A Simple Note on "P4FPGA: A Rapid Prototyping Framework for P4"
论文:P4FPGA: A Rapid Prototyping Framework for P4
Github:https://github.com/p4fpga
Reference: Han Wang, Robert Soule ́, Huynh Tu Dang, Ki Suh Lee, Vishal Shrivastav, Nate Foster, and Hakim Weatherspoon. 2017. P4FPGA : A Rapid Prototyping Framework for P4. In Proceedings of ACM Symposium on SDN Research conference, Santa Clara, California USA, April 2017 (SOSR 2017), 14 pages.
A Simple Note on "P4FPGA: A Rapid Prototyping Framework for P4"
Structure:
- Introduction, Background and Overview
- Code Generation
- Fixed-Function Runtime
- Optimization Principles
- Implementation and Evaluation
Introduction
P4语言的提出为网络领域带来了巨大的影响,编程人员可以通过P4实现一系列有意义的网络应用、协议等。
但是,当前大多数P4可编程的目标设备是以软件的形式实现的,开发人员需要在硬件上实现更高效的设计。在这方面,FPGA是更具吸引力的P4程序载体。作为一种形式的可重编程芯片,FPGA提供了软件的灵活性和硬件的性能。
而设计一款将P4语言转换为FPGA HDL代码的编译器面临着以下难点:
- FPGA主要通过低层次的、不可移植的代码库进行编程;此外,第三方处理设备之间的通信是设备特定的,具有不可移植性;
- 由于程序之间的差异性以及不同架构采取的不同负载策略,基于源P4代码生成高效的硬件代码实现是非常困难的;
- 虽然P4语言无感知底层硬件架构,但它依赖于一系列"extern"语法来导入外部实现的高效功能,这使代码生成变的更加复杂。
P4FPGA,灵活、高效、可移植的开源P4-to-FPGA编译器和runtime。为保证P4FPGA的灵活性,编译器允许用户导入使用不同语言编写的特定硬件模块。这种方法提供了在ASIC交换机上难以实现的灵活性。为保证生成代码的高效性,P4FPGA支持一或多个端口的数据通路,允许用户基于他们的特定应用选择最佳的设计。此外P4FPGA提供了基于设备无感知硬件抽象的runtime,保证P4FPGA支持往Xilinx或Altera FPGA上加载代码。
实验对不同的具有代表性的P4程序进行了验证,结果表明P4FPGA生成的代码能够在任意数据报大小的情况下达到线速,同时时延与商用ASIC交换机相似。P4FPGA已用于至少两个以上的科研项目。
总之,论文做出了以下贡献:
- 提出了P4FPGA编译器和运行时系统;
- 验证了生成代码和不同P4程序的后端的性能,并验证性能不输于商用交换机;
- 使用P4FPGA开发了一系列标准和网络应用,表明P4FPGA能够被广泛应用。
Code Generation
P4FPGA编译器的核心工作,是将用P4语言表达的逻辑数据报处理结构转换为用硬件描述语言表达的逻辑数据报处理结构。P4FPGA将生成的物理处理结构转换为一个个块block。在大多数编译器中,块对应于一系列的操作(查表,数据报操作原语等)。通过使用参数化的模板在P4FPGA中实现了这些基本块。在初始化的时候,这些模板是用于实现数据报解析器、流表、动作和逆解析器逻辑的硬件模块。
实现块主要有两个动机:
- 降低编译器的复杂性,代码生成本质上就是块的组合;
- 模块化设计从(1)程序员能够轻松通过外部函数接口新增外部定义的功能;(2)程序员可以通过替换相同功能的块来修改编译器 两个角度保证了拓展性。
