Python+Selenium框架设计之框架内封装基类和实现POM
原文地址https://blog.csdn.net/u011541946/article/details/70269965
作者:Anthony_tester
来源:CSDN 博客地址https://blog.csdn.net/u011541946
前面文章,我们实现了框架的一部分功能,包括日志类和浏览器引擎类的封装,今天我们继续封装一个基类和介绍如何实现POM。关于基类,是这样定义的:把一些常见的页面操作的selenium封装到base_page.py这个类文件,以后每个POM中的页面类,都继承这个基类,这样每个页面类都有基类的方法,这个我们会在这篇文章实现。
1. 在实现封装基类里,我们实现了元素八大方式的定位和截图类封装。具体项目层级结构如下图。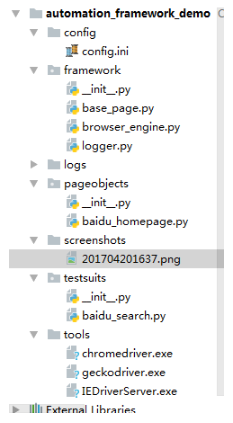
2. 基类base_page.py的具体实现代码,这里就封装了几个常用方法,其他方法,你自己去练习封装下。
# coding=utf-8
import time
from selenium.common.exceptions import NoSuchElementException
import os.path
from framework.logger import Logger # create a logger instance
logger = Logger(logger="BasePage").getlog() class BasePage(object):
"""
定义一个页面基类,让所有页面都继承这个类,封装一些常用的页面操作方法到这个类
""" def __init__(self, driver):
self.driver = driver # quit browser and end testing
def quit_browser(self):
self.driver.quit() # 浏览器前进操作
def forward(self):
self.driver.forward()
logger.info("Click forward on current page.") # 浏览器后退操作
def back(self):
self.driver.back()
logger.info("Click back on current page.") # 隐式等待
def wait(self, seconds):
self.driver.implicitly_wait(seconds)
logger.info("wait for %d seconds." % seconds) # 点击关闭当前窗口
def close(self):
try:
self.driver.close()
logger.info("Closing and quit the browser.")
except NameError as e:
logger.error("Failed to quit the browser with %s" % e) # 保存图片
def get_windows_img(self):
"""
在这里我们把file_path这个参数写死,直接保存到我们项目根目录的一个文件夹.\Screenshots下
"""
file_path = os.path.dirname(os.path.abspath('.')) + '/screenshots/'
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
screen_name = file_path + rq + '.png'
try:
self.driver.get_screenshot_as_file(screen_name)
logger.info("Had take screenshot and save to folder : /screenshots")
except NameError as e:
logger.error("Failed to take screenshot! %s" % e)
self.get_windows_img() # 定位元素方法
def find_element(self, selector):
"""
这个地方为什么是根据=>来切割字符串,请看页面里定位元素的方法
submit_btn = "id=>su"
login_lnk = "xpath => //*[@id='u1']/a[7]" # 百度首页登录链接定位
如果采用等号,结果很多xpath表达式中包含一个=,这样会造成切割不准确,影响元素定位
:param selector:
:return: element
"""
element = ''
if '=>' not in selector:
return self.driver.find_element_by_id(selector)
selector_by = selector.split('=>')[0]
selector_value = selector.split('=>')[1] if selector_by == "i" or selector_by == 'id':
try:
element = self.driver.find_element_by_id(selector_value)
logger.info("Had find the element \' %s \' successful "
"by %s via value: %s " % (element.text, selector_by, selector_value))
except NoSuchElementException as e:
logger.error("NoSuchElementException: %s" % e)
self.get_windows_img() # take screenshot
elif selector_by == "n" or selector_by == 'name':
element = self.driver.find_element_by_name(selector_value)
elif selector_by == "c" or selector_by == 'class_name':
element = self.driver.find_element_by_class_name(selector_value)
elif selector_by == "l" or selector_by == 'link_text':
element = self.driver.find_element_by_link_text(selector_value)
elif selector_by == "p" or selector_by == 'partial_link_text':
element = self.driver.find_element_by_partial_link_text(selector_value)
elif selector_by == "t" or selector_by == 'tag_name':
element = self.driver.find_element_by_tag_name(selector_value)
elif selector_by == "x" or selector_by == 'xpath':
try:
element = self.driver.find_element_by_xpath(selector_value)
logger.info("Had find the element \' %s \' successful "
"by %s via value: %s " % (element.text, selector_by, selector_value))
except NoSuchElementException as e:
logger.error("NoSuchElementException: %s" % e)
self.get_windows_img()
elif selector_by == "s" or selector_by == 'selector_selector':
element = self.driver.find_element_by_css_selector(selector_value)
else:
raise NameError("Please enter a valid type of targeting elements.") return element # 输入
def type(self, selector, text): el = self.find_element(selector)
el.clear()
try:
el.send_keys(text)
logger.info("Had type \' %s \' in inputBox" % text)
except NameError as e:
logger.error("Failed to type in input box with %s" % e)
self.get_windows_img() # 清除文本框
def clear(self, selector): el = self.find_element(selector)
try:
el.clear()
logger.info("Clear text in input box before typing.")
