转--python之正则入门
1. 正则表达式基础
1.1. 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程: 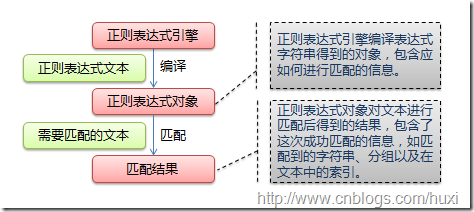
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法: 
1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1. 开始使用re
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# encoding: UTF-8import re# 将正则表达式编译成Pattern对象pattern = re.compile(r'hello')# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回Nonematch = pattern.match('hello world!')if match: # 使用Match获得分组信息 print match.group()### 输出 #### hello |
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
- S(DOTALL): 点任意匹配模式,改变'.'的行为
- L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
|
1
2
3
4
|
a = re.compile(r"""\d + # the integral part \. # the decimal point \d * # some fractional digits""", re.X)b = re.compile(r"\d+\.\d*") |
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。这些方法将在Pattern类的实例方法部分一起介绍。如上面这个例子可以简写为:
|
1
2
|
m = re.match(r'hello', 'hello world!')print m.group() |
re模块还提供了一个方法escape(string),用于将string中的正则表达式元字符如*/+/?等之前加上转义符再返回,在需要大量匹配元字符时有那么一点用。
2.2. Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
- string: 匹配时使用的文本。
- re: 匹配时使用的Pattern对象。
- pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
- lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
- lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
- group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 - groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 - groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 - start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 - end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 - span([group]):
返回(start(group), end(group))。 - expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import rem = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!')print "m.string:", m.stringprint "m.re:", m.reprint "m.pos:", m.posprint "m.endpos:", m.endposprint "m.lastindex:", m.lastindexprint "m.lastgroup:", m.lastgroupprint "m.group(1,2):", m.group(1, 2)print "m.groups():", m.groups()print "m.groupdict():", m.groupdict()print "m.start(2):", m.start(2)print "m.end(2):", m.end(2)print "m.span(2):", m.span(2)print r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')### output #### m.string: hello world!# m.re: <_sre.SRE_Pattern object at 0x016E1A38># m.pos: 0# m.endpos: 12# m.lastindex: 3# m.lastgroup: sign# m.group(1,2): ('hello', 'world')# m.groups(): ('hello', 'world', '!')# m.groupdict(): {'sign': '!'}# m.start(2): 6# m.end(2): 11# m.span(2): (6, 11)# m.expand(r'\2 \1\3'): world hello! |
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import rep = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL)print "p.pattern:", p.patternprint "p.flags:", p.flagsprint "p.groups:", p.groupsprint "p.groupindex:", p.groupindex### output #### p.pattern: (\w+) (\w+)(?P<sign>.*)# p.flags: 16# p.groups: 3# p.groupindex: {'sign': 3} |
实例方法[ | re模块方法]:
- match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
示例参见2.1小节。 - search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。12345678910111213141516# encoding: UTF-8importre# 将正则表达式编译成Pattern对象pattern=re.compile(r'world')# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None# 这个例子中使用match()无法成功匹配match=pattern.search('hello world!')ifmatch:# 使用Match获得分组信息printmatch.group()### 输出 #### world - split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。1234567importrep=re.compile(r'\d+')printp.split('one1two2three3four4')### output #### ['one', 'two', 'three', 'four', ''] - findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。1234567importrep=re.compile(r'\d+')printp.findall('one1two2three3four4')### output #### ['1', '2', '3', '4'] - finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。12345678importrep=re.compile(r'\d+')forminp.finditer('one1two2three3four4'):printm.group(),### output #### 1 2 3 4 - sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。123456789101112131415importrep=re.compile(r'(\w+) (\w+)')s='i say, hello world!'printp.sub(r'\2 \1', s)deffunc(m):returnm.group(1).title()+' '+m.group(2).title()printp.sub(func, s)### output #### say i, world hello!# I Say, Hello World! - subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。123456789101112131415importrep=re.compile(r'(\w+) (\w+)')s='i say, hello world!'printp.subn(r'\2 \1', s)deffunc(m):returnm.group(1).title()+' '+m.group(2).title()printp.subn(func, s)### output #### ('say i, world hello!', 2)# ('I Say, Hello World!', 2)
以上就是Python对于正则表达式的支持。熟练掌握正则表达式是每一个程序员必须具备的技能,这年头没有不与字符串打交道的程序了。笔者也处于初级阶段,与君共勉,^_^
另外,图中的特殊构造部分没有举出例子,用到这些的正则表达式是具有一定难度的。有兴趣可以思考一下,如何匹配不是以abc开头的单词,^_^
全文结束
Python 正则表达式入门(初级篇)
本文主要为没有使用正则表达式经验的新手入门所写。
转载请写明出处
引子
首先说 正则表达式是什么?
