022:SQL优化--JOIN算法
一. SQL优化--JOIN算法
1.1. JOIN 写法对比

(root@localhost) 17:51:15 [mytest]> select * from a;
+------+------+
| id | num |
+------+------+
| a | 5 |
| b | 10 |
| c | 15 |
| d | 10 |
| e | 99 |
+------+------+
5 rows in set (0.00 sec)
(root@localhost) 17:51:20 [mytest]> select * from b;
+------+------+
| id | num |
+------+------+
| b | 5 |
| c | 15 |
| d | 20 |
| e | 99 |
+------+------+
4 rows in set (0.00 sec)
--
-- 语法一
--
(root@localhost) 17:51:23 [mytest]> select * from a,b where a.id=b.id;
+------+------+------+------+
| id | num | id | num |
+------+------+------+------+
| b | 10 | b | 5 |
| c | 15 | c | 15 |
| d | 10 | d | 20 |
| e | 99 | e | 99 |
+------+------+------+------+
4 rows in set (0.00 sec)
--
-- 语法二
--
(root@localhost) 17:51:42 [mytest]> select * from a inner join b where a.id=b.id;
+------+------+------+------+
| id | num | id | num |
+------+------+------+------+
| b | 10 | b | 5 |
| c | 15 | c | 15 |
| d | 10 | d | 20 |
| e | 99 | e | 99 |
+------+------+------+------+
4 rows in set (0.00 sec)
--
-- 语法三
--
(root@localhost) 17:52:42 [mytest]> select * from a join b where a.id=b.id;
+------+------+------+------+
| id | num | id | num |
+------+------+------+------+
| b | 10 | b | 5 |
| c | 15 | c | 15 |
| d | 10 | d | 20 |
| e | 99 | e | 99 |
+------+------+------+------+
4 rows in set (0.00 sec)
