聊聊kafka结构
因为kafka用到的地方比较多,日志收集、数据同步等,所以咱们来聊聊kafka。
首先先看看kafaka的结构,producer将消息放到一个Topic然后push到broker,然后cosumer从broker中拉取对应Topic的消息。
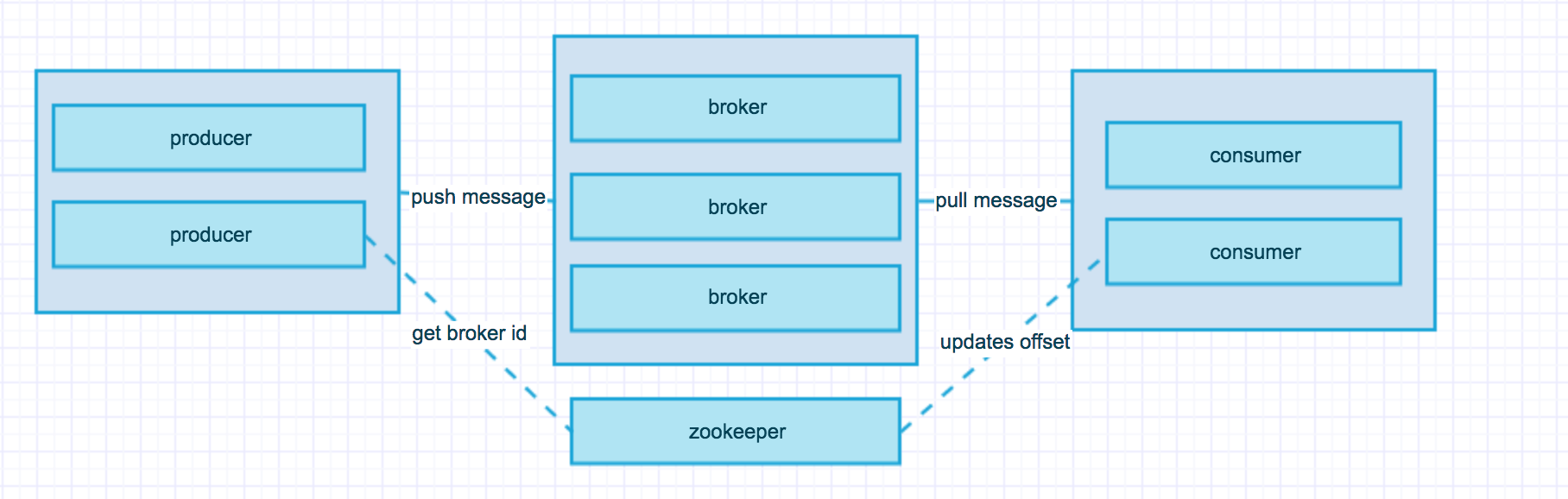
broker可能大家不太熟悉,这个broker就是构成kafka集群的机器,用于实现将数据持久化并且其他数据从leader broker中进行备份,一旦其中一台 broker出现问题之后将由其他broker直接升级为leader,然后代替原来的broker。
zookeeper的作用是记录当前leader broker的id,并将其发送给producer,并且记录每个consumer的进行的offset。offset就是消息存在的位置,这块与其他消息组件不同的是其他的消息组件消费完了直接就没有了,但是kafka会将消息持久化一段时间,这个时间可以是几天时间,用于消息重新再读取。
接下来咱们再继续看看broker的内部实现:
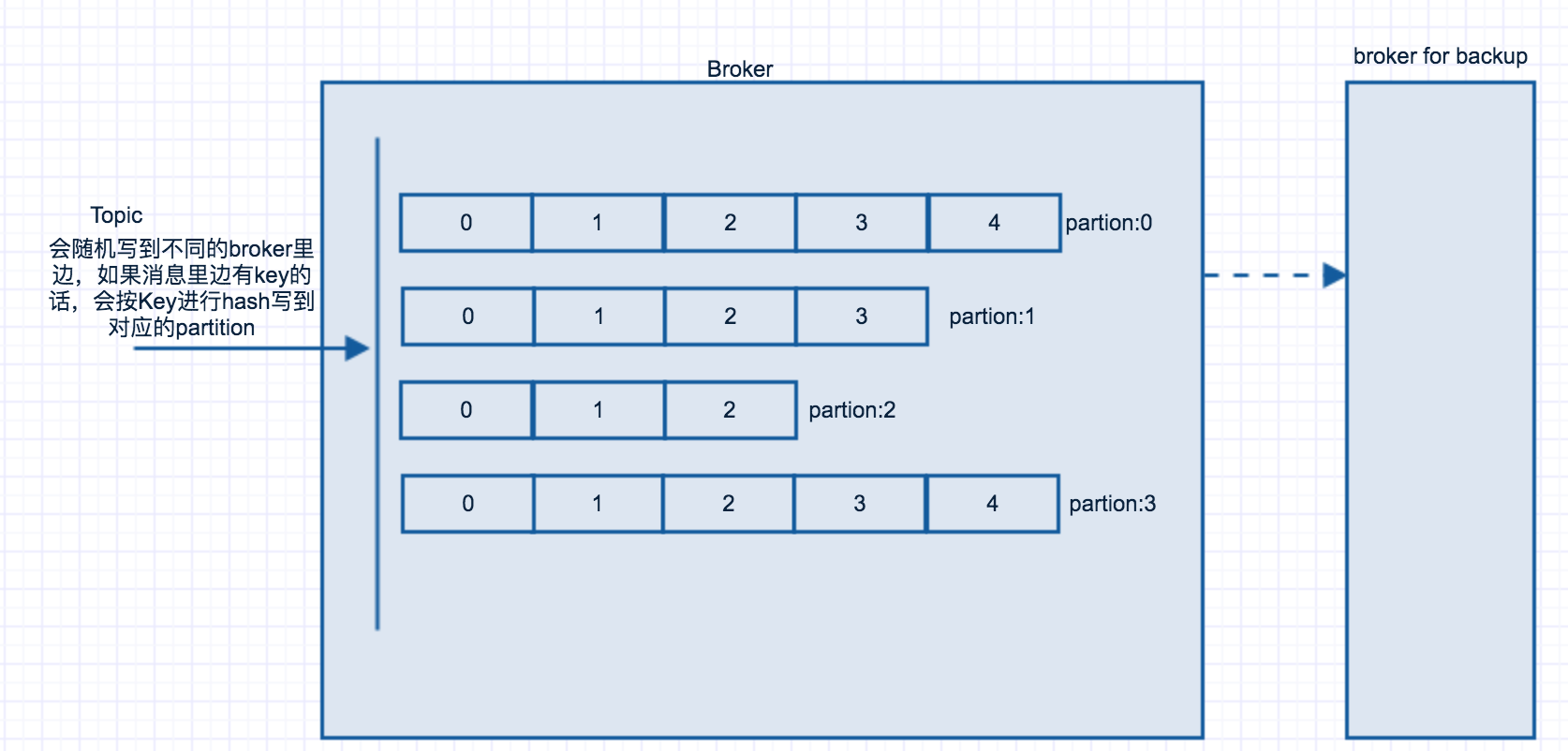
在每一个broker里边有相应的partition,这个partition就是按照Topic将消息分发到不同的partition, 然后consumer再到相应的partition获取对应的消息。如果producer发送消息到某个指定的key上,那么kafka会将这个key进行hash到指定的partition上。在kafka里边可以指定factor,这个factor的作用是备份,对partition的备份。如果指定factor=2,那么一个partion会有2个备份。如下图所示:
