【Hadoop学习之六】MapReduce原理
一、概念
MapReduce:
"相同"的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
块、分片、map、reduce、分组、分区之间对应关系
block > split
1:1:1个block可以切成1个分片
N:1:多个block可以以切成1个分片
1:N:1个block可以切成多个分片
split > map
1:1:一个分片只能产生一个map
map > reduce
N:1:多个Map可以对应一次reduce
N:N:多个Map可以对应多次reduce
1:1:1个Map可以对应1次reduce
1:N:1个Map可以对应多次reduce
group(key)>partition
1:1:1次分组可以对应1个分区
N:1:多个分组可以对应一个分区
N:N:多个分组可以对应多个分区
1:N? >违背了原语
partition > outputfile

MapTAsk:
(1)对于一个分片,加载到内存进行Map处理,
(2)Map业务逻辑将分片中数据处理成一个个的K,V键值对
(3)将Map输出的K,V键值对加工,生成含有分区partition的K,V,P键值对
(4)经过一段时间的处理,将生成的KVP数据放到缓存里(默认100M),然后按照分区P,键key排序,最终形成一个内部有序外部无序的100M文件
(5)将这个100M缓存输出到本地文件系统里,经过map处理完成后,最终生成一堆这样的小文件
(6)将这一堆小文件进行归并形成一个内部有序外部无序的大文件

ReduceTask:
(1)将各个节点归并后的大文件中拉取(shuffler)属于同一分区的文件
这个地方会产生网络IO,map之后的文件如果很大会影响性能,因此可以对map之后的数据进行简单统计 降低拉取文件的大小
(2)将拉过来的小文件进行归并,reduce的归并强依赖map的排序结果
(3)将合并的文件调用reduce
二、Hadoop整体协作
Hadoop 1.x
1、客户端clients先启动,计算切片清单,
2、客户端将MR jar包、切片清单、配置文件等作业资源上传HDFS;
3、客户端提交任务给Job Tracker
4、Job Tracker从HDFS获取切片清单,参考Task Tracker上的资源负载情况,规划Map、Reduce任务去到的节点
5、Task Tracker通过与Job Tracker心跳,获取属于自己的任务清单
6、Task Tracker从HDFS上获取切片清单、jar、配置,map运行map任务,Reduce运行Reduce任务,
7、Reduce任务将生成结果文件返回给HDFS
8、客户端通过HDFS下载文件 查看结果
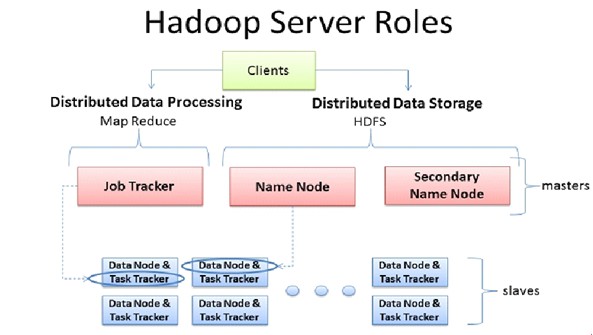

弊端:Job Tracker有两件事:任务调度和监控整个集群资源负载,存在单点故障、负载过重、资源管理和计算调度强耦合
因此有了Hadoop 2.x的YARN
【Hadoop学习之六】MapReduce原理的更多相关文章
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- hadoop笔记之MapReduce原理
MapReduce原理 MapReduce原理 简单来说就是,一个大任务分成多个小的子任务(map),并行执行后,合并结果(reduce). 例子: 100GB的网站访问日志文件,找出访问次数最多的I ...
- [Hadoop]浅谈MapReduce原理及执行流程
MapReduce MapReduce原理非常重要,hive与spark都是基于MR原理 MapReduce采用多进程,方便对每个任务资源控制和调配,但是进程消耗更多的启动时间,因此MR时效性不高.适 ...
- Hadoop学习笔记—MapReduce的理解
我不喜欢照搬书上的东西,我觉得那样写个blog没多大意义,不如直接把那本书那一页告诉大家,来得省事.我喜欢将我自己的理解.所以我会说说我对于Hadoop对大量数据进行处理的理解.如果有理解不对欢迎批评 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- 【尚学堂·Hadoop学习】MapReduce案例2--好友推荐
案例描述 根据好友列表,推荐好友的好友 数据集 tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive ...
- 【尚学堂·Hadoop学习】MapReduce案例1--天气
案例描述 找出每个月气温最高的2天 数据集 -- :: 34c -- :: 38c -- :: 36c -- :: 32c -- :: 37c -- :: 23c -- :: 41c -- :: 27 ...
- hadoop学习day3 mapreduce笔记
1.对于要处理的文件集合会根据设定大小将文件分块,每个文件分成多块,不是把所有文件合并再根据大小分块,每个文件的最后一块都可能比设定的大小要小 块大小128m a.txt 120m 1个块 b.txt ...
- Hadoop学习(3)-mapreduce快速入门加yarn的安装
mapreduce是一个运算框架,让多台机器进行并行进行运算, 他把所有的计算都分为两个阶段,一个是map阶段,一个是reduce阶段 map阶段:读取hdfs中的文件,分给多个机器上的maptask ...
随机推荐
- document.forms用法示例介绍
概述 forms 返回一个集合 (一个HTMLCollection对象),包含了了当前文档中的所有form元素. 语法 var collection = document.forms; documen ...
- synchronized同一把锁锁不同代码
对于多线程,如果是计算密集型,多线程不一定优势:但如果是io密集型(因为速度慢),多线程多数情况下就有很大的优势了(但也不全是,因为当io已经满负荷运转下,即100%了,再增加线程,未必就会增加效率) ...
- SQL Server 安装好后 Always On群组配置
需要对SQL Server必要的端口打开Windows防火墙的入站规则,比如TCP- 1433端口等. 特别注意:由于AG默认需要用到TCP-5022端口,所以该端口务必保证在Windows防火墙中开 ...
- Java基础知识(JAVA之IO流)
学习Java IO,不得不提到的就是JavaIO流. 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象.即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各 ...
- python实现根据当前时间创建目录并输出日志
举个例子:比如我们要实现根据当前时间的年月日来新建目录来存放每天的日志,当前时间作为日志文件名称:代码如下: #!/usr/bin/env python3 # _*_ coding: utf-8 _* ...
- 003-hive安装
http://www.aboutyun.com/thread-6902-1-1.html http://www.aboutyun.com/thread-7374-1-1.html
- GitHub账户注册
GitHub是一个优秀的面向开源及私有软件项目的托管平台,值得我们使用,但因为其不同于我们常见的很多平台,所以刚开始使用时,我们会遇到很多的问题.特此记录下博主自己使用GitHub的过程供自己以后查看 ...
- 多态使用时,父类多态时需要使用子类特有对象。需要判断 就使用instanceof
instanceof:通常在向下转型前用于健壮性的判断,判断是符合哪一个子类对象 package Polymorphic; public class TestPolymorphic { public ...
- (转)SpringBoot之退出服务(exit)时调用自定义的销毁方法
我们在工作中有时候可能会遇到这样场景,需要在退出容器的时候执行某些操作.SpringBoot中有两种方法可以供我们来选择(其实就是spring中我们常用的方式.只是destory-method是在XM ...
- 后续使用dubbo的必要性的思考
要做微服务,要做分布式,就得先解决网络调用即rpc的问题