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
引用自维基百科https://zh.wikipedia.org/wiki/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F
定义是定义,太正经了就没法用了。我们来举个栗子:假如你在写一个爬虫,你得到了
一个网页的HTML源码。其中有一段
<html><body><h1>hello world<h1></body></html>你想要把这个hello world提取出来,但你这时如果只会python 的字符串处理,那么第一反应可能是
s = <html><body><h1>hello world<h1></body></html>
start_index = s.find('<h1>')然后从这个位置向下查找到下一个<h1>出现这样做未尝不可,但是很麻烦不是吗。需要考虑多个标签,一不留神就多匹配到东西了,而如果想要非常准确的匹配到,又得多加循环判断,效率太低。
这时候,正则表达式就是首选的帮手。
干货开始
入门级别
接着说我们刚才那个例子。我们如果拿正则处理这个表达式要怎么做呢?
import re
key = r"<html><body><h1>hello world<h1></body></html>"#这段是你要匹配的文本
p1 = r"(?<=<h1>).+?(?=<h1>)"#这是我们写的正则表达式规则,你现在可以不理解啥意思
pattern1 = re.compile(p1)#我们在编译这段正则表达式
matcher1 = re.search(pattern1,key)#在源文本中搜索符合正则表达式的部分
print matcher1.group(0)#打印出来你可以尝试运行上面的代码,看看是不是和我们想象的一样(博主是在python2.7环境下)发现代码挺少挺简单?往下看。而且正则表达式实际上要比看起来的那种奇形怪状要简单得多。
首先,从最基础的正则表达式说起。
假设我们的想法是把一个字符串中的所有"python"给匹配到。我们试一试怎么做
import re
key = r"javapythonhtmlvhdl"#这是源文本
p1 = r"python"#这是我们写的正则表达式
pattern1 = re.compile(p1)#同样是编译
matcher1 = re.search(pattern1,key)#同样是查询
print matcher1.group(0)看完这段代码,你是不是觉得:卧槽?这就是正则表达式?直接写上去就行?
确实,正则表达式并不像它表面上那么奇葩,如果不是我们故意改变一些符号的含义时,你看到的就是想要匹配的。
所以,先把大脑清空,先认为正则表达式就是和想要匹配的字符串长得一样。在之后的练习中我们会逐步进化
初级
0.无论是python还是正则表达式都是区分大小写的,所以当你在上面那个例子上把"python"换成了"Python",那就匹配不到你心爱的python了。
1.重新回到第一个例子中那个<h1>hello world<h1>匹配。假如我像这么写,会怎么样?
import re
key = r"<h1>hello world<h1>"#源文本
p1 = r"<h1>.+<h1>"#我们写的正则表达式,下面会将为什么
pattern1 = re.compile(p1)
print pattern1.findall(key)#发没发现,我怎么写成findall了?咋变了呢?有了入门级的经验,我们知道那两个<h1>就是普普通通的字符,但是中间的是什么鬼?.字符在正则表达式代表着可以代表任何一个字符(包括它本身)
findall返回的是所有符合要求的元素列表,包括仅有一个元素时,它还是给你返回的列表。
机智如你可能会突然问:那我如果就只是想匹配"."呢?结果啥都给我返回了咋整?在正则表达式中有一个字符\,其实如果你编程经验较多的话,你就会发现这是好多地方的“转义符”。在正则表达式里,这个符号通常用来把特殊的符号转成普通的,把普通的转成特殊的23333(并不是特殊的“2333”,写完才发现会不会有脑洞大的想歪了)。
举个栗子,你真的想匹配"chuxiuhong@hit.edu.cn"这个邮箱(我的邮箱),你可以把正则表达式写成下面这个样子:
import re
key = r"afiouwehrfuichuxiuhong@hit.edu.cnaskdjhfiosueh"
p1 = r"chuxiuhong@hit\.edu\.cn"
pattern1 = re.compile(p1)
print pattern1.findall(key)发现了吧,我们在.的前面加上了转义符\,但是并不是代表匹配“\.”的意思,而是只匹配“.”的意思!