except NameError as e:
logger.error("Failed to clear in input box with %s" % e)
self.get_windows_img() # 点击元素
def click(self, selector): el = self.find_element(selector)
try:
el.click()
logger.info("The element \' %s \' was clicked." % el.text)
except NameError as e:
logger.error("Failed to click the element with %s" % e) # 或者网页标题
def get_page_title(self):
logger.info("Current page title is %s" % self.driver.title)
return self.driver.title @staticmethod
def sleep(seconds):
time.sleep(seconds)
logger.info("Sleep for %d seconds" % seconds)
3. 页面对象中,百度主页的元素定位和简单的操作函数,页面类主要是元素定位和页面操作写成函数,供测试类调用。
baidu_homepage.py
# coding=utf-8
from framework.base_page import BasePage class HomePage(BasePage): input_box = "id=>kw"
search_submit_btn = "xpath=>//*[@id='su']" def type_search(self, text):
self.type(self.input_box, text) def send_submit_btn(self):
self.click(self.search_submit_btn)
这里注意下元素定位写法,=>和base_page.py中find_element()方法元素定位切割有关系,网上有些人写根据逗号切割或者等号切割,在实际使用xpath定位,发现单独逗号或者单独等号切割都不精确,造成元素定位失败。
4. 测试类的写法举例
# coding=utf-8
import time
import unittest
from framework.browser_engine import BrowserEngine
from pageobjects.baidu_homepage import HomePage class BaiduSearch(unittest.TestCase): def setUp(self):
"""
测试固件的setUp()的代码,主要是测试的前提准备工作
:return:
"""
browse = BrowserEngine(self)
self.driver = browse.open_browser(self) def tearDown(self):
"""
测试结束后的操作,这里基本上都是关闭浏览器
:return:
"""
self.driver.quit() def test_baidu_search(self):
"""
这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。
:return:
"""
homepage = HomePage(self.driver)
homepage.type_search('selenium') # 调用页面对象中的方法
homepage.send_submit_btn() #调用页面对象类中的点击搜索按钮方法
time.sleep(2)
homepage.get_windows_img() # 调用基类截图方法
try:
assert 'selenium' in homepage.get_page_title() # 调用页面对象继承基类中的获取页面标题方法
print ('Test Pass.')
except Exception as e:
print ('Test Fail.', format(e)) if __name__ == '__main__':
unittest.main()
homepage = HomePage(self.driver)
上面这行代码要注意,意思是,到一个页面,第一件事情是初始化这个页面的一个页面对象实例。注意,一定要带self.driver,不然会报错,这个self.driver,可以这样理解:在当前测试类里面,self.driver是来自浏览器引擎类中方法得到的,在初始化一个页面对象的时候,也把这个来自浏览器引擎类的driver给赋值给当前的页面对象,这样,才能执行页面对象或者基类里面的相关driver方法。写多了selenium的自动化脚本,你会明白,最重要的是保持前后driver的唯一性。
测试结果:会在logs文件夹生成一个日志文件,也会在screenshots文件夹生成一个png图片。
Python+Selenium框架设计之框架内封装基类和实现POM的更多相关文章
- 无线客户端框架设计(3):基类的设计(iOS篇)
本文代码:YoungHeart-Chapter-03.zip 没有基类的App都不是好App. 因为iOS使用的是mvc模式的开发模式,所以,业务逻辑基本都在每个页面相应的ViewController ...