(root@localhost) 17:55:31 [mytest]> explain select * from a,b where a.id=b.id;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | a | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 20.00 | Using where; Using Join Buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
(root@localhost) 17:55:48 [mytest]> explain select * from a inner join b where a.id=b.id;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | a | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 20.00 | Using where; Using Join Buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
(root@localhost) 17:56:06 [mytest]> explain select * from a join b where a.id=b.id;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | b | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL |
| 1 | SIMPLE | a | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 20.00 | Using where; Using Join Buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
通过上述的
EXPLAIN可以得知,三种JOIN 语法在执行性能和效果上都是一样的。
2. JOIN的成本
- 两张表的JOIN的过程:

上图的Fetch阶段是指当内表关联的列是辅助索引时,但是需要访问表中的数据,那么这时就需要再访问主键索引才能得到数据的过程,不论表的存储引擎是InnoDB还是MyISAM,这都是无法避免的,只是MyISAM的回表速度要快点,因为其辅助索引存放的就是指向记录的指针,而InnoDB是索引组织表,需要再次通过索引查找才能定位数据。
Fetch阶段也不是必须存在的,如果是聚集索引链接,那么直接就能得到数据,无需回表,也就没有Fetch这个阶段。另外,上述给出了两张表之间的Join过程,多张表的Join就是继续上述这个过程。
回表:在找到二级索引后,得到对应的主键,再回到聚集索引中找主键对应的记录
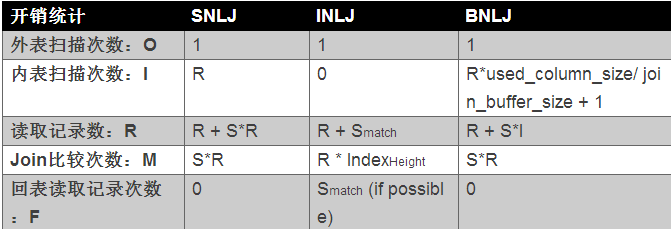
接着计算两张表Join的成本,这里有下列几种概念:
外表的扫描次数,记为O。通常外表的扫描次数都是1,即Join时扫描一次驱动表的数据即可Join
内表的扫描次数,记为I。根据不同Join算法,内表的扫描次数不同
读取表的记录数,记为R。根据不同Join算法,读取记录的数量可能不同
Join的比较次数,记为M。根据不同Join算法,比较次数不同