不知道你细不细心,有没有发现我们第一次用.时,后面还跟了一个+?那这个加号是干什么的呢?
其实不难想,我们说了“.字符在正则表达式代表着可以代表任何一个字符(包括它本身)”,但是"hello world"可不是一个字符啊。+的作用是将前面一个字符或一个子表达式重复一遍或者多遍。
比方说表达式“ab+”那么它能匹配到“abbbbb”,但是不能匹配到"a",它要求你必须得有个b,多了不限,少了不行。你如果问我有没有那种“有没有都行,有多少都行的表达方式”,回答是有的。*跟在其他符号后面表达可以匹配到它0次或多次
比方说我们在王叶内遇到了链接,可能既有http://开头的,又有https://开头的,我们怎么处理?
import re
key = r"http://www.nsfbuhwe.com and https://www.auhfisna.com"#胡编乱造的网址,别在意
p1 = r"https*://"#看那个星号!
pattern1 = re.compile(p1)
print pattern1.findall(key)输出
['http://', 'https://']2.比方说我们有这么一个字符串"cat hat mat qat",你会发现前面三个是实际的单词,最后那个是我胡编乱造的(上百度查完是昆士兰英语学院的缩写= =)。如果你本来就知道"at"前面是c、h、m其中之一时这才构成单词,你想把这样的匹配出来。根据已经学到的知识是不是会想到写出来三个正则表达式进行匹配?实际上不需要。因为有一种多字符匹方式[]代表匹配里面的字符中的任意一个
还是举个栗子,我们发现啊,有的程序员比较过分,,在<html></html>这对标签上,大小写混用,老害得我们抓不到想要的东西,我们该怎么应对?是写16*16种正则表达式挨个匹配?no
import re
key = r"lalala<hTml>hello</Html>heiheihei"
p1 = r"<[Hh][Tt][Mm][Ll]>.+?</[Hh][Tt][Mm][Ll]>"
pattern1 = re.compile(p1)
print pattern1.findall(key)输出
['<hTml>hello</Html>']我们既然有了范围性的匹配,自然有范围性的排除。[^]代表除了内部包含的字符以外都能匹配
还是cat,hat,mat,qat这个例子,我们想匹配除了qat以外的,那么就应该这么写:
import re
key = r"mat cat hat pat"
p1 = r"[^p]at"#这代表除了p以外都匹配
pattern1 = re.compile(p1)
print pattern1.findall(key)输出
为了方便我们写简洁的正则表达式,它本身还提供下面这样的写法
| 正则表达式 | 代表的匹配字符 |
|---|---|
| [0-9] | 0123456789任意之一 |
| [a-z] | 小写字母任意之一 |
| [A-Z] | 大写字母任意之一 |
| \d | 等同于[0-9] |
| \D | 等同于[^0-9]匹配非数字 |
| \w | 等同于[a-z0-9A-Z_]匹配大小写字母、数字和下划线 |
| \W | 等同于[^a-z0-9A-Z_]等同于上一条取非 |
3.介绍到这里,我们可能已经掌握了大致的正则表达式的构造方式,但是我们常常会在实战中遇到一些匹配的不准确的问题。比方说:
import re
key = r"chuxiuhong@hit.edu.cn"
p1 = r"@.+\."#我想匹配到@后面一直到“.”之间的,在这里是hit
pattern1 = re.compile(p1)
print pattern1.findall(key)输出结果
