Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述
线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x)。
Spark中实现了:
(1)普通最小二乘法
(2)岭回归(L2正规化)
(3)Lasso(L1正规化)。
(4)局部加权线性回归
(5)流式数据可以适用于线上的回归模型,每当有新数据达到时,更新模型的参数,MLlib目前使用普通的最小二乘支持流线性回归。除了每批数据到达时,模型更新最新的数据外,实际上与线下的执行是类似的。
本文采用的符号:

拟合函数
以多变量线性回归为例,对第k个样本进行拟合。拟合函数如下:


岭回归(Ridge)
“是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更稳定、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。”
从上面这段话我们可以看出,全面理解岭回归需要先弄清楚以下一些关键的问题(概念):
(1)什么是共线性数据?
(2)方程组中方程的个数少于特征个数是不是也是类似的情况?
(2)病态矩阵是什么?
(3)什么是有偏估计和无偏估计?
(4)为什么说放弃无偏性就可以使得模型更可靠?
(5)怎么样做才能放弃无偏性,提高模型的稳定性?
下面我们就一个一个问题慢慢探索吧?
(1)共线性数据
共线性数据说白了就是“自变量之间呈现出了某种线性关系”。线性回归模型中的自变量之间由于存在精确相关关系或高度相关关系从而使模型估计失真或难以估计准确。这时候,如果我们计算两个自变量之间的相关性系数,可以发现他们之间线性相关系数很高 。这在构建多元线性回归模型时,随着自变数目变得非常庞大,其中某些个自变量之间产生共线性是很容易发生的情况。
那么它究竟是如何使得传统的最小二乘法线性回归模型失真的呢?任何时候,我不希望抄一个公式来就来说明某个道理,虽然这样的回答是最简单的,但是我们还是希望把背后隐藏的道理搞明白先搞明白,公式自然而然就出来了,不是先有公式,才有道理,而是明白了某个道理,在此指引下,才推导出某个公式,数学公式往往是朴素道理的凝炼和精华,是极其美丽但又非常隐晦的诗句,所以如果从公式本身出发,一下子千头万绪砸在心头,是很难理解的。比如说刚才提到的这个问题,如果用公式来回答,因为此时计算(XTX)−1会出错,所以需要加一个λI项使得矩阵非奇异,进而可以对(XTX+λI)求逆,即
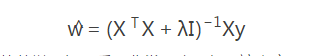
,岭回归的公式就这样冒出来了!!!虽然从数学逻辑上看,非常正确,但是这究竟是一个什么鬼?他又是如何想到的,为什么要这样做而不是那样做,等等诸多问题,其实这个公式本身什么都回答不了。所以我自己理解问题的习惯,是摒弃这种靠推公式来理解问题的做法,零基础小白版的机器学习或统计学学习,即用最朴素的思想去理解机器学习或统计学,未必不是一种笨拙的智慧,当然在理解朴素道理的情况下,还是应该仔细推导公式,其实这时推导公式其实更easy。
对于共线性数据,在最小二乘法失效的情况下,也研究出了很多方法进行参数估计,但是机器学习里面,我们通常用主成分方法和岭回归方法等方法代替传统的最小二乘方法对模型的参数进行估计。
(2)欠定方程组的情况
还有一种情况与共线性数据有所不同,也是岭回归适合解决的问题,在这里提一下:当样本点比较少,而特征比较多,特征个数多于样本个数,这时候输入数据的矩阵X是非满秩的,最直白的话就是方程的个数少于未知数,也就是欠定方程组,理论上应该有无穷多解。这时候最小二乘法同样是失效的。
我们需要注意到的最小二乘法是为了解决超定方程组而提出来的,即方程个数大于未知量个数的方程组,这时一般是不存在解的矛盾方程组,例如,如果给定的三点不在一条直线上, 我们将无法得到这样一条直线,使得这条直线同时经过给定这三个点。 也就是说给定的条件(限制)过于严格, 导致解不存在。在实验数据处理和曲线拟合问题中,求解超定方程组非常普遍。比较常用的方法是就是最小二乘法。形象的说,就是在无法完全满足给定的这些条件的情况下,求一个最接近的解(来自http://blog.sina.com.cn/s/blog_531bb7630100xx6c.html)。
