大数据技术hadoop入门理论系列之二—HDFS架构简介
HDFS简单介绍
HDFS全称是Hadoop Distribute File System,是一个能运行在普通商用硬件上的分布式文件系统。
与其他分布式文件系统显著不同的特点是:
- HDFS是一个高容错系统且能运行在各种低成本硬件上;
- 提供高吞吐量,适合于存储大数据集;
- HDFS提供流式数据访问机制。
HDFS起源于Apache Nutch,现在是Apache Hadoop项目的核心子项目。
HDFS设计假设和目标
- 硬件错误是常态
在数据中心,硬件异常应被视作常态而非异常态。
在一个大数据环境下,hdfs集群有大量物理机器构成,每台机器由很多硬件组成,整个因为某一个组件出错而出错的几率是很高的,
因此HDFS架构的一个核心设计目标就是能够快速检测硬件失效并快速从失效中恢复工作。 - 流式访问要求
在HDFS集群上运行的应用要求流式访问数据,HDFS设计为适用于批处理而非交互式处理,因此在架构设计时更加强调高吞吐量而非低延迟。
对于POSIX的标准访问机制比如随机访问会严重降低吞吐量,HDFS将忽略此机制。 - 大数据集
假定HDFS的典型文件大小是GB甚至TB大小的,HDFS设计重点是支持大文件,支持通过机器数量扩展以支持更大的集群,
单个集群应提供海量文件数量支持 - 简单一致性模型
HDFS提供的访问模型是一次写入多次读取的模型。写入后文件保持原样不动简化了数据一致性模型并且对应用来说,它能得到更高的吞吐量。
文件追加也支持。 - 移动计算比移动数据代价更低
HDFS利用了计算机系统的数据本地化原理,认为数据离CPU越近,性能更高。
HDFS提供接口让应用感知数据的物理存储位置。 - 异构软硬件平台兼容
HDFS被设计成能方便的从一个平台迁移到另外一个平台
HDFS适用场景
综合上述的设计假设和后面的架构分析,HDFS特别适合于以下场景:
- 顺序访问
比如提供流媒体服务等大文件存储场景 - 大文件全量访问
如要求对海量数据进行全量访问,OLAP等 整体预算有限
想利用分布式计算的便利,又没有足够的预算购买HPC、高性能小型机等场景
在如下场景其性能不尽如人意:低延迟数据访问
低延迟数据访问意味着快速数据定位,比如10ms级别响应,系统若忙于响应此类要求,
则有悖于快速返回大量数据的假设。- 大量小文件
大量小文件将占用大量的文件块会造成较大的浪费以及对元数据(namenode)是个严峻的挑战 - 多用户并发写入
并发写入违背数据一致性模型,数据可能不一致。 - 实时更新
HDFS支持append,实时更新会降低数据吞吐以及增加维护数据一致的代价。
HDFS架构
本文将从以下几个方面分析HDFS架构,探讨HDFS架构是如何满足设计目标的。
HDFS总体架构
下面这张HDFS架构图来自于hadoop官方网站.

