循环神经网络-RNN进阶
这部分许多内容要类比CNN来进行理解和解释,所以需要对CNN比较熟悉。
RNN的特点
1. 权值共享
CNN权值共享,RNN也有权值共享,在入门篇可以看到RNN结构图中,权重使用的是同样的字母
为什么要权值共享
a. 减少weight,减少计算量,这点其实比较好理解。
试想10X10的输入,全连接隐藏层如果是1000个神经元,那就有100000个weight要计算;
如果是卷积神经网络,5X5的感受视野,只要25个weight。即使100个卷积核,才2500,不严谨,反正很少就对了。
b. 参考再谈权值共享
为什么可以权值共享
参考CNN疑点解析
需要说明的是共享是同样的传递过程时参数相同,即x-s都是u,同理。
2. 每个输入都只与它本身的那条路线建立连接,不与其他神经元连接。
RNN的计算要素与流程
以标准RNN为例
计算要素

前向与反向
参照 https://www.cnblogs.com/yanshw/p/10478876.html 循环神经网络-极其详细的推到BPTT
参数优化
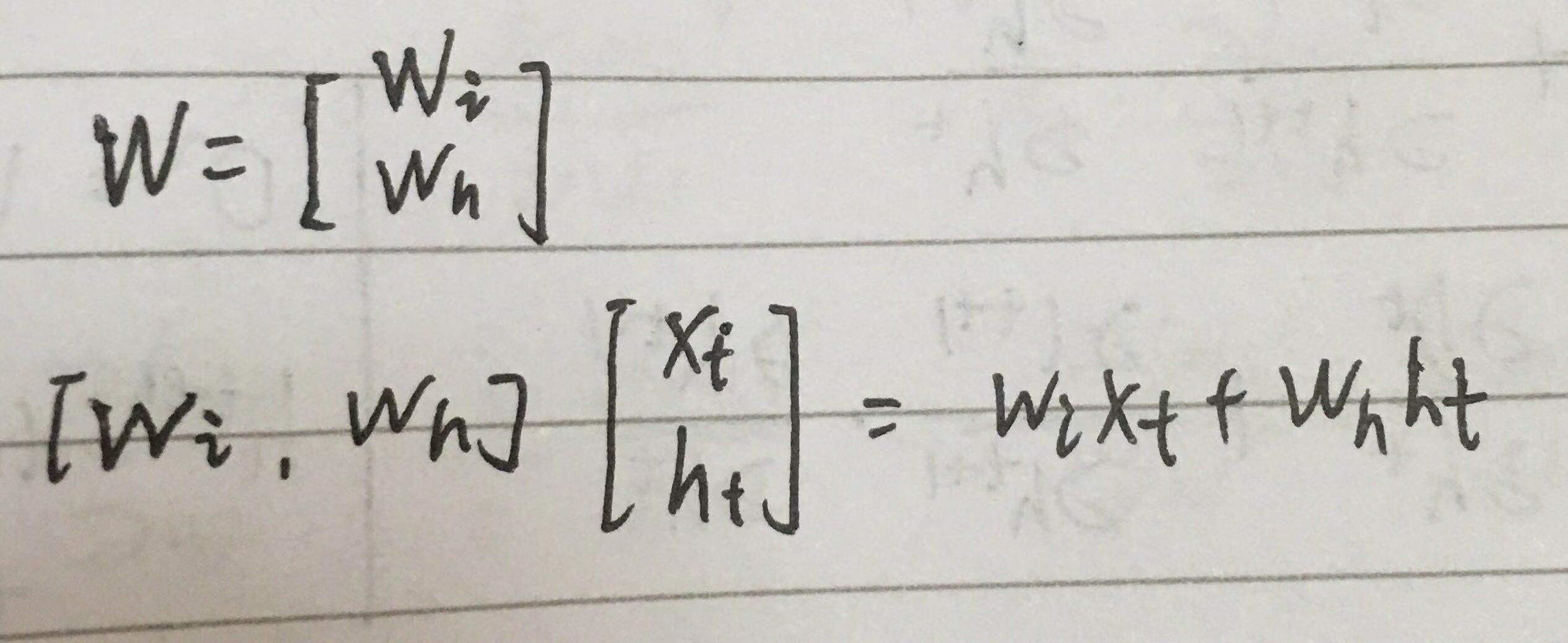
梯度爆炸和梯度消失
RNN在训练过程中容易出现梯度爆炸和梯度消失
所谓梯度爆炸就是在神经网络训练过程中,梯度变得越来越大以使得神经网络权重得到疯狂更新的情形,这种情况很容易发现,因为梯度过大,计算更新得到的参数也会大到崩溃,这时候我们可能看到更新的参数值中有很多的 NaN,这说明梯度爆炸已经使得参数更新出现数值溢出。这便是梯度爆炸的基本情况。
梯度消失。与梯度爆炸相反的是,梯度消失就是在神经网络训练过程中梯度变得越来越小以至于梯度得不到更新的一种情形。当网络加深时,网络深处的误差很难因为梯度的减小很难影响到前层网络的权重更新,一旦权重得不到有效的更新计算,神经网络的训练机制也就失效了。