lasso回归
从统计学的语言描述:Tibshirani(1996)提出了Lasso(The Least Absolute Shrinkage and Selectionator operator)算法。这种算法通过构造一个惩罚函数获得一个精炼的模型;通过最终确定一些指标的系数为零,Lasso算法实现了指标集合精简的目的。
Lasso的损失函数加L1正则化项:
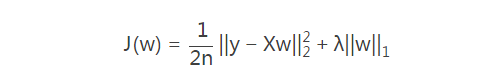
其实就是对所有回归系数w的绝对值进行了大小限定,也就是缩减技术。
Lasso回归和岭回归最重要的区别是,岭回归中随着惩罚项增加时,所以项都会减小,但是仍然保持非0的状态,然而Lasso回归中,随着惩罚项的增加时,越来越多的参数会直接变为0,正是这个优势使得lasso回归容易用作特征的选择(对应参数非0项),因此lasso回归可以说能很好的保留那些具有重要意义的特征而去掉那些那些意义不大甚至毫无意义的特征(如果是超多维的稀疏矩阵,这难道不是在垃圾中寻找黄金的“掘金术”吗?),而岭回归永远不会认为一个特征是毫无意义的。
在某些情况下,L1正则化真是非常好的一个东西啊,因为他的本领和解决问题的绝招就是倾向于将越多的参数变为0,也就意味着最终的近似解只依赖很少的变量,所以它也是最近时间很火的压缩感知的基石,抓住事物的本质,抓住主要矛盾,也许有时候面面俱到(比如说什么特征都照顾到)反而什么认识也得不出,所以我不成熟的认识是:L1正则化从实现层面上,提出了一个非常好的技术路线,从而实现了马克思主义哲学上的如何“抓主要矛盾”,诸多感慨就是,看了大量机器学习算法,降维,投影或者影射(嵌入),缩减,压缩,隐含变量近似分解等思想随处可见,似乎让我感觉到在某种思想的指引下,这些方法心有灵犀,但是也有一个担忧就是感觉,机器学习的算法总是跳不出这个逻辑框架和圈子,虽然形式看丰富多彩,效果也在一定程度上各异,但我还是希望能看到更多的完全不一样的逻辑框架和思路,害怕我们在进行循环证实或者说“小修小补”,而没有全新的革命性突破,没有进行基因“突变”,类似于“收敛到一个局部最优解”,我们是不是应该像遗传算法中的“灾变”那样勇敢地跳出来?从这个角度来说,我个人比较偏爱深度学习,尤其是那个琢磨不定的人工神经网络模型(虽然不喜欢他还是采用了和Logist回归中类似的Sigmoid函数来模拟神经元的输出),不好意思,跑偏了。
One of the prime differences between Lasso and ridge regression is that in ridge regression, as the penalty is increased, all parameters are reduced while still remaining non-zero, while in Lasso, increasing the penalty will cause more and more of the parameters to be driven to zero. This is an advantage of Lasso over ridge regression, as driving parameters to zero deselects the features from the regression. Thus, Lasso automatically selects more relevant features and discards the others, whereas Ridge regression never fully discards any features.
