【转载】协同过滤 & Spark机器学习实战
因为协同过滤内容比较多,就新开一篇文章啦~~
聚类和线性回归的实战,可以看:http://www.cnblogs.com/charlesblc/p/6159187.html
协同过滤实战,仍然参考:http://www.cnblogs.com/shishanyuan/p/4747778.html
其中有一些基础和算法类的,会有其他一些文章来做参考。
1.3 协同过滤实例
1.3.1 算法说明
协同过滤(Collaborative Filtering,简称CF,WIKI上的定义是:简单来说是利用某个兴趣相投、拥有共同经验之群体的喜好来推荐感兴趣的资讯给使用者,个人透过合作的机制给予资讯相当程度的回应(如评分)并记录下来以达到过滤的目的,进而帮助别人筛选资讯,回应不一定局限于特别感兴趣的,特别不感兴趣资讯的纪录也相当重要。
协同过滤常被应用于推荐系统。这些技术旨在补充用户—商品关联矩阵中所缺失的部分。
MLlib 当前支持基于模型的协同过滤,其中用户和商品通过一小组隐性因子进行表达,并且这些因子也用于预测缺失的元素。MLLib 使用交替最小二乘法(ALS) 来学习这些隐性因子。(ALS见后文内容)
用户对物品或者信息的偏好,根据应用本身的不同,可能包括用户对物品的评分、用户查看物品的记录、用户的购买记录等。其实这些用户的偏好信息可以分为两类:
l 显式的用户反馈:这类是用户在网站上自然浏览或者使用网站以外,显式地提供反馈信息,例如用户对物品的评分或者对物品的评论。
l 隐式的用户反馈:这类是用户在使用网站是产生的数据,隐式地反映了用户对物品的喜好,例如用户购买了某物品,用户查看了某物品的信息,等等。
显式的用户反馈能准确地反映用户对物品的真实喜好,但需要用户付出额外的代价;而隐式的用户行为,通过一些分析和处理,也能反映用户的喜好,只是数据不是很精确,有些行为的分析存在较大的噪音。但只要选择正确的行为特征,隐式的用户反馈也能得到很好的效果,只是行为特征的选择可能在不同的应用中有很大的不同,例如在电子商务的网站上,购买行为其实就是一个能很好表现用户喜好的隐式反馈。
推荐引擎根据不同的推荐机制可能用到数据源中的一部分,然后根据这些数据,分析出一定的规则或者直接对用户对其他物品的喜好进行预测计算。这样推荐引擎可以在用户进入时给他推荐他可能感兴趣的物品。
MLlib目前支持基于协同过滤的模型,在这个模型里,用户和产品被一组可以用来预测缺失项目的潜在因子来描述。特别是我们实现交替最小二乘(ALS)算法来学习这些潜在的因子,在 MLlib 中的实现有如下参数:
l numBlocks是用于并行化计算的分块个数(设置为-1时 为自动配置);
l rank是模型中隐性因子的个数;
l iterations是迭代的次数;
l lambda是ALS 的正则化参数;
l implicitPrefs决定了是用显性反馈ALS 的版本还是用隐性反馈数据集的版本;
l alpha是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准。

1.3.2 实例介绍
在本实例中将使用协同过滤算法对GroupLens Research(http://grouplens.org/datasets/movielens/)提供的数据进行分析,该数据为一组从20世纪90年末到21世纪初由MovieLens用户提供的电影评分数据,这些数据中包括电影评分、电影元数据(风格类型和年代)以及关于用户的人口统计学数据(年龄、邮编、性别和职业等)。根据不同需求该组织提供了不同大小的样本数据,不同样本信息中包含三种数据:评分、用户信息和电影信息。
对这些数据分析进行如下步骤:
1. 装载如下两种数据:
a)装载样本评分数据,其中最后一列时间戳除10的余数作为key,Rating为值;(Key用来分组的,如下校验组)
b)装载电影目录对照表(电影ID->电影标题)
2.将样本评分表以key值切分成3个部分,分别用于训练 (60%,并加入用户评分), 校验 (20%), and 测试 (20%)(这个分法非常重要,因为是多个参数进行实验的,一定需要校验数据来判断哪种参数是最优的)
3.训练不同参数下的模型,并再校验集中验证,获取最佳参数下的模型
4.用最佳模型预测测试集的评分,计算和实际评分之间的均方根误差
5.根据用户评分的数据,推荐前十部最感兴趣的电影(注意要剔除用户已经评分的电影)
1.3.3 测试数据说明
在MovieLens提供的电影评分数据分为三个表:评分、用户信息和电影信息,在该系列提供的附属数据提供大概6000位读者和100万个评分数据,具体位置为/data/class8/movielens/data目录下,对三个表数据说明可以参考该目录下README文档。
