去除 \ufeff
语言:python
编程工具:pycharm
硬件环境:win10 64位
读取文件过程中发现一个问题:已有记事本文件(非空),转码 UTF-8,复制到pycharm中,在开始位置打印结果会出现 \ufeff, 打印代码如下
f = open('new2.txt', encoding='UTF-8') # 打开文件,以 UTF-8 编码
l = []
for line in f:
l.append(line.strip())
print(l)
打印结果为:

只需改一下编码就行,把 UTF-8 编码 改成 UTF-8-sig
f = open('new2.txt', encoding='UTF-8-sig')
l = []
for line in f:
l.append(line.strip())
print(l)
打印结果为:

utf-8与utf-8-sig两种编码格式的区别:
As UTF-8 is an 8-bit encoding no BOM is required and anyU+FEFF character in the decoded Unicode string (even if it’s the firstcharacter) is treated as a ZERO WIDTH NO-BREAK SPACE.
UTF-8以字节为编码单元,它的字节顺序在所有系统中都是一様的,没有字节序的问题,也因此它实际上并不需要BOM(“ByteOrder Mark”)。但是UTF-8 with BOM即utf-8-sig需要提供BOM。
关于 \ufeff 的一些资料(引自维基百科):
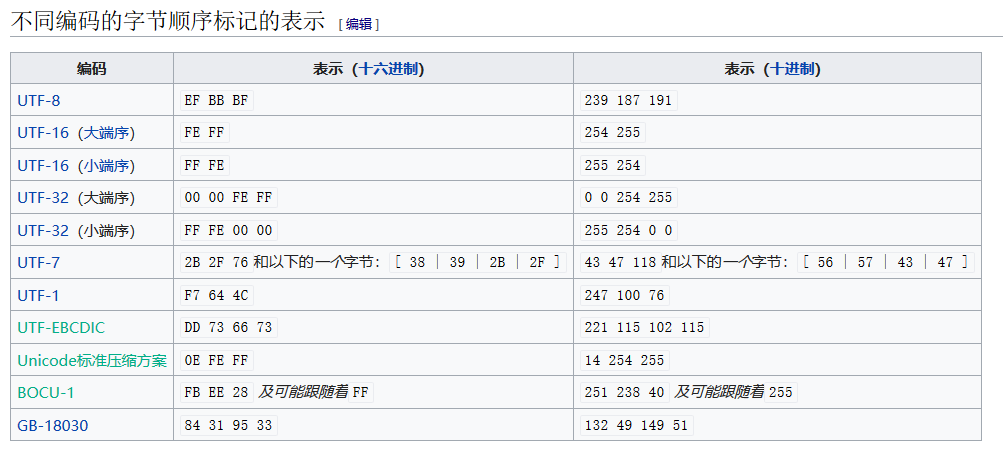
字节顺序标记(英语:byte-order mark,BOM)是位于码点U+FEFF的统一码字符的名称。当以UTF-16或UTF-32来将UCS/统一码字符所组成的字符串编码时,这个字符被用来标示其字节序。它常被用来当做标示文件是以UTF-8、UTF-16或UTF-32编码的记号。
字符U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序,是高位在前还是低位在前。如果它出现在字节流的中间,则表达零宽度非换行空格的意义,用户看起来就是一个空格。从Unicode3.2开始,U+FEFF只能出现在字节流的开头,只能用于标识字节序,就如它的名称——字节序标记——所表示的一样;除此以外的用法已被舍弃。取而代之的是,使用U+2060来表达零宽度无断空白。
在UTF-16中,字节顺序标记被放置为文件或字符串流的第一个字符,以标示在此文件或字符串流中,以所有十六比特为单位的字码的尾序(字节顺序)。
- 如果十六比特单位被表示成大尾序,这字节顺序标记字符在序列中将呈现
0xFE,其后跟着0xFF(其中的0x用来标示十六进制)。 - 如果十六比特单位使用小尾序,这个字节序列为
0xFF,其后接着0xFE。
而统一码中,值为U+FFFE的码位被保证将不会被指定成一个统一码字符。这意味着0xFF、0xFE将只能被解释成小尾序中的U+FEFF(因为不可能是大尾序中的U+FFFE)。
UTF-8则没有字节顺序的议题。UTF-8编码过的字节顺序标记则被用来标示它是UTF-8的文件。它只用来标示一个UTF-8的文件,而不用来说明字节顺序。[1]许多视窗程序(包含记事本)会添加字节顺序标记到UTF-8文件。然而,在类Unix系统(大量使用文本文件,用于文件格式,用于进程间通信)中,这种做法则不被建议采用。因为它会妨碍到如解译器脚本开头的Shebang等的一些重要的码的正确处理。它亦会影响到无法识别它的编程语言。如gcc会报告源码档开头有无法识别的字符。而在PHP中,如果没有激活输出缓冲(output buffering),它会使得页面内容开始被送往浏览器(即:用户头文件已被提交),这使PHP脚本无法指定用户头文件(HTTP Header)。字节顺序标记在UTF-8中被表示为序列EF BB BF,对大部分未准备好处理UTF-8的文本编辑器及网页浏览器而言,在ISO-8859-1的环境中则会显示。
虽然字节顺序标记亦可以用于UTF-32,但这个编码很少用于传输,其规则如同UTF-16。对于已于IANA注册的字符集UTF-16BE、UTF-16LE、UTF-32BE和UTF-32LE等来说,不可使用字节顺序标记。文档开头的U+FEFF会被解释成一个(已舍弃的)"零宽度无断空白",因为这些字符集的名字已决定了其字节顺序。对于已注册字符集UTF-16和UTF-32来说,一个开头的U+FEFF则用来表示字节顺序。
去除 \ufeff的更多相关文章
- python去除\ufeff、\xa0、\u3000
今天使用python处理一个txt文件的时候,遇到几个特殊字符:\ufeff.\xa0.\u3000,记录一下处理方法 代码:with open(file_path, mode='r') as f: ...