在BPTT中有 ∏w·f’ 的连乘,所以很容易出现问题。
长期依赖问题
RNN面临的最大挑战就是无法解决长期依赖问题。例如对下面两句话:
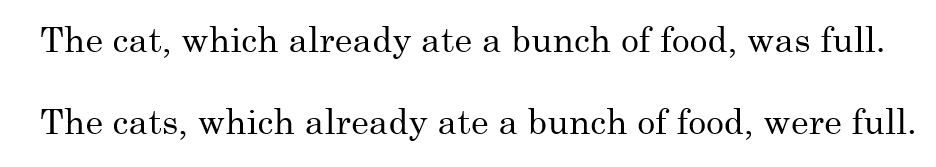
最后的was与were如何选择是和前面的单复数有关系的,但对于简单的RNN来说,两个词相隔比较远,如何判断是单数还是复数就很关键。
长期依赖的根本问题是,经过许多阶段传播后的梯度倾向于消失(大部分情况)或爆炸(很少,但对优化过程影响很大)。
对于梯度爆炸是很好解决的,可以使用梯度修剪(Gradient Clipping),即当梯度向量大于某个阈值,强行缩放梯度向量。但对于梯度消失是很难解决的。
RNN种类
一对一
一对多
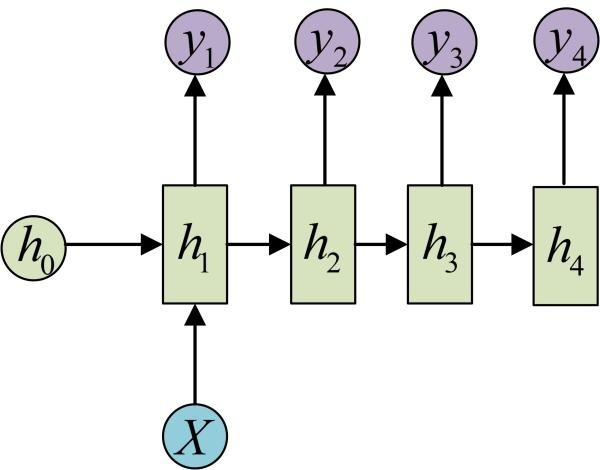
如图片描述,输入一张图片,输出图片的文字描述
多对一
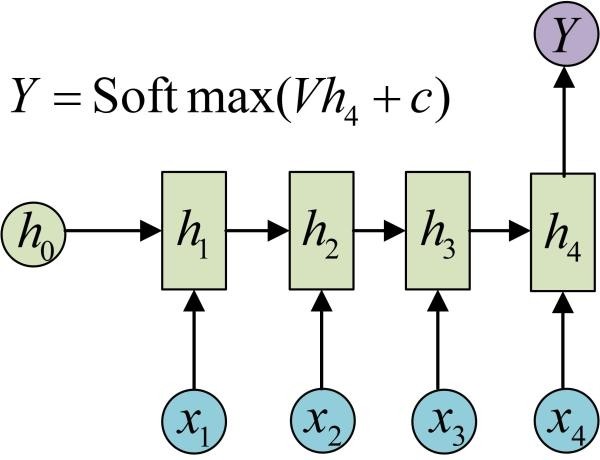
如分类,输入文本,分类积极消极。
多对多1
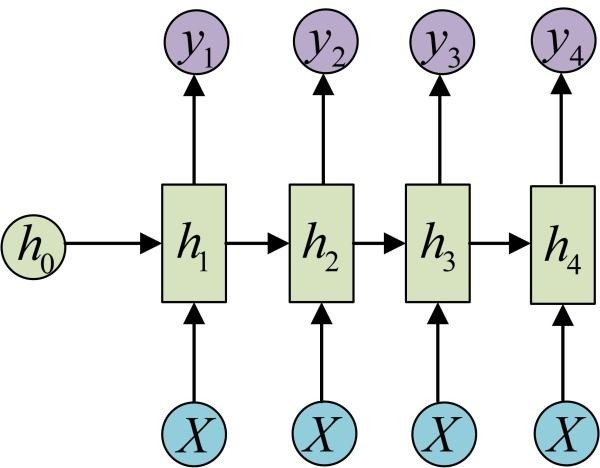
多用于序列标注
多对多2
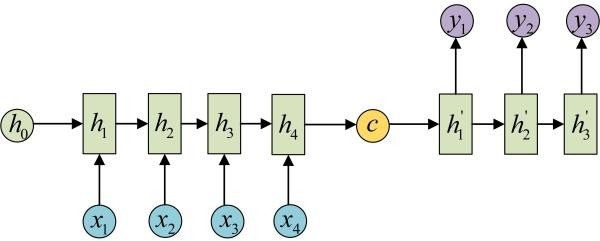
如机器翻译,输入中文,输出英文
RNN的形象描述
RNN模仿了人的记忆功能,它把昨天的记忆传给今天,然后做个总结,把今天的总结又传给明天,这使得它能够记住之前的事情,
但是由于它大脑容量有限,本身智商低,总结能力差,记忆力差,
所以每天都传一些乱七八糟的给第二天,以至于时间长了,之前的很难记得清。
人类之所以有聪明和笨之分,也是因为聪明的人善于总结,每天只记忆精华的东西,而笨的人一股脑全记,其实脑子里是一团浆糊,到真正用时,啥也没记住。
那RNN改进的办法是不是也是每天提炼一下,少记点东西呢?
