4067: [Ctsc2015]gender 动态规划 网络流
国际惯例的题面: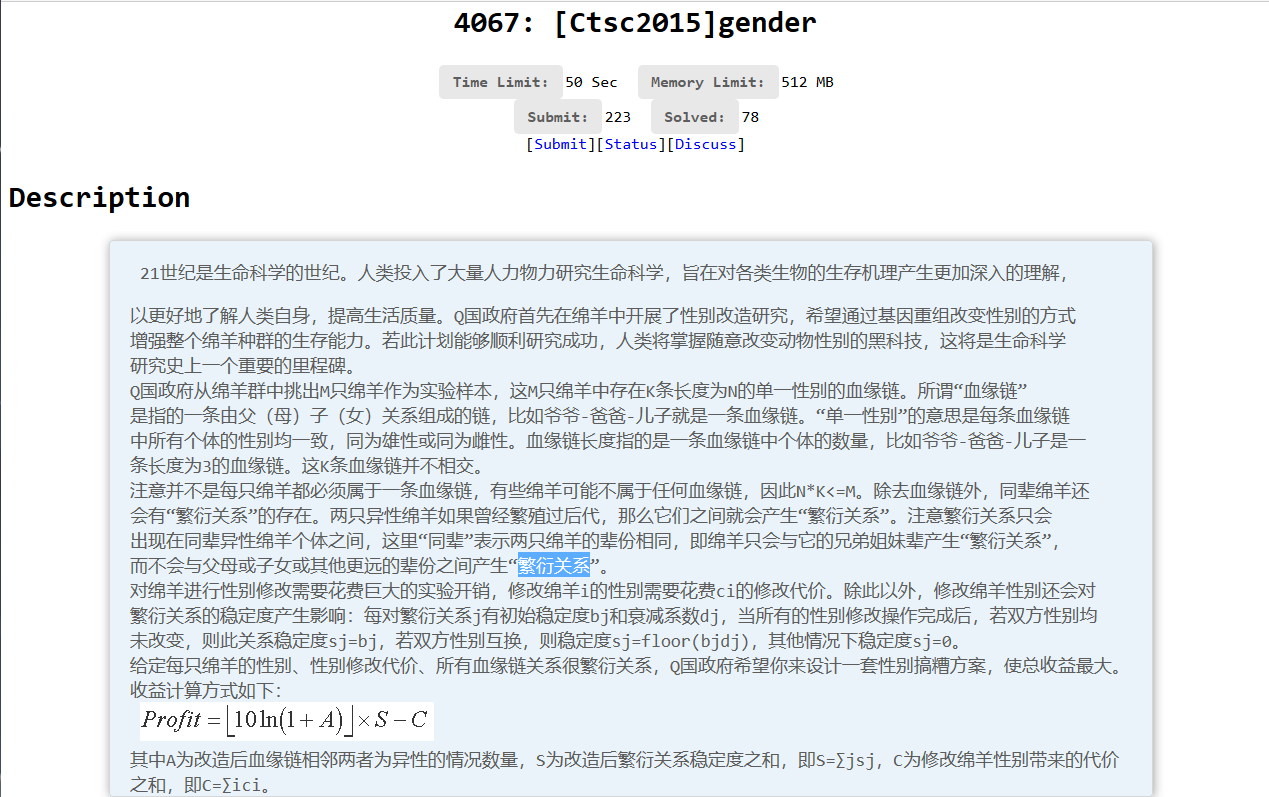
首先这题是缺少两个隐藏条件的:
第一个是这k条链的起点和终点所在的层是对齐的,也就是说不会出现两条链错开的情况,且这张图恰好由n层组成;
第二个就是任意一个点都包含在与链上的点直接或间接相关的同一层中,不存在与链无关的孤立层。
(如果缺少第一个条件这题是基本没法做的,分类讨论细节太多;第二个讨论倒是无关紧要,你钦定孤立层的点都在第一层就好了)
(别问我怎么知道的,第一个是找学长问出来的,第二个是调?教!某神犇的AC代码(把他WA掉)试出来的)
然后就是怎么做的问题。
观察到那个ln十分不好处理,我们可以枚举它。反正ln增长很慢,总共就40+种取值。
同时发现k很小,这提醒我们,每层的关键点很少,我们能否状压呢?
