Python抓取微博评论
本人是张杰的小迷妹,所以用杰哥的微博为例,之前一直看的是网页版,然后在知乎上看了一个抓取沈梦辰的微博评论的帖子,然后得到了这样的网址
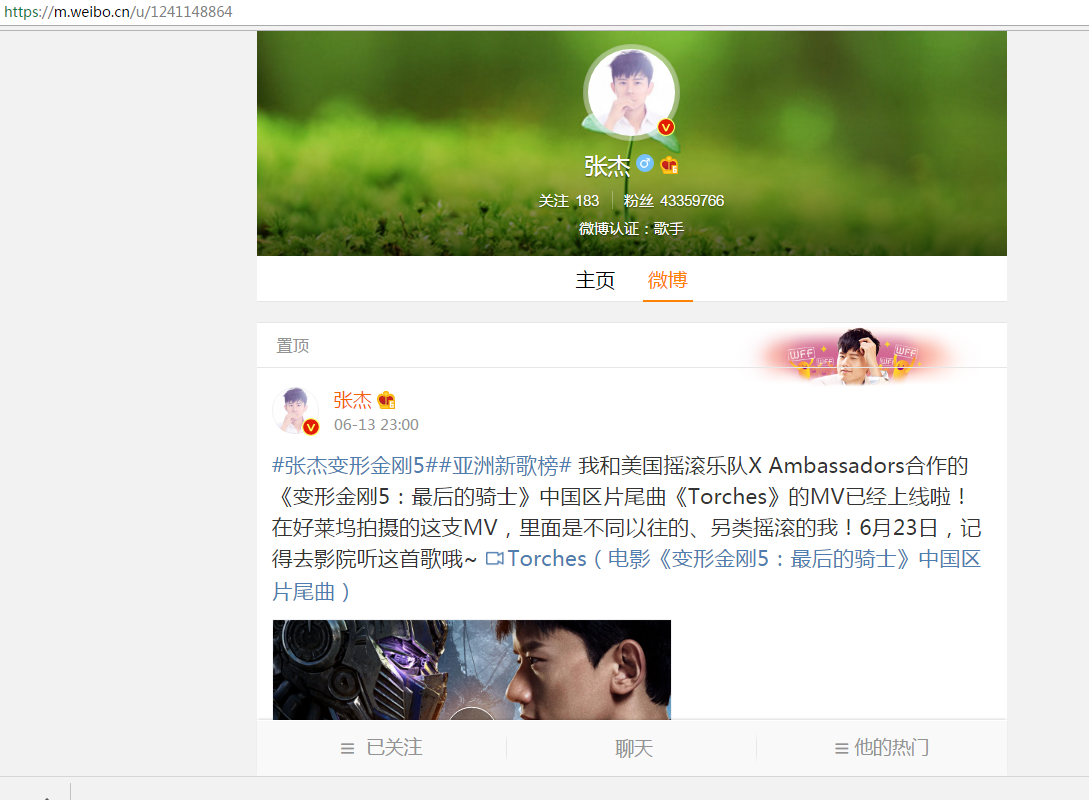
然后就用m.weibo.cn进行网站的爬取,里面的微博和每一条微博里面的评论都是ajax加载的,通过分析加载的数据分析可以得到,每次动态加载都是通过一个xhr进行加载的

表单提交的数据除了这是第页加载的微博之外,其他都是一样的。并且response信息里面有本条xhr信息返回当前xhr包括的所有信息的标识,一个xhr包含9条微博,然后会返回这9条微博的标识,标识是蓝框中的,

然后每条微博的就是https://m.weibo.cn/status/ + 标识
对于每条微博的标识,还没有弄明白...各位大佬知道了告诉我下.谢了
例如:
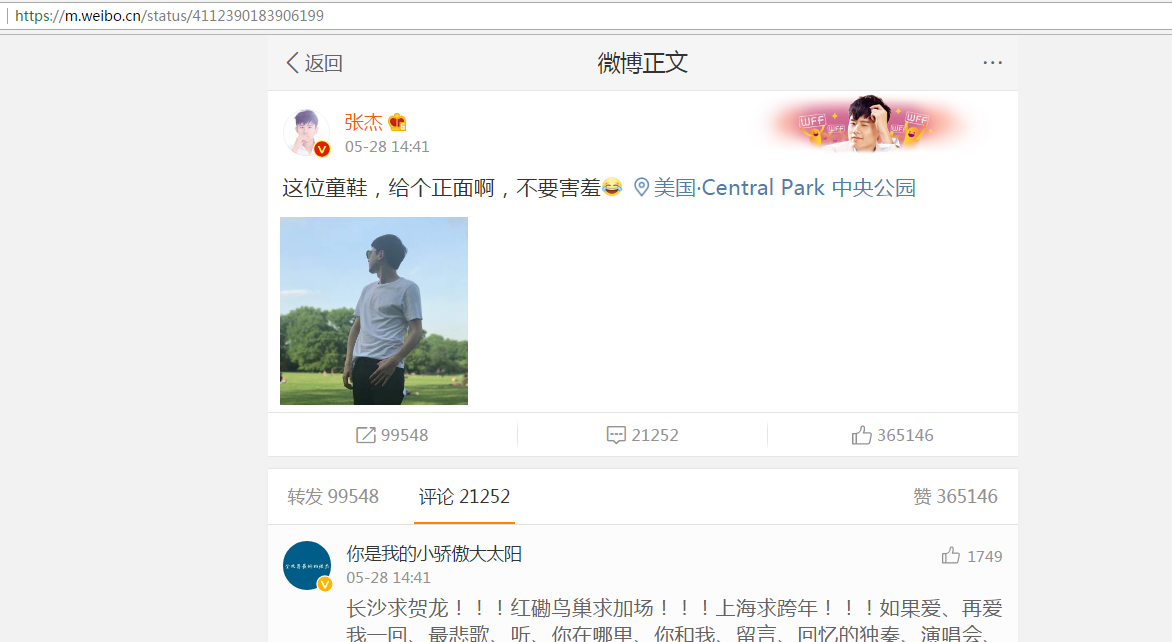
然后ajax加载评论,通过分析加载评论的url只是在后面的page值发生改变,如图:

并且里面的请求头之类的都很容易构造,不同处是当前的page页和当前微博的标识。
有些偷懒没有把每条微博的评论数抓出来,直接是固定多少的评论。
代码如下,不足请指出:
# -*- coding: utf-8 -*-
import re
import urllib
import urllib2
import os
import stat
import itertools
import re
import sys
import requests
import json
import time
import socket
import urlparse
import csv
import random
from datetime import datetime, timedelta
import lxml.html
from wordcloud import WordCloud
import jieba
import PIL
import matplotlib.pyplot as plt
import numpy as np from zipfile import ZipFile
from StringIO import StringIO
from downloader import Downloader
from bs4 import BeautifulSoup
from HTMLParser import HTMLParser
from itertools import product
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import json,urllib2
textmod={"uid":".....",
"luicode":"",
"lfid":"100103type=3&q=张杰",
"featurecode":"",
"type":"uid",
"value":"....",
"containerid":"....."
}
textmod = json.dumps(textmod)
header_dict = {'Connection':'keep-alive',
'Cookie':'',
'Accept-Language':'zh-CN,zh;q=0.8',
'Host':'m.weibo.cn',
'Referer':'............',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
} def wordcloudplot(txt):
path = 'C:\Users\Administrator\Downloads\msyh.ttf'
path = unicode(path, 'utf8').encode('gb18030')
alice_mask = np.array(PIL.Image.open('E:\\aa.jpg'))
wordcloud = WordCloud(font_path=path,
background_color="white",
margin=5, width=1800, height=800, mask=alice_mask, max_words=2000, max_font_size=60,
random_state=42)
wordcloud = wordcloud.generate(txt)
wordcloud.to_file('E:\\aa1.jpg')
plt.imshow(wordcloud)
plt.axis("off")
plt.show() def main():
a = []
f = open(r'E:\commentqq.txt', 'r').read()
words = list(jieba.cut(f))
for word in words:
if len(word) > 1:
a.append(word)
txt = r' '.join(a)
wordcloudplot(txt) def get_comment(que):
f = open('E:\commentqq.txt', 'w')
for each in que:
for i in range(1,1000):
textmood = {"id": each,
"page": i}
textmood = json.dumps(textmood)
uu = 'https://m.weibo.cn/status/' + str(each)
header = {'Connection': 'keep-alive',
'Cookie': '.....',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Host': 'm.weibo.cn',
'Referer':uu,
'User-Agent': '......',
'X-Requested-With': 'XMLHttpRequest'
}
url = 'https://m.weibo.cn/api/comments/show?id=%s&page=%s'%(str(each),str(i))
print url
#f.write(url) req = urllib2.Request(url=url, data=textmood, headers=header)
res = urllib2.urlopen(req)
res = res.read()
contents = res
d = json.loads(contents, encoding="utf-8")
if 'data' in d:
data = d['data']
if data != "":
for each_one in data:
if each_one != "":
if each_one['text'] != "":
mm = each_one['text'].split('<')
if r'回复' not in mm[0]:
index = mm[0]#filter(lambda x: x not in '0123456789', mm[0])
print index
#index = index.decode("gbk")
f.write(index.encode("u8")) def get_identified():
que = []
url = 'https://m.weibo.cn/api/container/getIndex?uid=1241148864&luicode=10000011&lfid=100103type%3D3%26q%3D%E5%BC%A0%E6%9D%B0&featurecode=20000180&type=uid&value=1241148864&containerid=1076031241148864'
for i in range(1,10):
if i > 1:
url = 'https://m.weibo.cn/api/container/getIndex?uid=1241148864&luicode=10000011&lfid=100103type%3D3%26q%3D%E5%BC%A0%E6%9D%B0&featurecode=20000180&type=uid&value=1241148864&containerid=1076031241148864&page='+str(i)
print url req = urllib2.Request(url=url, data=textmod, headers=header_dict)
res = urllib2.urlopen(req)
res = res.read()
content = res d = json.loads(content, encoding="utf-8")
data = d['cards']
if data != "":
for each in data:
print each['itemid']
mm = each['itemid']
if mm != "":
identity = mm.split('-')
num = identity[1][1:]
que.append(num)
#fd.write(num)
#fd.write('\n\n')
print num get_comment(que) if __name__ == '__main__':
get_identified()
main()
成效:


Python抓取微博评论的更多相关文章
- Python抓取微博评论(二)
对于新浪微博评论的抓取,首篇做的时候有些考虑不周,然后现在改正了一些地方,因为有人问,抓取评论的时候“爬前50页的热评,或者最新评论里的前100页“,这样的数据看了看,好像每条微博的评论都只能抓取到前 ...