1.评分数据说明(ratings.data)
该评分数据总共四个字段,格式为UserID::MovieID::Rating::Timestamp,分为为用户编号::电影编号::评分::评分时间戳,其中各个字段说明如下: l用户编号范围1~6040 l电影编号1~3952 l电影评分为五星评分,范围0~5 l评分时间戳单位秒 l每个用户至少有20个电影评分 使用的ratings.dat的数据样本如下所示: 1::1193::5::978300760
1::661::3::978302109
1::914::3::978301968
1::3408::4::978300275
1::2355::5::978824291
1::1197::3::978302268
1::1287::5::978302039
1::2804::5::978300719
2.用户信息(users.dat)
用户信息五个字段,格式为UserID::Gender::Age::Occupation::Zip-code,分为为用户编号::性别::年龄::职业::邮编,其中各个字段说明如下: l用户编号范围1~6040 l性别,其中M为男性,F为女性 l不同的数字代表不同的年龄范围,如:25代表25~34岁范围 l职业信息,在测试数据中提供了21中职业分类 l地区邮编 使用的users.dat的数据样本如下所示: 1::F::1::10::48067
2::M::56::16::70072
3::M::25::15::55117
4::M::45::7::02460
5::M::25::20::55455
6::F::50::9::55117
7::M::35::1::06810
8::M::25::12::11413
3.电影信息(movies.dat)
电影数据分为三个字段,格式为MovieID::Title::Genres,分为为电影编号::电影名::电影类别,其中各个字段说明如下: l电影编号1~3952 l由IMDB提供电影名称,其中包括电影上映年份 l电影分类,这里使用实际分类名非编号,如:Action、Crime等 使用的movies.dat的数据样本如下所示: 1::Toy Story (1995)::Animation|Children's|Comedy
2::Jumanji (1995)::Adventure|Children's|Fantasy
3::Grumpier Old Men (1995)::Comedy|Romance
4::Waiting to Exhale (1995)::Comedy|Drama
5::Father of the Bride Part II (1995)::Comedy
6::Heat (1995)::Action|Crime|Thriller
7::Sabrina (1995)::Comedy|Romance
8::Tom and Huck (1995)::Adventure|Children's
程序代码如下:
要注意的是,Spark的ALS协同过滤,是基于矩阵分解的,既不是user cf,也不是item cf。关于user cf 和 item cf可以看后面。
关于里面的Some函数,可以参考:
https://windor.gitbooks.io/beginners-guide-to-scala/content/chp5-the-option-type.html
http://www.jianshu.com/p/95896d06a94d
Option有两个子类别,Some和None。当程序回传Some的时候,代表这个函式成功地给了你一个String,而你可以透过get()函数拿到那个String,如果程序返回的是None,则代表没有字符串可以给你。
在返回None,也就是没有String给你的时候,如果你还硬要调用get()来取得 String 的话,Scala一样是会抛出一个NoSuchElementException异常给你的。
我们也可以选用另外一个方法,getOrElse。这个方法在这个Option是Some的实例时返回对应的值,而在是None的实例时返回传入的参数。换句话说,传入getOrElse的参数实际上是默认返回值。
代码如下:
package com.spark.my
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.regression.{LabeledPoint, LinearRegressionWithSGD}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import scala.io.Source
/**
* Created by baidu on 16/11/28.
