PageRank算法简介及Map-Reduce实现
PageRank对网页排名的算法,曾是Google发家致富的法宝。以前虽然有实验过,但理解还是不透彻,这几天又看了一下,这里总结一下PageRank算法的基本原理。
一、什么是pagerank
PageRank的Page可是认为是网页,表示网页排名,也可以认为是Larry Page(google 产品经理),因为他是这个算法的发明者之一,还是google CEO(^_^)。PageRank算法计算每一个网页的PageRank值,然后根据这个值的大小对网页的重要性进行排序。它的思想是模拟一个悠闲的上网者,上网者首先随机选择一个网页打开,然后在这个网页上呆了几分钟后,跳转到该网页所指向的链接,这样无所事事、漫无目的地在网页上跳来跳去,PageRank就是估计这个悠闲的上网者分布在各个网页上的概率。
二、最简单pagerank模型
互联网中的网页可以看出是一个有向图,其中网页是结点,如果网页A有链接到网页B,则存在一条有向边A->B,下面是一个简单的示例: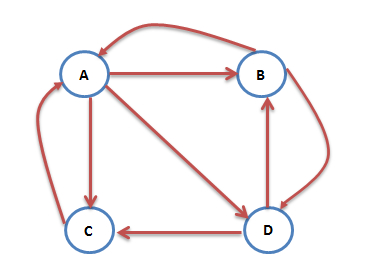
这个例子中只有四个网页,如果当前在A网页,那么悠闲的上网者将会各以1/3的概率跳转到B、C、D,这里的3表示A有3条出链,如果一个网页有k条出链,那么跳转任意一个出链上的概率是1/k,同理D到B、C的概率各为1/2,而B到C的概率为0。一般用转移矩阵表示上网者的跳转概率,如果用n表示网页的数目,则转移矩阵M是一个n*n的方阵;如果网页j有k个出链,那么对每一个出链指向的网页i,有M[i][j]=1/k,而其他网页的M[i][j]=0;上面示例图对应的转移矩阵如下:

初试时,假设上网者在每一个网页的概率都是相等的,即1/n,于是初试的概率分布就是一个所有值都为1/n的n维列向量V0,用V0去右乘转移矩阵M,就得到了第一步之后上网者的概率分布向量MV0,(nXn)*(nX1)依然得到一个nX1的矩阵。下面是V1的计算过程:

注意矩阵M中M[i][j]不为0表示用一个链接从j指向i,M的第一行乘以V0,表示累加所有网页到网页A的概率即得到9/24。得到了V1后,再用V1去右乘M得到V2,一直下去,最终V会收敛,即Vn=MV(n-1),上面的图示例,不断的迭代,最终V=[3/9,2/9,2/9,2/9]':

三、终止点问题
上述上网者的行为是一个马尔科夫过程的实例,要满足收敛性,需要具备一个条件:
- 图是强连通的,即从任意网页可以到达其他任意网页:
互联网上的网页不满足强连通的特性,因为有一些网页不指向任何网页,如果按照上面的计算,上网者到达这样的网页后便走投无路、四顾茫然,导致前面累计得到的转移概率被清零,这样下去,最终的得到的概率分布向量所有元素几乎都为0。假设我们把上面图中C到A的链接丢掉,C变成了一个终止点,得到下面这个图:
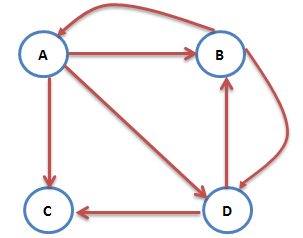
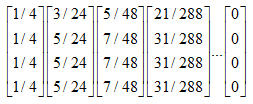
对应的转移矩阵为:

连续迭代下去,最终所有元素都为0:
四、陷阱问题
另外一个问题就是陷阱问题,即有些网页不存在指向其他网页的链接,但存在指向自己的链接。比如下面这个图:
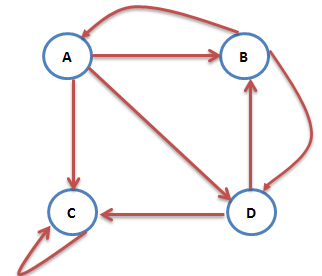