['@hit.edu.']呦呵!你咋能多了呢?我理想的结果是@hit.,你咋还给我加量了呢?这是因为正则表达式默认是“贪婪”的,我们之前讲过,“+”代表是字符重复一次或多次。但是我们没有细说这个多次到底是多少次。所以它会尽可能“贪婪”地多给我们匹配字符,在这个例子里也就是匹配到最后一个“.”。
我们怎么解决这种问题呢?只要在“+”后面加一个“?”就好了。
import re
key = r"chuxiuhong@hit.edu.cn"
p1 = r"@.+?\."#我想匹配到@后面一直到“.”之间的,在这里是hit
pattern1 = re.compile(p1)
print pattern1.findall(key)输出结果
['@hit.']加了一个“?”我们就将贪婪的“+”改成了懒惰的“+”。这对于[abc]+,\w*之类的同样适用。
小测验:上面那个例子可以不使用懒惰匹配,想一种方法得到同样的结果
**个人建议:在你使用"+","*"的时候,一定先想好到底是用贪婪型还是懒惰型,尤其是当你用到范围较大的项目上时,因为很有可能它就多匹配字符回来给你!!!**
为了能够准确的控制重复次数,正则表达式还提供
{a,b}(代表a<=匹配次数<=b)
还是举个栗子,我们有sas,saas,saaas,我们想要sas和saas,我们怎么处理呢?
import re
key = r"saas and sas and saaas"
p1 = r"sa{1,2}s"
pattern1 = re.compile(p1)
print pattern1.findall(key)输出
['saas', 'sas']如果你省略掉{1,2}中的2,那么就代表至少匹配一次,那么就等价于?
如果你省略掉{1,2}中的1,那么就代表至多匹配2次。
下面列举一些正则表达式里的元字符及其作用
| 元字符 | 说明 |
|---|---|
| . | 代表任意字符 |
| | | 逻辑或操作符 |
| [ ] | 匹配内部的任一字符或子表达式 |
| [^] | 对字符集和取非 |
| - | 定义一个区间 |
| \ | 对下一字符取非(通常是普通变特殊,特殊变普通) |
| * | 匹配前面的字符或者子表达式0次或多次 |
| *? | 惰性匹配上一个 |
| + | 匹配前一个字符或子表达式一次或多次 |
| +? | 惰性匹配上一个 |
| ? | 匹配前一个字符或子表达式0次或1次重复 |
| {n} | 匹配前一个字符或子表达式 |
| {m,n} | 匹配前一个字符或子表达式至少m次至多n次 |
| {n,} | 匹配前一个字符或者子表达式至少n次 |
| {n,}? | 前一个的惰性匹配 |
| ^ | 匹配字符串的开头 |
| \A | 匹配字符串开头 |
| $ | 匹配字符串结束 |
| [\b] | 退格字符 |
| \c | 匹配一个控制字符 |
| \d | 匹配任意数字 |
| \D | 匹配数字以外的字符 |
| \t | 匹配制表符 |
| \w | 匹配任意数字字母下划线 |
| \W | 不匹配数字字母下划线 |
中级篇介绍子表达式,向前向后查找,回溯引用 链接:http://www.cnblogs.com/chuxiuhong/p/5907484.html
Python 正则表达式入门(中级篇)
初级篇链接:http://www.cnblogs.com/chuxiuhong/p/5885073.html
上一篇我们说在这一篇里,我们会介绍子表达式,向前向后查找,回溯引用。到这一篇开始前除了回溯引用在一些场合不可替代以外,大部分情况下的正则表达式你应该都会写了。
1.子表达式
子表达式的概念特别好理解。其实它就是将几个字符的组合形式看做一个大的“字符”。不好理解?举个栗子:我们要匹配类似IP地址这种形式的字符(暂且不考虑数值范围的合理性,这个留作学完之后的思考题吧)。形如192.168.1.1这样的地址我们怎么写表达式呢?