回表的读取记录的数,记为F。若Join的是辅助索引,可能需要回表取得最终的数据
评判Join算法是否优劣,就是查看上述这些操作的开销是否比较小。当然还要考虑I/O的访问方式,顺序还是随机,总之Join的调优也是门艺术,并非想象的那么简单。
3. JOIN算法
- nsted_loop join
- simple nested-loop join
- index nested-loop join
- block nested-loop join
- classic Hash Join
- Only support in MariaDB
- bached key access join
- from MySQL 5.6
- from MariaDB 5.5
3.1. simple nested loop join
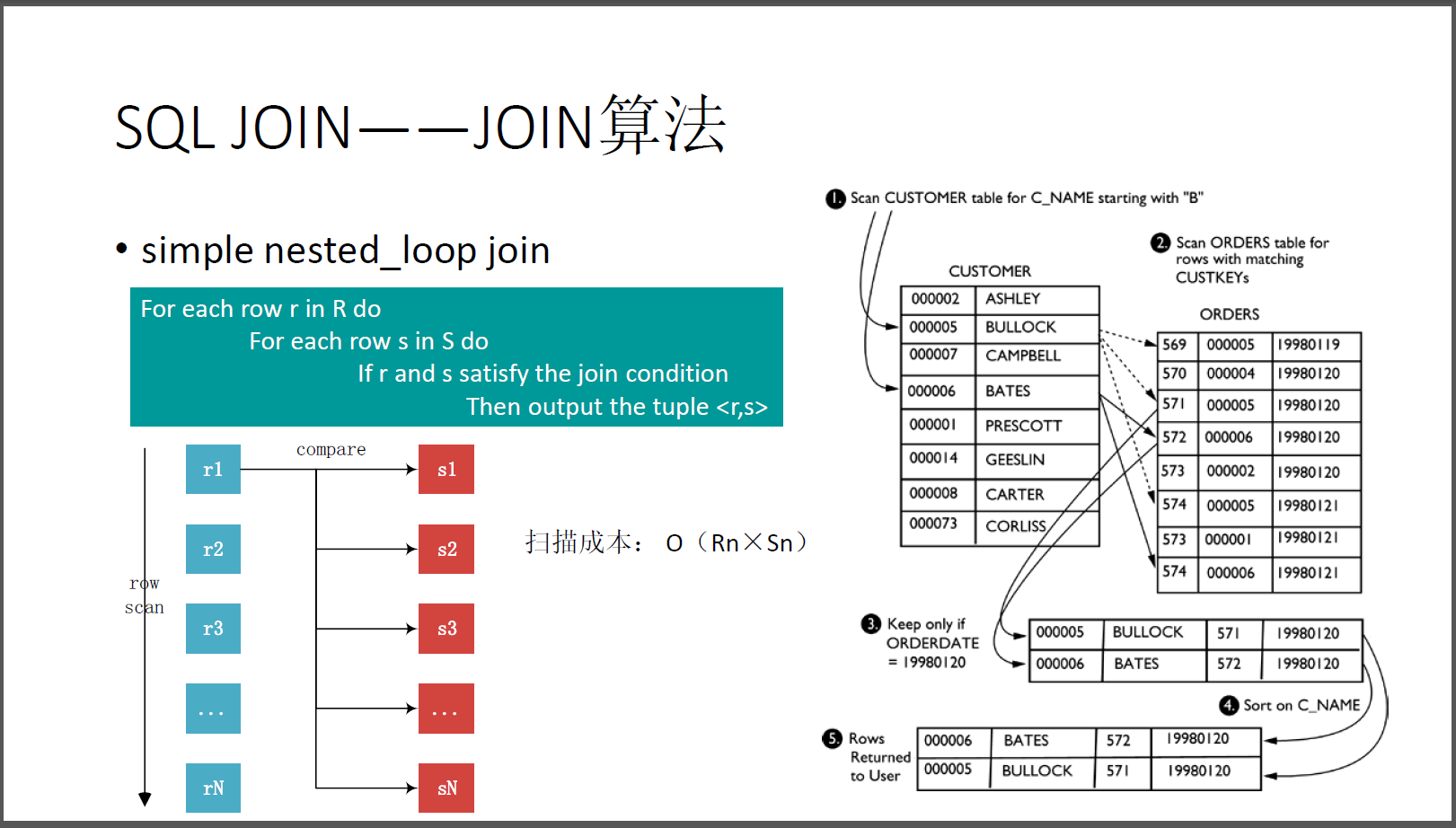
simple nested_loog join即外表(驱动表)中的每一条记录与内表中的记录进行判断其算法解析如下:
For each row r in R do -- 扫描R表
Foreach row s in S do -- 扫描S表
If r and s satisfy the join condition -- 如果r和s满足join条件
Then output the tuple -- 那就输出结果集
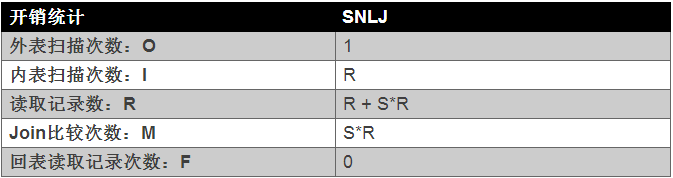
- 假设外表的记录数为R,内表的记录数位S
R表,该表只扫描了一次;S表,该表扫面了count(R)次;- 该方法相当于是一个
笛卡尔积,实际上数据库不会使用该算法; - 根据上面对于JOIN算法的评判标准来看,SNLJ的开销如下表所示:
3.2. index nested loop join

index nested_loop join由于内表上有索引,将外表扫描一次,内表是通过查找内表相应的索引的方式,和外表的记录进行匹配。
For each row r in R do -- 扫描R表
lookup s in S index -- 查询S表的索引(固定3~4次IO,B+树高度)
if found s == r -- 如果 r匹配了索引s
Then output the tuple -- 输出结果集
- S 表上有索引
- 扫描R表,将R表的记录和S表中的索引进行匹配
- R表上可以没有索引
- 优化器倾向使用记录数少的表作为外表(又称驱动表)
- 如果数据量大,
index nested loop join的成本也是高的,尤其是在二级索引的情况下,需要大量的回表操作 - 因为索引查询的成本是比较固定的,故优化器都倾向于使用记录数少的表作为外表。故
index nested_loop join的算法成本如下表所示:
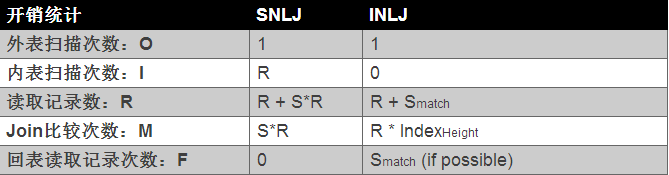
上表Smatch表示通过索引找到匹配的记录数量。通过索引可以大幅降低内表的Join的比较次数,每次比较1条外表的记录,其实就是一次indexlookup(索引查找),而每次index lookup的成本就是树的高度,即IndexHeight。
index nested_loop join的算法的效率能否达到用户的预期呢?