我们先枚举那个ln的值,定义f[depth][statement][different]表示考虑从第1到depth层,当前层(第depth层)修改状态为statement,总共产生的链上相邻点修改状态不同的数量为different的最大收益。
f[depth][statement][different] = max( f[depth-1][last_statement][different-diff(statement^last_statement)] + calc(depth,statement) )。
考虑如何计算第depth层,状态为statement时的最大代价。
点要么改要么不改,二种状态必选其一,不是2-sat就是最小割。
而2-sat只能解决判定性问题,所以铁定是最小割了。
考虑怎么建图:
(参考"Bzoj3438: 小M的作物"和"3894: 文理分科"的建图,然而你都没有写过也没关系,我会叙述清楚)
首先我们累加能获得的所有权值,再减去最后的最小割。
我们钦定对于一个点,如果在最小割中与源点相连,代表它保持原状,与汇点相连代表它被改变性别。
那么这个点与源点的边权就是对它进行改变的代价,与汇点的边权就是让它维持原状的代价。
(对于链上的点(显然状态被statement确定),我们让它只与源点汇点连inf边表示它被钦定保持原状/进行改变)
对于一条原图中的边(就是"繁衍关系"),在两个点都不被改变时产生价值di,我们为可以为它新建一个点,从源点向这个点连容量di的边,再从这个点向依赖的两个点ui,vi连接容量为inf的边,代表如果要把ui或者vi放到与汇点相连的集合,则必须割掉这条边的权值。
两个点都改变时产生的价值di*bi建图同理。
然后就是一些细节,比如层内的代价只和枚举的ln,层数depth和状态statement有关,那么我们对这样的三元组可以只跑一次网络流而不是每次进行计算。
网络流重建图的时候不要memset整个数组,用多少memset多少,否则TLE。
对每个点转换一下坐标,把点的编号转化为它在层内的编号,这样能使得每次网络流点的编号连续,减少memset的时间。
(然后就是我人傻用了一堆vector导致大常数的代码了)
代码:
#pragma GCC optimize(2)
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<queue>
#include<vector>
#include<cmath>
#define debug cout
using namespace std;
const int maxn=1e3+1e2,maxe=5e4+1e3,maxs=<<;
const int inf=0x3f3f3f3f,minf=0xefefefef; int chain[][maxn],id[maxn],c[maxn],dep[maxn],rid[maxn]; // id of chain .
vector<int> pts[maxn]; // points of each level .
struct Edge {int u,v,b,d;}ine[maxe];
vector<Edge> es[maxn]; // edge of each level.
int f[][<<][],ln[]; // f[level][statement][diffs]
int n,m,k,p,full,ans; namespace Flow {
int s[maxe],t[maxe<<],nxt[maxe<<],f[maxe<<],cnt=;
int dep[maxe],st,ed;
inline void coredge(int from,int to,int flow) {
t[++cnt] = to , f[cnt] = flow , nxt[cnt] = s[from] , s[from] = cnt;
}
inline void singledge(int from,int to,int flow) {
coredge(from,to,flow) , coredge(to,from,);
}
inline bool bfs() {
memset(dep,-,sizeof(int)*(ed+)) , dep[st] = ;
queue<int> q; q.push(st);
while( q.size() ) {
const int pos = q.front(); q.pop();
for(int at=s[pos];at;at=nxt[at])
if( f[at] && !~dep[t[at]] )
dep[t[at]] = dep[pos] + , q.push(t[at]);
}
return ~dep[ed];
}
inline int dfs(int pos,int flow) {
if( pos == ed ) return flow;
int ret = , now = ;
for(int at=s[pos];at;at=nxt[at])
if( f[at] && dep[t[at]] > dep[pos] ) {
now = dfs(t[at],min(flow,f[at])) ,
ret += now , flow -= now , f[at] -= now , f[at^] += now;
if( !flow ) return ret;
}
if( !ret ) dep[pos] = -;
return ret;
}
inline int dinic() {
int ret = ;
while( bfs() ) ret += dfs(st,inf);
return ret;
}
inline void reset() {
memset(s,,sizeof(int)*(ed+)) , cnt = ;
}
} inline int build(int dep,int sta,int mul) {
using namespace Flow;
st = pts[dep].size() + ( es[dep].size() * ) + , ed = st + , reset();
#define cov(x,t) (x*2+1+t+pts[dep].size())
int ret = ;
for(unsigned i=;i<pts[dep].size();i++) {
const int p = pts[dep][i];
if( id[p] ) { // & 1 means change it .