P4代码的流控制程序对应于基本块的组合,将这些基本块的组合称为可编程数据报处理流水线,这与P4FPGA运行时系统实现的固化流水线相反,换句话说,可编程数据报处理流水线对应于特定P4源程序,而固化流水线受制于目标平台,对于所有输入程序都是一样的。
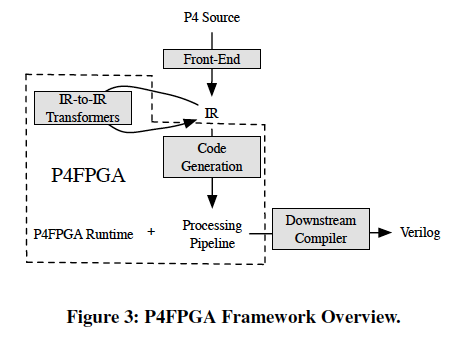
Programmable Pipeline
可编程的数据报处理流水线在FPGA硬件上实现了P4源程序的可编程逻辑。

Parsing
数据报的解析处理可以被抽象为有限状态机(Finite State Machine, FSM),由状态和转移组成。
对于一个给定的状态,FSM基于header或parser的输入进行解析状态转移。
一个状态的子集识别并解析首部字段,FSM图可以是无环的也可以是有环的。
P4FPGA采用数据流的方法将数据报字节输入FSM中,在有足够的数据解析首部或执行FSM转移的时候进行处理。
解析器基本块的实现包括适用于所有解析器实例的代码(包括状态变量,如数据报buffer,解析状态及偏移量,和管理输入字节的环路)以及解析器实例特定的代码(实现应用特定的FSM)。
Deparsing
输入:(1)存储于内存中的数据报,(2)可编程流水线修改过的数据报首部。逆解析器根据这两个输入重组数据报并转发。
类似于解析器,逆解析器也有一个FSM,但是由于要实现数据报首部的增添与删除,逆解析器的设计更加复杂。
逆解析器有以下三个模块:(1)数据报拓展器,(2)数据报合并器,(3)数据报压缩器。
- 数据报拓展器基于设计好的偏移量往数据报填充字节,支持数据报首部的添加;
- 数据报合并器对修改的数据报首部字段进行写操作,包括被数据报拓展器增加的首部;
- 数据报压缩器通过写位掩码将数据报的某些字节标记为非法。
注意:逆解析器负责进行数据报的修改操作。数据报的修改操作既可以在流水线中进行(一张流表处理完接着一张流表),或者在流水线的最后进行。为了提高效率,降低时延,P4FPGA采取后者。换句话说,可编程流水线对数据报的拷贝进行操作,逆解析器将这些操作合并到数据报中。
Matching
P4FPGA中实现流表的基本块被设计为支持数据流接口get/put访问的硬件模块,P4支持用户指定匹配数据报的算法。P4FPGA实现了两种:精确匹配和三元组匹配,三元组匹配使用了第三方的代码库。P4FPGA使用两种方法实现精确匹配,一种是通过CAM内存,另一种是通过基于hash的查找表。用户可以通过往编译器传入参数使用这两种方法。
由于P4向用户提供了"流表可编程"的抽象,一些流表可能只有动作,用于对 在该流水线阶段处理的每一个数据报 触发动作。P4FPGA不给该阶段分配任何流表资源。
Actions
P4的动作能够修改一个字段的值,移除、增加首部,或修改数据报的元数据。理论上,每一个动作在任意时间,根据暂时的元数据处理一个数据报。
P4FPGA实现对数据报元数据的内联(inline)编辑和对数据报首部的post-pipeline修改。修改动作创建一份存储于内存中的更新值拷贝,应用于逆解析器将操作合并到数据报时。
对于修改数据报长度的动作,基本块在实现逆解析器的块之前/之后创建,以实现重校准。比如,对于删除数据报首部的动作,实现逆解析器的块通过位掩码将删除的首部标记为非法,而之后的重校准块将剩余的字节覆盖在非法字节之上。
Control Flow
P4流控制程序在无环的情况下组织流表和动作。它的原始实现是采用固化的流水线设计,在该情况下,runtime会使用额外的元数据实现源程序的逻辑。但是由于实现目标是FPGA,P4FPGA能够将流控制逻辑直接映射到生成的硬件设计。每一个流控制节点对应于一个后接情况分支的基本块。因此我们注意到,在FPGA上实现流控制逻辑比硬件交换机更加灵活。
在程序执行阶段,解析后的数据报和元数据传入树结构。对于每一个节点,runtime评估情况并将数据传入合适的分支,或者基于控制平面API的规则执行查表。
P4FPGA依赖流水并行实现高吞吐,树结构的不同节点能够并行处理不同的数据报。