*/
object MovieLensALS {
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val conf = new SparkConf()
val sc = new SparkContext(conf)
println("Begin rating file")
// 装载数据集
val text = sc.textFile("hdfs://master.Hadoop:8390/movie_data/ratings.dat")
val ratings = text.map {
line =>
val parts = line.split("::")
(parts(3).toLong % 10, Rating(parts(0).toInt, parts(1).toInt, parts(2).toDouble))
}
val numPartitions = 4
val training = ratings.filter(x => x._1 < 6) // 分组
.values
.repartition(numPartitions)
.cache()
val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8)
.values
.repartition(numPartitions)
.cache()
val test = ratings.filter(x => x._1 >= 8)
.values
.repartition(numPartitions)
.cache()
println("Finish data loading, train num: " + training.count()
+ " valid num: " + validation.count() + " test num: " + test.count())
val ranks = List(8, 12)
val lambdas = List(0.1, 10.0)
val numIters = List(10, 20)
var bestModel: Option[MatrixFactorizationModel] = None
var bestValidationRmse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumIter = -1
println("Start train models with different parameters")
for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
val model = ALS.train(training, rank, numIter, lambda) // 注意参数的顺序
val rmse = computeRmse(model, validation)
println("RMSE=" + rmse + " for model with rank " + rank
+ " lambda " + lambda + " numIter " + numIter)
if (rmse < bestValidationRmse) {
bestModel = Some(model)
bestValidationRmse = rmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
// 计算测试集合的结果
val testRmse = computeRmse(bestModel.get, test)
println("The best model was trained with rank = " + bestRank + " and lambda = " + bestLambda
+ " and numIter = " + bestNumIter + " and its RMSE is " + testRmse)
// 跟直接平均rating做对比
val meanRating = training.union(validation).map(_.rating).mean
val baselineRmse = math.sqrt(test.map(x => (meanRating - x.rating) * (meanRating - x.rating)).reduce(_ + _) / test.count)
println("The best model improves the baseline by " + "%1.2f".format((baselineRmse - testRmse) / baselineRmse) + "%.")
// 获取某一个用户的推荐结果
/*val myratings = Source.fromFile("/home/work/data/installed/spark-2.0.1-bin-hadoop2.7/mydata/movie_data/oneratings.dat")
.getLines()
.map{
line =>
val parts = line.split("::")
Rating(parts(0).toInt, parts(1).toInt, parts(2).toDouble)
}*/
// 开始以为只能读普通文件,后来发现读hadoop也可以,用collect就可以
val myratings = sc.textFile("hdfs://master.Hadoop:8390/movie_data/oneratings.dat")
.collect()
.map {
line =>
val parts = line.split("::")
Rating(parts(0).toInt, parts(1).toInt, parts(2).toDouble)
}
val ratedMovies = myratings.toSeq.map(_.product).toSet
val myid = myratings.toSeq(0).user
val movies = sc.textFile("hdfs://master.Hadoop:8390/movie_data/movies.dat")
.map {
line =>
val fields = line.split("::")
(fields(0).toInt, fields(1))
}
.collect()
.toMap
val candid = movies.keys.filter(x => !ratedMovies.contains(x)).toSeq
val cand = sc.parallelize(candid) // 注意这一行很神奇,其实是创建RDD
val recommend = bestModel.get
.predict(cand.map(x => (myid, x)))
.collect()
.sortBy(-_.rating) // 为了从大到小排序
.take(10)
var i = 1
println("Movies recommeded for user " + myid)
recommend.foreach{
r =>
println("%2d".format(i) + ": " + movies.get(r.product))
i += 1
}
sc.stop()
println("All elements done")
}
// 根据实际数据的均方根误差来判断效果
def computeRmse(model:MatrixFactorizationModel, data:RDD[Rating]): Double = {
val predict: RDD[Rating] = model.predict(data.map(x=>(x.user, x.product)))
val comparePredict = predict.map(x=>((x.user, x.product), x.rating))
.join(data.map(x=>((x.user, x.product), x.rating)))
.values
val n = predict.count()
math.sqrt(comparePredict.map(x=>(x._1-x._2)*(x._1-x._2)).reduce(_+_)/n)
}
}
然后准备hadoop的数据
$ hadoop fs -mkdir /movie_data $ hadoop fs -put ratings.dat /movie_data $ hadoop fs -put movies.dat /movie_data $ hadoop fs -put oneratings.dat /movie_data $ hadoop fs -ls /movie_data
Found 3 items
-rw-r--r-- 3 work supergroup 171308 2016-12-12 23:35 /movie_data/movies.dat
-rw-r--r-- 3 work supergroup 2079 2016-12-12 23:35 /movie_data/oneratings.dat
