时间序列模式(ARIMA)---Python实现
时间序列分析的主要目的是根据已有的历史数据对未来进行预测。如餐饮销售预测可以看做是基于时间序列的短期数据预测, 预测的对象时具体菜品的销售量。
1.时间序列算法:
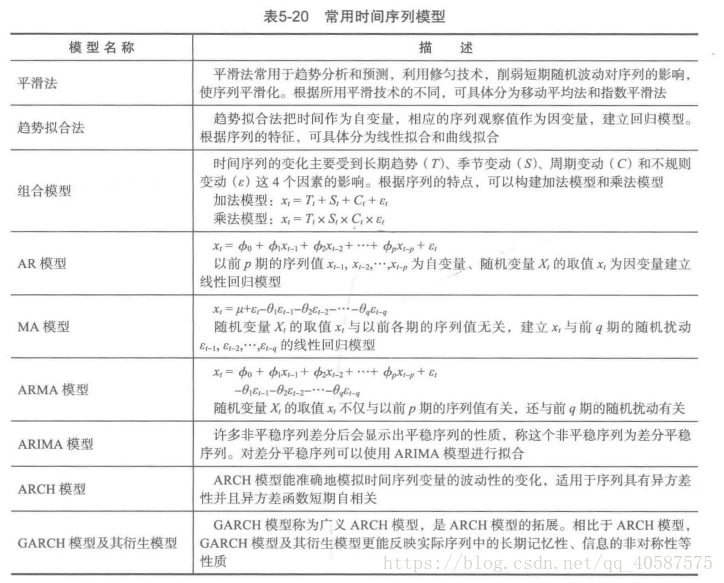
常见的时间序列模型;

2.时序模型的预处理
1. 对于纯随机序列,也称为白噪声序列,序列的各项之间没有任何的关系, 序列在进行完全无序的随机波动, 可以终止对该序列的分析。
2. 对于平稳非白噪声序列, 它的均值和方差是常数。ARMA 模型是最常用的平稳序列拟合模型。
3. 对于非平稳序列, 由于它的方差和均值不稳定, 处理方法一般是将其转化成平稳序列。 可以使用ARIMA 模型进行分析。
对平稳性的检验:
1.时序图检验:根据平稳时间序列的均值和方差都是常数的特性,平稳序列的时序图显示该序列值时钟在一个参数附近随机波动,而且波动的范围是有界的。如果有明显的趋势或者周期性, 那它通常不是平稳序列。
2.自相关图检验:平稳序列具有短期相关性, 这个性质表明对平稳序列而言, 通常 只有近期的序列值得影响比较明显, 间隔越远的过去值对现在的值得影响越小。 而非平稳序列的自相关系数衰减的速度比较慢。
3.单位根检验:单位根检验是指检验序列中是否存在单位根, 如果存在单位根, 那就是非平稳时间序列。 目前最常用的方法就是单位根检验。
原假设是 非平稳序列过程, 备择假设是 平稳序列, 趋势平稳过程
3.时间序列分析:
•平稳性:
•平稳性要求经由样本时间序列所得到的拟合曲线,在未来一段时间内仍然沿着现有的形态‘惯性’地延续下去。
•平稳性要求序列的均值和方差不发生明显的变化。
•弱平稳:期望和相关系数(依赖性)不变,未来某个时刻t 的值,Xt 要依赖于它过去的信息。
•差分法:时间序列在 T 与 T-1 时刻的差值(使用差分使其满足平稳性),一般差分1,2 阶就可以了。
•AR(自回归模型):
•描述当前值与历史值之间的关系, 用变量自身的历史时间数据对自身进行预测。自回归模型必须满足平稳性的要求。
公式定义:



自回归模型的限制:
1.自回归模型是使用自身的数据进行预测的
2.必须具有平稳性
3.必须具有相关性,如果相关性小于 0.5 , 则不宜使用
4.自回归模型只适用于预测与自身前期相关的预测。
•MA(移动平均模型):
•移动平均模型关注的是自回归模型中的误差项的累加
•移动平均法能有效地消除预测中的随机波动。

•ARMA(自回归平均模型):
•自回归和移动平均的结合。
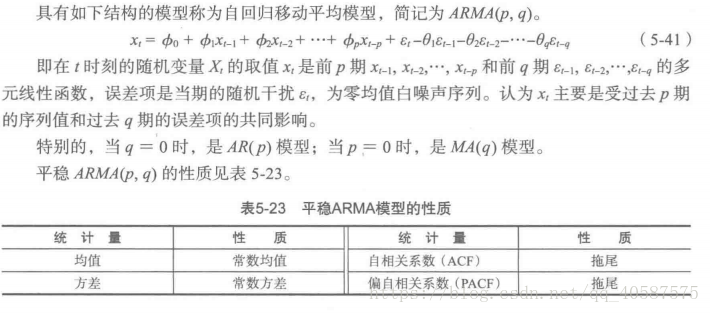
•ARIMA(p,d,q)差分自回归移动平均模型(Autoregressive Integrated Moving Average Model ,简称ARIMA)
•AR 是自回归, p 是自回归项, MA 是移动平均, q 为移动平均项, d 为时间序列称为平稳时 所做的差分次数。
•原理: 将非平稳时间序列转换成平稳时间序列, 然后将因变量仅对它的滞后值(p阶)以及随机误差项的现值和滞后值进行回顾所建立的模型。
•ARIMA 建模流程:
•1.将序列平稳化(差分法确定 d)
•2.p 和 q 阶数的确定(ACF 和 PACF 确定)
•3.建立模型 ARIMA (p , d , q )