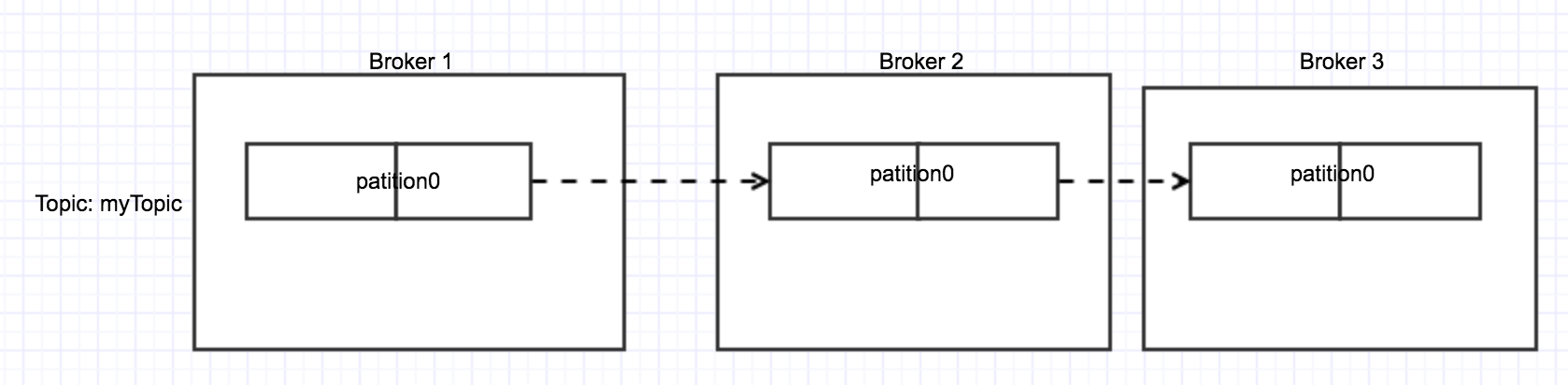
下面说一下consumer group, 因为partion设置的数量固定,所以在consumer group中的数量一定是小于等于partition的数量,因为最多每个consumer消息一个,consumer多了就消费不过来了。
consumer group 是拥有相同group id的机器,这些机器是单独的机器,每个机器都可以指定topic、partition进行消费。如下图所示:

这些就是基本的kafka结构了,当然里边还有很多非常详细的内容,这里就不单独说了。kafka的功能非常强大,分布式,可动态扩展,消息复制,高可用低延迟等特点,这就是为什么很多人喜欢使用kafka。kafka单台机器生产消费机器的话,每秒处理70-80万左右的消息。当然消息备份采用异步处理,如果消息采用同步处理的话,一秒可以处理的数据每秒也有30-40万左右。
kafka支持消息持久化,这个持久化的时间可以进行配置,也就是消息可以被consumer多次消费。这个是其他消息队列所没有的。
kafka支持consumer进行assign(分配)topic,也就是单独消费某一个消息,在consumer group里边只有一台机器消费此topic。也支持Pub-Sub模式,所有订阅指定Topic的consumer会收到消息。同时支持取消订阅功能。
