最大似然估计(Maximum likelihood estimation)(通过例子理解)
似然与概率
https://blog.csdn.net/u014182497/article/details/82252456
在统计学中,似然函数(likelihood function,通常简写为likelihood,似然)是一个非常重要的内容,在非正式场合似然和概率(Probability)几乎是一对同义词,但是在统计学中似然和概率却是两个不同的概念。概率是在特定环境下某件事情发生的可能性,也就是结果没有产生之前依据环境所对应的参数来预测某件事情发生的可能性,比如抛硬币,抛之前我们不知道最后是哪一面朝上,但是根据硬币的性质我们可以推测任何一面朝上的可能性均为50%,这个概率只有在抛硬币之前才是有意义的,抛完硬币后的结果便是确定的;而似然刚好相反,是在确定的结果下去推测产生这个结果的可能环境(参数),还是抛硬币的例子,假设我们随机抛掷一枚硬币1,000次,结果500次人头朝上,500次数字朝上(实际情况一般不会这么理想,这里只是举个例子),我们很容易判断这是一枚标准的硬币,两面朝上的概率均为50%,这个过程就是我们根据结果来判断这个事情本身的性质(参数),也就是似然。
结果和参数相互对应的时候,似然和概率在数值上是相等的,如果用 θ 表示环境对应的参数,x 表示结果,那么概率可以表示为:
P(x|θ)
P(x|θ)
是条件概率的表示方法,θ是前置条件,理解为在θ 的前提下,事件 x 发生的概率,相对应的似然可以表示为:
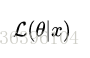
理解为已知结果为 x ,参数为θ (似然函数里θ 是变量,这里## 标题 ##说的参数是相对与概率而言的)对应的概率,即:
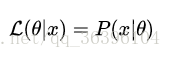
需要说明的是两者在数值上相等,但是意义并不相同,
举个例子
以伯努利分布(Bernoulli distribution,又叫做两点分布或0-1分布)为例:
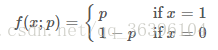
也可以写成以下形式:
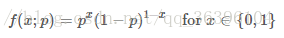
这里注意区分 f(x;p)f(x;p) 与前面的条件概率的区别,引号后的 pp 仅表示 ff 依赖于 pp 的值,pp 并不是 ff 的前置条件,而只是这个概率分布的一个参数而已,也可以省略引号后的内容:
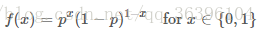
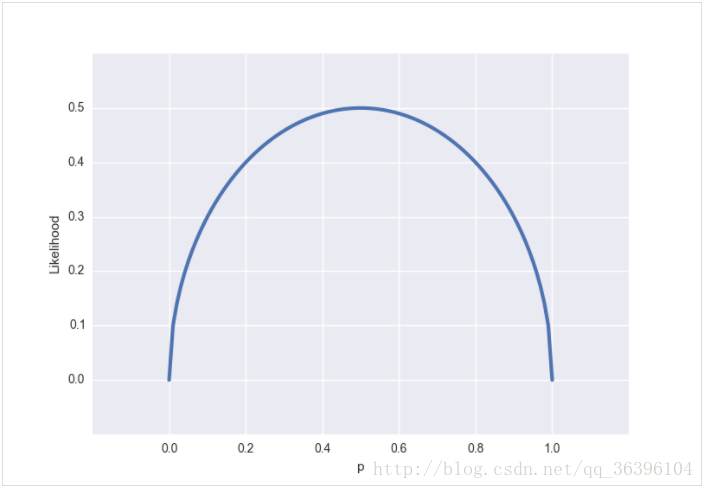
对于任意的参数 pp 我们都可以画出伯努利分布的概率图,当 p=0.5p=0.5 时:
f(x)=0.5
- 1
- 2
我们可以得到下面的概率密度图:
从似然的角度出发,假设我们观测到的结果是 x=0.5x=0.5(即某一面朝上的概率是50%,这个结果可能是通过几千次几万次的试验得到的,总之我们现在知道这个结论),可以得到以下的似然函数:
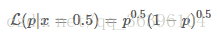
对应的图是这样的:
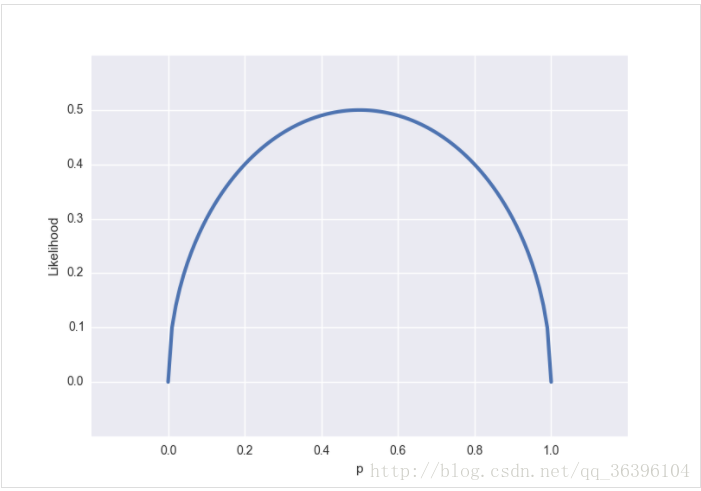
与概率分布图不同的是,似然函数是一个(0, 1)内连续的函数,所以得到的图也是连续的,我们很容易看出似然函数的极值(也是最大值)在 p=0.5p=0.5 处得到,通常不需要做图来观察极值,令似然函数的偏导数为零即可求得极值条件。
ps. 似然函数里的 pp 描述的是硬币的性质而非事件发生的概率(比如 p=0.5p=0.5 描述的是一枚两面均匀的硬币)。为了避免混淆,可以用其他字母来表示这个性质,如果我们用 ππ 来表示,那么似然函数就可以写成:

似然函数的最大值
似然函数的最大值意味着什么?让我们回到概率和似然的定义,概率描述的是在一定条件下某个事件发生的可能性,概率越大说明这件事情越可能会发生;而似然描述的是结果已知的情况下,该事件在不同条件下发生的可能性,似然函数的值越大说明该事件在对应的条件下发生的可能性越大。
