jMiniLang设计思路
前言
项目地址:https://github.com/bajdcc/jMiniLang
演示视频:https://www.bilibili.com/video/av13294962
jMiniLang是一个Java实现的基于栈的解释器,包含了语法分析和虚拟机等两大内容。
基于这个虚拟机呢,用脚本搭建了一个简单的“操作系统”。本来只是用来测试下解释器的语法特性的,后来把一些想法加了进去。
截图在https://github.com/bajdcc/jMiniLang/releases里面,操作视频在。
系统的架构倒是比较“另类”的,它完全就是由管道和互斥来构造的。对于进程而言,无非就是阻塞来实现进程同步,管道一方面可以形成阻塞,另一方面可以实现进程间通信,可以说,管道机制非常有效。
下面就简单讲讲jMiniOS系统的设计思路。几个部分:语法特性、同步机制、系统架构。(一共就3张图)
语法特性
语法分析用LALR的,只要设计好BNF就能解析,parser涉及的内容太多,这里就略了。这里说下某些特性的实现:闭包和协程。
闭包
说到闭包,就会提到lambda。实现闭包,首先,系统需要能够动态地返回函数,其次,返回的函数中会引用到函数体外部的变量。
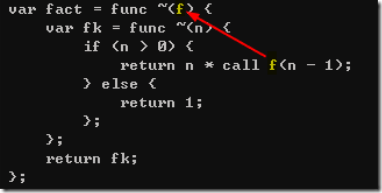
closure.png
上图中的fact会返回一个lambda(fk其实是多余的,只是语法实现功能有限)叫fk,fk中的一句"call f(n-1)"引用到了外层fact函数的参数f。
那这个特性如何去实现呢?
想像一下我现在执行fact函数时,发生的情况:
- f压栈,调用fact
- 栈上取参f,放入数据栈
- 返回一个lambda(图中是fk)
这时执行这个返回的lambda(注意它有一个参数n):
- 参数n压栈,调用lambda
- 栈上取参n
- 如果n大于0,跳到4,否则跳到5
- 执行f(n-1),乘上n,再返回
- 返回1
这里的问题是:在lambda中,如何执行f(n-1)呢?进一步要思考的问题:返回的lambda知晓不知晓f的存在?什么时候知晓的?解决了问题,就能实现闭包。
便于描述,将图中的f称作一个闭包(变量)。
思路:动态解决+静态解决。
从语法分析开始说起,解析fact函数之前,fk函数已经解析完毕了,这是由LR分析的特点决定的。在解析fk函数之前,fact的参数f已经被我放入一层层的符号表中,不管找到的这个f是在哪一层函数中的,只要找到了,确认不是引用错误就行。
步骤一:静态解决
在符号表中找到f后,接下来,我要让fk函数进行自检。由于这时fk函数已经是AST中的一个结点了,只要递归调用自检函数就可以了。自检很简单,凡是引用某个变量的,就将引用对象放入引用表中。然后,看一下fk函数的参数表。最终,引用表-参数表=闭包。
这样,通过自检,我在解析fact的过程中知道了fk的闭包。
解析好语法树后,就可以生成指令了。对于fk这个lambda,生成指令包含两大部分——实现部分和赋值部分。
实现部分就是将fk函数里面代码翻成指令(然后知道了fk第一行指令的位置fk_line),好理解。
赋值部分就是生成lambda并赋值给fk,指令类似于"load_lambda fk_line",这是因为对lambda而言,需要做一些额外的工作,因为这是动态语言,所以必须生成一个为function的动态类型。那闭包又该如何处理呢?对于函数中的闭包需要“额外优待”,即生成指令时将这些变量载入进去,每个变量有个自己的编号,载入这些编号就可以了。所以对于图中的fk,在"load_lambda fk_line"前肯定要有个声明闭包的指令"load_lambda_reference f",这样在生成动态类型时,会将外部变量f的值绑定到fk函数中。
步骤二:动态解决
动态运行的指令类似于(这里简化了,跟项目生成的有差别):
【fk函数的实现指令】
[1000] 载入参数n到数据栈
....