循环神经网络-RNN进阶的更多相关文章
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- 通过keras例子理解LSTM 循环神经网络(RNN)
博文的翻译和实践: Understanding Stateful LSTM Recurrent Neural Networks in Python with Keras 正文 一个强大而流行的循环神经 ...
- 循环神经网络RNN及LSTM
一.循环神经网络RNN RNN综述 https://juejin.im/entry/5b97e36cf265da0aa81be239 RNN中为什么要采用tanh而不是ReLu作为激活函数? htt ...
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
深度学习之循环神经网络RNN概述,双向LSTM实现字符识别 2. RNN概述 Recurrent Neural Network - 循环神经网络,最早出现在20世纪80年代,主要是用于时序数据的预测和 ...
- 循环神经网络RNN模型和长短时记忆系统LSTM
传统DNN或者CNN无法对时间序列上的变化进行建模,即当前的预测只跟当前的输入样本相关,无法建立在时间或者先后顺序上出现在当前样本之前或者之后的样本之间的联系.实际的很多场景中,样本出现的时间顺序非常 ...
- 从网络架构方面简析循环神经网络RNN
一.前言 1.1 诞生原因 在普通的前馈神经网络(如多层感知机MLP,卷积神经网络CNN)中,每次的输入都是独立的,即网络的输出依赖且仅依赖于当前输入,与过去一段时间内网络的输出无关.但是在现实生活中 ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
原文地址: http://blog.csdn.net/heyongluoyao8/article/details/48636251# 循环神经网络(RNN, Recurrent Neural Netw ...
- 用纯Python实现循环神经网络RNN向前传播过程(吴恩达DeepLearning.ai作业)
Google TensorFlow程序员点赞的文章! 前言 目录: - 向量表示以及它的维度 - rnn cell - rnn 向前传播 重点关注: - 如何把数据向量化的,它们的维度是怎么来的 ...
- 循环神经网络(RNN)模型与前向反向传播算法
在前面我们讲到了DNN,以及DNN的特例CNN的模型和前向反向传播算法,这些算法都是前向反馈的,模型的输出和模型本身没有关联关系.今天我们就讨论另一类输出和模型间有反馈的神经网络:循环神经网络(Rec ...
随机推荐
- sass制作雪碧图
1.配置文件config.rb http_path = "../../../" css_dir = "Content/css" sass_dir = " ...
- android -------- ConstraintLayout介绍 (一)
ConstraintLayout 翻译为 约束布局,也有人把它称作 增强型的相对布局,由 2016 年 Google I/O 推出. 扁平式的布局方式,无任何嵌套,减少布局的层级,优化渲染性能.从支持 ...
- linux文件系统(一)
linux的文件系统以及文件类型一.linux 文件系统: 根文件系统(rootfs) rootfilesystem /etc,/usr,/var,/home,/dev 系统自我运行必须用到的路径:( ...
- 正睿 2018 提高组十连测 Day4 T3 碳
记'1'为+1,'0'为-1; 可以发现 pre[i],suf[i]分别为前/后缀和 a[i]=max(pre[l.....i]); b[i]=max(suf[i+1....r]); ans=max( ...
- XXE漏洞
原理:XML外部实体注入,简称XXE漏洞,XML数据在传输中数据被修改,服务器执行被恶意插入的代码.当允许引用外部实体时,通过构造恶意内容,就可能导致任意文件读取.系统命令执行.内网端口探测.攻击内网 ...
- ubuntu计划任务的编写
1,首先,我编写的计划任务是在ubunut系统上的.首先我们来认识一下每一个 * 这样子的符号代表什么意思吧! * * * * * 从左到右: 第1列表示分钟1-59 每分钟用*或者 */1表 ...
- hdu-2865-polya+dp+矩阵+euler函数
Birthday Toy Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tota ...
- PHP手册-函数参考-加密扩展
一.Crack.CSPRNG.Hash.Mcrypt.Mhash.OpenSSL.密码散列算法的对比 Crack CSPRNG Hash Mcrypt Mhash OpenSSL 密码散列算法 简 ...
- SpringBoot利用注解@Value获取properties属性为null
参考:https://www.cnblogs.com/zacky31/p/8609990.html 今天在项目中想使用@Value来获取Springboot中properties中属性值. 场景:定义 ...
- ECharts饼状图添加事件
和柱状图添加事件没有区别,详情如下: <!DOCTYPE html> <html> <head> <meta http-equiv="Content ...