spark[源码]-sparkContext概述
SparkContext概述
sparkContext是所有的spark应用程序的发动机引擎,就是说你想要运行spark程序就必须创建一个,不然就没的玩了。sparkContext负责初始化很多东西,当其初始化完毕以后,才能像spark集群提交任务,这个地方还有另一个管理配置的类sparkConf,它主要负责配置,检查,修改等工作,这会在后期源码阅读的时候你会经常看到的一个参数conf,说的就是它。
1.代码小实例
object sparktest_hivesql {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("sparktest_sql"))
val hiveContext = new HiveContext(sc)
import hiveContext.implicits._
hiveContext.sql("use data_sence")
val testData = hiveContext.sql("select * from ods_position_day limit 10")
testData.collect().foreach(x=>println("****:"+x))
sc.stop()
}
}
功能很多简单,即使通过spark和hive 的配置连接,让spark可以读hive 库里面的数据,这个地方就读取一个表里面的数据,打印出来。主要是为了做一个sparkconf和sparkContext的引子。
2.sparkConf
1.参数配置处理
就是一些spark配置信息的处理,主要是一个:private val settings = new ConcurrentHashMap[String, String]()
sparkconf() 只接受一个boolean的参数:
当为true时,系统将加载外部设置。

当为false时,跳过加载外部设置,无论系统属性是什么,都要得到相同的配置.
对一些参数做出map处理,将用户自己添加和系统提供的进行整合,全是围绕这个方法进行处理的。

这个地方用到了一个scala的单例模式,返回的是this,这样你就用在生成sparkConf().setMaster().setAppName()的情况了。
2.对一些过时的参数进行验证。
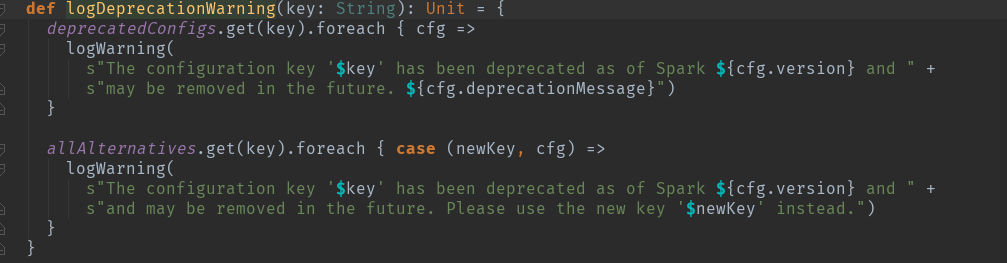
3.sparkContext描述
先来个简单的关系图了解一下基本关系:
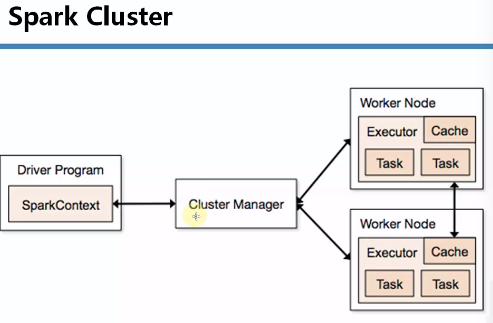
1.spark程序在运行的时候分为Driver(任务解析,分配)和Executor(job具体执行者)两部分。
2.spark编程是基于SparkContext的,具体说来包含两部分。
1.spark编程的核心基础RDD,是由SparkContext来创建的。
2.spark程序的调度优化也是基于SparkContext。
3.spark程序的注册是通过SparkContext实例化时候生产的对象来完成的。其实是通过SchedulerBankend来注册程序。
4.spark程序运行时通过Master获取具体的计算资源,计算资源获取也是通过SparkContext产生的对象来申请。实际是SchedulerBackend来获取计算资源的。
5.SparkContext结束的时候spark也结束了。
4.spark初始化步骤
SparkContext的主构造器参数为SparkConf:这个地方简单的说一下,一直强调sparkContext只能有一个,但是其实是可以多个的。

