CentOS 安装 Hadoop 手记
.png)
.png)
CentOS 安装 Hadoop 手记的更多相关文章
- centos安装hadoop(伪分布式)
在本机上装的CentOS 5.5 虚拟机, 软件准备:jdk 1.6 U26 hadoop:hadoop-0.20.203.tar.gz ssh检查配置 [root@localhost ~]# ssh ...
- 腾讯云CentOS 安装 Hadoop 2.7.3
1.安装 jdk yum install java 2.安装maven wget http://mirrors.hust.edu.cn/apache/maven/maven-3/3.5.0/binar ...
- CentOS 安装 Hadoop
原文地址:http://www.cnblogs.com/caca/p/centos_hadoop_install.html 下载和安装 download hadoop from http://ha ...
- CentOS安装Hadoop
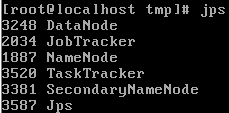
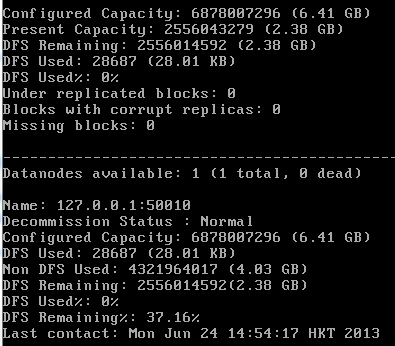
Hadoop的核心由3个部分组成: HDFS: Hadoop Distributed File System,分布式文件系统,hdfs还可以再细分为NameNode.SecondaryNameNode ...
- CentOS安装Hive
1.环境和软件准备: hive版本:apache-hive-2.3.6-bin.tar.gz,下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hive ...
- CentOS下安装hadoop
CentOS下安装hadoop 用户配置 添加用户 adduser hadoop passwd hadoop 权限配置 chmod u+w /etc/sudoers vi /etc/sudoers 在 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- CentOS 7 Hadoop安装配置
前言:我使用了两台计算机进行集群的配置,如果是单机的话可能会出现部分问题.首先设置两台计算机的主机名 root 权限打开/etc/host文件 再设置hostname,root权限打开/etc/hos ...
- 大数据——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
随机推荐
- pytest四:fixture_yield 实现 teardown
既然有 setup 那就有 teardown,fixture 里面的 teardown 用 yield 来唤醒 teardown的执行 在所有用例执行完后执行:yield import pytest ...
- 《剑指offer》-双栈实现队列
题目描述 用两个栈来实现一个队列,完成队列的Push和Pop操作. 队列中的元素为int类型. 很基本的STL容器操作了,应该可以1A的,但是忘记返回值的时候,clang的报错感觉并不友好啊.. cl ...
- Android Strings.xml To CSV / Excel互转
Android Strings.xml To CSV/Excel互转https://blog.csdn.net/hzxpyjq/article/details/50686983https://blog ...
- springmvc文件上传下载简单实现案例(ssm框架使用)
springmvc文件上传下载实现起来非常简单,此springmvc上传下载案例适合已经搭建好的ssm框架(spring+springmvc+mybatis)使用,ssm框架项目的搭建我相信你们已经搭 ...
- mysql 快速拷贝表
- 011 Spark应用构成结构
一:端口4040 1.意思 其中4040端口代表的含义是application UI 是应用程序界面. 包含Jobs,Stages,environment,System,SQL等. 二:应用结构 1. ...
- Scrapy爬虫学习笔记 - 爬虫基础知识
一.正则表达式 二.深度和广度优先 三.爬虫去重策略
- POJ 1384 Piggy-Bank【完全背包】+【恰好完全装满】(可达性DP)
题目链接:https://vjudge.net/contest/217847#problem/A 题目大意: 现在有n种硬币,每种硬币有特定的重量cost[i] 克和它对应的价值val[i]. 每 ...
- HTTP协议学习笔记(三)
HTTP协议学习笔记(三) 1.状态码告知从服务器端返回的请求结果 状态码的职责是当客户端向服务端向服务端发送请求时,描述返回的请求结果.借助状态码,用户可以知道服务端是正常处理了请求,还是出现了错误 ...
- Python Django 学习 (二) 【Django 模型】
注: 由于自己排版确实很难看,本文开始使用markdown编辑,希望有所改善 官方定义 A model is the single, definitive source of information ...