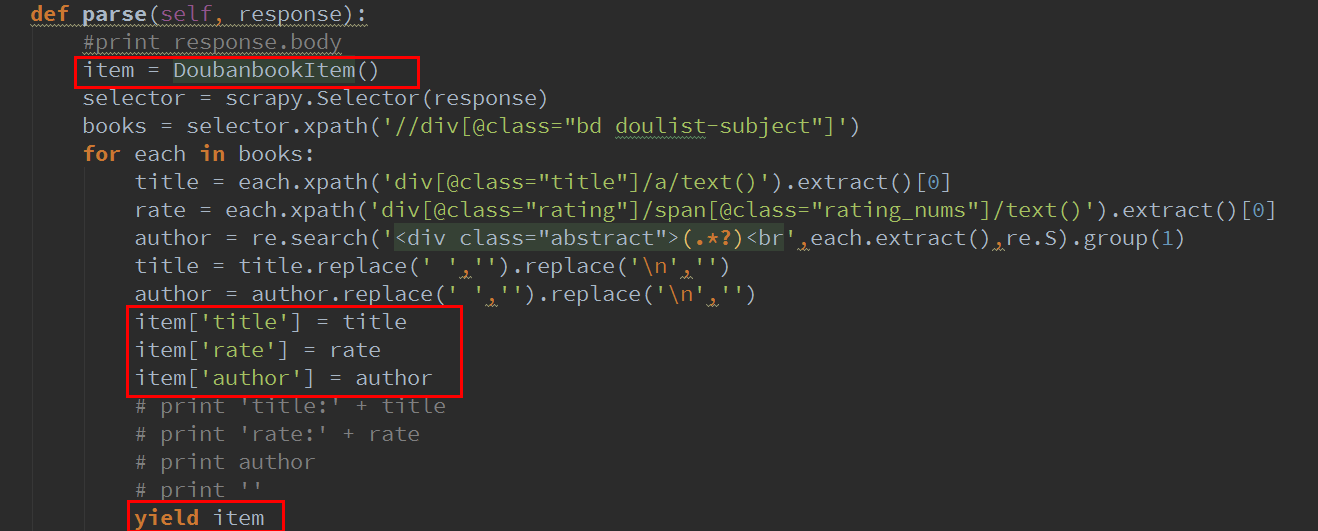
当然,你要使用item,需要把item类引入
from doubanbook.items import DoubanbookItem下面的yield可以让scrapy自动去处理item
好拉,再运行一下,可以看见G盘出现了一个douban.csv的文件
用excel打开看一下,怎么是乱码
没关系又是编码的问题,用可以修改编码的编辑器比如sublime打开一下,

保存编码为utf-8包含bom,或者用gvim打开:set fileencoding=gbk
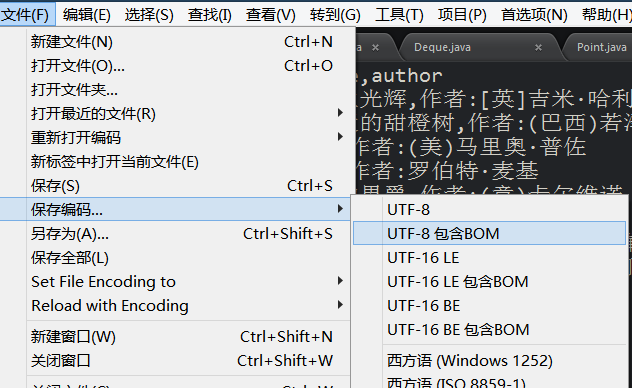
再打开,就正常了

爬取剩下页面
这还只保存了一个页面,那剩下的页面怎么办呢?难道要一个个复制网址??当然不是,我们重新观察网页,可以发现有个后页的链接,里面包含着后一页的网页链接,我们把它提取出来就行了。
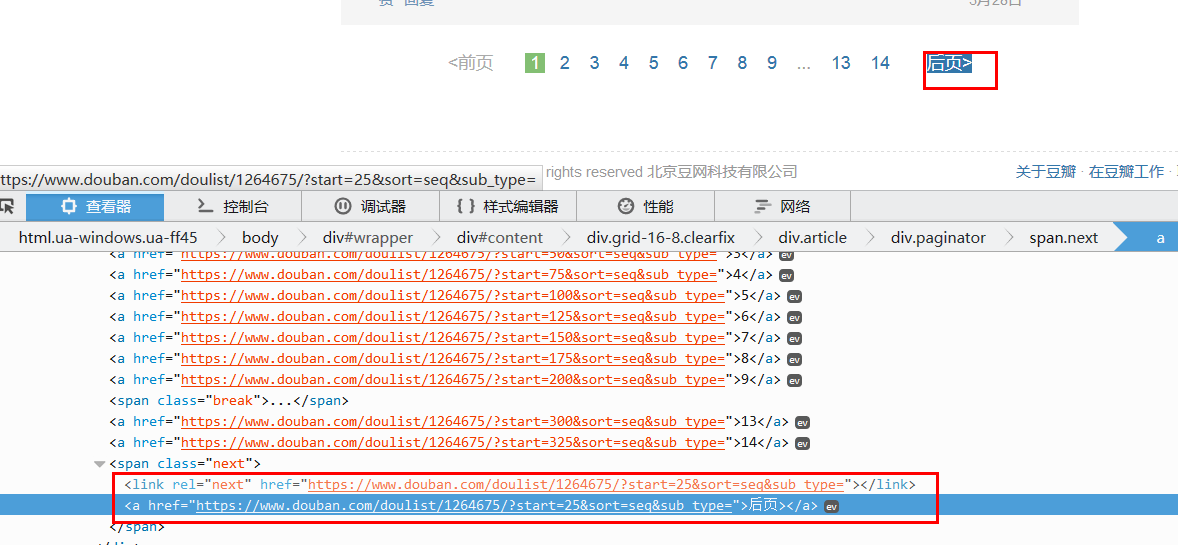