从这上面可以看出,HDFS采取主从式C/S架构,HDFS的节点分为两种角色:
- NameNode
NameNode提供文件元数据,访问日志等属性的存储、操作功能。
文件的基础信息等存放在NameNode当中,采用集中式存储方案。 DataNode
DataNode提供文件内容的存储、操作功能。
文件数据块本身存储在不同的DataNode当中,DataNode可以分布在不同机架。HDFS的Client会分别访问NameNode和DataNode以获取文件的元信息以及内容。HDFS集群的Client将
直接访问NameNode和DataNode,相关数据直接从NameNode或者DataNode传送到客户端。
HDFS数据组织机制
HDFS的数据组织分成两部分进行理解,首先是NameNode部分,其次是DataNode数据部分,数据的组织图如下所示:
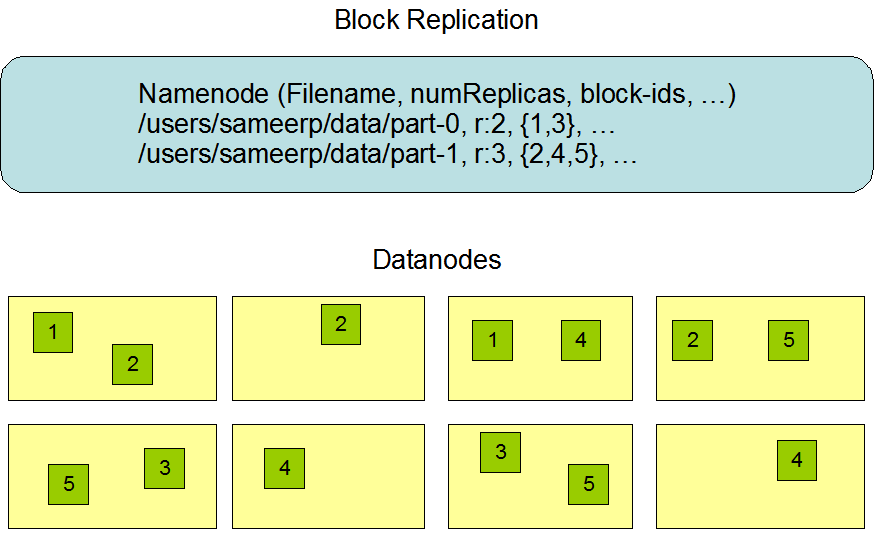
- NameNode
基于Yarn架构的HDFS中,NameNode采取主从式设计,主机主要负责客户端访问元数据的要求,以及存储块信息。
从机主要负责对主机进行实时备份,同时定期将用户操作记录以及文件记录归并到块存储设备,并将其回写到主机。
当主机失效时,从机接管主机所有的工作。 主从NameNode协同工作方式如下:
- DataNode
DataNode负责存储真正的数据。DataNode中文件以数据块为基础单位,数据块大小固定。整个集群中,同一个数据块
将被保存多份,分别存储在不同的DataNode当中。其中数据块大小,副本个数由hadoop的配置文件参数确定。数据块大小、
副本个数在集群启动后可以修改,修改后的参数重启之后生效,不影响现有的文件。
DataNode启动之后会扫描本地文件系统中物理块个数,并将对应的数据块信息汇报给NameNode。
HDFS数据访问机制
HDFS的文件访问机制为流式访问机制,即通过API打开文件的某个数据块之后,可以顺序读取或者写入某个文件,不可以指定
读取文件然后进行文件操作。
由于HDFS中存在多个角色,且对应应用场景主要为一次写入多次读取的场景,因此其读和写的方式有较大不同。读写操作都由
客户端发起,并且进行整个流程的控制,服务器角色(NameNode和DataNode)都是被动式响应。
下面分别对其进行 介绍:
- 读取流程
客户端发起读取请求时,首先与Namenode机进行连接,连接时同样需要hdfs配置文件,因此其知道各服务器相关信息。连接建立
完成后,客户端请求读取某个文件的某一个数据块,NameNode在内存中进行检索,查看是否有对应的文件以及文件块,若没有
则通知客户端对应文件或块不存在。若有则通知客户端对应的数据块存在哪些服务器之上,客户端确定收到信息之后,与对应的数据
接连连接,并开始进行网络传输。客户端任意选择其中一个副本数据进行读操作。
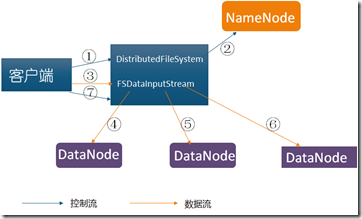
流程分析
•使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
• Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的DataNode地址;
•客户端开发库Client会选取离客户端最接近的DataNode来读取block;如果客户端本身就是DataNode,那么将从本地直接获取数据.