其实如果是通过表的
主键索引进行Join,即使是大数据量的情况下,index nested_loop join的效率亦是相当不错的。因为索引查找的开销非常小,并且访问模式也是顺序的(假设大多数聚集索引的访问都是比较顺序的)。
大部分人诟病MySQL的
index nested_loop join慢,主要是因为在进行Join的时候可能用到的索引并不是主键的聚集索引,而是辅助索引,这时index nested_loop join的过程又需要多一步Fetch的过程,而且这个过程开销会相当的大:
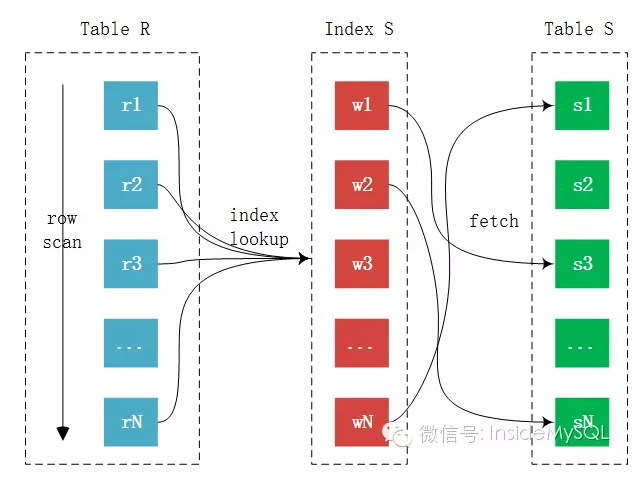
由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是index nested_loop join算法最大的弊端。
- 首先,辅助索引的index lookup是比较
随机I/O访问操作。 - 其次,根据index lookup再进行回表
又是一个随机的I/O操作。所以说,index nested_loop join最大的弊端是其可能需要大量的离散操作,这在SSD出现之前是最大的瓶颈。而即使SSD的出现大幅提升了随机的访问性能,但是对比顺序I/O,其还是慢了很多,依然不在一个数量级上。
3.3. block nested loop join
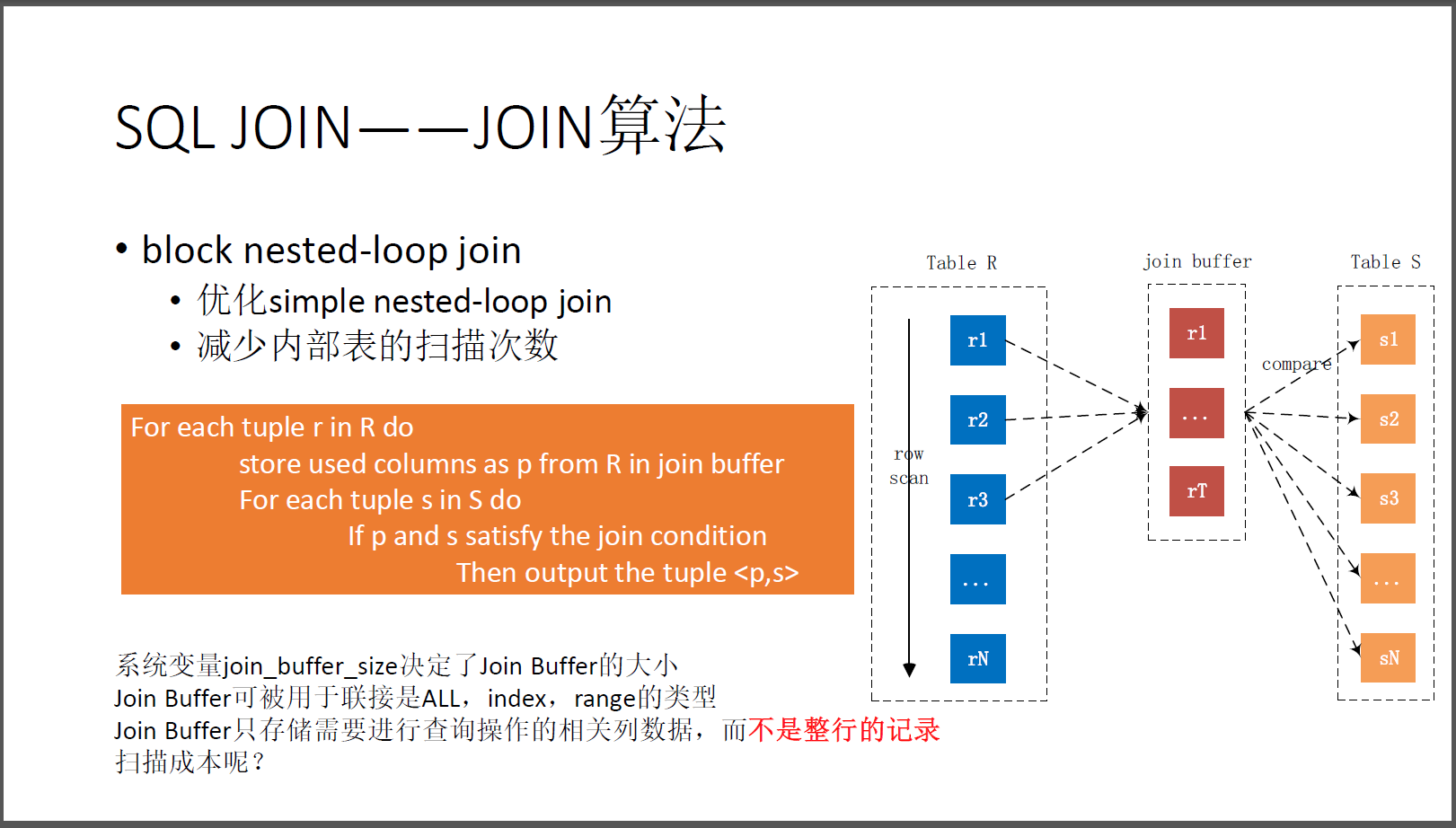
block nested loop join将外表中的需要join匹配的列(不是完整的记录)暂时保存在一块内存( Join Buffer )中,让后将这块内存中的数据和内表进行匹配(内表只扫描一次)
- block nested loop join 可被用于联接的是ALL,index,range的类型
For each tuple r in R do
store used columns as p from R in Join Buffer # 将部分或者全部R的记录保存到 Join Buffer中,记为p
For each tuple s in S do
If p and s satisfy the join condition # p 与 s满足join条件
Then output the tuple # 输出为结果集
block nested loop join 与simple nested loop join 相比,多了一个Join Buffer
mysql> show variables like "%join%buffer%";
+------------------+-----------+
| Variable_name | Value |
+------------------+-----------+
| join_buffer_size | 134217728 | -- 128M,默认是256K
+------------------+-----------+
1 row in set (0.00 sec)
Join Buffer 用的不是Buffer Pool中的内存,而是线程级别的内存。
可以通过explain查看执行计划,并通过join条件字段的大小,来预估 join_buffer_size 的大小。
注意:
增大join_buffer_size 进行优化的前提是没有使用index ,如果使用了index,根本不会使用block nested join算法
3.3.1 Join Buffer缓存的对象
Join Buffer缓存的对象是所有参与查询的列都会保存到Join Buffer,而不是只有Join的列.
比如下面的SQL语句,假设没有索引,需要使用到Join Buffer进行链接:
SELECT a.col3 FROM a,b
WHERE a.col1 = b.col2
AND a.col2 > … AND b.col2 = …
假设上述SQL语句的外表是a,内表是b,那么存放在Join Buffer中的列是所有参与查询的列,在这里就是(a.col1,a.col2,a.col3)。
通过上面的介绍,我们现在可以得到内表的扫描次数为:
Scaninner_table = (Rn * used_column_size) / join_buffer_size + 1可以预估需要分配的Join Buffer大小,然后尽量使得内表的扫描次数尽可能的少,最优的情况是只扫描内表一次。
3.3.2 Join Buffer的分配
需要牢记的是,Join Buffer是在Join之前就进行分配,并且每次Join就需要分配一次Join Buffer,所以假设有N张表参与Join,每张表之间通过Block Nested-Loop Join,那么总共需要分配N-1个Join Buffer,这个内存容量是需要DBA进行考量的。
- Join Buffer可分为以下两类:
- regular Join Buffer
- incremental Join Buffer
regular Join Buffer是指Join Buffer缓存的是所有参与查询的列, 如果第一次使用Join Buffer,必然使用的是regular Join Buffer。
incremental Join Buffer中的Join Buffer缓存的是当前使用的列,以及之前使用Join Buffer的指针。在多次进行Join的操作时,这样可以极大减少Join Buffer对于内存开销的需求。
此外,对于
NULL类型的列,其实不需要存放在Join Buffer中,而对于VARCHAR类型的列,也是仅需最小的内存即可,而不是以CHAR类型在Join Buffer中保存。最后,从MySQL 5.6版本开始,对于Outer Join也可以使用Join Buffer。
3.3.3 Block Nested-Loop Join总结
Block Nested-Loop Join极大的避免了内表的扫描次数,如果Join Buffer可以缓存外表的数据,那么内表的扫描仅需一次,这和Hash Join非常类似。但是Block Nested-Loop Join依然没有解决的是Join比较的次数,其仍然通过Join判断式进行比较。综上所述,到目前为止各Join算法的成本比较如下所示:
3.4. MariaDB中的Hash Join算法
MySQL 目前不支持Hash Join


由上图可知, MariaDB 中的
Hash Join算法是在Block Join基础之上,根据Join Buffer中的对象创建哈希表,内表通过哈希算法进行查找,减少内外表扫描的次数,提升Join的性能
MariaDB中的