if( ( sta >> ( id[p] - ) ) & ) singledge(rid[p],ed,inf) , ret -= c[p];
else singledge(st,rid[p],inf);
} else singledge(st,rid[p],c[p]) , singledge(rid[p],ed,);
}
for(unsigned i=;i<es[dep].size();i++) {
int o = cov(i,) , h = cov(i,);
ret += es[dep][i].d * mul , ret += es[dep][i].b * mul;
singledge(st,o,es[dep][i].d*mul) , singledge(o,rid[es[dep][i].u],inf) , singledge(o,rid[es[dep][i].v],inf) ,
singledge(h,ed,es[dep][i].b*mul) , singledge(rid[es[dep][i].u],h,inf) , singledge(rid[es[dep][i].v],h,inf);
}
return ret - dinic(); }
inline int calbet(int stfa,int stcur) {
int dif = stfa ^ stcur , ret = ;
while( dif ) ++ret , dif -= ( dif & -dif );
return ret;
} inline void dp(int mul) {
memset(f,0xef,sizeof(f));
for(int i=;i<full;i++) f[][i][] = ;
for(int i=;i<n;i++) {
for(int cur=;cur<full;cur++) {
int bul = -;
for(int dif=;dif<=n*k;dif++)
if( f[i][cur][dif] != minf) {
if( !~bul ) bul = build(i,cur,mul);
f[i][cur][dif] += bul;
for(int nxt=;nxt<full;nxt++) {
const int nxtdif = dif + calbet(cur,nxt);
f[i+][nxt][nxtdif] = max( f[i+][nxt][nxtdif] , f[i][cur][dif] );
}
}
}
}
for(int i=;i<full;i++) {
int bul = -;
for(int dif=;dif<=n*k;dif++) if( ln[dif] == mul ) {
if( !~bul ) bul = build(n,i,mul);
ans = max( ans , f[n][i][dif] + bul );
}
}
} inline void pre() {
for(int i=;i<=n*k;i++) ln[i] = * log(i+);
} struct UnionFindSet {
int fa[maxn];
inline int findfa(int x) {
return fa[x] == x ? x : fa[x] = findfa(fa[x]);
}
inline void merge(int x,int y) {
if( ( x = findfa(x) ) != ( y = findfa(y) ) ) fa[x] = y;
}
inline void init() {
for(int i=;i<=m;i++) fa[i] = i;
}
}ufs; int main() {
static double dd;
scanf("%d%d%d%d%*s",&n,&k,&m,&p) , ufs.init() , pre() , full = << k;
for(int i=;i<=m;i++) scanf("%d",c+i);
for(int i=;i<=k;i++) for(int j=;j<=n;j++) scanf("%d",chain[i]+j) , id[chain[i][j]] = i;
for(int i=;i<=p;i++) {
scanf("%d%d%d%lf",&ine[i].u,&ine[i].v,&ine[i].d,&dd) , ine[i].b = floor( ine[i].d * dd ) ,
ufs.merge(ine[i].u,ine[i].v);
}
for(int i=;i<=k;i++) for(int j=;j<=n;j++) dep[ufs.findfa(chain[i][j])] = j;
for(int i=;i<=m;i++) {
dep[i] = dep[ufs.findfa(i)];
if( !dep[i] ) dep[i] = dep[ufs.findfa(i)] = ;
pts[dep[i]].push_back(i) , rid[i] = pts[dep[i]].size();
}
for(int i=;i<=p;i++) es[dep[ine[i].u]].push_back(ine[i]);
for(int i=ln[];i<=ln[n*k];i++) dp(i);
printf("%d\n",ans);
return ;
}
キミの未来が私の未来
你的未来 就是 我的未来
キミが居るなら何も怖くない
只要有你在 我便什么都不怕
二人を繋ぐ 重ねた手と手
维系你我的 交叠的手与手
離れないように強く握りしめて行こう
为再也不离不弃 往后也用力紧握
誰よりも優しく強い
比任何人 都温柔坚强
誰よりも脆く弱い人
比任何人 都脆弱的人
たくさんの痛みを知って
遍尝世间万千苦痛
悲しいことも隠して笑う
藏起伤悲强颜欢笑
4067: [Ctsc2015]gender 动态规划 网络流的更多相关文章
- bzoj4067 [Ctsc2015]gender
好神的一道题啊! 我们发现题目中的ln的贡献非常傻逼,但是我们可以发现这个东西的取值只有40个左右,于是我们可以枚举他! 枚举完了对于题里的贡献就是一个普通的最小割,采用的是文理分科的思想,与S连代表 ...
- bzoj AC倒序
Search GO 说明:输入题号直接进入相应题目,如需搜索含数字的题目,请在关键词前加单引号 Problem ID Title Source AC Submit Y 1000 A+B Problem ...