-rw-r--r-- 3 work supergroup 24594131 2016-12-12 23:35 /movie_data/ratings.dat
准备好jar文件后,运行命令:
./bin/spark-submit --class com.spark.my.MovieLensALS --master spark://10.117.146.12:7077 myjars/scala-demo.jar
能够得出结果:
$ ./bin/spark-submit --class com.spark.my.MovieLensALS --master spark://10.117.146.12:7077 myjars/scala-demo.jar
16/12/12 23:44:11 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/12/12 23:44:12 INFO util.log: Logging initialized @1690ms
16/12/12 23:44:12 INFO server.Server: jetty-9.2.z-SNAPSHOT
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@297ea53a{/jobs,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@acb0951{/jobs/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5bf22f18{/jobs/job,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@267f474e{/jobs/job/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7a7471ce{/stages,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@28276e50{/stages/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@62e70ea3{/stages/stage,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3efe7086{/stages/stage/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@675d8c96{/stages/pool,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@741b3bc3{/stages/pool/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2ed3b1f5{/storage,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@63648ee9{/storage/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@68d6972f{/storage/rdd,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@45be7cd5{/storage/rdd/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7651218e{/environment,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3185fa6b{/environment/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6d366c9b{/executors,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5b58ed3c{/executors/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@24faea88{/executors/threadDump,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3a320ade{/executors/threadDump/json,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@64beebb7{/static,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7813cb11{/,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@bcec031{/api,null,AVAILABLE}
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@21005f6c{/stages/stage/kill,null,AVAILABLE}
16/12/12 23:44:12 INFO server.ServerConnector: Started ServerConnector@6d0068ad{HTTP/1.1}{0.0.0.0:4040}
16/12/12 23:44:12 INFO server.Server: Started @1816ms
16/12/12 23:44:12 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@b273a59{/metrics/json,null,AVAILABLE}
Begin rating file
16/12/12 23:44:14 INFO mapred.FileInputFormat: Total input paths to process : 1
Finish data loading, train num: 602241 valid num: 198919 test num: 199049
Start train models with different parameters
RMSE=0.8806912752883373 for model with rank 8 lambda 0.1 numIter 10
RMSE=0.8723240467041277 for model with rank 8 lambda 0.1 numIter 20
RMSE=3.756322766790857 for model with rank 8 lambda 10.0 numIter 10
RMSE=3.756322766790857 for model with rank 8 lambda 10.0 numIter 20
RMSE=0.8771920345984275 for model with rank 12 lambda 0.1 numIter 10
RMSE=0.8708229872082264 for model with rank 12 lambda 0.1 numIter 20
RMSE=3.756322766790857 for model with rank 12 lambda 10.0 numIter 10
RMSE=3.756322766790857 for model with rank 12 lambda 10.0 numIter 20
The best model was trained with rank = 12 and lambda = 0.1 and numIter = 20 and its RMSE is 0.8685987185037917
The best model improves the baseline by 0.22%.
16/12/12 23:45:17 INFO mapred.FileInputFormat: Total input paths to process : 1
16/12/12 23:45:17 INFO mapred.FileInputFormat: Total input paths to process : 1
Movies recommeded for user 1000
1: Some(Bewegte Mann, Der (1994))
2: Some(For All Mankind (1989))
3: Some(Sanjuro (1962))
4: Some(Man of the Century (1999))
5: Some(Bandits (1997))
6: Some(Chushingura (1962))
7: Some(Leather Jacket Love Story (1997))
8: Some(Usual Suspects, The (1995))
9: Some(Wrong Trousers, The (1993))
10: Some(Rear Window (1954))
...