现在再来看看之前提到的抛硬币的例子:
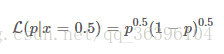
上面的 pp (硬币的性质)就是我们说的事件发生的条件,LL 描述的是性质不同的硬币,任意一面向上概率为50% 的可能性有多大,是不是有点绕?让我们来定义 A:
A=事件的结果=任意一面向上概率为50%
那么 LL 描述的是性质不同的硬币,A 事件的可能性有多大,这么一说是不是清楚多了?
在很多实际问题中,比如机器学习领域,我们更关注的是似然函数的最大值,我们需要根据已知事件来找出产生这种结果最有可能的条件,目的当然是根据这个最有可能的条件去推测未知事件的概率。在这个抛硬币的事件中,pp
可以取 [0, 1] 内的所有值,这是由硬币的性质所决定的,显而易见的是 p=0.5p=0.5 这种硬币最有可能产生我们观测到的结果。
对数化的似然函数
实际问题往往要比抛一次硬币复杂得多,会涉及到多个独立事件,在似然函数的表达式中通常都会出现连乘:
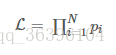
对多项乘积的求导往往非常复杂,但是对于多项求和的求导却要简单的多,对数函数不改变原函数的单调性和极值位置,而且根据对数函数的性质可以将乘积转换为加减式,这可以大大简化求导的过程:
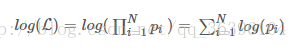
在机器学习的公式推导中,经常能看到类似的转化。
看到这应该不会再那么迷糊了吧~最后再来个例子:
举个别人博客中的例子,假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的比例也不知。我
们想知道罐中白球和黑球的比例,但我们不能把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球
再放回罐中。这个过程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,有七十次是白球,请问罐中白球所占的比例最有可能是多少?很多人马上就有答案了:70%。而其后的理论支撑是什么呢?
我们假设罐中白球的比例是p,那么黑球的比例就是1-p。因为每抽一个球出来,在记录颜色之后,我们把抽出的球放回了罐中并摇匀,所以每次抽出来的球的颜 色服从同一独立分布。这里我们把一次抽出来球的颜色称为一次抽样。题目中在一百次抽样中,七十次是白球的概率是P(Data | M),这里Data是所有的数据,M是所给出的模型,表示每次抽出来的球是白色的概率为p。如果第一抽样的结果记为x1,第二抽样的结果记为x2... 那么Data = (x1,x2,…,x100)。这样,
- 1
- 2
P(Data | M)
= P(x1,x2,…,x100|M)
= P(x1|M)P(x2|M)…P(x100|M)
= p^70(1-p)^30.
那么p在取什么值的时候,P(Data |M)的值最大呢?将p^70(1-p)^30对p求导,并其等于零。
70p^69(1-p)^30-p^70*30(1-p)^29=0。
解方程可以得到p=0.7。
在边界点p=0,1,P(Data|M)=0。所以当p=0.7时,P(Data|M)的值最大。这和我们常识中按抽样中的比例来计算的结果是一样的。
假如我们有一组连续变量的采样值(x1,x2,…,xn),我们知道这组数据服从正态分布,标准差已知。请问这个正态分布的期望值为多少时,产生这个已有数据的概率最大?
P(Data | M) = ?
根据公式

由上可知最大似然估计的一般求解过程:
(1) 写出似然函数;
(2) 对似然函数取对数,并整理;
(3) 求导数 ;
(4) 解似然方程
最大似然估计(Maximum likelihood estimation)(通过例子理解)的更多相关文章
- 最大似然估计 (Maximum Likelihood Estimation), 交叉熵 (Cross Entropy) 与深度神经网络
最近在看深度学习的"花书" (也就是Ian Goodfellow那本了),第五章机器学习基础部分的解释很精华,对比PRML少了很多复杂的推理,比较适合闲暇的时候翻开看看.今天准备写 ...