kafka还支持connector(连接器),可以进行数据库连接,连上数据库后可以将数据库的记录读取到,按照自增列id或者timestamp(时间戳)进行读取,然后将消息写入到需要的地方,比如写到数据分析的地方。
kafka支持stream(流),可以将消息写入到stream,并将消息以流的形式从一个topic写入到另一个topic中,这个功能其他队列也没有。
kafka一般用于消息队列,日志收集,网站行为记录等,当然它也有区别,比如不能topic不能使用通配符,connector的支持的语言不是特别多。
好了,关于kafka咱们先聊到这里,还有很多地方没有说到,有觉得那些写的不好的地方还望同学不吝赐教。
聊聊kafka结构的更多相关文章
- 大数据之kafka-05.讲聊聊Kafka的版本号
今天聊聊kafka版本号的问题,这个问题实在是太重要了,我觉得甚至是日后能否用好kafka的关键.上一节我们介绍了kafka的几种发行版,其实不论是哪种kafka,本质上都内嵌了最核心的Apache ...
- 聊聊kafka
两个月因为忙于工作毫无输出了,最近想给团队小伙伴分享下kafka的相关知识,于是就想着利用博客来做个提前的准备工作了:接下来会对kafka做一个简单的介绍,包括利用akf原则来解析单机下kafk的各个 ...
- 【原创】美团二面:聊聊你对 Kafka Consumer 的架构设计
在上一篇中我们详细聊了关于 Kafka Producer 内部的底层原理设计思想和细节, 本篇我们主要来聊聊 Kafka Consumer 即消费者的内部底层原理设计思想. 1.Consumer之总体 ...