因为只有这里会出现标签,所以用xpath轻松提取
'//span[@class="next"]/link/@href'
然后提取后 我们scrapy的爬虫怎么处理呢?
答案还是yield,
yield scrapy.http.Request(url,callback=self.parse) 这样爬虫就会自动执行url的命令了,处理方式还是使用我们的parse函数
改后的代码这样:
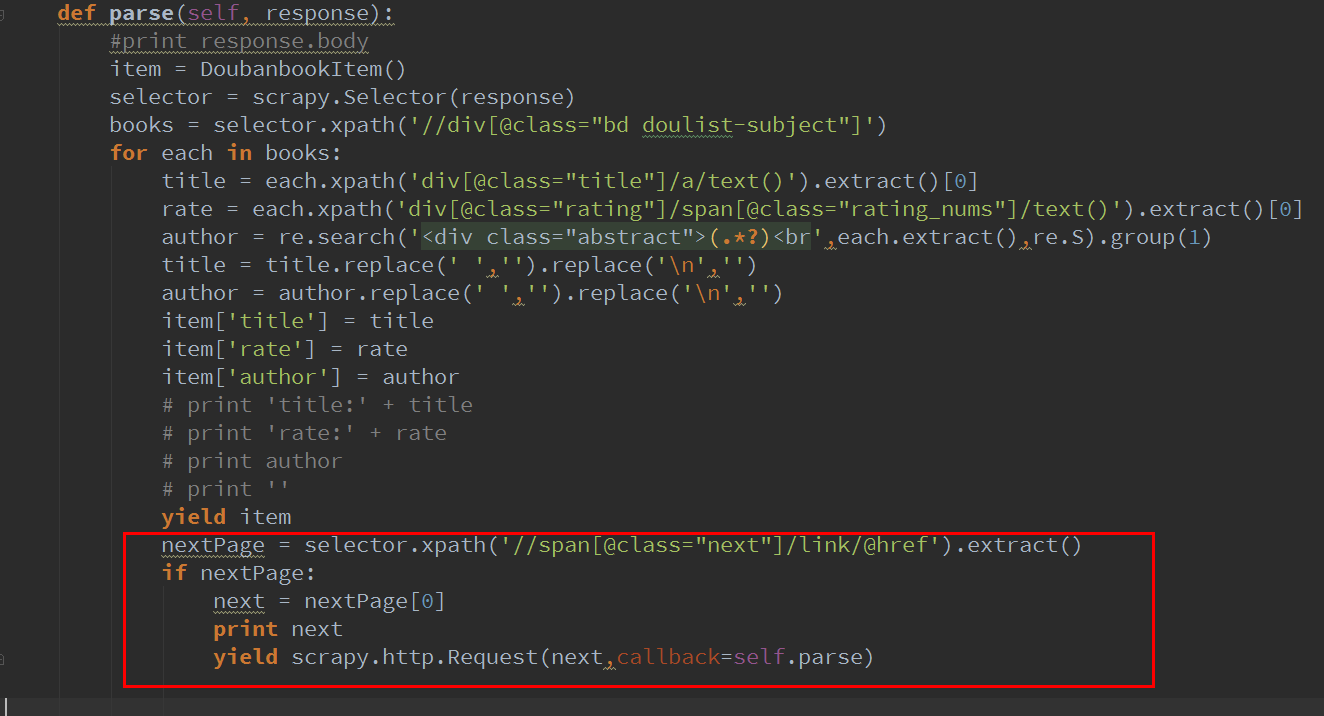
这里要加一个判断,因为在最后一页,“后一页”的链接就没了。
好了,我们再运行一下(先把之前的csv删除,不然就直接在后面添加了)可以发现,运行的特别快,十几页一下就运行完了,如果你用requests自己编写的代码,可以比较一下,用scrapy快很多,而且是自动化程度高很多。
我们打开csv,可以看见,有345篇文章了,和豆瓣上一致。
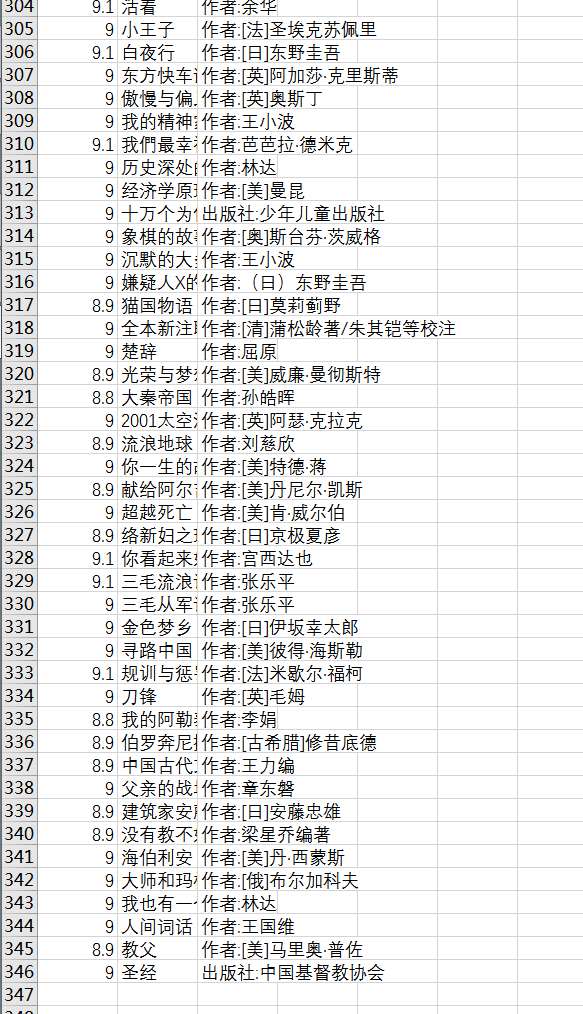
好了,这个豆瓣9分图书的爬虫结束了,相信通过这个例子,scrapy也差不多能上手,至少编写一般的爬虫是so easy了!
代码我放github上了,可以参考:
https://github.com/hk029/doubanbook
【图文详解】scrapy安装与真的快速上手——爬取豆瓣9分榜单的更多相关文章
- Git客户端图文详解如何安装配置GitHub操作流程攻略
收藏自 http://www.ihref.com/read-16377.html Git介绍 分布式 : Git版本控制系统是一个分布式的系统, 是用来保存工程源代码历史状态的命令行工具; 保存点 : ...
- Windows下图文详解Mongodb安装及配置
这两天接触了MongoDB数据库,发现和mysql数据库还是有很大差别的,同时使用前的配置看起来有些繁杂,踩过不少坑,其实只要一步一步搞清了,并不难. 接下来,我就整理下整个安装及配置过程. 安装的M ...