使用ARIMA 模型对某餐厅的销售数据进行预测
#使用ARIMA 模型对非平稳时间序列进行建模操作
#差分运算具有强大的确定性的信息提取能力, 许多非平稳的序列差分后显示出平稳序列的性质, 这是称这个非平稳序列为差分平稳序列。
#对差分平稳序列可以还是要ARMA 模型进行拟合, ARIMA 模型的实质就是差分预算与 ARMA 模型的结合。
#coding=gbk
#使用ARIMA 模型对非平稳时间序列记性建模操作
#差分运算具有强大的确定性的信息提取能力, 许多非平稳的序列差分后显示出平稳序列的性质, 这是称这个非平稳序列为差分平稳序列。
#对差分平稳序列可以还是要ARMA 模型进行拟合, ARIMA 模型的实质就是差分预算与 ARMA 模型的结合。
#导入数据
import pandas as pd
filename = r'D:\datasets\arima_data.xls'
data = pd.read_excel(filename, index_col = u'日期')
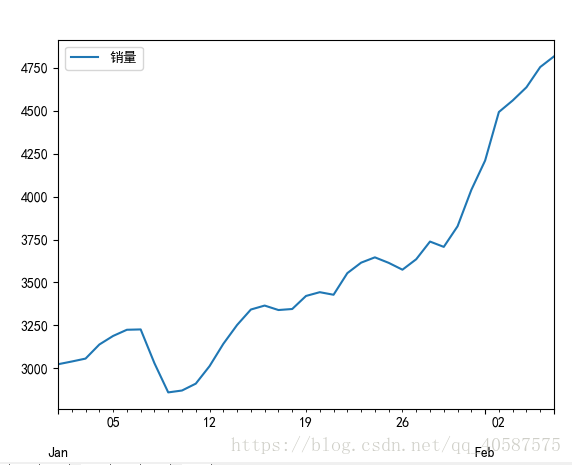
#画出时序图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #定义使其正常显示中文字体黑体
plt.rcParams['axes.unicode_minus'] = False #用来正常显示表示负号
# data.plot()
# plt.show()
#画出自相关性图
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
# plot_acf(data)
# plt.show()
#平稳性检测
from statsmodels.tsa.stattools import adfuller
print('原始序列的检验结果为:',adfuller(data[u'销量']))
#原始序列的检验结果为: (1.8137710150945268, 0.9983759421514264, 10, 26, {'1%': -3.7112123008648155,
# '10%': -2.6300945562130176, '5%': -2.981246804733728}, 299.46989866024177)
#返回值依次为:adf, pvalue p值, usedlag, nobs, critical values临界值 , icbest, regresults, resstore
#adf 分别大于3中不同检验水平的3个临界值,单位检测统计量对应的p 值显著大于 0.05 , 说明序列可以判定为 非平稳序列
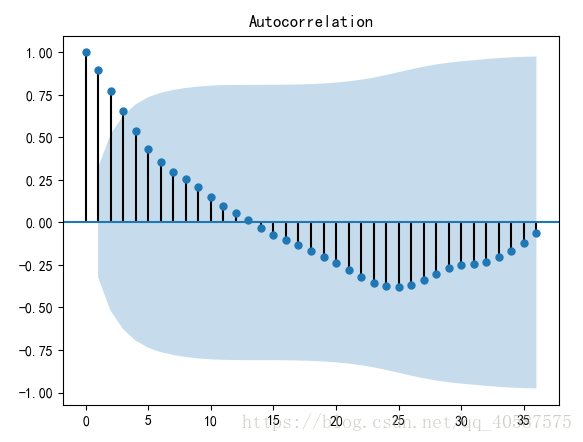
#对数据进行差分后得到 自相关图和 偏相关图
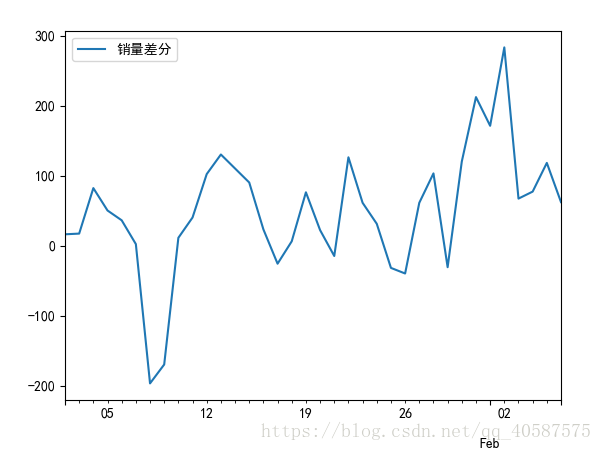
D_data = data.diff().dropna()
D_data.columns = [u'销量差分']
D_data.plot() #画出差分后的时序图
# plt.show()
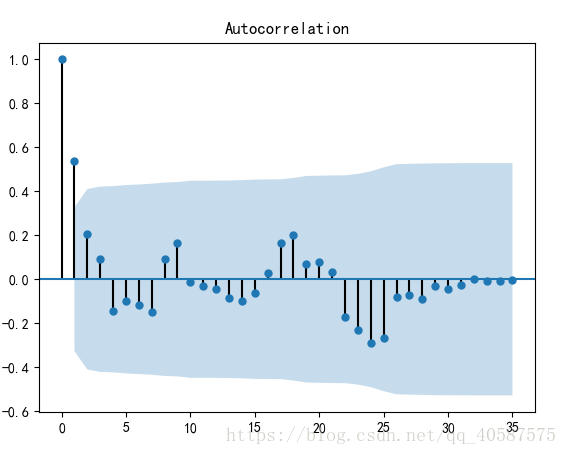
plot_acf(D_data) #画出自相关图
