Oracle(2)之多表查询&子查询&集合运算
多表查询
笛卡尔积
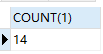
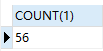
同时查询多张表时,每张表的每条数据都要和其它表的每条数据做组合。如下栗子,我们发现产生的总记录数是 56 条,还发现 emp 表是 14 条,dept 表是 4 条,56 条正是 emp 表和 dept 表的记录数的乘积,这就是笛卡尔积。
select count(1) from dept;

select count(1) from emp;
select count(1) from emp,dept;
例:
连接条件类型
- 等值连接
- 不等值连接
- 外链接
- 自连接
多表基本查询
使用一张以上的表做查询就是多表查询,而多表查询一般则需要通过多表连接来实现。
如果多张表一起进行查询而且每张表的数据很大的话那么该查询的笛卡尔积就会变得非常大,对性能造成影响。而我们仅需要笛卡尔积中部分对我们有用的数据,这时我们可以使用关联查询。
在 emp(员工) 表和 dept(部门) 表中我们会发现有一个共同的字段是 depno,depno 就是两张表关联的字段,用来描述一个员工属于哪个部门。我们可以使用这个字段来做限制条件。
两张表的关联查询字段一般一个是其中一张表的主键,另一个是另一张表的外键。
select e1.ename 员工名字,d1.dname 部门名称,d1.loc 部门地址 from dept d1,emp e1 where d1.deptno = e1.deptno;
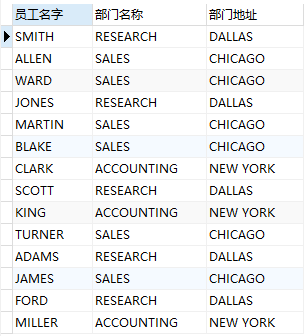
例:查询出员工名字和其所属部门的名称、地址
select e1.ename 员工名字,e2.ename 领导名字 from emp e1,emp e2 where e1.mgr=e2.empno;
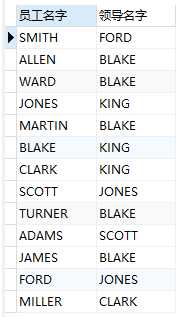
例:查询出每个员工名字和该员工的领导名字
select
e1.ename 员工名字,
d1.dname 所属部门名称,
decode(s1.grade,1,'一级',2,'二级',3,'三级',4,'四级',5,'五级') 员工工资等级,
e2.ename 领导名字,
decode(s2.grade,1,'一级',2,'二级',3,'三级',4,'四级',5,'五级') 领导工资等级
from
emp e1,dept d1,salgrade s1,emp e2,salgrade s2
where
e1.deptno=d1.deptno
and
e1.sal between s1.losal and s1.hisal
and
e1.mgr=e2.empno
and
e2.sal between s2.losal and s2.hisal;
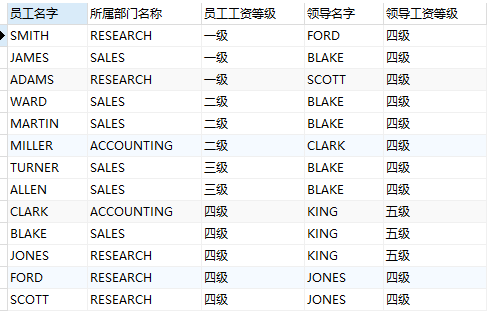
例:查询出每个员工的名字、部门名称、工资等级和该员工的领导名字、工资等级
外连接
在上面‘查询出员工名字和其所属部门的名称、地址’示例中,其中有一个部门是没有员工的,可还是要求要把这个部门显示出来,这时就可以使用右连接:
-- 使用 +
select e1.ename 员工名字,d1.dname 部门名称 from emp e1,dept d1 where e1.deptno(+)=d1.deptno;
-- 使用 right join
select e1.ename 员工名字,d1.dname 部门名称 from emp e1 right join dept d1 on e1.deptno=d1.deptno;
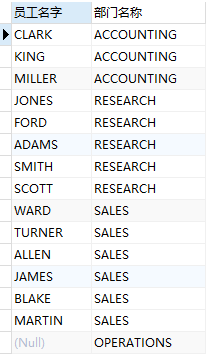
右连接
在上面‘查询出每个员工名字和该员工的领导名字’示例中,其中有一个员工是没有领导的,可还是要求将这个员工显示出来,这时就可以使用左连接:
-- 使用 +
select e1.ename 员工名字,e2.ename 领导名字 from emp e1,emp e2 where e1.mgr=e2.empno(+);
-- 使用 left join
select e1.ename 员工名字,e2.ename 领导名字 from emp e1 left join emp e2 on e1.mgr=e2.empno;
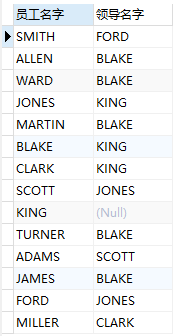
右连接
注意:'+' 方式外连接是 Oracle 数据库独有的。
子查询
select
e1.empno 员工编号,
e1.ename 员工名字,
e1.job 工作,
e1.sal 工资
from
emp e1
where
e1.sal>(select sal from emp e2 where empno=7654)
and
e1.job=(select job from emp e3 where empno=7788)