Hash Join问题是,优化器默认不会去选择Hash Join算法- set join_cache_level = 4;
- set optimizer_switch='join_cache_hashed=on';
设置两个变量后,MariaDB将强制使用hash算法,无法智能判断
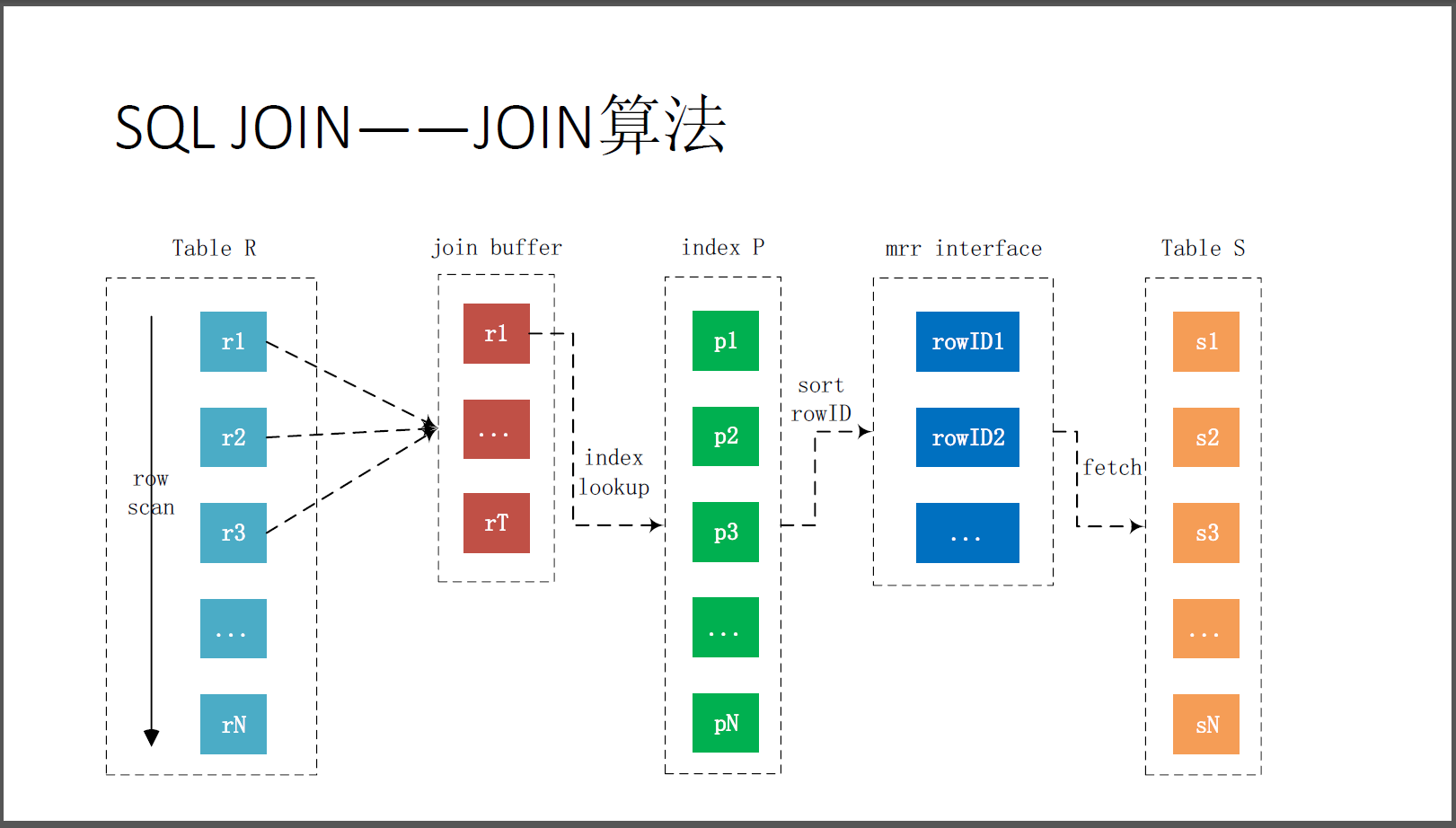
3.5. batched key access join

通过上图可以知道,在index join的基础上,增加MRR的功能,先对索引进行排序,然后批量获取聚集索引中的记录,由于使用了MRR的功能,所以默认该join算法也是不会被使用到的
- set optimizer_switch='mrr_cost_based=off';
-- 方法一
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on'; -- 在session中打开BKA特性
mysql> explain SELECT * FROM part, lineitem WHERE l_partkey=p_partkey AND p_retailprice>3000\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: part
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 195802
filtered: 33.33
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: ref
possible_keys: i_l_suppkey_partkey,i_l_partkey
key: i_l_partkey
key_len: 5
ref: dbt3.part.p_partkey
rows: 27
filtered: 100.00
Extra: Using Join Buffer (Batched Key Access) -- 使用了BKA
2 rows in set, 1 warning (0.00 sec)
-- 方法二
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=on,batched_key_access=off'; -- 在session中关闭BKA特性
mysql> explain SELECT /*+ BKA(lineitem)*/ * FROM part, lineitem WHERE l_partkey=p_partkey AND p_retailprice>2050\G -- 使用/*+ BKA(tablename)*/ 的语法,强制使用BKA特性
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: part
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 195802
filtered: 33.33
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: ref
possible_keys: i_l_suppkey_partkey,i_l_partkey