# plt.show()
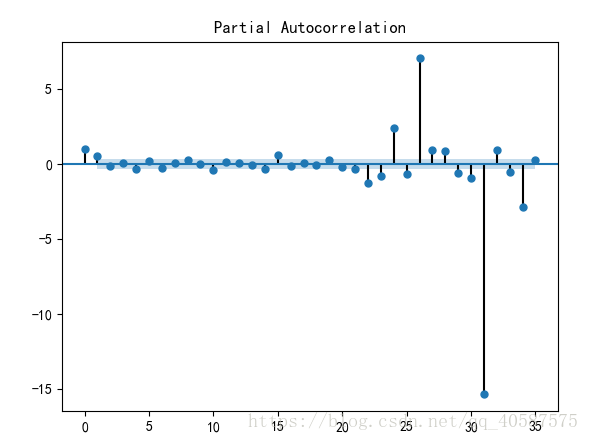
plot_pacf(D_data) #画出偏相关图
# plt.show()
print(u'差分序列的ADF 检验结果为: ', adfuller(D_data[u'销量差分'])) #平稳性检验
#差分序列的ADF 检验结果为: (-3.1560562366723537, 0.022673435440048798, 0, 35, {'1%': -3.6327426647230316,
# '10%': -2.6130173469387756, '5%': -2.9485102040816327}, 287.5909090780334)
#一阶差分后的序列的时序图在均值附近比较平稳的波动, 自相关性有很强的短期相关性, 单位根检验 p值小于 0.05 ,所以说一阶差分后的序列是平稳序列
#对一阶差分后的序列做白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
print(u'差分序列的白噪声检验结果:',acorr_ljungbox(D_data, lags= 1)) #返回统计量和 p 值
# 差分序列的白噪声检验结果: (array([11.30402222]), array([0.00077339])) p值为第二项, 远小于 0.05
#对模型进行定阶
from statsmodels.tsa.arima_model import ARIMA
pmax = int(len(D_data) / 10) #一般阶数不超过 length /10
qmax = int(len(D_data) / 10)
bic_matrix = []
for p in range(pmax +1):
temp= []
for q in range(qmax+1):
try:
temp.append(ARIMA(data, (p, 1, q)).fit().bic)
except:
temp.append(None)
bic_matrix.append(temp)
bic_matrix = pd.DataFrame(bic_matrix) #将其转换成Dataframe 数据结构
p,q = bic_matrix.stack().idxmin() #先使用stack 展平, 然后使用 idxmin 找出最小值的位置
print(u'BIC 最小的p值 和 q 值:%s,%s' %(p,q)) # BIC 最小的p值 和 q 值:0,1
#所以可以建立ARIMA 模型,ARIMA(0,1,1)
model = ARIMA(data, (p,1,q)).fit()
model.summary2() #生成一份模型报告
model.forecast(5) #为未来5天进行预测, 返回预测结果, 标准误差, 和置信区间
利用模型向前预测的时期越长, 预测的误差就会越大,这是时间预测的典型特点。
时间序列模式(ARIMA)---Python实现的更多相关文章
- 时间序列模式——ARIMA模型
ARIMA模型全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA),是由博克思(Box)和詹金斯(Jenkins ...