- 分区助手里如何从临近盘(如D盘)抽取一定的空间给已经快满了的盘(如E盘)(博主推荐)(图文详解)
不多说,直接上干货! 分区助手是什么?(博主推荐)(图文详解) 分区助手各版本比较(图文详解) 分区助手官网使用教程(专业版.绿色版和WinPE版)(图文详解) 安装分区助手时出现“分区助手已安装到你 ...
- 关于在真实物理机器上用cloudermanger或ambari搭建大数据集群注意事项总结、经验和感悟心得(图文详解)
写在前面的话 (1) 最近一段时间,因担任我团队实验室的大数据环境集群真实物理机器工作,至此,本人秉持负责.认真和细心的态度,先分别在虚拟机上模拟搭建ambari(基于CentOS6.5版本)和clo ...
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装爬虫框架Scrapy(离线方式和在线方式)(图文详解)
不多说,直接上干货! 参考博客 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装OpenCV(离线方式和在线方式)(图文详解) 第一步:首先,提示升级下pip 第二步 ...
- StreamSets学习系列之StreamSets的Core Tarball方式安装(图文详解)
不多说,直接上干货! 前期博客 StreamSets学习系列之StreamSets支持多种安装方式[Core Tarball.Cloudera Parcel .Full Tarball .Full R ...
- Logstash安装和设置(图文详解)(多节点的ELK集群安装在一个节点就好)
前提 Elasticsearch-2.4.3的下载(图文详解) Elasticsearch-2.4.3的单节点安装(多种方式图文详解) Elasticsearch-2.4.3的3节点安装(多种方式图文 ...
- 基于CentOS6.5下如何正确安装和使用Tcpreplay来重放数据(图文详解)
前期博客 基于CentOS6.5下snort+barnyard2+base的入侵检测系统的搭建(图文详解)(博主推荐) tcpreplay是什么? 简单的说, tcpreplay是一种pcap包的重放 ...
- 基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8、0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口)
不多说,直接上干货! 至于为什么,要写这篇博客以及安装Kafka-manager? 问题详情 无奈于,在kafka里没有一个较好自带的web ui.启动后无法观看,并且不友好.所以,需安装一个第三方的 ...
随机推荐
- 使用servletAPI三种方式简单示例
一.直接实现Action接口或集成ActionSupport类(推荐) public class HelloAction implements Action { @Override public St ...
- 初学JDBC,最简单示例
一.下载相应数据库驱动jar包,添加到项目中 二.注册驱动,数据库驱动只加入到classpath中是还不行的,还要在使用的时候注册一下,就像安装驱动软件,只拷贝到硬盘还不行,需要安装一下 Driver ...
- tomcat Host及Context 配置
参考资料: 一.Host配置 对一个Tomcat,可以配置多台虚拟主机.简单地说,就是让一台服务器可以对应多个主机名.这在Tomcat中称之为Host.要求每个Host的Name必须唯一. 配置方法: ...
- 同步文本框内容的JS代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- javascript console 函数详解 js开发调试的利器
Console 是用于显示 JS和 DOM 对象信息的单独窗口.并且向 JS 中注入1个 console 对象,使用该对象 可以输出信息到 Console 窗口中. 使用 alert 不是一样可以显示 ...
- Session超时处理
1.web.xml 添加配置: <!-- session超时 --> <filter> <filter-name>sessionFilter</filter- ...
- 背景透明的 Dialog
一:控制Dialog 的背景方法:1.定义一个无背景主题主题 <!--去掉背景Dialog--> <style name="NobackDialog" paren ...
- MBProgressHUD使用
//方式1.直接在View上show HUD = [[MBProgressHUD showHUDAddedTo:self.view animated:YES] retain]; HUD.delegat ...
- 服务器部署之 cap deploy:setup
文章是从我的个人博客上粘贴过来的, 大家也可以访问 www.iwangzheng.com $ cap deploy:setup 执行到这一步的时候会时间较长,可以直接中断 * executing &q ...
- ubuntu同步系统时间命令
*设置时区的命令 sudo tzselect 然后一步步选择就行 *同步时间的命令 sudo ntpdate ntp.ubuntu.com