Redis 搜索引擎优化
场景
大家如果是做后端开发的,想必都实现过列表查询的接口,当然有的查询条件很简单,一条 SQL 就搞定了,但有的查询条件极其复杂,再加上库表中设计的各种不合理,导致查询接口特别难写,然后加班什么的就不用说了(不知各位有没有这种感受呢~)。
下面以一个例子开始,这是某购物网站的搜索条件,如果让你实现这样的一个搜索接口,你会如何实现?(当然你说借助搜索引擎,像 Elasticsearch 之类的,你完全可以实现。但我这里想说的是,如果要你自己实现呢?)

从上图中可以看出,搜索总共分为6大类,每大类中又分了各个子类。这中间,各大类条件之间是取的交集,各子类中有单选、多选、以及自定义的情况,最终输出符合条件的结果集。
好了,既然需求很明确了,我们就开始来实现。
实现1
率先登场是小A同学,他是写 SQL 方面的“专家”。小A信心满满的说:“不就是一个查询接口吗?看着条件很多,但凭着我丰富的 SQL 经验,这点还是难不倒我的。”
于是乎就写出了下面这段代码(这里以 MYSQL 为例):
select ... from table_1
left join table_2
left join table_3
left join (select ... from table_x where ...) tmp_1
...
where ...
order by ...
limit m,n
代码在测试环境跑了一把,结果好像都匹配上了,于是准备上预发。这一上预发,问题就开始暴露出来。预发为了尽可能的逼真线上环境,所以数据量自然而然要比测试大的多。所以这么一个复杂的 SQL,它的执行效率可想而知。测试同学果断把小A的代码给打了回来。
实现2
总结了小A失败的教训,小B开始对SQL进行了优化,先是通过了explain关键字进行SQL性能分析,对该加索引的地方都加上了索引。同时将一条复杂SQL拆分成了多条SQL,计算结果在程序内存中进行计算。
伪代码如下:
$result_1 = query('select ... from table_1 where ...');
$result_2 = query('select ... from table_2 where ...');
$result_3 = query('select ... from table_3 where ...');
...
$result = array_intersect($result_1, $result_2, $result_3, ...);
这种方案从性能上明显比第一种要好很多,可是在功能验收的时候,产品经理还是觉得查询速度不够快。小B自己也知道,每次查询都会向数据库查询多次,而且有些历史原因,部分条件是做不到单表查询的,所以查询等待的时间是避免不了的。
实现3
小C从上面的方案中看到了优化的空间。他发现小B在思路上是没问题的,将复杂条件拆分,计算各个子维度的结果集,最后将所有的子结果集进行一个汇总合并,得到最终想要的结果。
于是他突发奇想,能否事先将各个子维度的结果集给缓存起来,这要查询的时候直接去取想要的子集,而不用每次去查库计算。
这里小C采用 Redis 来存储缓存数据,用它的主要原因是,它提供了多种数据结构,并且在 Redis 中进行集合的交并集操作是一件很容易的事情。