The L1-regularized formulation is useful in some contexts due to its tendency to prefer solutions where more parameters are zero, which gives solutions that depend on fewer variables.[8] For this reason, the Lasso and its variants are fundamental to the field of compressed sensing. An extension of this approach is elastic net regularization.(https://en.wikipedia.org/wiki/Least_squares#Lasso_method)
杨灿写的《统计学习那些事》一文, 一定要看看,文中对许多方法的内在联系有一个概要的阐述:
”Tibshrani自己说他的Lasso是受到Breiman的Non-NegativeGarrote(NNG)的启发。Lasso把NNG的两步合并为一步,即L1-normregularization。Lasso的巨大优势在于它所构造的模型是Sparse的,因为它会自动地选择很少一部分变量构造模型。”
L1,L2正则化与稀疏解
参考引用了参考文献4,知乎上的内容: http://freemind.pluskid.org/machine-learning/sparsity-and-some-basics-of-l1-regularization/ ;https://www.zhihu.com/question/37096933?sort=created
实际上在前面比较Lasso和岭回归时,已经对L1,L2正则化与稀疏解有了阐述,下面进一步从稀疏解的角度分析,分析L1,L2。
机器学习问题中,具有非常高维度的数据随处可见。例如,在文档或图片分类中常用的bag of words 模型里,如果词典的大小是一百万,那么每个文档将由一百万维的向量来表示。因此在bag of words模型中文档向量通常都是非常稀疏的。再例如在许多生物相关的问题中,数据的维度非常高,但是由于收集数据需要昂贵的实验,因此可用的训练数据却相当少,也是一个典型的高维度稀疏数据。
这样的问题通常称为“small n, large p problem”——用n 表示数据点的个数,用p 表示变量的个数,即数据维度。**当p ≫ n 的时候,不做任何其他假设或者限制的话,学习问题基本上是没法进行的。
在线性回归中,从 w^=(XTX)−1Xy可以看出:只要p > n,或者XTX不满秩 的话,就存在无穷多个解,说白了就是你的数据不足以得出一个确定的解。所以我们需要再增加约束,正则化就是加约束,加约束的目的就是为了从无数个解中最终选出一个来。就像是某些单位招聘,前来应聘的人很多,都满足所要求的学历,工作经历等条件(就好比线性回归中有无数个w 都满足wTx=y )那么岗位只有一个,这时候怎么办呢?这时候某领导的智慧就体现出来了,“加约束条件吧!”,这位领导发话了,“普通高校全日制应届本科毕业生,获得国外学士学位,机器学习专业,能解释明白L1和L2正则化的区别,明白L1正则化约束条件||w||1<C)有什么优缺点。XX户籍,女,年龄25周岁以下。”,在这样严苛的条件下,总算是把唯一的一个“合格者w 向量”选拔出来了。
在接下来具体分析L1,L2正则化之前,我们还需要明白一个概念,什么是稀疏解?文献4用了一个很形象的例子:像生物或者医学等通常需要和人交互的领域,稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”。比如说,一个病如果依赖于5 个变量的话,将会更易于医生理解、描述和总结规律,但是如果依赖于5000 个变量的话,基本上就超出医生可处理的范围了。
稀疏解也可以从过拟合的角度去理解,如果给你一个1万维的稀疏数据,最后总你拟合的模型用到了其中的5000个变量(f(X)=∑5000i=1wixi+b ,模型包含5000个系数,由于数据是稀疏的,很显然这样的模型过拟合了稀疏数据,泛化能力(模型预测能力)一定不行的。合适的解应该是这样的,他自动找出了对y影响最大的,最主要的几个特征,比如是5个,而忽略其它的影响,建立了f(X)=∑5i=1wixi+b 这样一个预测模型,那么这个模型的泛化能力,显然会好得多(抓住问题的主要矛盾)。
L1正则化可以得到一个稀疏解释,而L2正则化就不容易获得稀疏解,怎么理解这个事情?好像不太容易,我结合网上的一些文献和知乎的讨论,认识以下三个角度都是可以解释这个问题,把这仨放在一起,大家可以都看一看,便于理解问题的本质。
(1)几何角度直观理解:
《The Elements of Statistical Learning(Second Edition) 》应该算是最权威的一个解释了吧,从几何上理解清楚了,就不会有什么疑问了! 