Control Plane API
P4FPGA生成控制平面API,提供C++函数,允许用户对流表项进行增删改查,读/写状态化内存。API也支持Debug。
External Functions
相比ASIC,FPGA的优点在于它们更加灵活和可编程。
P4提供了有限的编程接口来实现网络应用,并在设计上是平台无关的。因此有时需要实现额外的功能通过调用外部函数。比如校验和计算、加密、解密等。P4语言中是通过extern语法来声明和调用这些函数的,而这些调用和架构紧密相关。
P4FPGA允许用户自己通过HDL实现外部定义的函数,但是这样会对高效代码的生成造成影响,因为会造成高时延。比如,一个外部函数需要访问持续型的状态或者有很复杂的处理逻辑,那么就需要较长的时间等待完成。如果整个进程因为外部函数处理而阻塞,那么将大幅影响吞吐量。P4FPGA实现了异步的操作处理,保证操作是并行的,这类似于多进程,但是无需内容交换的额外开销。
Fixed-Function Runtime
P4FPGA固化功能的runtime为P4中的处理算法提供执行环境,它定义了允许生成代码通过目标无感知抽象访问通用功能的途径。因此,runtime扮演着相当重要的角色,它为数据报处理应用提供高效、灵活、可拓展的环境。
- 必须提供一个对于不同硬件平台都通用的抽象架构;
- 必须提供高效的中间媒介用于在不同处理组件之间传递数据;
- 必须提供辅助功能用于支持控制、监控和debug。
P4程序员可能会编写各式各样的网络应用,对runtime提出了不同的要求。为支持这些不同的用户场景,P4FPGA允许用户选择两种架构:
- multi-port switching: 适用于网络转发组件,比如交换机和路由器,以及测试新型网络协议;它使用一个512位的crossbar做出端口选择。
- bump-in-the-wire: 适用于网络功能和网络加速,只有一个入端口和一个出端口。
Memory Management
当数据报进入交换机时,它需要在内存中存储起来,有两种实现方法:
- 使用FIFO队列缓存数据报,缺点在于不利于实现先进的数据报处理特征,比如QoS(这些特征需要数据报重排序);
- P4FPGA通过内存管理单元MMU对可选内存buffer进行管理,MMU做了两个接口,一个malloc()一个free(),使用buffer分配的方法管理数据报。
Transceiver Management
P4FPGA是跨硬件平台的,因此提供了收发管理单元来保证runtime能使用平台特定的MAC层和物理层。
Host Communication
P4FPGA集成了主机通信通道与CPU进行通信,对于实现控制通道和debug非常有用。主机通信模块主要基于PCIe协议。P4FPGA在硬件和软件之间提供了阻塞和非阻塞两种RPC方法
Timing Closure
对于时序收敛问题,做了两个方面的处理:
- 使用流水FIFO保证parser的输入输出、流表和动作块是记录过的(registered);
- 优化动作引擎的设计和流控制的逻辑,在每个时钟周期实现简单的组合逻辑。
Optimization Principles
为保证P4FPGA生成代码具备高效性,在编译器层面和微架构层面基于以下信条实现了优化:
- 1.Leverage hardware parallelism in space and time to increase throughput.
- 2.Transform sequential semantics to parallel semantics to reduce latency.
- 3.Select the right architecture for the job.
- 4.Use a resource-efficient components to implement match tables.
- 5.Eliminate dead metadata
- 6.Use non-blocking access for external modules.