•读取完当前block的数据后,关闭与当前的DataNode连接,并为读取下一个block寻找最佳的DataNode;
•当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
•读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
- 写入流程
客户端发起写入求时,NameNode在内存中进行检索,查看是否有对应的文件以及文件块,若有 则通知客户端对应文件或块已存在,
若没有则通知客户端某台服务器作为写入主服务器。NameNode同时通知写入主服务器就绪,客户端与主服务器进行通信并写入数据时,
主写入服务器写入数据到物理磁盘,写入完成之后与NameNode通信获取其下一个副本服务器地址,确认地址之后将数据传递给它,这样
进行接力棒式写入,一直到达设置副本数目为止,等最后一个副本写完成,则同样将写入成功失败情况以接力棒方式返回给客户端,最后
客户端通知NameNode数据块写入成功,若其中某台失败则整个写入失败。
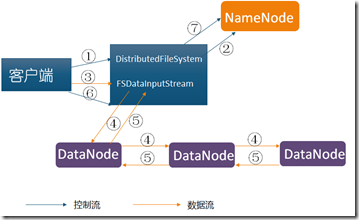
流程分析
•使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
•Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件 创建一个记录,否则会让客户端抛出异常;
•当客户端开始写入文件的时候,会将文件切分成多个packets,并在内部以数据队列"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
•开始以pipeline(管道)的形式将packet写入所有的replicas中。把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
•最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
•如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。
HDFS数据安全机制
HDFS文件系统的安全机制采取类linux的ACL安全访问机制。每一个文件默认继承其父对象即目录的访问权限,默认的用户和属组来自于
上传客户端的用户。相关控制方法也与linux类似,可以通过命令或者API指定某个用户对某个文件的读写权限。当用户没有对应的权限时,
若进行文件读写操作将会得到对应的错误提示。
HDFS高可用性机制
HDFS作为一个高可用集群,其可用性设计是非常用心的,主要体现在:
- NameNode主从设计
主从设计保证了元数据的可靠,解决了HDFS 1.0中单点故障的问题。具体可以参看上文描述 - 数据副本机制
数据副本机制保证了存放在某台服务器的文件块因为某种原因遭到破坏的时候,整个集群照样可以对外提供
文件访问服务,具体请参考上文数据访问机制部分。 - 数据恢复机制
这儿的数据恢复指HDFS提供一定时间的反悔窗口期,默认系统中被删除的文件被移动到trash目录里面,过了
一段时间之后有HDFS清理掉,此机制在云存储中普遍使用。若某数据块失效,通过副本机制则可以恢复。 - 机架感知机制
大型集群的组织是以机架形式组织的,机器以固定数量服务器以及对应的网络设备组成一个机柜,一般来说,跨机架的网络IO总是比同一机架更高,当然若跨机房则代价更高。因此HDFS总是想办法将数据保存在性能更好的服务器当中以提升性能,同时会设法将数据保存到不同机架以保证数据的容错性。典型机架拓扑和副本如下图所示:
在应用读取数据时,HDFS总是选择离应用更近的服务器。 - 快照机制
- 自动错误检测恢复机制
机器失效检测通过心跳检测完成,若在一段时间内,DataNode或者NameNode不能返回心跳,主NameNode会将其标记为宕机服务器,此后新的IO请求等将不会被转发到此服务器,同时对应的文件若有相关文件因为某台服务器宕机导致副本数目达不到指定数目,HDFS将重新复制部分文件副本,以保证整个集群的可靠性。 - 校验和机制
校验和是指对每一个数据块产生一个校验和,当数据被再次读取时,客户端对其进行计算并与服务器上的校验和进行比较,保证了数据不会因为网络传输或者其他方式被篡改。
HDFS集群扩展机制
集群的动态扩展方式方便用户以动态的方式对集群进行扩容和缩容。若有新服务器加入,则后续的IO会有更多的机会被
发送到新服务器上执行,对集群中现有文件的充分分布,可以通过命令进行,但是数据重新分布将只占用少量网络IO,这样保证集群上的应用不会因为重分布而受到重大影响。同样机器下架也通过命令进行,此时集群表现出与机器宕机类似情况,会不再往其上发IO请求以及重新复制以保证副本数量。
参考文献:
大数据技术hadoop入门理论系列之二—HDFS架构简介的更多相关文章
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据:Hadoop入门
大数据:Hadoop入门 一:什么是大数据 什么是大数据: (1.)大数据是指在一定时间内无法用常规软件对其内容进行抓取,管理和处理的数据集合,简而言之就是数据量非常大,大到无法用常规工具进行处理,如 ...