例:查询出比员工 7654 的工资高,同时从事和 7788 相同工作的员工编号、名字、工作、工资
select
t_min.min_sal 最低工资,
e1.ename 员工名称,
d1.dname 部门名称
from
dept d1,
(select deptno,min(sal) min_sal from emp group by deptno) t_min,
emp e1
where d1.deptno = t_min.deptno
and e1.sal = t_min.min_sal

例:查询每个部门的最低工资、最低工资的员工名称和该员工所属的部门名称
-- 查询有员工的部门
select * from dept d1 where exists (select * from emp e1 where d1.deptno=e1.deptno);
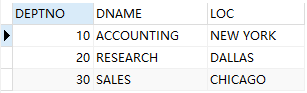
例(exists):查询出有员工的部门
-- 查询员工 7788、7844 的领导信息
select * from emp where empno in(select mgr from emp where empno in (7788,7844));

例(in):查询员工 7788、7844 的领导信息
-- 查询比部门编号为 20 的部门中的所有员工工资都高的员工
select * from emp e1 where e1.sal>all(select sal from emp e2 where e2.deptno=20);

例(all):查询比部门编号为 20 的部门中的所有员工工资都高的员工
-- 查询员工编号为 7844、7900 的员工
select * from emp e1 where e1.empno=any(7844,7900);

例(any):查询员工编号为 7844、7900 的员工
-- 查询是领导的员工
select * from emp where empno in (select mgr from emp);
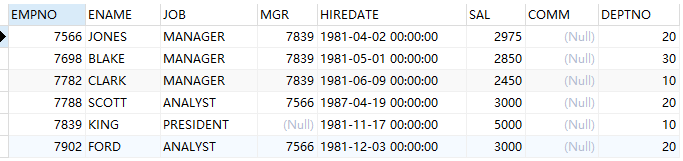
-- 查询不是领导的员工
select * from emp where empno not in (select mgr from emp);