All elements done
参考资料
(1)Spark官网 mlllib说明 http://spark.apache.org/docs/1.1.0/mllib-guide.html
(2)《机器学习常见算法分类汇总》 http://www.ctocio.com/hotnews/15919.html
可以继续看一下 ALS的介绍:
https://www.zhihu.com/question/31509438/answer/52268608
对于一个users-products-rating的评分数据集,ALS会建立一个user*product的m*n的矩阵
其中,m为users的数量,n为products的数量
但是在这个数据集中,并不是每个用户都对每个产品进行过评分,所以这个矩阵往往是稀疏的,用户i对产品j的评分往往是空的
ALS所做的事情就是将这个稀疏矩阵通过一定的规律填满,这样就可以从矩阵中得到任意一个user对任意一个product的评分,
ALS填充的评分项也称为用户i对产品j的预测得分
所以说,ALS算法的核心就是通过什么样子的规律来填满(预测)这个稀疏矩阵
它是这么做的:
假设m*n的评分矩阵R,可以被近似分解成U*(V)T
U为m*d的用户特征向量矩阵
V为n*d的产品特征向量矩阵((V)T代表V的转置,原谅我不会打转置这个符号。。)
d为user/product的特征值的数量
关于d这个值的理解,大概可以是这样的
对于每个产品,可以从d个角度进行评价,以电影为例,可以从主演,导演,特效,剧情4个角度来评价一部电影,那么d就等于4
可以认为,每部电影在这4个角度上都有一个固定的基准评分值
例如《末日崩塌》这部电影是一个产品,它的特征向量是由d个特征值组成的
d=4,有4个特征值,分别是主演,导演,特效,剧情
每个特征值的基准评分值分别为(满分为1.0):
主演:0.9(大光头还是那么霸气)
导演:0.7
特效:0.8
剧情:0.6
矩阵V由n个product*d个特征值组成 注:不太清楚,这个d是否指的就是spark程序里面的rank
其中a1-4为用户A的特征值,d1-4为之前所说的电影的特征值
参考:
协同过滤中的矩阵分解算法研究
那么对于之前ALS算法的这个假设
m*n的评分矩阵R,可以被近似分解成U*(V)T
就是成立的,某个用户对某个产品的评分可以通过矩阵U某行和矩阵V(转置)的某列相乘得到 那么现在的问题是,如何确定用户和产品的特征值?(之前仅仅是举例子,实际中这两个都是未知的变量)
采用的是交替的最小二乘法

在上面的公式中,a表示评分数据集中用户i对产品j的真实评分,另外一部分表示用户i的特征向量(转置)*产品j的特征向量(这里可以得到预测的i对j的评分)
用真实评分减去预测评分然后求平方,对下一个用户,下一个产品进行相同的计算,将所有结果累加起来
(其中,数据集构成的矩阵是存在大量的空打分,并没有实际的评分,解决的方法是就只看对已知打分的项)
参考:
ALS 在 Spark MLlib 中的实现
但是这里之前问题还是存在,就是用户和产品的特征向量都是未知的,这个式子存在两个未知变量。
具体算法略,见原文。
总结一下:
ALS算法的核心就是将稀疏评分矩阵分解为用户特征向量矩阵和产品特征向量矩阵的乘积
交替使用最小二乘法逐步计算用户/产品特征向量,使得差平方和最小
通过用户/产品特征向量的矩阵来预测某个用户对某个产品的评分
另,问: ALS训练出来的模型里面有用户和产品的所有特征向量,我可不可以拿这些特征向量来计算用户/产品的相似度,然后用UserCF或者ItemCF来计算推荐,mllib里面现在都没有这两个算法的实现?