- 【BZOJ4200】【NOI2015】小园丁与老司机(动态规划,网络流)
[BZOJ4200][NOI2015]小园丁与老司机(动态规划,网络流) 题面 BZOJ权限题,洛谷链接 题解 一道二合一的题目 考虑第一问. 先考虑如何计算六个方向上的第一个点. 左右上很好考虑,只 ...
- 【洛谷2304_LOJ2134】[NOI2015]小园丁与老司机(动态规划_网络流)
题目: 洛谷 2304 LOJ 2134 (LOJ 上每个测试点有部分分) 写了快一天 -- 好菜啊 分析: 毒瘤二合一题 -- 注意本题(及本文)使用 \(x\) 向右,\(y\) 向上的「数学坐标 ...
- BZOJ4200 NOI2015小园丁与老司机(动态规划+上下界网络流)
一看上去就是一个二合一的题.那么先解决第一部分求最优路线(及所有可能在最优路线上的线段). 由于不能往下走,可以以y坐标作为阶段.对于y坐标不同的点,我们将可以直接到达的两点连边,显然这样的边的个数是 ...
- poj 动态规划题目列表及总结
此文转载别人,希望自己能够做完这些题目! 1.POJ动态规划题目列表 容易:1018, 1050, 1083, 1088, 1125, 1143, 1157, 1163, 1178, 1179, 11 ...
- poj动态规划列表
[1]POJ 动态规划题目列表 容易: 1018, 1050, 1083, 1088, 1125, 1143, 1157, 1163, 1178, 1179, 1189, 1208, 1276, 13 ...
- POJ 动态规划题目列表
]POJ 动态规划题目列表 容易: 1018, 1050, 1083, 1088, 1125, 1143, 1157, 1163, 1178, 1179, 1189, 1208, 1276, 1322 ...
- poj 动态规划的主题列表和总结
此文转载别人,希望自己可以做完这些题目. 1.POJ动态规划题目列表 easy:1018, 1050, 1083, 1088, 1125, 1143, 1157, 1163, 1178, 1179, ...
随机推荐
- UML和模式应用5:细化阶段(6)---操作契约
1.前言 操作契约使用前置和后置条件,描述领域模型里对象的详细变化,作为系统操作的结果. 操作契约可以作为有用的OOA相关的制品. 操作契约可以视为UP用例模型的一部分,它是对用例之处的系统操作的效用 ...
- C# 实现UDP打洞通信(一)
最近研究了一下网络打洞的相关技术,TCP的方式据说可行性不高,各种困难,因此决定采用UDP(UDP是什么就不解释了)的方式. 原理: 我们都知道局域网内的主机想要访问外网的服务器是比较容易的,比如浏览 ...
- Spring的Aspect切面类不能拦截Controller中的方法
根本原因在于<aop:aspectj-autoproxy />这句话是在spring的配置文件内,还是在springmvc的配置文件内.如果是在spring的配置文件内,则@Control ...
- mybatis框架之foreach标签
foreach一共有三种类型,分别为List,[](array),Map三种,下面表格是我总结的各个属性的用途和注意点. foreach属性 属性 描述 item 循环体中的具体对象.支持属性的点路径 ...
- Vue.js——component(组件)
概念: 组件(Component)是自定义元素. 作用: 可以扩展HTML元素,封装可重用的代码. <div id="myView"> <!-- 把学生的数据循环 ...
- centos配置golang & SVN客户端配置
环境:centos 6.5 一.下载和解压go环境包 >>cd /usr/local/ >>wget -c http://golangtc.com/static/go/go1. ...
- jmeter之正则表达式
一.Jmeter关联的方式: Jmeter中关联可以在需要获取数据的请求上 右键-->后置处理器 选择需要的关联方式,如下图有很多种方法可以提取动态变化数据: 二.正则表达式提取器: 1.比如需 ...
- Lodash JavaScript 实用工具库
地址:https://www.lodashjs.com/ Lodash 是一个一致性.模块化.高性能的 JavaScript 实用工具库.
- Java7编程高级进阶学习笔记
本书PDF 下载地址: http://pan.baidu.com/s/1c141KGS 密码:v6i1 注:本文有空会跟新: 讲述的是jdk7的内容: 注关于java 更详细的内容请进入:<Ja ...
- js获取iframe中的元素
var obj=document.getElementById("iframe的name").contentWindow; var ifmObj=obj.document.getE ...