这里考虑了一个二维时候的情况,左图是lasso回归,右图是岭回归,lasso回归等价于下面的问题。

最有意思的情况出现了:
可以看到,菱形(L1)与圆形(L2)的不同就在于他在和每个坐标轴相交的地方都有“角” 出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交。注意到在角的位置为产生稀疏性,例如图中的相交点就有β=0 ,而更高维的时候(想象一下三维的菱形是什么样的?见下图,是不是产生更多的稀疏性?!!!)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性。
相比之下,圆形(L2)就没有这样的性质β1,β2都不为0,因为没有”角”,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。这就从直观上来解释了为什么L1 regularization 能产生稀疏性,而L2 regularization 不行的原因了。

四幅分别为p=2(L2),p=1.5,p=1(L1),p=0.7,来自:
http://blog.sina.com.cn/s/blog_82a927880102vb7j.html
如果s.t.|β1|+|β2|≤t中的t不断变化(t即下图中的L1 Arc Length,和J(w)=12n||y−Xw||22+λ||w||1中的正则化参数λ一一对应),那么下图则展示了如果搜索到不同t时,系数(\beta_1^,\beta_2^)的变化。 
(注:LAR方法与Lasso有相似的路径,LAR不是本文的谈论范围)
(2)凸优化角度:
主要是参考了知乎上的回答,上面的讨论非常专业,给理解这个问题帮助很大。
假设原先损失函数是C0,那么在L2和L1正则条件下对参数求导分别是:

L2:可以想象用梯度下降的方法,当w小于1时,(1−ηλn)w减小量越来越小,无法将任何一个系数wi项减小到0,通俗理解为对所有系数同等的缩放。
L1方法中,使用了sgn函数,(−ηλn)sgn(w),可以理解在某次迭代中,对有的系数减少(sgn(wi)=1,实施惩罚),另一些系数增加(sgn(wi)=−1),这样经过反复迭代,就好比经历了层层选拔,过五关斩六将毕竟是很难的,大部分系数变为0了,只有少部分特征对应的系数不为0,从而达到了良好的缩减系数的目的。
(3)先验分布的角度
内容比较多,直接参见文献10 http://charleshm.github.io/2016/03/Regularized-Regression/ 写的非常详细。
正则化参数等价于对参数引入先验分布,使得模型复杂度变小(缩小解空间),对于噪声以及 outliers 的鲁棒性增强(泛化能力)。整个最优化问题从贝叶斯观点来看是一种贝叶斯最大后验估计,其中 正则化项 对应后验估计中的 先验信息,损失函数对应后验估计中的似然函数,两者的乘积即对应贝叶斯最大后验估计的形式【摘自文献10】。
作者:Charles Xiao
链接:https://www.zhihu.com/question/23536142/answer/90135994
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
局部加权线性回归
局部加权的目的:降低预测的均方误差,减小欠拟合现象(如下图,显然是需要改进回归算法的)。 
加权方法:局部加权线性回归(Locally Weighted Liner Regression,LWLR)在该算法中,我们给待预测点附近的每个点赋予一定的权重,然后利用计算最小均方差来进行普通的回归。
LWLR使用核来对附近的点赋予更高的权重,最常用的核方法是高斯核,其对应的权重如下:

这样就构建了一个只含对角线元素的权重矩阵w,并且点x与x(i)越近,w(i,i)将会越大,上述公式包含一个需要用户指定的参数k,他决定了对附近的点赋予多大的权重,这也是使用LWLR时唯一需要考虑的参数,下图展示了参数k与权重的关系。 


回归结果评估
Spark2.0中代码
对于Spark中一个算法中有那些参数可以设置?
val lr=new LinearRegression()
println(lr.explainParams())
首先建立一个模型,然后用explainParams就可以查看全部可以设置的参数:
(1)elasticNetParam: the ElasticNet mixing parameter, in range [0, 1]. For alpha = 0, the penalty is an L2 penalty. For alpha = 1, it is an L1 penalty (default: 0.0)
(2)featuresCol: features column name (default: features)
(3)fitIntercept: whether to fit an intercept term (default: true)(是否拟合截距,默认选择”是“)
(4)labelCol: label column name (default: label)
(5)maxIter: maximum number of iterations (>= 0) (default: 100)(最大迭代次数)
(6)predictionCol: prediction column name (default: prediction)
(7)regParam: regularization parameter (>= 0) (default: 0.0)
(8)solver: the solver algorithm for optimization. If this is not set or empty, default value is ‘auto’ (default: auto)
(9)standardization: whether to standardize the training features before fitting the model (default: true)(是否进行标准化,默认选择“是”,由于使用L1、L2正则化进行“缩减技术”的前提是首先要进行标准化,所以默认就好,不需要(甚至可以说不可以)改它)
(10)tol: the convergence tolerance for iterative algorithms (default: 1.0E-6)
(11)weightCol: weight column name. If this is not set or empty, we treat all instance weights as 1.0 (undefined)
线性回归重要的一些参数:
一定要使用正则化来避免模型的过拟合,相关的两个参数如下:
(1)elasticNetParam(α ):用L1,L2两种正则化方法混合来完成,其比例就是α 。设置为0,相当于L2正则化,此时对应的是ridge模型;设置为1相当于L1正则化,对应的是 Lasso回归。当然可以设置为[0,1]之间的任意数值。
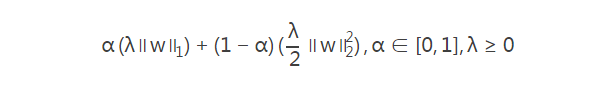
L2-regularized problems are generally easier to solve than L1-regularized due to smoothness. However, L1 regularization can help promote sparsity in weights leading to smaller and more interpretable models, the latter of which can be useful for feature selection. Elastic net is a combination of L1 and L2 regularization. It is not recommended to train models without any regularization, especially when the number of training examples is small。
(2)regParam(λ ):正则化参数的大小。
(3)算法
Under the hood, linear methods use convex optimization methods to optimize the objective functions. spark.mllib uses two methods, SGD and L-BFGS, described in the optimization section. Currently, most algorithm APIs support Stochastic Gradient Descent (SGD), and a few support L-BFGS. Refer to this optimization section for guidelines on choosing between optimization methods.
