Hadoop
Hadoop应用场景
Hadoop是专为离线处理和大规模数据分析而设计的,它并不适合那种对几个记录随机读写的在线事务处理模式。
大数据存储:Hadoop最适合一次写入、多次读取的数据存储需求,如数据仓库。
大数据分析:数据密集型并行计算:数据量极大,但是计算相对简单的并行处理。如:大规模Web信息搜索、日志分析。
Hadoop相关术语
Hadoop:这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者,Doug Cutting解释Hadoop的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手。” The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.

Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。Hadoop在分布式存储和分布式计算中都采用了主/从架构。分布式存储系统被称为Hadoop分布式文件系统,简称HDFS。分布式计算使用了MapReduce。MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
1、存储
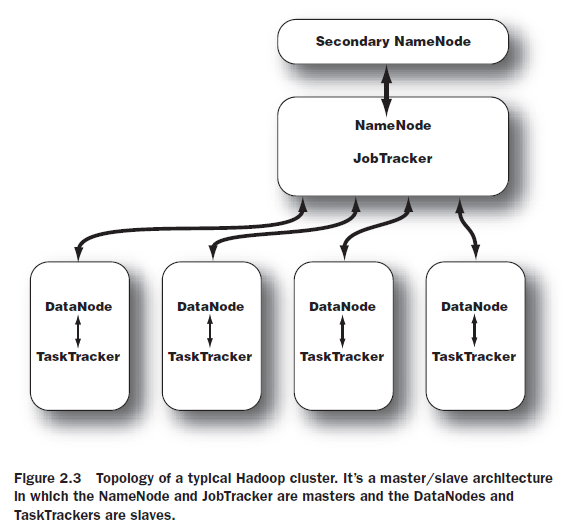
NameNode:名字节点。NameNode位于HDFS的主端,它指导从端的DataNode执行底层的I/O任务。NameNode是HDFS的书记员,它跟踪文件如何被分割成文件块,而这些文件块又被哪些节点存储,以及分布式文件系统的整体运行状态是否正常。
DataNode:数据节点。每一个集群的从节点都会驻留一个DataNode守护进程,来执行分布式文件系统的繁重工作-将HDFS数据块读取或者写入到本地文件系统的实际文件中。当希望对HDFS文件进行读写时,文件被分隔为多个块,由NameNode告知客户端每个数据块驻留在哪个DataNode。客户端直接与DataNode守护进程通信,来处理与数据块相对应的本地文件。而后,DataNode会与其他DataNode进行通信,复制这些数据块以实现备份。
Secondary NameNode:次名字节点。SNN是一个用于监测HDFS集群状态的辅助守护进程。SNN与NameNode通信,根据集群所配置的时间间隔获取HDFS元数据的快照。SNN的快照可以有助于减少停机的时间,并降低数据丢失的风险。

2、计算
与存储的守护进程一样,计算的守护进程也遵循主/从架构:JobTracker作为主节点,监测MapReduce作业的整个执行过程,同时,TaskTracher管理各个任务在每个从节点上的执行情况。
JobTracker:作业跟踪节点。JobTracker守护进程是应用程序和Hadoop之间的纽带。一旦提交代码到集群上,JobTracker就会确定执行计划,包括决定处理哪些文件、为不同的任务分配节点以及监控所有任务的运行。如果任务失败,JobTracker将自动重启任务,但所分配的节点可能会不同,同时受到预定义的重试次数限制。
TaskTracker:任务跟踪节点。每个TaskTracker负责执行由JobTracker分配的单项任务。虽然每个从节点上仅有一个TaskTracker,但每个TaskTracker可以生成多个JVM来并行地处理许多map或reduce任务。TaskTracker的一个职责是持续不断地与JobTracker通信。如果JobTracker在指定的时间内没有收到来自TaskTracker的“心跳”,它会假定TaskTracker已经崩溃了,进而重新提交相应的任务到集群中的其他节点中。

