Python3红楼梦人名出现次数统计分析
一、程序说明
本程序流程是读取红楼梦txt文件----使用jieba进行分词----借助Counter读取各人名出现次数并排序----使用matplotlib将结果可视化
这里的统计除了将“熙凤”出现的次数合并到“凤姐”中外并没有其他处理,但应该也大体能反映人物提及次数情况
二、执行结果展示
条形图:
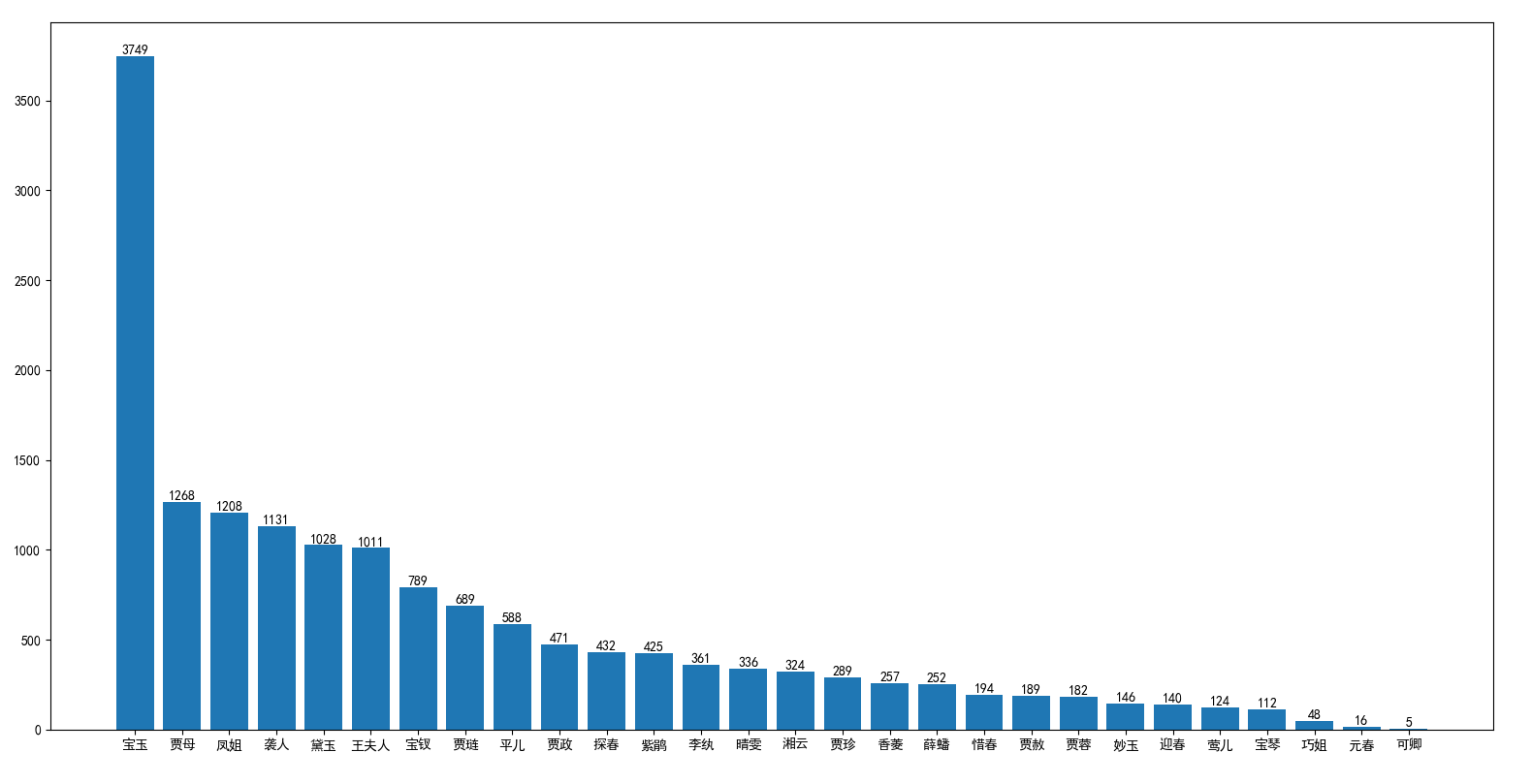
饼状图:
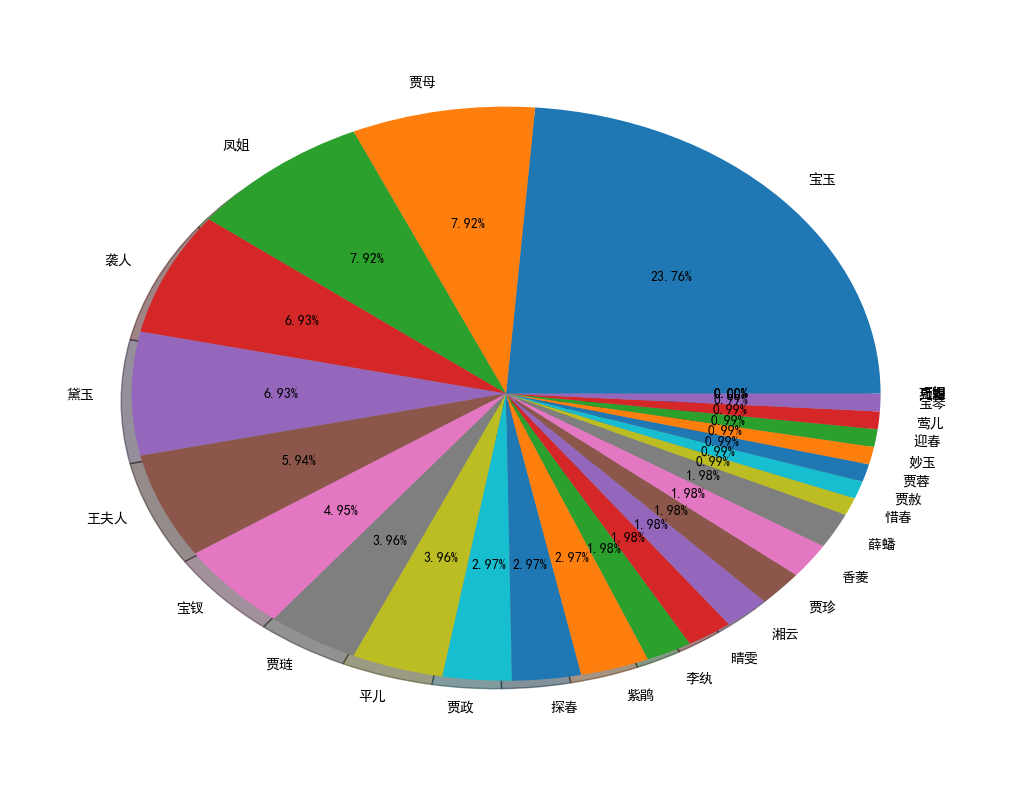
三、程序源代码
import jieba
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np class HlmNameCount():
# 此函数用于绘制条形图
def showNameBar(self,name_list_sort,name_list_count):
# x代表条形数量
x = np.arange(len(name_list_sort))
# 处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制条形图,bars相当于句柄
bars = plt.bar(x,name_list_count)
# 给各条形打上标签
plt.xticks(x,name_list_sort)
# 显示各条形具体数量
i = 0
for bar in bars:
plt.text((bar.get_x() + bar.get_width() / 2), bar.get_height(), '%d' % name_list_count[i], ha='center', va='bottom')
i += 1
# 显示图形
plt.show() # 此函数用于绘制饼状图
def showNamePie(self, name_list_sort, name_list_fracs):
# 处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制饼状图
plt.pie(name_list_fracs, labels=name_list_sort, autopct='%1.2f%%', shadow=True)
# 显示图形
plt.show() def getNameTimesSort(self,name_list,txt_path):
# 将所有人名临时添加到jieba所用字典,以使jieba能识别所有人名
for k in name_list:
jieba.add_word(k)
# 打开并读取txt文件
file_obj = open(txt_path, 'rb').read()
# jieba分词
jieba_cut = jieba.cut(file_obj)
# Counter重新组装以方便读取
book_counter = Counter(jieba_cut)
# 人名列表,因为要处理凤姐所以不直接用name_list
name_dict ={}