import org.apache.spark.sql.SparkSession
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.regression.LinearRegression object linearRegressin { def main(args:Array[String]){
//屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF) val warehouseLocation = "file///:G:/Projects/Java/Spark/spark-warehouse" val spark=SparkSession
.builder()
.appName("myLinearRegression")
.master("local[4]")
.config("spark.sql.warehouse.dir",warehouseLocation)
.getOrCreate();
val training=spark.read.format("libsvm").load("/data/mllib/sample_linear_regression_data.txt") val lr=new LinearRegression()
.setMaxIter()
.setElasticNetParam(0.3)//alpha: 0-ridge;1-lasso;
.setRegParam(0.5)//正则化参数lambda
//.setSolver("l-bfgs")//default:l-bfgs,还可选sgd val lrModel=lr.fit(training) // Print the coefficients and intercept for linear regression
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}") // Summarize the model over the training set and print out some metrics
val trainingSummary = lrModel.summary
println(s"numIterations: ${trainingSummary.totalIterations}")
println(s"objectiveHistory: ${trainingSummary.objectiveHistory.toList}")
trainingSummary.residuals.show()
println(s"RMSE: ${trainingSummary.rootMeanSquaredError}")
println(s"r2: ${trainingSummary.r2}") //println(lr.explainParams())
}
}
参考文献:
(1)《统计学习那些事》 杨灿 非常推荐看看这篇文章,对Lasso方法有非常不一样的认识
http://wenku.baidu.com/link?url=iJwMSLgXVTDwaO66LF1iHUmmvd6qe-ttIoNHTVk8wlt1Dzhg4_7yUcHJ3TNNAIqvR-k9qJK_qZKsH-WDsZ0cBAsQUv3xANCaaulQ9p1cQx7
(2)legotime的CSDN博客 SparkML之回归(一)线性回归
http://blog.csdn.net/legotime/article/details/51836008
(3)线性回归、分类、逻辑回归、回归
http://blog.sina.com.cn/s/blog_9ca9623b0102wgt2.html
(4)http://freemind.pluskid.org/machine-learning/sparsity-and-some-basics-of-l1-regularization/ 理解L1正则化非常好的材料
(5)知乎关于稀疏解的讨论https://www.zhihu.com/question/37096933?sort=created
(6)稀疏解的几何理解 ,DavFrank的博客http://blog.sina.com.cn/s/blog_82a927880102vb7j.html
(7)Lasso Regression http://blog.csdn.net/daunxx/article/details/51596877 各种参数实验,python代码,还介绍了最小角回归,值得仔细学习。
(8)机器学习中的范数规则化之(一)L0、L1与L2范数 http://blog.csdn.net/zouxy09/article/details/24971995/
(9)http://blog.csdn.net/zouxy09/article/details/24972869
(10)http://charleshm.github.io/2016/03/Regularized-Regression/ Regularized Regression: A Bayesian point of view 完整的分析从数据贝叶斯先验分布的角度去认识正则化。
Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解的更多相关文章
- Spark2.0机器学习系列之10: 聚类(高斯混合模型 GMM)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet allocation (LDA) ...