- 大数据技术Hadoop笔试题
Hadoop有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上.以下是由应届毕业生网小编J.L为您整理推荐的面试笔试题目和经验,欢迎参考阅读. 单项选择题 1. 下面哪个程序负责 H ...
- 大数据技术Hadoop面试题
1. 下面哪个程序负责 HDFS 数据存储.答案C datanode a)NameNodeb)Jobtrackerc)Datanode d)secondaryNameNodee)tasktracker ...
- 《Hadoop》大数据技术开发实战学习笔记(二)
搭建Hadoop 2.x分布式集群 1.Hadoop集群角色分配 2.上传Hadoop并解压 在centos01中,将安装文件上传到/opt/softwares/目录,然后解压安装文件到/opt/mo ...
- Java+大数据开发——Hadoop集群环境搭建(二)
1. MAPREDUCE使用 mapreduce是hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序 2. Demo开发--wo ...
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- 大数据技术之Hadoop入门
第1章 大数据概论 1.1 大数据概念 大数据概念如图2-1 所示. 图2-1 大数据概念 1.2 大数据特点(4V) 大数据特点如图2-2,2-3,2-4,2-5所示 图2-2 大数据特点之大量 ...
- 大数据之Hadoop技术入门汇总
今天,小编对Hadoop入门学习知识进行了汇总,帮助大家更好地入手大数据.小编关于Hadoop入门总共发写了12篇原创文章,文章是参照尚硅谷大数据视频教程来进行撰写的. 今天,小编带你解锁正确的阅读顺 ...
随机推荐
- 【转】velocity 显示List和Map方法
一.遍历个map类型 1.先看后台java程序Java代码 Map<String,String> paramValues=new HashMap<String, String ...
- 查看Eclipse中的jar包的源代码:jd-gui.exe
前面搞了很久的使用JAD,各种下载插件,最后配置好了,还是不能用,不知道怎么回事, 想起一起用过的jd-gui.exe这个工具,是各种强大啊!!! 只需要把jar包直接扔进去就可以了,非常清晰,全部解 ...
- php开发网站编码统一问题
一个良好的网站代码整洁,注释适当是最基本的,也是好的习惯,这可以避免以后的非常乱了自己感觉都乱,一旦重构麻烦就大了耗时耗力,其中网站整个体系的编码是最重要的一个方面,为了网站的稳定性建议php程序,H ...
- 【python】choice函数
来源:http://www.runoob.com/python/func-number-choice.html 描述 choice() 方法返回一个列表,元组或字符串的随机项. 语法 以下是 choi ...
- 前端代理nproxy
一.场景/用途 前端代理的用途,相信大家都清楚.应用场景很多,如—— . 将线上的静态资源文件(JS.CSS.图片)替换为本地相应的文件,来调试线上(代码都被压缩过)的问题: . 本地开发过程,当后端 ...
- CocoaPods报错及解决方法记录
[!] Oh no, an error occurred. Search for existing GitHub issues similar to yours: https://github.com ...
- Diablo3
1.装备 主手:元素弓 副手:精细箭袋 头: 胸:燃火外套 手:娜塔亚的手感 护腕:稳击护腕 戒指:罗盘玫瑰+布尔凯索的婚戒 颈部:旅者之誓 腰:科雷姆的强力腰带(速度加25%) 腿:深渊挖掘裤 脚: ...
- C++基础(1)
1.关于继承及访问. C++中 public,protected, private 访问标号小结,即访问标号使用限制. 第一:private, public, protected 访问标号的访问范围. ...
- 什么是网络爬虫(Spider) 程序
Spider又叫WebCrawler或者Robot,是一个沿着链接漫游Web 文档集合的程序.它一般驻留在服务器上,通过给定的一些URL,利用HTTP等标准协议读取相应文档,然后以文档中包括的所有未访 ...
- 在Android中将子View的坐标转换为父View的坐标
在Android中,我们有时候可能会将子View的坐标转换为父View中的坐标.感觉很有用,分享给大家. 在Launcher中有这么一段代码可以完成这项工作. public float getDes ...