具体方案,如图所示:

这里每个条件都事先将计算好的结果集ID存入对应的key中,选用的数据结构是集合(Set)。查询操作包括:
子类单选:直接根据条件 key,获取对应结果集;
子类多选:根据多个条件 Key,进行并集操作,获取对应结果集;
最终结果:将获取的所有子类结果集进行交集操作,得到最终结果;
这其实就是所谓的反向索引。
这里会发现,漏了一个价格的条件。从需求中可知,价格条件是个区间,并且是无穷举的。所以上述的这种穷举条件的 Key-Value 方式是做不到的。这里我们采用 Redis 的另一种数据结构进行实现,有序集合(Sorted Set):

将所有商品加入 Key 为价格的有序集合中,值为商品ID,每个值对应的分数为商品价格的数值。这样在 Redis 的有序集合中就可以通过ZRANGEBYSCORE命令,根据分数(价格)区间,获取相应结果集。
至此,方案三的优化已全部结束,将数据的查询与计算通过缓存的手段,进行了分离。在每次查找时,只需要简单的查找 Redis 几次就能得出结果。查询速度上符合了验收的要求。
扩展
分页
这里你或许发现了一个严重的功能缺陷,列表查询怎么能没有分页。是的,我们马上来看 Redis 是如何实现分页的。
分页主要涉及排序,这里简单起见,就以创建时间为例。
如图所示:
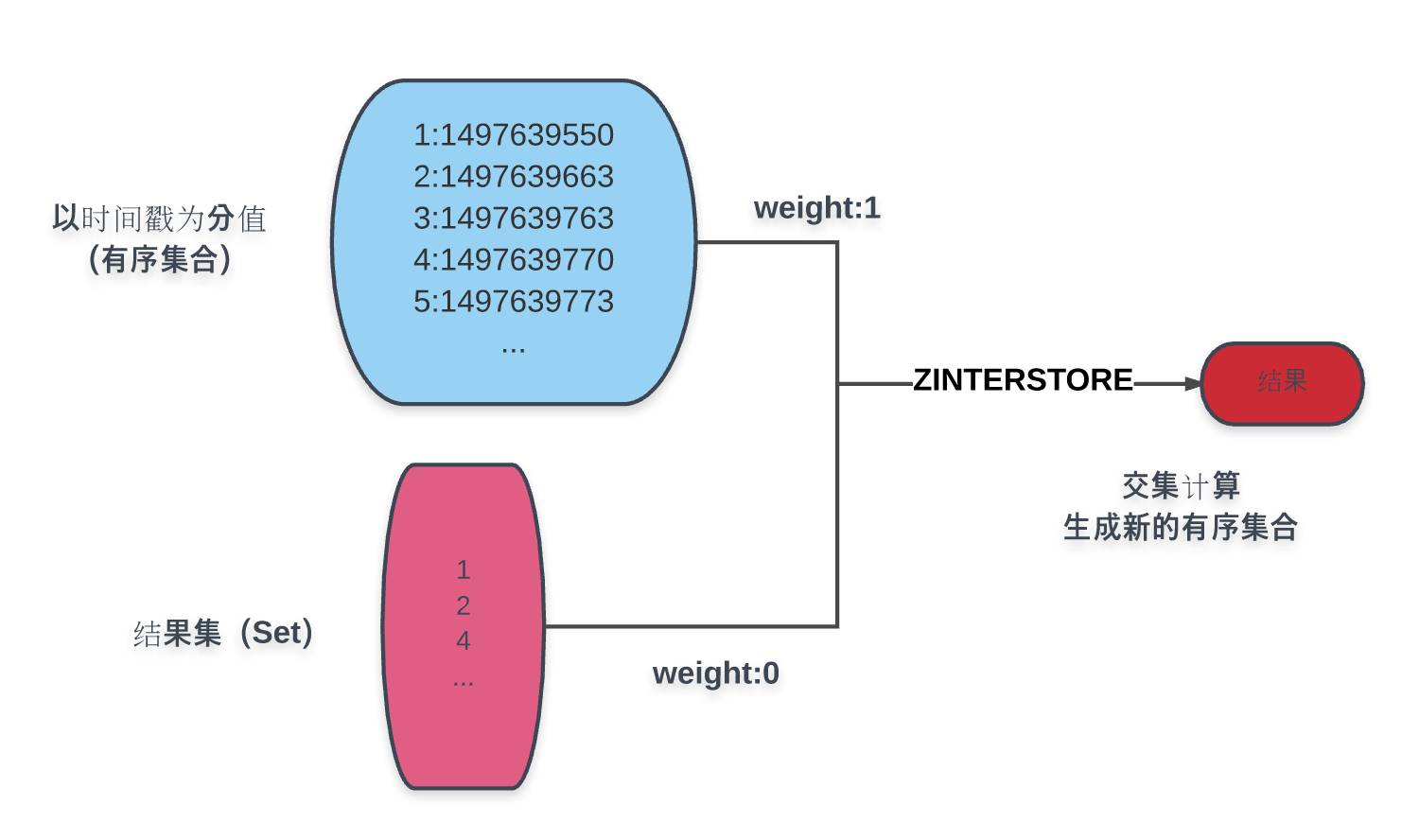
图中蓝色部分是以创建时间为分值的商品有序集合,蓝色下方的结果集即为条件计算而得的结果,通过ZINTERSTORE命令,赋结果集权重为0,商品时间结果为1,取交集而得的结果集赋予创建时间分值的新有序集合。对新结果集的操作即能得到分页所需的各个数据:
页面总数为:ZCOUNT命令
当前页内容:ZRANGE命令
若以倒序排列:ZREVRANGE命令
数据更新
关于索引数据更新的问题,有两种方式来进行。一种是通过商品数据的修改,来即时触发更新操作,一种是通过定时脚本来进行批量更新。这里要注意的是,关于索引内容的更新,如果暴力的删除 Key,再重新设置 Key。因为 Redis 中两个操作不会是原子性进行的,所以中间可能存在空白间隙,建议采用仅移除集合中失效元素,添加新元素的方式进行。
性能优化
Redis 是内存级操作,所以单次的查询会很快。但是如果我们的实现中会进行多次的 Redis 操作,Redis 的多次连接时间可能是不必要时间消耗。通过使用MULTI命令,开启一个事务,将 Redis 的多次操作放在一个事务中,最后通过EXEC来进行原子性执行(注意:这里所谓的事务,只是将多个操作在一次连接中执行,如果执行过程中遇到失败,是不会回滚的)。
总结
这里只是一个采用 Redis 优化查询搜索的一个简单 Demo,和现有的开源搜索引擎相比,它更轻量,学习成本也相应低些。其次,它的一些思想与开源搜索引擎是类似的,如果再加上词语解析,也可以实现类似全文检索的功能。
Redis 搜索引擎优化的更多相关文章
- 知道吗?9个搜索引擎优化(SEO)最佳实践
作为网页设计师,搜索引擎优化重要吗?我们知道,网站设计是把屏幕上平淡无奇变成令人愉快的美感,更直观地辨认信息.这也是人与人之间在沟通想法,这样的方式一直在演变.穴居人拥有洞穴壁画,古埃及人有象形文字, ...
