embedding与word2vec
embedding与word2vec的更多相关文章
- Embedding和Word2Vec实战
在之前的文章中谈到了文本向量化的一些基本原理和概念,本文将介绍Word2Vec的代码实现 https://www.cnblogs.com/dogecheng/p/11470196.html#Word2 ...
- Word Embedding与Word2Vec
http://blog.csdn.net/baimafujinji/article/details/77836142 一.数学上的“嵌入”(Embedding) Embed这个词,英文的释义为, fi ...
- 无所不能的Embedding 1 - Word2vec模型详解&代码实现
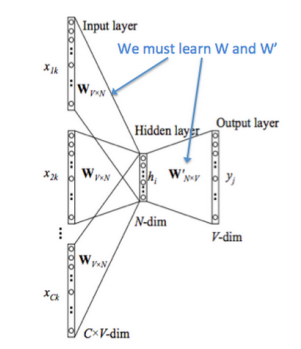
word2vec是google 2013年提出的,从大规模语料中训练词向量的模型,在许多场景中都有应用,信息提取相似度计算等等.也是从word2vec开始,embedding在各个领域的应用开始流行, ...
- word2vec和word embedding有什么区别?
word2vec和word embedding有什么区别? 我知道这两个都能将词向量化,但有什么区别?这两个术语的中文是什么? from: https://www.zhihu.com/question ...
- 学习笔记CB011:lucene搜索引擎库、IKAnalyzer中文切词工具、检索服务、查询索引、导流、word2vec
影视剧字幕聊天语料库特点,把影视剧说话内容一句一句以回车换行罗列三千多万条中国话,相邻第二句很可能是第一句最好回答.一个问句有很多种回答,可以根据相关程度以及历史聊天记录所有回答排序,找到最优,是一个 ...
- Word Embedding理解
一直以来感觉好多地方都吧Word Embedding和word2vec混起来一起说,所以导致对这俩的区别不是很清楚. 其实简单说来就是word embedding包含了word2vec,word2ve ...
- tensorflow加载embedding模型进行可视化
1.功能 采用python的gensim模块训练的word2vec模型,然后采用tensorflow读取模型可视化embedding向量 ps:采用C++版本训练的w2v模型,python的gensi ...
- PaperWeekly 第五期------从Word2Vec到FastText
PaperWeekly 第五期------从Word2Vec到FastText 张俊 10 个月前 引 Word2Vec从提出至今,已经成为了深度学习在自然语言处理中的基础部件,大大小小.形形色色的D ...
- 无所不能的embedding 3. word2vec->Doc2vec[PV-DM/PV-DBOW]
这一节我们来聊聊不定长的文本向量,这里我们暂不考虑有监督模型,也就是任务相关的句子表征,只看通用文本向量,根据文本长短有叫sentence2vec, paragraph2vec也有叫doc2vec的. ...
随机推荐
- Oracle 基本操作--数据类型、修改和删除表、增删改查和复制表
一.Oracle基础数据类型:数据类型: 创建数据表时,设计数据表的结构问题,也就是设计及确定数据表中各个列的数据类型,是数值.字符.日期还是图像等其他类型. 因为只有设计好数据表结构,系统才会在磁盘 ...
- java getInstance()的使用
转自:https://www.cnblogs.com/roadone/p/7977544.html 对象的实例化方法,也是比较多的,最常用的方法是直接使用new,而这是最普通的,如果要考虑到其它的需要 ...
- 27. Remove Element C++移除元素
网址:https://leetcode.com/problems/remove-element/ 双指针(广义) class Solution { public: int removeElement( ...
- lua 函数基础
函数定义在前,调用在后 如果函数只有一个实参,并且此参数是一个字面字符串或者table构造式,那么可以省略() 例如 print "hello" unpack{1,2} print ...
- 【LeetCode】最大子序列和
要求时间复杂度 O(n). e.g. 给定数组 [-2,1,-3,4,-1,2,1,-5,4],其中有连续子序列 [4,-1,2,1] 和最大为 6. 我完全没有想法,看了答案. C++实现: int ...
- Vue + webpack 项目配置化、接口请求统一管理
准备工作 需求由来: 当项目越来越大的时候提高项目运行编译速度.压缩代码体积.项目维护.bug修复......等等成为不得不考虑而且不得不做的问题. 又或者后面其他同事接手你的模块,或者改你的bug ...
- A Bug's Life(向量偏移)
A Bug's Life Time Limit : 15000/5000ms (Java/Other) Memory Limit : 32768/32768K (Java/Other) Total ...
- 常用的flex知识 ,比起float position 好用不少
flex布局具有便捷.灵活的特点,熟练的运用flex布局能解决大部分布局问题,这里对一些常用布局场景做一些总结. web页面布局(topbar + main + footbar) 示例代码 要 ...
- 原 spring-boot工程中,jpa下hibernate的ddl-auto的各种属性
jpa: hibernate: ddl-auto: create ddl-auto:create----每次运行该程序,没有表格会新建表格,表内有数据会清空 ddl-auto:create-d ...
- ubuntu 挂载虚拟机vdi文件
sudo apt-get install nbd-server nbd-client qemu-kvm # rmmod nbd # modprobe nbd max_part=8 # qemu- ...