- 最大似然估计(Maximum likelihood estimation)
最大似然估计提供了一种给定观察数据来评估模型参数的方法,即:"模型已定,参数未知".简单而言,假设我们要统计全国人口的身高,首先假设这个身高服从服从正态分布,但是该分布的均值与方差 ...
- Maximum Likelihood及Maximum Likelihood Estimation
1.What is Maximum Likelihood? 极大似然是一种找到最可能解释一组观测数据的函数的方法. Maximum Likelihood is a way to find the mo ...
- 似然函数 | 最大似然估计 | likelihood | maximum likelihood estimation | R代码
学贝叶斯方法时绕不过去的一个问题,现在系统地总结一下. 之前过于纠结字眼,似然和概率到底有什么区别?以及这一个奇妙的对等关系(其实连续才是f,离散就是p). 似然函数 | 似然值 wiki:在数理统计 ...
- Linear Regression and Maximum Likelihood Estimation
Imagination is an outcome of what you learned. If you can imagine the world, that means you have lea ...
- 均匀分布(uniform distribution)期望的最大似然估计(maximum likelihood estimation)
maximum estimator method more known as MLE of a uniform distribution [0,θ] 区间上的均匀分布为例,独立同分布地采样样本 x1, ...
- 【MLE】最大似然估计Maximum Likelihood Estimation
模型已定,参数未知 已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值.最大似然估计是建立在这样的思想上:已知某个参数能使这个 ...
- 最大似然预计(Maximum likelihood estimation)
一.定义 最大似然预计是一种依据样本来预计模型參数的方法.其思想是,对于已知的样本,如果它服从某种模型,预计模型中未知的參数,使该模型出现这些样本的概率最大.这样就得到了未知參数的预计值. 二 ...
- 机器学习的MLE和MAP:最大似然估计和最大后验估计
https://zhuanlan.zhihu.com/p/32480810 TLDR (or the take away) 频率学派 - Frequentist - Maximum Likelihoo ...
随机推荐
- 4. OpenAI GPT算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- sql操作总结
SQL 语句的多表查询方式例如:按照 department_id 查询 employees(员工表)和 departments(部门表)的信息.方式一(通用型):SELECT ... FROM ... ...
- Javascript模版引擎简介
回顾 Micro-Templating 出自John Resig 2008年的一片文章,以及其经典实现: // Simple JavaScript Templating // John Resig - ...
- JAVA的各种O
转自:http://jeoff.blog.51cto.com/186264/88517/ J2EE开发中大量的专业缩略语很是让人迷惑, 特别是对于刚毕业的新人来说更是摸不清头脑.若与公司大牛谈技术人家 ...
- centos下安装Loadrunner
背景: 网上的资料呀,真是浑水摸鱼的多,有些人直接拷贝别人的帖子,这样有啥意思呢,只会让别人要搜索的时候,更扰乱些! 这里我不写步骤,我用shell把步骤弄了一下,看的懂的看,看不懂的留言吧.就酱,看 ...
- 飞鱼48小时游戏创作嘉年华_厦门Pitch Time总结与收获
一.48小时游戏开发前期准备 1,策划 明确美术队友和程序队友的水平,提需求的过程中尝试做减法,在保留核心玩法的基础上,看队友水平和时间判断是否添加需求. 策划是整个游戏团队的灵魂,也是开发的上限所在 ...
- 第三百九十八节,Django+Xadmin打造上线标准的在线教育平台—生产环境部署CentOS6.5系统环境设置
第三百九十八节,Django+Xadmin打造上线标准的在线教育平台—生产环境部署CentOS6.5系统环境设置 1.Linux安装配置 注意事项: 虚拟机网卡桥接模式 不要拨VPN 如果,网络怎么都 ...
- 第三百九十四节,Django+Xadmin打造上线标准的在线教育平台—Xadmin后台进阶开发配置2,以及目录结构说明
第三百九十四节,Django+Xadmin打造上线标准的在线教育平台—Xadmin后台进阶开发配置2,以及目录结构说明 设置后台列表页面可以直接修改字段内容 在当前APP里的adminx.py文件里的 ...
- SpringBatch的流程简介
SpringBatch的流程图如下: 每个Batch都会包含一个Job.Job就像一个容器,这个容器装了若干Step,Batch中实际干活的也就是这些Step,至于Step干什么活,无外乎读取数据,处 ...
- Ubuntu 14.04 配置VNC服务 配置Xfce4桌面
一.安装配置VNC 1.首先安装VNC apt-get install vnc4server 2.为VNC设置密码 vncpasswd 输入密码,然后再确认一遍,就OK了. 3.启动VNC vncse ...