- 涨姿势了解一下Kafka消费位移可好?
摘要:Kafka中的位移是个极其重要的概念,因为数据一致性.准确性是一个很重要的语义,我们都不希望消息重复消费或者丢失.而位移就是控制消费进度的大佬.本文就详细聊聊kafka消费位移的那些事,包括: ...
- Kafka入门(2):消费与位移
摘要 在这篇文章中,我将从消息在Kafka中的物理存储方式讲起,介绍分区-日志段-日志的各个层次. 然后我将接着上一篇文章的内容,把消费者的内容展开讲一讲,区分消费者与消费者组,以及这么设计有什么用. ...
- 【原创】阿里三面:搞透Kafka的存储架构,看这篇就够了
阅读本文大约需要30分钟.这篇文章干货很多,希望你可以耐心读完. 你好, 我是华仔,在这个 1024 程序员特殊的节日里,又和大家见面了. 从这篇文章开始,我将对 Kafka 专项知识进行深度剖析, ...
- Go语言结构
目录 结构体定义 创建结构体实例 普通方式创建结构体实例 new()创建结构体实例 结构体实例初始化 结构体类型实例和指向它的指针内存布局 结构体的方法 面向对象 组合(继承) 结构体使用注意事项 G ...
- Kafka架构
一.Kafka介绍 Kafka是Linkin在2010年开源的分布式发布订阅消息系统,Kafka是高吞吐量的消息订阅系统. 二.Kafka结构 Kafka由三部分构成,producer.broker. ...
- Kafka系列1:Kafka概况
Kafka系列1:Kafka概况 Kafka是当前分布式系统中最流行的消息中间件之一,凭借着其高吞吐量的设计,在日志收集系统和消息系统的应用场景中深得开发者喜爱.本篇就聊聊Kafka相关的一些知识点. ...
随机推荐
- python 新式类的 __getattribute__
这个方法定义在object中,所以所有的新式类都继承有该方法,所有的新式类的实例在获取属性value的时候都会调用该方法,为了验证这一结论,我们重写一下该方法: class C(object): a ...
- 【python】pip安装报错UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 7: ordinal not in range(128)
刚安装完python,准备pip安装第三方库的时候出现了一个错误: UnicodeDecodeError: ‘ascii’ code can’t decode byte 0xef in positio ...
- winform程序生成条形码并且并且保存到本地文件中。
今天公司让做一个输入数字.字母生成条形码并且可以以图片格式保存到本地.当看到这个需求时候感觉很搞笑,明明可以用文本框搞定的东西非得做个程序.哎,寄人篱下,不多说了,这就是养兵千日用兵一时. 我在网上找 ...
- jmeter中实现java请求实战日志
view code public class JdbcInsert implements JavaSamplerClient { // 全局变量 PreparedStatement pstmt; Co ...
- MFC创建线程示例
MFC创建线程示例 AfxBeginThread() 创建现场的方法是AfxBeginThread()函数. 在[.CPP]文件定义一个全局变量,决定什么时候退出这个线程. BOOL g_bWillE ...
- Python-百度经纬度转高德经纬度
import math def bdToGaoDe(lon,lat): """ 百度坐标转高德坐标 :param lon: :param lat: :return: &q ...
- cacti系列(三)之cacti添加对mysql服务器主从的监控
1.配置主从同步 主服务器: 建立从服务器的复制权限账号 GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'repluser'@'192.16 ...
- 转载:2.2.1 块配置项《深入理解Nginx》(陶辉)
原文:https://book.2cto.com/201304/19626.html 块配置项由一个块配置项名和一对大括号组成.具体示例如下:events {-} http { upstream ba ...
- 重装windows系统后配置Anaconda
给电脑换了系统,十分担心anaconda需要重装.还好以下方法完美解决.(同是win10 64位) 原始anaconda安装路径:D:\ProgramData\Anaconda3 (不能有空格哦) ...
- 使用swiper.js实现移动端tab切换
在项目中遇到的,要实现tab切换,我用的是swiper.js 官网:http://www.swiper.com.cn/api/start/new.html <!DOCTYPE html> ...