allowMultipleContexts :多个contexts的标签,当为true的时候 有多个sparkcontext的时候 会抛出异常。
SparkContext.markPartiallyConstructed(this, allowMultipleContexts) 为了多个sparkContexts。
SparkContext的初始化步骤如下:
1) 创建Spark执行环境SparkEnv;
2) 创建RDD清理器metadataCleaner;
3) 创建并初始化Spark UI;
4) Hadoop相关配置及Executor环境变量的设置;
5) 创建任务调度TaskScheduler;
6) 创建和启动DAGScheduler;
7) TaskScheduler的启动;
8) 初始化块管理器BlockManager;
9) 启动测量系统MetricsSystem;
10) 创建和启动Executor分配管理器ExecutorAllocationManager;
11) ContextCleaner的创建和启动;
12) Spark环境更新;
13) 创建DAGSchedulerSource和BlockManagerSource;
14) 将SparkContext标记为激活。
spark[源码]-sparkContext概述的更多相关文章
- spark[源码]-sparkContext详解[一]
spark简述 sparkContext在Spark应用程序的执行过程中起着主导作用,它负责与程序和spark集群进行交互,包括申请集群资源.创建RDD.accumulators及广播变量等.spar ...
- Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象.由于在local模式下Driver会创建Executor,local-cl ...
- Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI
3. 创建并初始化Spark UI 任何系统都需要提供监控功能,用浏览器能访问具有样式及布局并提供丰富监控数据的页面无疑是一种简单.高效的方式.SparkUI就是这样的服务. 在大型分布式系统中,采用 ...
- Spark源码分析 – SparkContext
Spark源码分析之-scheduler模块 这位写的非常好, 让我对Spark的源码分析, 变的轻松了许多 这里自己再梳理一遍 先看一个简单的spark操作, val sc = new SparkC ...
- spark源码阅读--SparkContext启动过程
##SparkContext启动过程 基于spark 2.1.0 scala 2.11.8 spark源码的体系结构实在是很庞大,从使用spark-submit脚本提交任务,到向yarn申请容器,启 ...
- Apache Spark源码剖析
Apache Spark源码剖析(全面系统介绍Spark源码,提供分析源码的实用技巧和合理的阅读顺序,充分了解Spark的设计思想和运行机理) 许鹏 著 ISBN 978-7-121-25420- ...
- emacs+ensime+sbt打造spark源码阅读环境
欢迎转载,转载请注明出处,徽沪一郎. 概述 Scala越来越流行, Spark也愈来愈红火, 对spark的代码进行走读也成了一个很普遍的行为.不巧的是,当前java社区中很流行的ide如eclips ...
- 《Apache Spark源码剖析》
Spark Contributor,Databricks工程师连城,华为大数据平台开发部部长陈亮,网易杭州研究院副院长汪源,TalkingData首席数据科学家张夏天联袂力荐1.本书全面.系统地介绍了 ...
- Spark源码分析之八:Task运行(二)
在<Spark源码分析之七:Task运行(一)>一文中,我们详细叙述了Task运行的整体流程,最终Task被传输到Executor上,启动一个对应的TaskRunner线程,并且在线程池中 ...
随机推荐
- 主线程不能执行耗时的操作,子线程不能更新Ui
在Android项目中经常有碰到这样的问题,在子线程中完成耗时操作之后要更新UI,下面就自己经历的一些项目总结一下更新的方法: 在看方法之前看一下Android中消息机制: 引用 Message:消息 ...
- kotlin 遇到的问题
转载请表明 https://i.cnblogs.com/EditPosts.aspx?opt=1 从5月18号goole正式公布用kotlin做为android的新语言,做为android也很庆幸可以 ...
- Android无线测试之—UiAutomator UiScrollable API介绍六
向前与向后滚动API 一.向前与向后滚动相关API 返回值 API 描述 boolean scrollBackward(int steps) 自动以步长向后滑动 boolean scrollBackw ...
- UIImage 裁剪图片和等比列缩放图片
本文转载至 http://blog.csdn.net/cuiweijie3/article/details/9514293 转自 http://www.tedz.me/ios/uiimage-crop ...
- Course Selection CodeChef - RIN
All submissions for this problem are available. Read problems statements in Mandarin Chineseand Russ ...
- js的等于号==的判断
var str=0; str == "" 将返回true:
- Python--进阶处理6
# =================第六章:数据编码和处理====================== # 读CSV文件# 数据读取为一个元组的序列import csv# with open('E: ...
- 2017 Multi-University Training Contest - Team 1—HDU6033&&HDU6034
HDU6033 Add More Zero 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6033 题目意思:给一个m,求一个数k使得10^k最接近2 ...
- 粘性会话 session affinity sticky session requests from the same client to be passed to the same server in a group of servers
Module ngx_http_upstream_module http://nginx.org/en/docs/http/ngx_http_upstream_module.html#sticky S ...
- Apache Kafka Replication Design – High level
参考,https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Replication Kafka Replication High-level ...