- 我用了半年的时间,把python学到了能出书的程度
Python难学吗?不难,我边做项目边学,过了半年就通过了出版社编辑的面试,接到了一本Python选题,并成功出版. 有同学会说,你有编程基础外带项目实践机会,所以学得快.这话不假,我之前的基础确实加 ...
- Python获取当前时间 分类: python 2014-11-08 19:02 132人阅读 评论(0) 收藏
Python有专门的time模块可以供调用. <span style="font-size:14px;">import time print time.time()&l ...
- Python小任务 - 如何编写指定时间执行的Python小程序
我们在平时的工作中经常会遇到这样的需求,需要再某个时间点执行一段程序逻辑. 那么,在python中我们是怎么做的呢? 下面看代码: waitDesignatedTimeToRun.py import ...
- 算法导论 第八章 线性时间排序(python)
比较排序:各元素的次序依赖于它们之间的比较{插入排序O(n**2) 归并排序O(nlgn) 堆排序O(nlgn)快速排序O(n**2)平均O(nlgn)} 本章主要介绍几个线性时间排序:(运算排序非比 ...
- ansible执行playbook时间显示的python脚本
import datetime import os import time from ansible.plugins.callback import CallbackBase class Callba ...
- 剑指offer-最小的K个数-时间效率-排序-python
题目描述 输入n个整数,找出其中最小的K个数.例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,. 这就是排序题(将结果的最小K值输出) # -*- coding ...
- [python] 时间序列分析之ARIMA
1 时间序列与时间序列分析 在生产和科学研究中,对某一个或者一组变量 进行观察测量,将在一系列时刻 所得到的离散数字组成的序列集合,称之为时间序列. 时间序列分析是根据系统观察得到的时间序列数据, ...
- python解无忧公主的数学时间097.py
python解无忧公主的数学时间097.py """ python解无忧公主的数学时间097.py codegay 2016年3月30日 00:17:26 http:// ...
随机推荐
- 170825、SolrCloud 分布式集群部署步骤
安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux 环境的 64位 软件,以上软件请到各自的 ...
- 将GitLab数据库从阿里云PostgreSQL RDS迁移至自建的PostgreSQL服务器
阿里云RDS目前支持的是PostgreSQL 9.4,而gitlab支持的最低版本是PostgreSQL 9.6.1,不升级PostgreSQL,gitlab就无法升级,阿里云RDS短期内不进行升级, ...
- wpf中的数据模板
wpf中的模板分为数据模板和控件模板,我们可以通过我们自己定制的数据模板来制定自己想要的数据表现形式.例如:时间的显示可以通过图片,也可以通过简单数字表现出来. 例如: (1)先在Demo这个命名空间 ...
- day0321正则表达式
一.正则表达式 1.定义一个规则,检测某一段字符串是否符合规则,将符合规则的字符匹配出来. 2.只和字符串相关 3.字符组 描述一个字符位置的内容 3.1 [012345]检测0,1,2,3,4 ...
- LeetCode 973 K Closest Points to Origin 解题报告
题目要求 We have a list of points on the plane. Find the K closest points to the origin (0, 0). (Here, ...
- django--验证码功能实现
首先建立验证码的视图函数1需要安装pillow库 #导入绘图库 from PIL import ImageDraw #导入绘图字体库 from PIL import ImageFont #导入图片库 ...
- 获取链接的参数,判断是否是微信打开,ajax获取数据
//获取链接参数function GetQueryString(name) { var reg = new RegExp("(^|&)" + name + " ...
- Feature如何解决参数数量不匹配
问题描述: Feature 写了两个参数,匹配到Steps.Java, 文件只写了两个参数,但是两个参数都加了$ 符号. 而$ 又是结束的意思. 1一:Feature 用例
- 【PyQt5-Qt Designer】文本框读写操作
主要内容: 1.读.写 输入控件(Input Widgets)中的内容(str) 2.保存数据到txt文件 3.从txt文件中读内容,与输入控件中内容比较 将上述各种输入控件(Input Widget ...
- js中常用的offset client screen对象
javascript中offsetWidth.clientWidth.width.scrollWidth.clientX.screenX.offsetX.pageX offsetWidth //返回元 ...