- 一篇文章教会你使用Python定时抓取微博评论
[Part1--理论篇] 试想一个问题,如果我们要抓取某个微博大V微博的评论数据,应该怎么实现呢?最简单的做法就是找到微博评论数据接口,然后通过改变参数来获取最新数据并保存.首先从微博api寻找抓取评 ...
- Python爬虫抓取微博评论
第一步:引入库 import time import base64 import rsa import binascii import requests import re from PIL impo ...
- python抓取新浪微博评论并分析
1,实现效果 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQveGlhb2xhbnphbw==/font/5a6L5L2T/fontsize/400/fill ...
- 测试开发Python培训:抓取新浪微博评论提取目标数据-技术篇
测试开发Python培训:抓取新浪微博评论提取目标数据-技术篇 在前面我分享了几个新浪微博的自动化脚本的实现,下面我们继续实现新的需求,功能需求如下: 1,登陆微博 2,抓取评论页内容3,用正则表 ...
- 使用Python抓取猫眼近10万条评论并分析
<一出好戏>讲述人性,使用Python抓取猫眼近10万条评论并分析,一起揭秘“这出好戏”到底如何? 黄渤首次导演的电影<一出好戏>自8月10日在全国上映,至今已有10天,其主演 ...
- [Python爬虫] 之四:Selenium 抓取微博数据
抓取代码: # coding=utf-8import osimport refrom selenium import webdriverimport selenium.webdriver.suppor ...
- Python抓取豆瓣《白夜追凶》的评论并且分词
最近网剧<白夜追凶>在很多朋友的推荐下,开启了追剧模式,自从琅琊榜过后没有看过国产剧了,此剧确实是良心剧呀!一直追下去,十一最后两天闲来无事就抓取豆瓣的评论看一下 相关代码提交到githu ...
- Python 3.6 抓取微博m站数据
Python 3.6 抓取微博m站数据 2019.05.01 更新内容 containerid 可以通过 "107603" + user_id 组装得到,无需请求个人信息获取: 优 ...
随机推荐
- spark(一)
一.spark 学习 1. spark学习的三种地方: (1)Spark.apache.org 官方文档 (2)spark的源代码的官方网站 https://github.com/apache/ ...
- [Wf2011]Chips Challenge
两个条件都不太好处理 每行放置的个数实际很小,枚举最多放x 但还是不好放 考虑所有位置先都放上,然后删除最少使得合法 为了凑所有的位置都考虑到,把它当最大流 但是删除最少,所以最小费用 行列相关,左行 ...
- ContestHunter#24-C 逃不掉的路
Description: 求无向图的必经边 思路:一眼题 将无向图缩成树,然后求两点树上距离 #include<iostream> #include<vector> #incl ...
- 【loj6179】Pyh的求和
Portal -->loj6179 Solution 这题其实有一个式子一喵一样的版本在bzoj,但是那题是\(m\)特别大然后只有一组数据 这题多组数据== 首先根据\(\v ...
- python的复制,深拷贝和浅拷贝的区别(转)
在python中,对象赋值实际上是对象的引用.当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用 一般有三种方法, alist=[1,2,3,[& ...
- Codeforces Round #416 (Div. 2)A B C 水 暴力 dp
A. Vladik and Courtesy time limit per test 2 seconds memory limit per test 256 megabytes input stand ...
- [python]乱码:python抓取脚本
参考: http://www.zhxl.me/1409.html 使用 python urllib2 抓取网页时出现乱码的解决方案 发表回复 这里记录的是一个门外汉解决使用 urllib2 抓取网页时 ...
- socket--粘包
参考博客:http://www.cnblogs.com/kex1n/p/6502002.html 一.粘包现象 在上一篇的socket传输大数据文章中,我们可以顺利的接发数据,似乎做的不错,可以接收了 ...
- 关于NUL
问题:正常的order by不起作用了,如下图 分析:使用notepad++打开,发现 NUL以字符'\0'作为字符串结束标志.'\0'是一个ASCII码为0的字符,从ASCII码表中可以看到ASCI ...
- 跟我一起写Makefile(七)
make 的运行—————— 一般来说,最简单的就是直接在命令行下输入make命令,make命令会找当前目录的makefile来执行,一切都是自动的.但也有时你也许只想让make重编译某些文件,而不是 ...