【数据挖掘基础算法】KNN最近邻分类算法
算法简介:
通过计算待预测样本和已知分类号的训练样本之间的距离来判断该样本属于某个已知分类号的概率。并选取概率最大的分类号来作为待预测样本的分类号
懒惰分类算法,其模型的建立直到待预测实例进行预测时才开始。
KNN算法的指导思想是“近朱者赤,近墨者黑”,由你的邻居来推断出你的类别。
本质上,KNN算法就是用距离来衡量样本之间的相似度
算法图示:
从训练集中找到和新数据最接近的k条记录,然后根据多数类来决定新数据类别。
算法涉及3个主要因素:
1) 训练数据集
2) 距离或相似度的计算衡量
3) k的大小
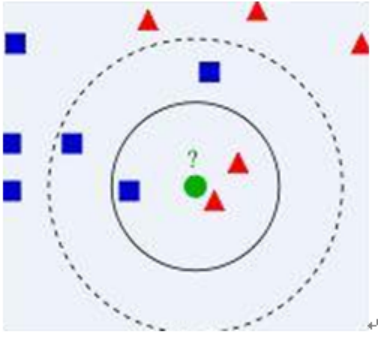
算法描述
1) 已知两类“先验”数据,分别是蓝方块和红三角,他们分布在一个二维空间中
2) 有一个未知类别的数据(绿点),需要判断它是属于“蓝方块”还是“红三角”类
3) 考察离绿点最近的3个(或k个)数据点的类别,占多数的类别即为绿点判定类别
算法要点
计算步骤
计算步骤如下:
1)算距离:给定测试对象,计算它与训练集中的每个对象的距离
2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类
相似度的衡量
距离越近应该意味着这两个点属于一个分类的可能性越大。但距离不能代表一切,有些数据的相似度衡量并不适合用距离
相似度衡量方法:空间上有欧氏距离,路径上有曼哈顿距离,国际象棋上的一致范数:切比雪夫距离等,还有夹角余弦等。
(简单应用中,一般使用欧氏距离,但对于文本分类来说,使用余弦(cosine)来计算相似度就比欧式(Euclidean)距离更合适)
类别的判定
简单投票法:少数服从多数,近邻中哪个类别的点最多就分为该类。
加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
K值的选取
选定训练集和对应的测试机,然后选取不同的k值,把其中错误率最低的k作为分类的k值,当有新的训练集更新时,我们再运行模型,不断迭代更新。一般来说k是不超过20的整数。k<sqrt(样本数)
一般使用交叉验证的方式
算法不足之处
样本不平衡容易导致结果错误
如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
改善方法:对此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
计算量较大
因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
改善方法:事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
该方法比较适用于样本容量比较大的类域的分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
性能改进:
kNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。
懒惰的后果:构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。
已经有一些方法提高计算的效率,例如压缩训练样本量等,方法有浓缩技术、编辑技术等
【数据挖掘基础算法】KNN最近邻分类算法的更多相关文章
- K-NN(最近邻分类算法 python
# algorithm:K-NN(最近邻分类算法)# author:Kermit.L# time: 2016-8-7 #======================================== ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
1. 基于实例的学习算法 0x1:数据挖掘的一些相关知识脉络 本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科. 其实人类的科学技术发展的历史,就一直伴随 ...
- 【原创】数据挖掘案例——ReliefF和K-means算法的医学应用
数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘 (DataMiriing),指的是从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的.事先未知 ...
- KNN近邻算法
K近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.kNN算法的核 ...
- 分类算法-----KNN
摘要: 所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用她最接近的k个邻居来代表.kNN算法的核心思想是如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于 ...
- 一步步教你轻松学KNN模型算法
一步步教你轻松学KNN模型算法( 白宁超 2018年7月24日08:52:16 ) 导读:机器学习算法中KNN属于比较简单的典型算法,既可以做聚类又可以做分类使用.本文通过一个模拟的实际案例进行讲解. ...
- 数据挖掘领域十大经典算法之—C4.5算法(超详细附代码)
https://blog.csdn.net/fuqiuai/article/details/79456971 相关文章: 数据挖掘领域十大经典算法之—K-Means算法(超详细附代码) ...
- 数据挖掘算法之k-means算法
系列文章:数据挖掘算法之决策树算法 k-means算法可以说是数据挖掘中十大经典算法之一了,属于无监督的学习.该算法由此衍生出了很多类k-means算法,比如k中心点等等,在数据挖掘领域, ...
随机推荐
- php-fpm: hundreds of seconds in the log
favoriteI have nginx+php-fpm web serverSo I've noticed in php5-fpm.log many strange lines:[03-Sep-20 ...
- C++——内存对象 禁止产生堆对象 禁止产生栈对象
用C或C++写程序,需要更多地关注内存,这不仅仅是因为内存的分配是否合理直接影响着程序的效率和性能,更为主要的是,当我们操作内存的时候一不小心就会出现问题,而且很多时候,这些问题都是不易发觉的,比如内 ...
- bzoj4165: 矩阵(堆+hash)
求第k大用堆维护最值并出堆的时候扩展的经典题... 因为只有正数,所以一个矩阵的权值肯定比它的任意子矩阵的权值大,那么一开始把所有满足条件的最小矩阵加进堆里,弹出的时候上下左右扩展一行加进堆,用has ...
- [CodeVs1050]棋盘染色2(状态压缩DP)
题目大意:有一个5*N(≤100)的棋盘,棋盘中的一些格子已经被染成了黑色,求最少对多少格子染色,所有的黑色能连成一块. 这题卡了我1h,写了2.6k的代码,清明作业一坨还没做啊...之前一直以为这题 ...
- Linux基础-配置网络、集群内主机名设定、ssh登入、bash命令、通配符(元字符)
作业一:临时配置网络(ip,网关,dns)+永久配置 设置临时网络配置: 配置IP ifcongfig ens33 192.168.16.177/24 (ifconfig 网卡 ip地址 /24 ...
- Codeforces Round #299 (Div. 2)A B C 水 dfs 二分
A. Tavas and Nafas time limit per test 1 second memory limit per test 256 megabytes input standard i ...
- 解决HTML5标签兼容的办法搜集
HTML5的语义化标签以及属性,可以让开发者非常方便地实现清晰的web页面布局,加上CSS3的效果渲染,快速建立丰富灵活的web页面显得非常简单. HTML5的新标签元素有: <header&g ...
- Spring整合JMS(一)——基于ActiveMQ实现 (转)
*注:别人那复制来的 1.1 JMS简介 JMS的全称是Java Message Service,即Java消 息服务.它主要用于在生产者和消费者之间进行消息传递,生产者负责产生消息,而消费者 ...
- 条件转化,2-sat BZOJ 1997
http://www.lydsy.com/JudgeOnline/problem.php?id=1997 1997: [Hnoi2010]Planar Time Limit: 10 Sec Memo ...
- Python学习笔记(四十七)SMTP发送邮件
摘抄自:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001432005226 ...