回答:当然可以,但是感觉这个是在绕远路,本来都已经有factor信息可以直接计算了,还通过相似度来计算评分有点舍近求远了。
上面这段问答,其实讲出了ALS和 item/user CF 的区别。他们是殊途同归。
http://www.cnblogs.com/skyEva/p/5570098.html
ALS 其实是 交替最小二乘(alternating least squares)
1. 基础回顾
矩阵的奇异值分解 SVD
(特别详细的总结,参考 http://blog.csdn.net/wangzhiqing3/article/details/7446444)
- 矩阵与向量相乘的结果与特征值,特征向量有关。
- 数值小的特征值对矩阵-向量相乘的结果贡献小
1)低秩近似
2)特征降维
相似度和距离度量
(参考 http://blog.sina.com.cn/s/blog_62b83291010127bf.html)
2. ALS 交替最小二乘(alternating least squares)
在机器学习中,ALS 指使用交替最小二乘求解的一个协同推荐算法。
- 它通过观察到的所有用户给商品的打分,来推断每个用户的喜好并向用户推荐适合的商品。
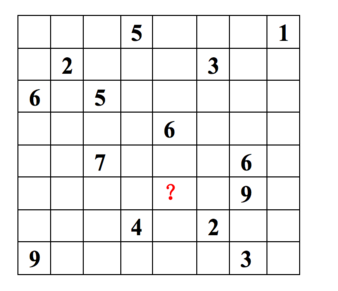
每一行代表一个用户(u1,u2,…,u8), 每一列代表一个商品(v1,v2,…,v8),用户的打分为1-9分。
这个矩阵只显示了观察到的打分,我们需要推测没有观察到的打分。
ALS的核心就是这样一个假设:打分矩阵是近似低秩的。
换句话说,就是一个m*n的打分矩阵可以由分解的两个小矩阵U(m*k)和V(k*n)的乘积来近似,即 A=UVT,k<=m,n 。这就是ALS的矩阵分解方法。
这样我们把系统的自由度从O(mn)降到了O((m+n)k)。
低维空间的选取。
这个低维空间要能够很好的区分事物,那么就需要一个明确的可量化目标,这就是重构误差。
在ALS中我们使用 F范数 来量化重构误差,就是每个元素重构误差的平方和。这里存在一个问题,我们只观察到部分打分,A中的大量未知元是我们想推断的,所以这个重构误差是包含未知数的。
解决方案很简单:只计算已知打分的重构误差。

3. 协同过滤
协同过滤分析用户以及用户相关的产品的相关性,用以识别新的用户-产品相关性。
协同过滤系统需要的唯一信息是用户过去的行为信息,比如对产品的评价信息。
- 推荐系统依赖不同类型的输入数据,最方便的是高质量的显式反馈数据,它们包含用户对感兴趣商品明确的评价。例如,
Netflix收集的用户对电影评价的星星等级数据。 - 但是显式反馈数据不一定总是找得到,因此推荐系统可以从更丰富的隐式反馈信息中推测用户的偏好。 隐式反馈类型包括购买历史、浏览历史、搜索模式甚至鼠标动作。
4. 显示反馈模型
通过内积 rij = uiT vj 来预测,另外加入正则化参数 lamda 来预防 过拟合。
最小化重构误差:
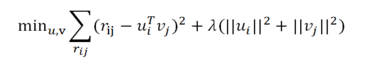
5. 隐式反馈模型
(此处隐藏细节)最小化损失函数(看起来就是变成了多个):
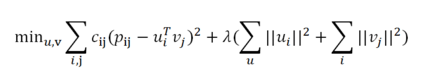
6. 求解:最优化
1)显示和隐式的异同:
- 显示模型只基于观察到的值;隐式需要考虑不同的信任度,最优化时需要考虑所有可能的
u,v对
2) 交替最小二乘求解:
即固定 ui 求 vi+1 再固定 vi+1 求 ui+1
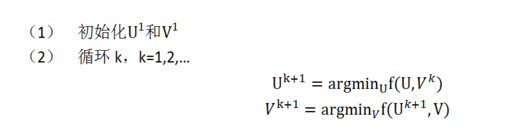
例子
import org.apache.spark.mllib.recommendation._ //处理训练数据
val data = sc.textFile("data/mllib/als/test.data")
val ratings = data.map(_.split(',') match { case Array(user, item, rate) =>
Rating(user.toInt, item.toInt, rate.toDouble)
}) // 使用ALS训练推荐模型
val rank = 10
val numIterations = 10
val model = ALS.train(ratings, rank, numIterations, 0.01)
ALS算法实现于org.apache.spark.ml.recommendation.ALS.scala文件中- Rating也在recommendation里面
注意,上面参数最后的lambda一般要小于1.