--此时会发现结果为空,查看会发现子查询中存在了 null 值:
select mgr from emp;
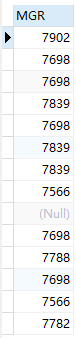
--在 Oracle 中,任何条件与 null 比较结果都为 null ,所以使用在对一个子查询使用 not in 时,应先过滤子查询结果中的 null 值:
select * from emp where empno not in (select mgr from emp where mgr is not null);
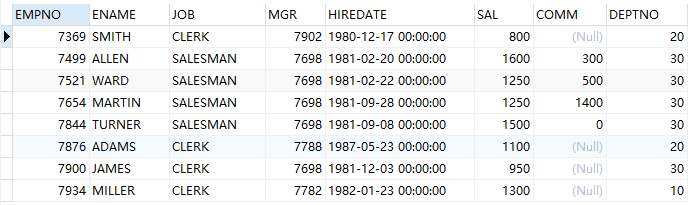
例(not in):查询不是领导的员工
集合运算
-- union :去重排序再合并
(select * from emp where sal>1500)
union
(select * from emp where deptno=20)
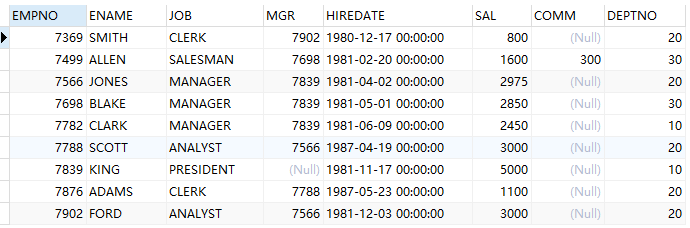
-- union all :不去重直接合并所有
(select * from emp where sal>1500)
union all
(select * from emp where deptno=20)
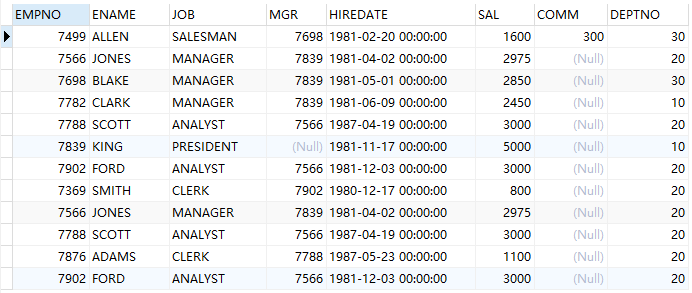
例(union&union all):查询工资大于 1500 或者是编号为 20 的部门下的员工
--查询工资大于1500,且在20号部门下的员工
-- intersect :交集运算
(select * from emp where sal>1500)
intersect
(select * from emp where deptno=20);

例(intersect):查询工资大于1500,且在20号部门下的员工
-- minus :差集运算
(select * from emp where to_char(hiredate,'yyyy')='')
minus
(select * from emp where job='PRESIDENT' or job='MANAGER')
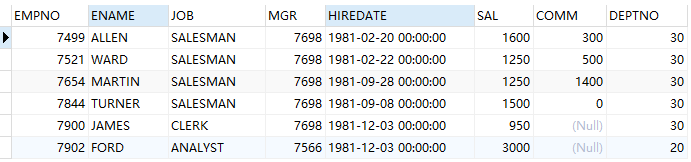
例(minus):查询 1981 年的入职员工,不包括总裁和经理
- 列类型必须一致。
- 列的数量必须一致,如果不足,可用空值填充。
练习
--rownum 是一个伪列,由系统自动生成,用来表示行号。rownum 是 Oracle 中特有的用来表示行号的列,起始值为 1,在查询出结果后再加 1。 -- 查出员工工资最高的前三名并按顺序显示序号
select rownum,e2.* from (select * from emp e1 order by sal desc) e2 where rownum<4;

例(rownum):查询出员工表中工资最高的前三名
-- 查询出薪水大于本部门平均薪水的员工
select * from emp e1,(select deptno,avg(sal) avgsal from emp group by deptno) s1 where e1.deptno=s1.deptno and e1.sal>s1.avgsal

例(avg):查询出薪水大于本部门平均薪水的员工
--例(sum):统计每年入职的员工个数
select to_char(hiredate,'yyyy') year,count(1) count from emp group by to_char(hiredate,'yyyy');
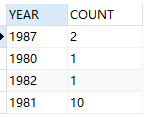
select
sum(decode(year,'',count)) "1987",
sum(decode(year,'',count)) "1980",
sum(decode(year,'',count)) "1981",
sum(decode(year,'',count)) "1982",
sum(count) Total
from
(select to_char(hiredate,'yyyy') year,count(1) count from emp group by to_char(hiredate,'yyyy')) r1;

例(sum):统计每年入职的员工个数
-- 方式一
delete from customer where rowid not in (select min(rowid) from customer group by cname)
-- 方式二
delete from customer c1 where rowid >(select min(rowid) from customer c2 where c1.cname=c2.cname)
例(rowid):删除表中重复的数据
select * from (select rownum hanghao,e1.* from emp e1) e2 where e2.hanghao between 1 and 3;