答案一 \d+.?\d+.?\d+.?\d+不好,一个是太繁琐,另一个是连位数都控制不了
答案二 \d+{1,3}.?\d+{1,3}.?\d+{1,3}.?\d+{1,3}一般般,复杂但是起码能把位数控制在合理范围
答案三 (\d+{1,3}\.){3}\d+{1,3}\.利用子表达式,将123.这种数字加小数点看做一个整体字符,对其规定重复匹配的次数,既简洁,效果又好。所以只要你将几个字符组合用圆括号括起来,那么你就可以把一个圆括号内的内容当做一个字符,外面可以加我们之前讲过的所有元字符来控制匹配。
2.向前向后查找
现在,我们终于来到了向前向后查找这一块。为什么说终于来到这了呢?还记得我们在初级篇最开始的例子吗?
假如你在写一个爬虫,你得到了一个网页的HTML源码。其中有一段html
<html><body><h1>hello world</h1></body></html>
你想要把这个hello world提取出来
import re
key = r"<html><body><h1>hello world</h1></body></html>"#这段是你要匹配的文本
p1 = r"(?<=<h1>).+?(?=</h1>)"#这是我们写的正则表达式规则,你现在可以不理解啥意思
pattern1 = re.compile(p1)#我们在编译这段正则表达式
matcher1 = re.search(pattern1,key)#在源文本中搜索符合正则表达式的部分
print matcher1.group(0)#打印出来这个正则表达式
p1 = r"(?<=<h1>).+?(?=<h1>)"看到(?<=<h1>) 和 (?=<h1>)了吗?第一个?<=表示在被匹配字符前必须得有<h1>,后面的?=表示被匹配字符后必须有<h1>
简单来说,就是你要匹配的字符是XX,但必须满足形式是AXXB这样的字符串,那么你就可以这样写正则表达式
p = r"(?<=A)XX(?=B)"匹配到的字符串就是XX。并且,向前查找向后查找不需要必须同时出现。如果你愿意,可以只写满足一个条件。
所以你也不需要记住哪个是向前查找,哪个是向后查找。只要记住?<=后面跟着的是前缀要求,?=后面跟的是后缀要求。
本质上来说,向前查找和向后查找其实是匹配整个字符串,即AXXB,但返回时仅仅返回一个XX。也就是说,如果你愿意,完全可以避开向前向后查找的方式,直接匹配带有前后缀的字符串,然后做字符串切片处理。
3.回溯引用
不同于前面的向前向后查找,这一条有时候你未必绕的过去。在有些情况下,你还必须得用到回溯引用,所以你如果想拥有在实际应用中使用正则表达式,回溯引用是你应该了解和掌握的。
我们还是从最开始的例子来说。
你原本要匹配<h1></h1>之间的内容,现在你知道HTML有多级标题,你想把每一级的标题内容都提取出来。你也许会这样写:
p = r"<h[1-6]>.*?</h[1-6]>"这样一来,你就可以将HTML页面内所有的标题内容全部匹配出来。即<h1></h1>到<h6></h6>的内容都可以被提取出来。但是我们之前说过,写正则表达式困难的不是匹配到想要的内容,而是尽可能的不匹配到不想要的内容。在这个例子中,很有可能你就会被下面这样的用例玩坏。
比方说
<h1>hello world</h3>发现后面的</h3>了吗?我们不管是怎么写出来这样的标题的,但实实在在的是我们的正则表达式同样会把这里面的hello world匹配出来。这时候就是回溯引用的重要作用。下面就是一个示例:
import re
key = r"<h1>hello world</h3>"
p1 = r"<h([1-6])>.*?</h\1>"
pattern1 = re.compile(p1)
m1 = re.search(pattern1,key)
print m1.group(0)#这里是会报错的,因为匹配不到,你如果将源字符串改成</h1>
结尾就能看出效果看到\1了吗?原本那个位置应该是[1-6],但是我们写的是\1,我们之前说过,转义符\干的活就是把特殊的字符转成一般的字符,把一般的字符转成特殊字符。普普通通的数字1被转移成什么了呢?在这里1表示第一个子表达式,也就是说,它是动态的,是随着前面第一个子表达式的匹配到的东西而变化的。比方说前面的子表达式内是[1-6],在实际字符串中找到了1,那么后面的\1就是1,如果前面的子表达式在实际字符串中找到了2,那么后面的\1就是2。
类似的,\2,\3,....就代表第二个第三个子表达式。
所以回溯引用是正则表达式内的一个“动态”的正则表达式,让你根据实际的情况变化进行匹配。
中级篇就到这里,其实正则表达式还有很多细节还没有写出来,也有很多元字符我没有交代,但掌握了纲要,懂得原理之后剩下的就类似于查表构造这种活了。
建议看到这的朋友看看《正则表达式必知必会》,初级篇和这篇中有几个例子也是取材于此。
转--python之正则入门的更多相关文章
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python学习--01入门
Python学习--01入门 Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.和PHP一样,它是后端开发语言. 如果有C语言.PHP语言.JAVA语言等其中一种语言的基础,学习Py ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python不完全入门指南
适用范围: 有一定编程基础,想快速入门python的人群 说明: 使用jupyter notebook编写,可以使用nbviewer网站进行查看. Python不完全入门指南 项目放在github上, ...