- 去除\ufeff的解决方法,python语言
语言:python 编程工具:pycharm 硬件环境:win10 64位 读取文件过程中发现一个问题:已有记事本文件(非空),转码 UTF-8,复制到pycharm中,在开始位置打印结果会出现 \ ...
- python去除BOM头\ufeff等特殊字符
1.\ufeff 字节顺序标记 去掉\ufeff,只需改一下编码就行,把UTF-8编码改成UTF-8-sigwith open(file_path, mode='r', encoding='UTF-8 ...
- php读取文件时多了个%uFEFF[bom字符],怎样去掉?
今天从记事本文件中读取静态生成记录时,发现读出来的第一个链接打开的时候总是提示非法操作,把鼠标放到链接上发现链接的前面多了个%uFEFF, 百度一查,原来这是好多人都有遇到过的bom头问题,特地记录下 ...
- PHP中出现BOM字符\ufeff,PHP去掉诡异的BOM \ufeff
研究一个PHP项目的时候,今天项目突然打不开了. 前几天还好好的,用Chrome看了下Response的内容,AJAX页面和普通HTML页面内容前面有一个红色的点. 鼠标移上去,提示"\uf ...
- JSON字符串带BOM头"ufeff"
调用三方接口返回值JSON字符串带BOM头"\ufeff",JSON解析死活报错. 我是用SpringBoot的RestTemplate调用三方接口的,一开始返回值我是用对象接收返 ...
- JS去除字符串内的空白字符方法
有时我们需要对用户的输入进行一些处理,比如用户输入的密码或者用户名我们就需要去除前后空格,下面写一个去除空白字符的方法 function trim(string = '') { return stri ...
- sqlServer去除字符串空格
说起去除字符串首尾空格大家肯定第一个想到trim()函数,不过在sqlserver中是没有这个函数的,却而代之的是ltrim()和rtrim()两个函数.看到名字所有人都 知道做什么用的了,ltrim ...
- .Net 序列化(去除默认命名空间,添加编码)
1.序列化注意事项 (1).Net 序列化是基于对象的.所以只有实例字段呗序列化.静态字段不在序列化之中. (2)枚举永远是可序列化的. 2.XML序列化时去除默认命名空间xmlns:xsd和xmln ...
随机推荐
- 通过LDAP验证Active Directory服务
原文地址:http://www.byywee.com/page/M0/S215/215725.html C#: using System; using System.Collections.Gener ...
- Python爬虫实战案例:爬取爱奇艺VIP视频
一.实战背景 爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟.比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1 ...
- Linux命令-目录处理命令:ls
ls 查看当前目文件 ls -a 查看当前目录的所有文件(--all所有文件) 以"."开头的文件是隐藏文件. ls / 查看根目录的文件 ls -l 查看当前目录文件(--lo ...
- 使用vs调试.net源代码
使用.NET Framework库参考源进行调试 您可能会想知道使用.NET Framework参考源的调试方式.在下面的示例中,您将看到一个我调用公用Console.WriteLine方法的工具.从 ...
- Atitit.软件仪表盘(0)--软件的子系统体系说明
Atitit.软件仪表盘(0)--软件的子系统体系说明 1. 温度检测报警子系统 2. Os子系统 3. Vm子系统 4. Platform,业务系统子系统 5. Db数据库子系统 6. 通讯子系统 ...
- 常用Linux shell命令汇总
1.检查远程端口是否对bash开放:echo >/dev/tcp/8.8.8.8/53 && echo "open" 2.让进程转入后台:Ctrl + z 3 ...
- Hystrix使用Commond的三种方式
目录(?)[-] 1 依赖引入 2 使用 21 Hystrix command 211 同步执行 212 异步执行 213 反应执行 214 三种模式使用区别 22 Fallback 23 Error ...
- IIS添加域名
前提:域名可用 1.打开网站,点击右侧 绑定 2.添加域名 点击确定 3.结果: ok 配置完成.
- linux查看匹配内容的前后几行(转)
linux系统中,利用grep打印匹配的上下几行 如果在只是想匹配模式的上下几行,grep可以实现. $grep -5 'parttern' inputfile //打印匹配行的前后5行 ...
- TIM—高级定时器
本章参考资料:< STM32F4xx 参考手册>.< STM32F4xx 规格书>.库帮助文档< stm32f4xx_dsp_stdperiph_lib_um.chm&g ...