例(rownum):分页查询
Oracle(2)之多表查询&子查询&集合运算的更多相关文章
- oracle 基础SQL语句 多表查询 子查询 分页查询 合并查询 分组查询 group by having order by
select语句学习 . 创建表 create table user(user varchar2(20), id int); . 查看执行某条命令花费的时间 set timing on: . 查看表的 ...
- sql:除非另外还指定了 TOP 或 FOR XML,否则,ORDER BY 子句在视图、内联函数、派生表、子查询
执行sql语句: select * from ( select * from tab where ID>20 order by userID desc ) as a order by date ...
- Python-select 关键字 多表查询 子查询
sql 最核心的查询语句!!!! 增删改 单表查询 select语句的完整写法 关键字的书写顺序 执行顺序 多表查询 笛卡尔积 内连接 左外连接 右外连接 全外连接 通过合并左外连接和右外连接 子查询 ...
- ORDER BY 子句在视 图、内联函数、派生表、子查询和公用表表达式中无效
SQL语句: select * from (select distinct t2.issue,cashmoney from (select distinct issue from lot_gamepa ...
- [转]sql:除非另外还指定了 TOP 或 FOR XML,否则,ORDER BY 子句在视图、内联函数、派生表、子查询
执行sql语句: select * from ( select * from tab where ID>20 order by userID desc ) as a order by date ...
- [sql Server]除非另外还指定了TOP 或 FOR XML,否则,ORDER BY 子句在视图、内联函数、派生表、子查询和公用表表达式中无效
今天遇到一个奇怪的问题,项目突然要从mysql切换到sql server数据库,包含order by 子句的嵌套子查询报错. 示例:select top 10 name,age,sex from ( ...
- ylb: SQL表的高级查询-子查询
ylbtech-SQL Server: SQL Server- SQL表的高级查询-子查询 SQL Server 表的高级查询-子查询. 1,ylb:表的高级查询-子查询返回顶部 --======== ...
- Oracle的查询-子查询
--子查询 --子查询返回一个值 --查询出工资和scott一样的员工信息 select * from emp where sal in (select sal from emp where enam ...
- mysql中【update/Delete】update中无法用基于被更新表的子查询,You can't specify target table 'test1' for update in FROM clause.
关键词:mysql update,mysql delete update中无法用基于被更新表的子查询,You can't specify target table 'test1' for update ...
- 【数据库】SQL经典面试题 - 数据库查询 - 子查询应用二
上节课我们通过子查询,完成了查询的最高分学生的需求,今天我们来学习子查询的分类,以及通过子查询来完成工作中经常遇到一些个性化需求. 子查询概念: 一个SELECT语句嵌套在另一个SELECT语句中,子 ...
随机推荐
- 15适配器模式Adapter
一.什么是适配器模式 Adapter模式也叫适配器模式,是构造型模式之一 ,通过Adapter模式可以改变已有类(或外部类)的接 口形式. 二.适配器模式应用场景 在大规模的系统开发过程中,我们常常碰 ...
- php 启动服务器监听
使用命令 php -S 域名:端口号 -t 项目路径 截图如下: 原本是通过localhost访问的 现在可以通过 127.0.0.1:8880 访问 此时命令行终端显示如下:
- js 获取验证码计时器
效果图: 贴上代码: <div class="logintitle"> <input type="tel" id="mobile&q ...
- 遍历form表单里面的表单元素,取其value
form.elements 获取所有表单元素 form 表单 <form action="http://localhost:1995/api/post" class=&quo ...
- 三剑客之grep
简介 grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它 ...
- 网络通信协议五之IP协议详解
网络层协议 >>IP协议 >>ARP(地址解析协议) >>RARP(反向地址解析协议) >>ICMP(互联网控制消息协议) IP协议功能 >> ...
- mysql命令大全用户管理相关命令
1.登陆 mysql>mysql -uJDev -p 2.用户管理 mysql>use mysql; 3.查看有哪些登陆用户 mysql> select host,user, ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第二周测验【中英】
[中英][吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第二周测验 第2周测验 - 神经网络基础 神经元节点计算什么? [ ]神经元节点先计算激活函数,再计算线性函数(z = Wx + ...
- POJ 3764 - The xor-longest Path - [DFS+字典树变形]
题目链接:http://poj.org/problem?id=3764 Time Limit: 2000MS Memory Limit: 65536K Description In an edge-w ...
- [No0000149]ReSharper操作指南6/16-编码协助之其他协助
语法高亮 ReSharper扩展了默认Visual Studio的符号高亮显示.此外,它还会使用可配置的颜色突出显示字段,局部变量,类型和其他标识符.例如,ReSharper语法突出显示允许您轻松区分 ...