[1010] 返回
【fact函数的实现指令】
[2000] 载入参数f到数据栈
[2001] 将f放到额外的一个栈中(用于存放闭包)
[2002] 加载函数fk,地址1000,这时检测额外栈中有闭包,故生成动态类型RuntimeFunction时加上一个闭包f
【调用fact函数返回的lambda--fk】
[3000] 将n取出并保存到数据栈中
....
[3005] "call f(n-1)"对应的指令,这时要加载f,到符号表中找肯定找不到(因为当前执行的环境中没有f),因而尝试到当前环境fk的闭包里去找,找到后执行它并返回
闭包部分总结
语法分析部分:AST中查找闭包(变量),将闭包的信息存入AST结点ExpFunc中
指令生成部分:在AST中的调用结点ExpInvoke中,如果发现了闭包信息,就添加额外的指令load_lambda_reference(本项目中是压栈指令,将闭包的编号压栈,再将闭包数量压栈)
运行时部分:执行到load_lambda指令时,确认是否有闭包在栈中,如果有,将其添加到运行时函数类型RuntimeFunction中
查找变量:先在当前(函数)域中查找正常声明的变量(用var声明的),找不到,再从域中查找闭包(变量),再找不到,从上一层域中找,以此类推
协程

coroutine.png
认识协程,先想一个问题:实现对[a,b]中每个整数的依次处理(比方,实现[1,100]这一百个数的依次打印)
【简单方法】for循环100个数,分别调用之
【一般方法】先生成一个数组,for循环放入1~100这100个数,然后对数组遍历
【另类方法】协程,如图所示
上面除另类方法外,应该都好理解。另类方法其实是一种新的语法特性,协程。
在上面的问题上增加难度,现在对[a,b]进行扩展,变成[a,正无穷),如何?
【简单方法】依然可以
【一般方法】数组占用了大量内存空间,程序gg
【另类方法】依然可以
再降低难度,将范围[a,b]变成列表{101,203,407,666,888},列表里数是我胡乱写的,如何?
【简单方法】gg
【一般方法】将列表中的数依然放入数组并遍历
【另类方法】依然可以(yield 101,yield 203...)
需要3的倍数,...,再分别调用,如何?
【简单方法】可以
【一般方法】gg
【另类方法】魔性,"foreach (var i : call g_range(1, INT_MAX) * 3) {}",改个数字即可
综上,协程确实在某些方法与传统方法有着差别。
项目中用yield声明协程函数,返回用"yield n"。
foreach搭配yield的使用,使得foreach每次迭代时,会调用一次协程函数,协程返回一个当前索引i,然后再执行foreach循环体。第二次循环调用的协程不会重新开始,而是在第一次循环的基础上继续执行,这,就是协程的精华。常规语法时,每次调用同一个函数,如果函数不依靠任何外部信息,那么每次返回的值都是相同的,而协程不一样,它每次被调用后,就“自动暂停”了。
协程要怎样实现呢?