# 人名出现的总次数,用于后边计算百分比
name_total_count = 0
for k in name_list:
if k == '熙凤':
# 将熙凤出现的次数合并到凤姐
name_dict['凤姐'] += book_counter[k]
else:
name_dict[k] = book_counter[k]
name_total_count += book_counter[k]
# Counter重新组装以使用most_common排序
name_counter = Counter(name_dict)
# 按出现次数排序后的人名列表
name_list_sort = []
# 按出现次数排序后的人名百分比列表
name_list_fracs = []
# 按出现次数排序后的人名次数列表
name_list_count = []
for k,v in name_counter.most_common():
name_list_sort.append(k)
name_list_fracs.append(round(v/name_total_count,2)*100)
name_list_count.append(v)
# print(k+':'+str(v))
# 绘制条形图
self.showNameBar(name_list_sort, name_list_count)
# 绘制饼状图
self.showNamePie(name_list_sort,name_list_fracs) if __name__ == '__main__':
# 参与统计的人名列表,可修改成自己想要的列表
name_list = ['宝玉', '黛玉', '宝钗', '元春', '探春', '湘云', '妙玉', '迎春', '惜春', '凤姐', '熙凤', '巧姐', '李纨', '可卿', '贾母', '贾珍', '贾蓉', '贾赦', '贾政', '王夫人', '贾琏', '薛蟠', '香菱', '宝琴', '袭人', '晴雯', '平儿', '紫鹃', '莺儿']
# 红楼梦txt文件所在路径,修改成自己文件所在路径
txt_path = 'F:/PycharmProjects/tutorial/hlm.txt'
hnc = HlmNameCount()
hnc.getNameTimesSort(name_list,txt_path)
参考:
https://github.com/fxsjy/jieba
https://docs.python.org/3/library/collections.html#collections.Counter
Python3红楼梦人名出现次数统计分析的更多相关文章
- 用R进行文本分析初探——以《红楼梦》为例
一.写在前面的话~ 刚吃饭的时候同学问我,你为什么要用R做文本分析,你不是应该用R建模么,在我和她解释了一会儿后,她嘱咐我好好写这篇博文,嗯为了娟儿同学,细细说一会儿文本分析. 文本数据挖掘(Text ...