在之前的Spark例子里,用了val lambdas = List(0.1, 10.0) 两种。根据跑的结果,看起来0.1的效果要远远好于10.0的结果。
如下:
RMSE=0.8806912752883373 for model with rank 8 lambda 0.1 numIter 10
RMSE=0.8723240467041277 for model with rank 8 lambda 0.1 numIter 20
RMSE=3.756322766790857 for model with rank 8 lambda 10.0 numIter 10
RMSE=3.756322766790857 for model with rank 8 lambda 10.0 numIter 20
RMSE=0.8771920345984275 for model with rank 12 lambda 0.1 numIter 10
RMSE=0.8708229872082264 for model with rank 12 lambda 0.1 numIter 20
RMSE=3.756322766790857 for model with rank 12 lambda 10.0 numIter 10
RMSE=3.756322766790857 for model with rank 12 lambda 10.0 numIter 20
以及user CF / item CF
http://www.cnblogs.com/luchen927/archive/2012/02/01/2325360.html
什么是协同过滤
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。 换句话说,就是借鉴和你相关人群的观点来进行推荐,很好理解。 协同过滤的实现:要实现协同过滤的推荐算法,要进行以下三个步骤: 收集数据——找到相似用户和物品——进行推荐
收集数据
这里的数据指的都是用户的历史行为数据,比如用户的购买历史,关注,收藏行为,或者发表了某些评论,给某个物品打了多少分等等,这些都可以用来作为数据供推荐算法使用,服务于推荐算法。需要特别指出的在于,不同的数据准确性不同,粒度也不同,在使用时需要考虑到噪音所带来的影响。
找到相似用户和物品
这一步也很简单,其实就是计算用户间以及物品间的相似度。以下是几种计算相似度的方法:
欧几里德距离
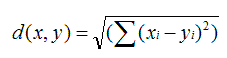
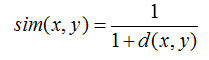
皮尔逊相关系数

Cosine 相似度
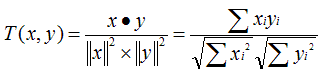
Tanimoto 系数
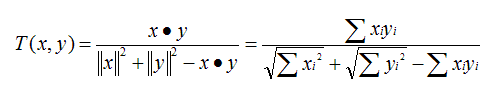
进行推荐
在知道了如何计算相似度后,就可以进行推荐了。
在协同过滤中,有两种主流方法:基于用户的协同过滤,和基于物品的协同过滤(当然了,还有上文提到的ALS)。具体怎么来阐述他们的原理呢,看个图大家就明白了。
User-based CF
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。 下图给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
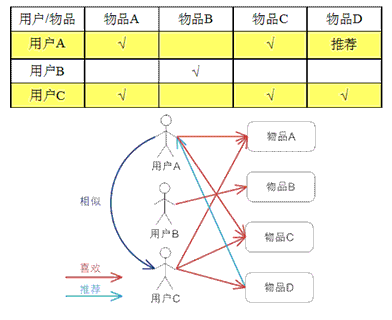
Item-based CF
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。下图给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
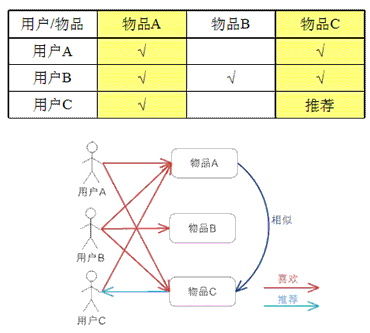
总结及对比
以上两个方法都能很好的给出推荐,并可以达到不错的效果。但是他们之间还是有不同之处的,而且适用性也有区别。下面进行一下对比
1. 计算复杂度
Item CF 和 User CF 是基于协同过滤推荐的两个最基本的算法,User CF 是很早以前就提出来了,Item CF 是从 Amazon 的论文和专利发表之后(2001 年左右)开始流行,大家都觉得 Item CF 从性能和复杂度上比 User CF 更优,其中的一个主要原因就是对于一个在线网站,用户的数量往往大大超过物品的数量,同时物品的数据相对稳定,因此计算物品的相似度不但计算量较小,同时也不必频繁更新。但我们往往忽略了这种情况只适应于提供商品的电子商务网站,对于新闻,博客或者微内容的推荐系统,情况往往是相反的,物品的数量是海量的,同时也是更新频繁的,所以单从复杂度的角度,这两个算法在不同的系统中各有优势,推荐引擎的设计者需要根据自己应用的特点选择更加合适的算法。
2. 适用场景
在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的推荐原则更加有效。比如在购书网站上,当你看一本书的时候,推荐引擎会给你推荐相关的书籍,这个推荐的重要性远远超过了网站首页对该用户的综合推荐。可以看到,在这种情况下,Item CF 的推荐成为了引导用户浏览的重要手段。同时 Item CF 便于为推荐做出解释,在一个非社交网络的网站中,给某个用户推荐一本书,同时给出的解释是某某和你有相似兴趣的人也看了这本书,这很难让用户信服,因为用户可能根本不认识那个人;但如果解释说是因为这本书和你以前看的某本书相似,用户可能就觉得合理而采纳了此推荐。
相反的,在现今很流行的社交网络站点中,User CF 是一个更不错的选择,User CF 加上社会网络信息,可以增加用户对推荐解释的信服程度。
下面是上面CF这篇引用文章的参考文章,主要讲了一些理论,还有Apache Mahout的使用。因为我主要用Spark,所以可以先忽略。
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html
(完)
【转载】协同过滤 & Spark机器学习实战的更多相关文章
- 协同过滤 spark scala
1 http://www.cnblogs.com/charlesblc/p/6165201.html [转载]协同过滤 & Spark机器学习实战 2 基于Spark构建推荐引擎之一:基于物品 ...