协程的实现基于for循环。for的语法是"for (声明指令; 判断指令; 迭代指令) {主体}";foreach的语法是"foreach(var 变量名 : yield函数表达式){主体}"。
for循环生成指令的主要步骤:
- 生成声明指令
- 生成break和continue的label
- 生成判断指令
- 生成循环主体指令
- 生成迭代指令(如i++)
而foreach生成指令的步骤:
- 生成声明指令
- 生成break和continue的label
- 调用协程函数(函数如果返回空则break)
- 生成循环主体指令
- 生成迭代指令(如i++)
在foreach中协程一直存在,既然它的状态是持续的,因而必然要保存其状态。
先设计好一些指令:
- iyldl 协程返回
- iyldr 协程进入
- iyldx 协程销毁
- iyldy 协程创建
- iyldi 协程栈数据入栈
- iyldo 协程栈数据出栈
上述指令负责程序在foreach间与协程函数间进行切换,以及数据交换等操作。
【协程函数翻译指令】
无非是原有的return指令变成了yield return指令。原先:ipushXXX/iret;现在:ipushXXX/iyldi/iyldl,即数据压栈、数据进协程栈、协程切回。
【调用者foreach指令】
调用协程的具体过程
判断协程是否初始化(首次创建),如果没有创建,就初始化。
初始化操作:
- 调用类型:ipush 调用类型/iyldi
- 协程传参:ipush 每个参数/后面带iyldi
- ipush 地址:传协程入口地址
- iyldy:创建协程,此时协程栈的大小=1(调用类型)+参数数量+1(地址)
如果已经初始化完成,进行:
- iyldr:切换到协程
- iyldo:将数据出协程栈,入数据栈
- ijnan:判断数据合法性,如果是null,就退出foreach循环
协程的创建
- 读取协程栈中的数据:调用类型+协程参数+协程地址。
- 切换到协程并执行
由于有协程栈和调用栈,所以栈与栈间存在父子关系。协程是当前调用栈创建出的,因为要设置父子关系parent。这样,当协程返回时,只要找到其parent就可以了(子找父)。反过来时,父根据hash表找到子,这是因为同一时刻同一层次也只有唯一一个协程存在。
循环出口的清理工作
执行iyldx,销毁创建的协程。
协程部分总结
- 调用栈部分:协程就是一种调用栈,而调用栈可以创建协程(调用)栈,反之亦可,可见调用栈存在层级关系,栈间的切换可以用类似树中父子关系实现
- 协程传参:通过协程栈数据通道进行传参,这个通道维系当前调用栈和产生的协程调用栈,且协程调用栈和普通调用栈一样,也有自己的数据栈和函数栈
- 指令部分:由上述设计的6种指令组成,不过还可进一步简化,值得注意的是,协程的创建只能创建一次,后一次必须检测协程是否已存在,避免重复创建
同步机制
jMiniLang采用的单线程模拟多进程的方式,这种比较容易实现。
多进程的世界,有两个典型问题——互斥量、信号量。进程的状态我设置得很简单——阻塞和非阻塞。把互斥量、信号量这两个问题解决了,就ok。
从时间来看,互斥量的使用场景应是激烈竞争、占用时间少的情况;信号量的情况是竞争不激烈、占用时间长。基于此情况,我将多数操作采用自旋锁实现,如锁定单变量的操作等。将少数耗时操作用信号量去做,即让进程休眠,节省开销。
互斥量
自旋锁实现是很简单的,就是轮循。由于解释器是单线程的,因此非常easy。
我添加了全局共享变量,让互斥量有用武之地。比如进程间的等待操作,将pid挂到等待列表上,而读写等待列表的操作是互斥的,且读写操作很快。
代码写来就是"lock(var);操作...;unlock(var);",而lock的操作就是"while(检测var有锁不,有就锁定);操作...",unlock的操作"直接解锁var变量"。其中这个while就是轮询。事实上,这些轮询操作都可以转化为用信号量去做,只是要设计一些等待列表。上面说到使用场景不怎么花时间(就改个变量),而用信号量会让进程休眠,强行进程切换,因此用信号量反而不适宜。
PS:jMiniLang中的互斥量是用自旋锁实现的,这不意味着所有互斥量都是用自旋锁做的。
信号量
这里,信号量我主要用block()和wakeup(),就是阻塞和唤醒。这两个方法的使用不是在用户代码层面,是在虚拟机层面。
管道与信号量
本系统中我设计了管道,相信管道这一概念已非常普及了。我没有直接提供操作信号量的API,而是提供了管道的API。
管道的操作:
- 创建/销毁
- 读/写
其中,管道读是一个阻塞操作,利用这一阻塞,可以用管道去实现信号量的功能。
原理也很简单,设计的命名管道,每一管道有缓冲区。读:如果缓冲区无数据,就阻塞,否则取数据;写:向缓冲区写数据,并唤醒阻塞的进程。