- Spark2.0机器学习系列之1: 聚类算法(LDA)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet allocation (LDA) ...
- Spark2.0机器学习系列之11: 聚类(幂迭代聚类, power iteration clustering, PIC)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet all ...
- Spark2.0机器学习系列之9: 聚类(k-means,Bisecting k-means,Streaming k-means)
在Spark2.0版本中(不是基于RDD API的MLlib),共有四种聚类方法: (1)K-means (2)Latent Dirichlet allocation (LDA) ...
- Spark2.0机器学习系列之7: MLPC(多层神经网络)
Spark2.0 MLPC(多层神经网络分类器)算法概述 MultilayerPerceptronClassifier(MLPC)这是一个基于前馈神经网络的分类器,它是一种在输入层与输出层之间含有一层 ...
- Spark2.0机器学习系列之6:GBDT(梯度提升决策树)、GBDT与随机森林差异、参数调试及Scikit代码分析
概念梳理 GBDT的别称 GBDT(Gradient Boost Decision Tree),梯度提升决策树. GBDT这个算法还有一些其他的名字,比如说MART(Multiple Addi ...
- Spark2.0机器学习系列之5:随机森林
概述 随机森林是决策树的组合算法,基础是决策树,关于决策树和Spark2.0中的代码设计可以参考本人另外一篇博客: http://www.cnblogs.com/itboys/p/8312894.ht ...
- Spark2.0机器学习系列之4:Logistic回归及Binary分类(二分问题)结果评估
参数设置 α: 梯度上升算法迭代时候权重更新公式中包含 α : http://blog.csdn.net/lu597203933/article/details/38468303 为了更好理解 α和 ...
- Spark2.0机器学习系列之3:决策树
概述 分类决策树模型是一种描述对实例进行分类的树形结构. 决策树可以看为一个if-then规则集合,具有“互斥完备”性质 .决策树基本上都是 采用的是贪心(即非回溯)的算法,自顶向下递归分治构造. 生 ...
随机推荐
- php 的rabbitmq 扩展模块amqp安装
php 的rabbitmq 扩展模块amqp安装 2017年10月08日 10:34:22 阅读数:240 使用PHP开发,要使用中间队列rabbitmq, 必须要安装PHP的扩展模块amqp, 服务 ...
- MyBatis 使用简单的 XML或注解用于配置和原始映射
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis .My ...
- 自定义 httpHandler 配置
开发 环境 vs2010.asp.net 4.0 时 写在<system.web> ,<httpHandlers>节点下 部署 环境Windows server 2007 , ...
- hdu 3008:Warcraft(动态规划 背包)
Warcraft Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Su ...
- 设置Android程序图标和程序标题
修改程序名称 在/res/values/strings.xml中修改程序名称,例如: <string name="app_name">你的程序名称</string ...
- Java Tomcat 注册为Windows系统服务
注册方法: 1. 在DOS命令行模式下,cd到tomcat的bin目录下 cd tomcatpath 根目录加:后回车 进入到tomcat安装目录,cd bin,进入tomcat启动目录 2.在tom ...
- Oracle中select使用别名
1 .将字段用as转换成别名. 2 .直接在字段的名字后面跟别名. 3 .在字段后面用双引号引起的别名. 我的朋友 大鬼不动 最近访客 fhwlj kochiyas 大極星 Alz__ deser ...
- webstorm配置内存参数,解决卡顿
找到WebStorm.exe.vmoptions这个文件,路径如下webstorm安装主目录>bin>WebStorm.exe.vmoptions更改为第二行:-Xms526m第三行:-X ...
- js apply()、call() 使用参考
引入,求一个数组的最大值,有这么一种快捷方法:Math.max.apply(null,arr); 但是最初看 JavaScript高级程序设计 的时候,没看懂,原文(斜体表示)如下: 每个函数都包含两 ...
- jdk1.7访问https报javax.net.ssl.SSLHandshakeException: Received fatal alert: handshake_failure问题解决
本地jdk版本java version "1.8.0_31",代码中已对https做了相应处理:信任所有来源证书,运行正常:上包到服务器(服务器jdk版本java version ...