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- 【Spark机器学习速成宝典】推荐引擎——协同过滤
目录 推荐模型的分类 ALS交替最小二乘算法:显式矩阵分解 Spark Python代码:显式矩阵分解 ALS交替最小二乘算法:隐式矩阵分解 Spark Python代码:隐式矩阵分解 推荐模型的分类 ...
- Spark机器学习(11):协同过滤算法
协同过滤(Collaborative Filtering,CF)算法是一种常用的推荐算法,它的思想就是找出相似的用户或产品,向用户推荐相似的物品,或者把物品推荐给相似的用户.怎样评价用户对商品的偏好? ...
- spark机器学习从0到1协同过滤算法 (九)
一.概念 协同过滤算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法. 基于用户的协同过滤算法和基于项目的协同过滤算法 1.1.以用户为基础(User-based)的协同过滤 用相似统 ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark入门实战系列--8.Spark MLlib(下)--机器学习库SparkMLlib实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .MLlib实例 1.1 聚类实例 1.1.1 算法说明 聚类(Cluster analys ...
- 协同过滤 CF & ALS 及在Spark上的实现
使用Spark进行ALS编程的例子可以看:http://www.cnblogs.com/charlesblc/p/6165201.html ALS:alternating least squares ...
随机推荐
- 佛祖保佑 永无BUG 永不修改
// // _oo0oo_ // o8888888o // 88" . "88 // (| -_- |) // 0\ = /0 // ___/`---'\___ // .' \\| ...
- JAVA的回忆
访问修饰符: 1.常用访问修饰符: public 共有的 private 私有的 protect 保护 public 所有人能用,私有的自己能用,protect一个包里. 2.自动修正快捷键 ctrl ...
- 集合中list、ArrayList、LinkedList、Vector的区别、Collection接口的共性方法以及数据结构的总结
List (链表|线性表) 特点: 接口,可存放重复元素,元素存取是有序的,允许在指定位置插入元素,并通过索引来访问元素 1.创建一个用指定可视行数初始化的新滚动列表.默认情况下,不允许进行多项选择. ...
- 加载UI
weak情况 1 2 3 4 @property (weak,nonatomic) UILabel *nameLabel; UILabel *nameLabel = [[UILabel alloc ...
- oracle重建控制文件
根据已有数据库创建新的控制文件#数据库必须是mounted或open状态 sql> alter database backup controlfile to trace; 可以使用以下快捷方式找 ...
- Scrum项目4.0
4.0----------------------------------------------- 1.准备看板. 形式参考图4. 2.任务认领,并把认领人标注在看板上的任务标签上. 先由个人主动领 ...
- 我去,徒弟半夜来电让写一个PHP短信验证(和群发)
感觉很纳闷啊,,..好几天几乎通宵了,今晚本来以为有个早觉睡,居然2点多才打电话来让帮忙... 记得前段时间还有博友问过同类的问题.... 名字我就隐藏掉了,呵呵,, 我在网上随便找了一个提供相应接口 ...
- struts2笔记4
1.自定义struts拦截器 应用场景:如果用户登陆后可以访问action中的所有方法,如果用户没有登陆不允许访问action中的方法,并且提示“你没有操作权限” 1)两个页面,一个用户登陆user. ...
- IE7 float:left失效的解决方法
<div id="a" style="width:500px"> <div id="b" style="widt ...
- 四、Salesforce Styles_1
1.静态变量的使用:<apex:stylesheet value="{!$Resource.TestStyles}"/>2.<apex:page><s ...