另外,进程等待(join)操作也是阻塞的。类似的耗时操作都可以改成阻塞的。
系统架构
用jMiniLang解释器做个仿OS的程序,姑且称作jMiniOS吧。
它的设计理念:
- 基于互斥量和信号量
- 仅有共享变量服务(全局set/get)和管道服务
- 微服务架构service
- 多进程间的输入/输出流
- 中断例程task(流实现)
服务组成

ps.png
模拟IRQ的系统服务task:
- remote 用户界面输入输出
- task 微服务代理
- print 控制台debug输出
- signal 信号(如poweroff)
用户服务service(目前实现的):system util ui net
微服务架构
三种对象:客户端(调用者)、代理端(系统服务)、服务端(被调用者)
下面区别三种对象:客户端、代理端、服务端
客户端(调用者)
调用方法:客户端进程调用g_task_get/g_task_get_fast/g_task_get_fast_arg方法,获取数据代理端(充当中介)
已实现的task_handler,它的目的是连接客户端和服务端服务端(服务者)
这方面要自己实现
调用顺序:
- 客户端调用task_get_fast等方法
- task_get_fast安排好请求数据,触发int#1服务中断
- 中断会调用task_handler代理方法
客户端向代理端发送消息
- 准备请求数据
- 锁定等待队列
- 将当前进程添加至代理端的等待队列中
- 解锁队列
- 报告服务中断例程
- 发送消息事件给中断例程,使之调用task_handler
- 此时代理端会向服务端发送请求
- 等待代理端处理完毕
代理端处理客户端的消息
- 锁定等待队列
- 取最早等待的进程,移除它
- 解锁队列
- 读取客户端的数据
- 唤醒服务端,这时服务端在处理请求
- 连接服务端
- 防止多个代理端同时请求服务端,用管道做阻塞
- 处理完毕,唤醒客户端
此架构的好处
如果没有代理端,那么客户端和服务端直接相连,由于服务端只有一条输入管道,那么多个客户端发送的数据会发生冲突,因此多个客户端的请求只能一个个来,代理端就是这个作用,维护一个等待队列。
另外,服务端的接口不会暴露给客户端,保证了安全。
进程传输流
jMiniOS提供了一个简单的shell,用来执行一些程序,依照linux,采用管道去处理父/子进程间的输入输出流。
以最简单的pipe函数为例:
- 获取本pid的输入流句柄
- 获取本pid的输出流句柄
- 读取输入流,在读取操作中将数据传给输出流
当最内层的进程销毁输出流后,流将被链式销毁,直到最外层进程。实现ctrl+c的思路:销毁各子进程的输入流、创建SIGKILL类似的共享变量。
由于我未实现kill_process函数,所以每个进程只能自己退出,不会强行被kill,这样只要所有进程都退出,就说明堵塞的调用没有问题。
总结
从15年开始第一行代码,到现在约莫2W行(除去废话),每次加个新功能要想半天+查错N天,但是还是坚持下来了。写上面的闭包和协程时因为当时懒没多少注释,还打log半天才搞懂当时的设计思路,所以写写总结也是必要的,毕竟是坚持得最久的一个repo了。
把parser+vm+ui结合起来,除了fastjson和log4j也没用其他库,白手起家,自娱自乐~
作者:bajdcc
链接:https://www.jianshu.com/p/c7d819fbf873
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
由https://www.jianshu.com/p/c7d819fbf873备份。
jMiniLang设计思路的更多相关文章
- TYPESDK手游聚合SDK服务端设计思路与架构之一:应用场景分析
TYPESDK 服务端设计思路与架构之一:应用场景分析 作为一个渠道SDK统一接入框架,TYPESDK从一开始,所面对的需求场景就是多款游戏,通过一个统一的SDK服务端,能够同时接入几十个甚至几百个各 ...
- 分享一个CQRS/ES架构中基于写文件的EventStore的设计思路
最近打算用C#实现一个基于文件的EventStore. 什么是EventStore 关于什么是EventStore,如果还不清楚的朋友可以去了解下CQRS/Event Sourcing这种架构,我博客 ...
- ENode框架单台机器在处理Command时的设计思路
设计目标 尽量快的处理命令和事件,保证吞吐量: 处理完一个命令后不需要等待命令产生的事件持久化完成就能处理下一个命令,从而保证领域内的业务逻辑处理不依赖于持久化IO,实现真正的in-memory: 保 ...