- 【Python爬虫】入门知识
爬虫基本知识 这阵子需要用爬虫做点事情,于是系统的学习了一下python爬虫,觉得还挺有意思的,比我想象中的能干更多的事情,这里记录下学习的经历. 网上有关爬虫的资料特别多,写的都挺复杂的,我这里不打 ...
- python re 正则
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- Python第一天——入门Python(1)数据定义
数据类型: 什么是数据? 在计算机科学中,数据是指所有能输入到计算机并被计算机程序处理的符号的介质的总称,是用于输入电子计算机进行处理,具有一定意义的数字字母.符号和模拟量等的统称.现在计算机存储和处 ...
- Python系列之入门篇——HDFS
Python系列之入门篇--HDFS 简介 HDFS (Hadoop Distributed File System) Hadoop分布式文件系统,具有高容错性,适合部署在廉价的机器上.Python ...
随机推荐
- Fuck me 忘记改REDO 造成复制用户超级慢
. 一个用户的测试环境, 想着复制用户进行功能和单点性能测试. 但是用户数据量较大,见图 2. 发现在测试环境里面复制一个用户 大概耗时2小时20min的时间, 测试虚拟机的配置: 最开始注意到awr ...
- centos7 tar.xz格式文件的解压方法
现在很多找到的软件都是tar.xz的格式的,xz 是一个使用 LZMA压缩算法的无损数据压缩文件格式. 和gzip与bzip2一样,同样支持多文件压缩,但是约定不能将多于一个的目标文件压缩进同一个档案 ...
- k8s 1.9 安装
测试环境 主机 系统 master CentOS 7.3 node CentOS 7.3 2.关闭selinux(所有节点都执行) [root@matser ~]# getenforce Disabl ...
- ABP框架学习
一.总体与公共结构 1,ABP配置 2,多租户 3,ABP Session 4,缓存 5,日志 6,设置管理 7,Timing 8,ABPMapper 9,发送电子邮件 二.领域层 10,实体 11, ...
- Python——多进程
进程的实例 # -*- coding:UTF-8 -*- import os import time from multiprocessing import Process #进程 def func( ...
- Python调用C++类
http://blog.csdn.net/liyuan_669/article/details/25361655 C++导出类到Python http://blog.csdn.net/arnozhan ...
- Hadoop 入门
我看过的比较全的文章.赞一下 原文链接:http://www.aboutyun.com/thread-8329-1-1.html 问题导读: 1.hadoop编程需要哪些基础?2.hadoop编程需要 ...
- MT【25】切线不等式原理及例题
评:切线不等式和琴生(Jesen)不等式都是有其几何意义的,在对称式中每一项单变量后利用图像的凹凸性得到一个线性的关系式.已知的条件往往就是线性条件,从而可以得到最值.
- emwin之点击窗口的无效部分来实现一些功能
@2018-07-27 触摸屏幕窗口的无效部分实现 Dropdown 部件的折叠操作 > 具体代码 case WM_TOUCH: if (pMsg->Data.p) // Somethin ...
- 洛谷 P1450.硬币购物 解题报告
P1450.硬币购物 题目描述 硬币购物一共有\(4\)种硬币.面值分别为\(c1,c2,c3,c4\).某人去商店买东西,去了\(tot\)次.每次带\(d_i\)枚\(c_i\)硬币,买\(s_i ...