- Python+selenium+unittest+HTMLTestReportCN单元测试框架分享
分享一个比较基础的,系统性的知识点.Python+selenium+unittest+HTMLTestReportCN单元测试框架分享 Unittest简介 unittest是Python语言的单元测 ...
- Python+Selenium中级篇之8-Python自定义封装一个简单的Log类《转载》
Python+Selenium中级篇之8-Python自定义封装一个简单的Log类: https://blog.csdn.net/u011541946/article/details/70198676
- 微信公众号开发系列-Http请求封装基类
HttpHelper请求封装基类,支持get请求和POS请求,方便微信开发接口交互,为后面接口交互做准备. 1.HttpHelper帮助基类 [csharp] view plaincopy using ...
- Http请求封装基类HttpHelper.cs
HttpHelper请求封装基类,支持get请求和POS请求http接口交互,为后面接口交互做准备. 1.HttpHelper帮助基类 using System; using System.Colle ...
- 基于PO和单例设计模式用python+selenium进行ui自动化框架设计
一)框架目录的结构 二)config包当中的config.ini文件主要是用来存项目的绝对路径,是为了后续跑用例和生成测试报告做准备然后目前的配置文件大都会用yaml,ini,excel,还有.py也 ...
- python3+requests库框架设计03-请求重新封装
在完成了日志类封装之后,那我们就要对测试基类进行实现,在其中对一些请求再次封装,在项目下新建一个Common文件夹,在文件夹下新建Base_test.py文件,项目结构如下. 具体怎么封装还是要看被测 ...
- .NET框架设计(高级框架架构模式)—钝化程序、逻辑冻结、冻结程序的延续、瞬间转移
阅读目录: 1.开篇介绍 2.程序书签(代码书签机制) 2.1ProgramBookmark 实现(使用委托来锚点代码书签) 2.2ProgramBookmarkManager书签管理器(对象化书签集 ...
- Python&Selenium 关键字驱动测试框架之数据文件解析
摘要:在关键字驱动测试框架中,除了PO模式以及一些常规Action的封装外,一个很重要的内容就是读写EXCEL,在团队中如何让不会写代码的人也可以进行自动化测试? 我们可以将自动化测试用例按一定的规格 ...
随机推荐
- 联想y720 淋了雨,字体变得模糊了
显卡驱动没有问题 重新校准显示器问题解决 事实上,可能是某些软件 扰乱了系统字体,请安装上述来重新调整显示器的字体清晰度
- BZOJ 1150 - 数据备份Backup - [小顶堆][CTSC2007]
题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=1150 Time Limit: 10 Sec Memory Limit: 162 M De ...
- 安装MAC的ReactNative环境
brew install node brew install watchman npm config set registry https://registry.npm.taobao.org --gl ...
- Hystrix在项目中实践
Hystrix在项目中实践 https://mp.weixin.qq.com/s/4Fg0COnWRB3rRWfxbJt7gA
- PHP之引用
php数字月份转换为英语缩写 实现数字月份到英文月份缩写的转换 英语 1 => 'Jan', January 2 => 'Feb', February 3 => 'Mar', Mar ...
- 2016年蓝桥杯省赛A组c++第7题(图论)
/* 有12张连在一起的12生肖的邮票,规格是3*4,即: 1111 1111 1111 现在你要从中剪下5张来,要求必须是连着的.(仅仅连接一个角不算相连) */ /* 思路: 先将所有五个一组的情 ...
- 树和二叉树->最优二叉树
文字描述 结点的路径长度 从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径,路径上的分支数目称作路径长度. 树的路径长度 从树根到每一个结点的路径长度之和叫树的路径长度. 结点的带权路径长 ...
- SQL server 2005数据库的还原与备份
一.SQL数据库的备份: 1.依次打开 开始菜单 → 程序 → Microsoft SQL Server 2005→SQL Server Management Studio ,这里我以UMVTEST命 ...
- oracle中not in 和 in 的替代写法
-- not in 的替代写法select col from table1 where col not in(select col from table2); select col,table2.co ...
- 五、Docker
1.简介 Docker是一个开源的应用容器引擎:是一个轻量级容器技术: Docker支持将软件编译成一个镜像:然后在镜像中各种软件做好配置,将镜像发布出去,其他使用者可以直接使用这个镜像: 运行中的这 ...