- 红楼梦人物关系图,一代大师成绝响,下回分解待何人,kindle读书摘要
人物关系图: https://www.cnblogs.com/images/cnblogs_com/elesos/1120632/o_2033091006.jpg 红楼梦 (古典名著普及文库) ( ...
- 红楼梦3d游戏
1. 红楼梦大观园2d图 2. 红楼梦3d图 潇湘馆 注册机:根据电脑名和时间生成一个id,然后根据注册机生成注册码.
- iOS_12_tableViewCell的删除更新_红楼梦
终于效果图: Girl.h // // Girl.h // 12_tableView的增删改 // // Created by beyond on 14-7-27. // Copyright (c) ...
- Google BERT应用之《红楼梦》对话人物提取
Google BERT应用之<红楼梦>对话人物提取 https://www.jiqizhixin.com/articles/2019-01-24-19
- 朴素贝叶斯文本分类-在《红楼梦》作者鉴别的应用上(python实现)
朴素贝叶斯算法简单.高效.接下来我们来介绍其如何应用在<红楼梦>作者的鉴别上. 第一步,当然是先得有文本数据,我在网上随便下载了一个txt(当时急着交初稿...).分类肯定是要一个回合一个 ...
- [置顶] 【SQL】查询重复人名的次数并列出
select count(姓名) as 重复次数,姓名from 某表 group by 姓名order by 重复次数 asc 首先,group by 姓名,可以将所有相同姓名的项集合在一起.然后,c ...
- iOS_6_ToolBar+xib+红楼梦
终于效果图 BeyondViewController.h // // BeyondViewController.h // 6_ToolBar // // Created by beyond on 14 ...
- 红楼梦 + 写入 MySQL
import requests import re import pymysql from bs4 import BeautifulSoup conn = pymysql.Connect(host=' ...
随机推荐
- C++类的大小——sizeof(class)
第一:空类的大小 class CBase { }; 运行cout<<"sizeof(CBase)="<<sizeof(CBase)<<endl; ...
- json扩展
using Newtonsoft.Json.Linq; namespace Utility { public static class JsonExt { /// <summary> // ...
- 【Mysql】【Navicat For Mac】Navicat Premium for Mac v12.0.23 + macOS Sierra 10.12.6
参考地址:https://blog.csdn.net/womeng2009/article/details/79700667 [备注]我只用到了部分信息,就激活了 内容: Navicat Premiu ...
- 2018.3 江苏省计算机等级考试 C语言 编程题答案
题目要求:给定一个数字范围,输出满足这些条件: 1.能被3整除: 2.包含数字5, 将满足的数字放在特定的数组里输出.输出这些数里5出现的个数.数字的个数. 想起来有点伤心,本来很简单的题,考试的时候 ...
- CentOS6.5下搭建SVN服务器
1.检查是否已安装 rpm -qa | grep subversion 如果要卸载旧版本: yum remove subversion 2.安装 yum install subversion PS:y ...
- 内连接查询输出到datagridView
实现步骤: 1. 新建两张对应表的类 例如: 第一张表对应的类 { class ManagerInfo { public Table1 group { get; set; } //重点 需要内连接的字 ...
- Qt5标准文件对话框类
getOpenFileName()函数返回用户选择的文件名,其函数形式如下: QString QFileDialog::getOpenFileName(QWidget *parent = Q_NULL ...
- POP3、SMTP和IMAP介绍和设置
什么是POP3.SMTP和IMAP? 参照:http://help.163.com/09/1223/14/5R7P6CJ600753VB8.html 用于 Outlook 的 POP 和 IMAP 电 ...
- 图像识别 | AI在医学上的应用 | 深度学习 | 迁移学习
参考:登上<Cell>封面的AI医疗影像诊断系统:机器之心专访UCSD张康教授 Identifying Medical Diagnoses and Treatable Diseases b ...
- 部署--云服务器(RubyChina上的转帖); 附加用cap部署sidekiq
https://ruby-china.org/topics/36899 附加https://ruby-china.org/topics/36899 Capistrano + Rails5.2部署 使用 ...