3、Hadoop集群
这是一个典型的Hadoop集群的拓扑图。这是一个主/从架构,其中NameNode和JobTracker为主端,DataNode和TaskTracker为从端。
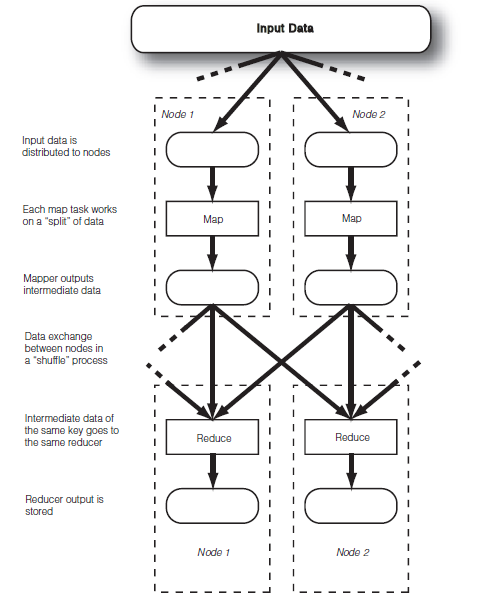
4、MapReduce数据流
map:映射。每个map任务处理一个数据分片,读取输入数据,输出中间数据。
shuffle:洗牌。节点间的数据交换在“洗牌”阶段完成。注意:输入数据被分配到不同节点之后,节点间通信的唯一时间是在“洗牌”阶段。这个通信约束对可扩展性有极大的帮助。
reduce:归约。读取mapper输出的中间数据,相同key的中间数据进入相同的reducer,最后保存数据到HDFS。
Hadoop的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 初识Hadoop、Hive
2016.10.13 20:28 很久没有写随笔了,自打小宝出生后就没有写过新的文章.数次来到博客园,想开始新的学习历程,总是被各种琐事中断.一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版 ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- 程序员必须要知道的Hadoop的一些事实
程序员必须要知道的Hadoop的一些事实.现如今,Apache Hadoop已经无人不知无人不晓.当年雅虎搜索工程师Doug Cutting开发出这个用以创建分布式计算机环境的开源软...... 1: ...
- Hadoop 2.x 生态系统及技术架构图
一.负责收集数据的工具:Sqoop(关系型数据导入Hadoop)Flume(日志数据导入Hadoop,支持数据源广泛)Kafka(支持数据源有限,但吞吐大) 二.负责存储数据的工具:HBaseMong ...
- Hadoop的安装与设置(1)
在Ubuntu下安装与设置Hadoop的主要过程. 1. 创建Hadoop用户 创建一个用户,用户名为hadoop,在home下创建该用户的主目录,就不详细介绍了. 2. 安装Java环境 下载Lin ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
随机推荐
- shell注释
sh里没有多行注释,只能每一行加一个#号.只能像这样: #-------------------------------------------- # 这是一个自动打ipa的脚本,基于webfrogs ...
- Taurus.MVC 2.2 开源发布:WebAPI 功能增强(请求跨域及Json转换)
背景: 1:有用户反馈了关于跨域请求的问题. 2:有用户反馈了参数获取的问题. 3:JsonHelper的增强. 在综合上面的条件下,有了2.2版本的更新,也因此写了此文. 开源地址: https:/ ...
- .NET Core系列 :3 、使用多个项目
通过前面的两篇文章,我们已经知道如何创建新的项目,如何生成并运行我们的应用程序,也知道(大致) project.json 文件中的内容是什么意思.但大多数项目往往也需要多个项目或引用的类库.我们要创建 ...
- MVVM模式和在WPF中的实现(二)数据绑定
MVVM模式解析和在WPF中的实现(二) 数据绑定 系列目录: MVVM模式解析和在WPF中的实现(一)MVVM模式简介 MVVM模式解析和在WPF中的实现(二)数据绑定 MVVM模式解析和在WPF中 ...
- windows下 安装 rabbitMQ 及操作常用命令
rabbitMQ是一个在AMQP协议标准基础上完整的,可服用的企业消息系统.它遵循Mozilla Public License开源协议,采用 Erlang 实现的工业级的消息队列(MQ)服务器,Rab ...
- Html.DropDownLis绑定数据库
效果: 方法一: View: <div class="col-md-md-4"> <div class="input-group"> & ...
- iOS开源项目周报1222
由OpenDigg 出品的iOS开源项目周报第二期来啦.我们的iOS开源周报集合了OpenDigg一周来新收录的优质的iOS开发方面的开源项目,方便iOS开发人员便捷的找到自己需要的项目工具等. io ...
- docker4dotnet #3 在macOS上使用Visual Studio Code和Docker开发asp.net core和mysql应用
.net猿遇到了小鲸鱼,觉得越来越兴奋.本来.net猿只是在透过家里那田子窗看外面的世界,但是看着海峡对岸的苹果园越来越茂盛,实在不想再去做一只宅猿了.于是,.net猿决定搭上小鲸鱼的渡轮到苹果园去看 ...
- ES6+ 现在就用系列(二):let 命令
系列目录 ES6+ 现在就用系列(一):为什么使用ES6+ ES6+ 现在就用系列(二):let 命令 ES6+ 现在就用系列(三):const 命令 ES6+ 现在就用系列(四):箭头函数 => ...
- C#将Word转换成PDF方法总结(基于Office和WPS两种方案)
有时候,我们需要在线上预览word文档,当然我们可以用NPOI抽出Word中的文字和表格,然后显示到网页上面,但是这样会丢失掉Word中原有的格式和图片.一个比较好的办法就是将word转换成pdf,然 ...