key: i_l_partkey
key_len: 5
ref: dbt3.part.p_partkey
rows: 27
filtered: 100.00
Extra: Using Join Buffer (Batched Key Access) -- 使用了BKA
2 rows in set, 1 warning (0.00 sec)
二. MRR补充
(root@localhost) 10:35:54 [employees]> show variables like "%optimizer_switch%"\G;
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on
1 row in set (0.01 sec)
ERROR:
No query specified
(root@localhost) 10:36:05 [employees]> explain select * from employees where hire_date >= '1996-01-01'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: employees
partitions: NULL
type: range
possible_keys: idx_date
key: idx_date
key_len: 3
ref: NULL
rows: 41036
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
(root@localhost) 10:36:06 [employees]> explain select /*+ MRR(employees)*/ * from employees where hire_date >= '1996-01-01'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: employees
partitions: NULL
type: range
possible_keys: idx_date
key: idx_date
key_len: 3
ref: NULL
rows: 41036
filtered: 100.00
Extra: Using index condition; Using MRR --使用MRR
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specified
(root@localhost) 10:36:46 [employees]>
如果
强制开启MRR,那在某些SQL语句下,性能可能会变差;因为MRR需要排序,假如排序的时间超过直接执行的时间,那性能就会降低。
optimizer_switch可以是全局的,也可以是会话级的。
[参考MySQL Join算法与调优白皮书]
022:SQL优化--JOIN算法的更多相关文章
- sql优化 表连接join方式
sql优化核心 是数据库中 解析器+优化器的工作,我觉得主要有以下几个大方面:1>扫表的方法(索引非索引.主键非主键.书签查.索引下推)2>关联表的方法(三种),关键是内存如何利用 ...