- WebGIS中快速整合管理多源矢量服务以及服务权限控制的一种设计思路
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 在真实项目中,往往GIS服务数据源被其他多个信息中心或者第三方 ...
- OpenStack 通用设计思路 - 每天5分钟玩转 OpenStack(25)
API 前端服务 每个 OpenStack 组件可能包含若干子服务,其中必定有一个 API 服务负责接收客户请求. 以 Nova 为例,nova-api 作为 Nova 组件对外的唯一窗口,向客户暴露 ...
- Redis入门指南(第2版) Redis设计思路学习与总结
https://www.qcloud.com/community/article/222 宋增宽,腾讯工程师,16年毕业加入腾讯,从事海量服务后台设计与研发工作,现在负责QQ群后台等项目,喜欢研究技术 ...
- MVC3 数据验证用法之密码验证设计思路
描述:MVC数据验证使用小结 内容:display,Required,stringLength,Remote,compare,RegularExpression 本人最近在公司用mvc做了一个修改密码 ...
- YYCache设计思路及源码学习
设计思路 利用YYCache来进行操作,实质操作分为了内存缓存操作(YYMemoryCache)和硬盘缓存操作(YYDiskCache).内存缓存设计一般是在内存中开辟一个空间用以保存请求的数据(一般 ...
- 第三篇:Retrofit SDK的设计思路
2016-05-08 15:24:03 Retreofit毫无疑问是一个优美的开源框架,有轻量级.耦合性低.扩展性好.灵活性高的特点,那么Retrofit的设计者们到底是怎么样做到这些的呢?我希望能够 ...
随机推荐
- go语言基础之range的用法
一.range的用法 示例1: 传统用法 package main //必须有一个main包 import "fmt" func main() { str := "abc ...
- 神奇的container_of
container_of是linux内核中常用的一个宏,这个宏的功能是,根据某个结构体字段的指针,找到对应的结构体指针. 话不多说,先上源码: /** * container_of - cast a ...
- 如何使用JW Player来播放Flash并隐藏控制按钮和自定义播放完成后执行的JS
在一个客户项目中播放的flash需要进行定制如不显示控制按钮,flash播放完成后执行特定的js等,在用过了N多的JQery插件和播放器后最终JW Player插件可以满足我的以上要求 因为JW Pl ...
- JWT token心得
token的组成 token串的生成流程. token在客户端与服务器端的交互流程 Token的优点和思考 参考代码:核心代码使用参考,不是全部代码 JWT token的组成 头部(Header),格 ...
- (笔试题)N!的三进制数尾部0的个数
题目: 用十进制计算30!(30的阶乘),将结果转换成3进制进行表示的话,该进制下的结果末尾会有____个0. 思路: 这道题与上一篇博文N!尾部连续0的个数的思路是一样的. 计算N!下三进制结果末尾 ...
- 2014年七月最佳jQuery插件荟萃
本月的jQuery插件荟萃我们将介绍几款非常不错的jQuery插件,涵盖了表单,幻灯,页面设计等等方面,相信大家肯定会喜欢! Select or Die 一款帮助开发者美化并且强化选择框的jQuery ...
- SQL语句中拆分字段
SELECT PARSENAME(replace(MONITOR_ROOM_ID,'^' , '.'), 1) AS RoomID FROM ZY_MONITOR_ROOM 遇到以前系统高人设计的表, ...
- Linux系统攻略 用UUID在Fstab中挂载分区
Fstab 文件大家都很熟悉,Linux 在启动的时候通过 fstab 中的信息挂载各个分区,一个典型的分区条目就像这样: /dev/sdb5 /mnt/usb vfat utf8,umask=0 0 ...
- ios开发-调用系统自带手势
在 iPhone 或 iPad 的开发中,除了用 touchesBegan / touchesMoved / touchesEnded 这组方法来控制使用者的手指触控外,也可以用 UIGestureR ...
- Oracle的操作系统身份认证
Oracle的操作系统身份认证 oraclelogin数据库远程登录authenticationos sqlnet.authentication_services=(NTS),在$ORACLE_HOM ...