Implementation and Evaluation
A Simple Note on "P4FPGA: A Rapid Prototyping Framework for P4"的更多相关文章
- A Network in a Laptop: Rapid Prototyping for Software-Defined Networks
文章名称:A Network in a Laptop: Rapid Prototyping for Software-Defined Networks 文章来源:Lantz B , Heller B ...
- PaperRead - A Shader Framework for Rapid Prototyping of GPU-Based Volume Rendering
PaperRead - A Shader Framework for Rapid Prototyping of GPU-Based Volume Rendering 目录 PaperRead - A ...
- Axure RP = Axure Rapid Prototyping
不要一味追求高保真,特别是交互后产生动态数据.并且将动态数据交互传递出去,违背了做原型的初衷了. 自己做着玩追求高保真可以,有成就感. 但作为工作的话,效率优先.能简单直观地展示必要的交互效果即可.
- rapid js framework
allcountjs.com http://mean.io/ https://www.meteor.com/ http://sailsjs.org/#!/ nodejs 博客 http://hexo. ...
- Docker distrubution in django
https://www.syncano.io/blog/configuring-running-django-celery-docker-containers-pt-1/ Update: Fig ha ...
- Understanding Convolution in Deep Learning
Understanding Convolution in Deep Learning Convolution is probably the most important concept in dee ...
- 计算机视觉code与软件
Research Code A rational methodology for lossy compression - REWIC is a software-based implementatio ...
- 所有的GUI Toolkit,类型之多真开眼界
The GUI Toolkit, Framework Page User interfaces occupy an important part of software development. Th ...
- C++ 100款开源界面库 (10)
(声明:Alberl以后说到开源库,一般都是指著名的.或者不著名但维护至少3年以上的.那些把代码一扔就没下文的,Alberl不称之为开源库,只称为开源代码.这里并不是贬低,像Alberl前面那个系列的 ...
随机推荐
- double,失去精度
double,失去精度: amount.doubleValue() * 使用 BigDecimal: public static double add(double d1,double d2){ Bi ...
- mysql安装使用
linux系统 mysql-5.7.14-linux.zip部署包支持在CentOS 6.x/7.x 服务器硬盘大小要求 a) /data/mysql_data 如果存在该独立分区,要求该分区 &g ...
- Linux基础命令---ping
ping ping指令可以发送ICMP请求到目标地址,如果网络功能正常,目标主机会给出回应信息.ping使用ICMP协议强制发送ECHO_REQUEST报文到目标主机,从主机或网关获取ICMP ECH ...
- 实现Winform 跨线程安全访问UI控件
在多线程操作WinForm窗体上的控件时,出现“线程间操作无效:从不是创建控件XXXX的线程访问它”,那是因为默认情况下,在Windows应用程序中,.NET Framework不允许在一个线程中直接 ...
- JustOj 2042: Dada的游戏
题目描述 Dada无聊时,喜欢做一个游戏,将很多钱分成若干堆排成一列,每堆钱数不固定,谁能找出每堆钱数严格递增的最长区间,谁就是人生赢家了.Dada可能脑子里的水还没干,她找不出来,你来帮她找找吧. ...
- HDU 1232 畅通工程 (并查集)
某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇.省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可). ...
- 监控nginx服务
转自:http://www.cnblogs.com/silent2012/p/5310500.html 在Nginx的插件模块中有一个模块stub_status可以监控Nginx的一些状态信息,默认安 ...
- ubuntu_查看software
感谢原博主的分享 ubuntu安装和查看已安装 说明:由于图形化界面方法(如Add/Remove... 和Synaptic Package Manageer)比较简单,所以这里主要总结在终端通过命令行 ...
- jdbc --例子7
package cn.kitty.o1; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLE ...
- Spring/SpringMVC/MyBatis(持久层、业务层、控制层思路小结)
准备工作: ## 7 导入省市区数据到数据库中 1. 从FTP下载SQL脚本文件 2. 把脚本文件移动到易于描述绝对路径的位置 3. 进入MySQL控制台 4. 使用`xxx_xxx`数据库 5. 运 ...