- paip.sql索引优化----join 代替子查询法
paip.sql索引优化----join 代替子查询法 作者Attilax , EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog.csdn.n ...
- MySQL Nested-Loop Join算法学习
不知不觉的玩了两年多的MySQL,发现很多人都说MySQL对比Oracle来说,优化器做的比较差,其实某种程度上来说确实是这样,但是毕竟MySQL才到5.7版本,Oracle都已经发展到12c了,今天 ...
- 关于join算法的四篇文章
MySQL Join算法与调优白皮书(一) MySQL Join算法与调优白皮书(二) MySQL Join算法与调优白皮书(三) MySQL Join算法与调优白皮书(四) MariaDB Join ...
- Spark SQL概念学习系列之Spark SQL 优化策略(五)
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟.除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略. (1)内存列式存 ...
- SQL优化的四个方面,缓存,表结构,索引,SQL语句
一,缓存 数据库属于 IO 密集型的应用程序,其主要职责就是数据的管理及存储工作.而我们知道,从内存中读取一个数据库的时间是微秒级别,而从一块普通硬盘上读取一个IO是在毫秒级别,二者相差3个数量级.所 ...
- 大型系统开发sql优化总结(转)
Problem Description: 1.每个表的结构及主键索引情况 2.每个表的count(*)记录是多少 3.对于创建索引的列,索引的类型是什么?count(distinct indexcol ...
- 智能SQL优化工具--SQL Optimizer for SQL Server(帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 )
SQL Optimizer for SQL Server 帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 SQL Optimizer for SQL Server 让 SQL Serve ...
- HASH JOIN算法
哈希连接(HASH JOIN) 前文提到,嵌套循环只适合输出少量结果集.如果要返回大量结果集(比如返回100W数据),根据嵌套循环算法,被驱动表会扫描100W次,显然这是不对的.看到这里你应该明白为 ...
随机推荐
- APUE学习笔记——10.9 信号发送函数kill、 raise、alarm、pause
转载注明出处:Windeal学习笔记 kil和raise kill()用来向进程或进程组发送信号 raise()用来向自身进程发送信号. #include <signal.h> int k ...
- dilworth定理+属性排序(木棍加工)
P1233 木棍加工 题目描述 一堆木头棍子共有n根,每根棍子的长度和宽度都是已知的.棍子可以被一台机器一个接一个地加工.机器处理一根棍子之前需要准备时间.准备时间是这样定义的: 第一根棍子的准备时间 ...
- L147 Low Cost Study Has High Impact Results For Premature Babies
No one knows exactly why some babies are born prematurely(早产), but some of the smallest premature ba ...
- html dom SetInterVal()
HTML DOM setInterval() 方法 HTML DOM Window 对象 定义和用法 setInterval() 方法可按照指定的周期(以毫秒计)来调用函数或计算表达式. setInt ...
- Linux内核源代码目录结构详解
http://blog.csdn.net/u013014440/article/details/44024207
- Unity内存优化技术测试案例
笔者介绍:姜雪伟,IT公司技术合伙人,IT高级讲师,CSDN社区专家,特邀编辑,畅销书作者,已出版书籍:<手把手教你架构3D游戏引擎>电子工业出版社和<Unity3D实战核心技术详解 ...
- UISegmentedControl字体大小,颜色,选中颜色,左边椭圆,右边直线的Button 解决之iOS开发之分段控制器UISegmentedControl
NSArray *segmentedArray = [NSArrayarrayWithObjects:STR(@"Mynews"),STR(@"Systemmes ...
- android Camera模块分析
Android Camera Module Architecture and Bottom layer communication mechanism ----------- ...
- 读文件名,shell
参考文献:(忘了哪个笔记了)http://www.docin.com/p-871820919.html
- Struts标签库详解,非常好的Struts标签详解
Struts提供了五个标签库,即:HTML.Bean.Logic.Template和Nested. HTML 标签: 用来创建能够和Struts 框架和其他相应的HTML 标签交互的H ...