- 总结的一些网站利于搜索引擎优化的小常识及SEO优化
网站利于搜索引擎优化的小常识 1. 尽量用独立IP和空间原因:同IP下其他网站受罚,可能会对你站有影响.如果你的站和很多垃圾.色情站同在一个服务器,搜索引擎会喜欢吗? 2. 做不同内容网站时,避免使用 ...
- 网络爬虫与搜索引擎优化(SEO)
爬虫及爬行方式 爬虫有很多名字,比如web机器人.spider等,它是一种可以在无需人类干预的情况下自动进行一系列web事务处理的软件程序.web爬虫是一种机器人,它们会递归地对各种信息性的web站点 ...
- angularjs应用prerender.io 搜索引擎优化实践
上一篇博文(http://www.cnblogs.com/ideal-lx/p/5625428.html)介绍了单页面搜索引擎优化的原理,以及介绍了两个开源框架的优劣.prerender框架的工作原理 ...
- SEO搜索引擎优化(一)
什么是SEO呢 英文为"Search Engine Optimization",中文名为"搜索引擎优化".SEO是指通过对网站进行站内优化和修复(网站Web结构 ...
- 《SEO教程:搜索引擎优化入门与进阶(第3版)》
<SEO教程:搜索引擎优化入门与进阶(第3版)> 基本信息 作者: 吴泽欣 丛书名: 图灵原创 出版社:人民邮电出版社 ISBN:9787115357014 上架时间:2014-7-1 出 ...
- 网站优化不等于搜索引擎优化SEO
对于SEO相信搞网络营销的人基本上都知道这个名词,英文全称为search engine optimization,中文一般叫搜索引擎优化,也有的叫搜索引擎定位(Search Engine Positi ...
- 网站搜索引擎优化SEO策略及相关工具资源
网站优化的十大奇招妙技 1. 选择有效的关键字: 关键字是描述你的产品及服务的词语,选择适当的关键字是建立一个高排名网站的第一步.选择关键字的一个重要的技巧是选取那些常为人们在搜索时所用到的关键字. ...
- 《SEO深度解析——全面挖掘搜索引擎优化的核心秘密》
<SEO深度解析——全面挖掘搜索引擎优化的核心秘密> 基本信息 作者: 痞子瑞 出版社:电子工业出版社 ISBN:9787121224041 上架时间:2014-2-28 出版日期:201 ...
随机推荐
- 搭建自己的GitHub Pages
本文记录博主使用Win 10操作系统和Jekyll 3.1.2搭建GitHub Pages的过程.希望能帮助到相同有需要的朋友. 基本需求 GitHub账号及一个命名为{GitHub昵称}.githu ...
- 基于zookeeper、连接池、Failover/LoadBalance等改造Thrift 服务化
对于Thrift服务化的改造,主要是客户端,可以从如下几个方面进行: 1.服务端的服务注册,客户端自动发现,无需手工修改配置,这里我们使用zookeeper,但由于zookeeper本身提供的客户端使 ...
- 实战c++中的vector系列--知道emplace_back为何优于push_back吗?
上一篇博客说道vector中放入struct.我们先构造一个struct对象.再push_back. 那段代码中,之所以不能使用emplace_back,就是由于我们定义的struct没有显示的构造函 ...
- Entity Framework(六):数据迁移
在前面的几篇文章中,简单的介绍了如何使用Entity Framework的Code First模式创建数据库,但是,在前面的几篇文章中,我们都是通过使用数据库初始化策略来做,也就是每次先删除数据库然后 ...
- c++开发之对应Linux下的sem_t和lock
http://www.cnblogs.com/P_Chou/archive/2012/07/13/semaphore-and-mutex-in-thread-sync.html http://blog ...
- ti8168平台的tiler memory
DM8168 DMM/TILER简介 1.概述 如图4-1,DMM定位在SDRAM控制器的前端,是所有initiator产生的内存存取的接口. 动态内存管理器DMM,是一个专门的管理模块,广义上说,包 ...
- 【BZOJ】1093: [ZJOI2007]最大半连通子图(tarjan+拓扑序)
http://www.lydsy.com/JudgeOnline/problem.php?id=1093 两个条件综合起来加上求最大的节点数,那么很明显如果是环一定要缩点. 然后再仔细思考下就是求da ...
- shell命令技巧——文本去重并保持原有顺序
简单来说,这个技巧相应的是例如以下一种场景 假设有文本例如以下 cccc aaaa bbbb dddd bbbb cccc aaaa 如今须要对它进行去重处理.这个非常easy,sort -u就能够搞 ...
- 用公式编辑器编辑n元乘积的方法
在数学中经常会出现很多个元素进行求和或者是乘积的情况,但是在整个数学过程中,不可能将所有的元素都写出来,这样很费时费力同时过程也很赘余,不能很好地理解其中的过程,因此数学中对于这一类的多元相加或者相乘 ...
- MyEclipse10.6 安装SVN插件方法及插件下载地址
今天MyEclipse10.6出了点问题,所以重装了它,同一时候也把svn的插件重装了一次,把网上资源和自己的经历顺便在博客这里记录一下.建议直接看方法一好了,简单方便,不必要折腾太多. 下来 ...