上网者跑到C网页后,就像跳进了陷阱,陷入了漩涡,再也不能从C中出来,将最终导致概率分布值全部转移到C上来,这使得其他网页的概率分布值为0,从而整个网页排名就失去了意义。如果按照上面图对应的转移矩阵为:

不断的迭代下去,就变成了这样:
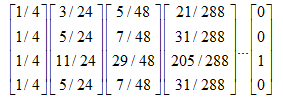
五、解决终止点问题和陷阱问题
上面过程,我们忽略了一个问题,那就是上网者是一个悠闲的上网者,而不是一个愚蠢的上网者,我们的上网者是聪明而悠闲,他悠闲,漫无目的,总是随机的选择网页,他聪明,在走到一个终结网页或者一个陷阱网页(比如两个示例中的C),不会傻傻的干着急,他会在浏览器的地址随机输入一个地址,当然这个地址可能又是原来的网页,但这里给了他一个逃离的机会,让他离开这万丈深渊。模拟聪明而又悠闲的上网者,对算法进行改进,每一步,上网者可能都不想看当前网页了,不看当前网页也就不会点击上面的连接,而上悄悄地在地址栏输入另外一个地址,而在地址栏输入而跳转到各个网页的概率是1/n。假设上网者每一步查看当前网页的概率为a,那么他从浏览器地址栏跳转的概率为(1-a),于是原来的迭代公式转化为:
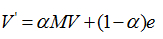
现在我们来计算带陷阱的网页图的概率分布:

重复迭代下去,得到:

可以看到C虽然占了很大一部分pagerank值,但其他网页页获得的一些值,因此C的链接结构,它的权重确实应该会大些。
六、用Map-reduce计算Page Rank
上面的演算过程,采用矩阵相乘,不断迭代,直到迭代前后概率分布向量的值变化不大,一般迭代到30次以上就收敛了。真的的web结构的转移矩阵非常大,目前的网页数量已经超过100亿,转移矩阵是100亿*100亿的矩阵,直接按矩阵乘法的计算方法不可行,需要借助Map-Reduce的计算方式来解决。实际上,google发明Map-Reduce最初就是为了分布式计算大规模网页的pagerank,Map-Reduce的pagerank有很多实现方式,我这里计算一种简单的。
考虑转移矩阵是一个很多的稀疏矩阵,我们可以用稀疏矩阵的形式表示,我们把web图中的每一个网页及其链出的网页作为一行,这样第四节中的web图结构用如下方式表示:
A B C D
B A D
C C
D B C
A有三条出链,分别指向B、C、D,实际上,我们爬取的网页结构数据就是这样的。
1、Map阶段
Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出<B,1/3*1/4>,<C,1/3*1/4>,<D,1/3*1/4>;
2、Reduce阶段
Reduce操作收集网页id相同的值,累加并按权重计算,pj=a*(p1+p2+...Pm)+(1-a)*1/n,其中m是指向网页j的网页j数,n所有网页数。
思路就是这么简单,但是实践的时候,怎样在Map阶段知道当前行网页的概率值,需要一个单独的文件专门保存上一轮的概率分布值,先进行一次排序,让出链行与概率值按网页id出现在同一Mapper里面,整个流程如下:
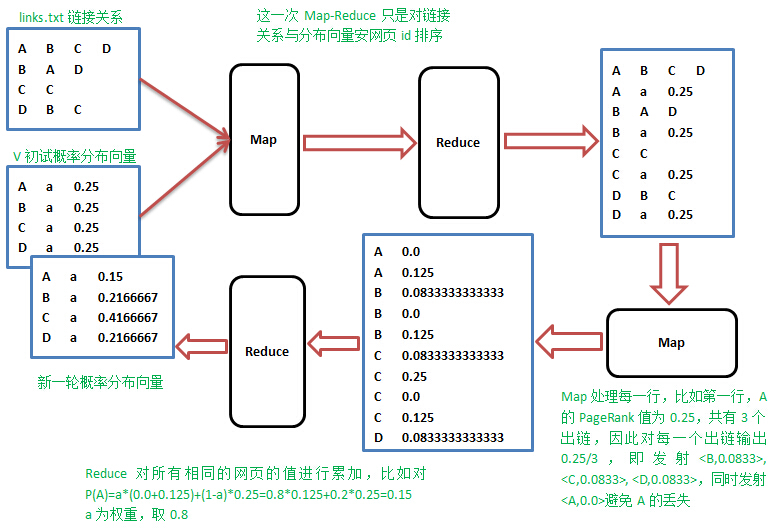
这样进行一次迭代相当于需要两次MapReduce,但第一次的MapReduce只是简单的排序,不需要任何操作,用python调用Hadoop的Streaming.
SortMappert.py代码如下:
#!/bin/python
'''Mapper for sort'''
import sys
for line in sys.stdin:
print line.strip()
SortReducer.py也是一样
#!/bin/python
'''Reducer for sort'''
import sys
for line in sys.stdin:
print line.strip()
PageRankMapper.py代码:
''' mapper of pangerank algorithm'''
import sys
id1 = id2 = None
heros = value = None
count1 = count2 = 0 for line in sys.stdin:
data = line.strip().split('\t')
if len(data) == 3 and data[1] == 'a':# This is the pangerank value
count1 += 1
if count1 >= 2:
print '%s\t%s' % (id1,0.0) id1 = data[0]
value = float(data[2])
else:#This the link relation
id2 = data[0]
heros = data[1:]
if id1 == id2 and id1:
v = value / len(heros)
for hero in heros:
print '%s\t%s' % (hero,v)
print '%s\t%s' % (id1,0.0)
id1 = id2 = None
count1 = 0
PageRankReducer.py代码:
''' reducer of pagerank algorithm'''
import sys
last = None
values = 0.0
alpha = 0.8
N = 4# Size of the web pages
for line in sys.stdin:
data = line.strip().split('\t')
hero,value = data[0],float(data[1])
if data[0] != last:
if last:
values = alpha * values + (1 - alpha) / N
print '%s\ta\t%s' % (last,values)
last = data[0]
values = value
else:
values += value #accumulate the page rank value
if last:
values = alpha * values + (1 - alpha) / N
print '%s\ta\t%s' % (last,values)
在linux下模仿Map-Reduce的过程:
#!/bin/bash
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games
export PATH
max=10
for i in `seq 1 $max`
do
echo "$i"
cat links.txt pangerank.value > tmp.txt
cat tmp.txt |sort|python PageRankMapper.py |sort|python PageRankReducer.py >pangerank.value
done
这个代码不用改动就可以直接在hadoop上跑起来。调用hadoop命令:
#!/bin/bash #sort
mapper=SortMapper.py
reducer=SortReducer.py
input="yours HDFS dir"/links.txt
input="yours HDFS dir"/pagerank.value
output="yours HDFS dir"/tmp.txt hadoop jar contrib/streaming/hadoop-*streaming*.jar \
-mapper /home/hduser/mapper.py \
-reducer /home/hduser/reducer.py -file *.py\
-input $input \
-output $output #Caculator PageRank
mapper=PageRankMapper.py
reducer=PageRankReducer.py
input="yours HDFS dir"/tmp.txt
output="yours HDFS dir"/pagerank.value hadoop jar contrib/streaming/hadoop-*streaming*.jar \
-mapper /home/hduser/mapper.py \
-reducer /home/hduser/reducer.py -file *.py\
-input $input \
-output $output
关于使用python操作hadoop可以查看参考文献。python代码写得浓浓的C味,望海涵!
第四步中带环的陷阱图,迭代40次,权值a取0.8,计算结果如下:
A B C D
0.15 0.216666666667 0.416666666667 0.216666666667
0.136666666666 0.176666666666 0.51 0.176666666666
0.120666666666 0.157111111111 0.565111111111 0.157111111111
0.112844444444 0.145022222222 0.597111111111 0.145022222222
0.108008888889 0.138100740741 0.615789629629 0.138100740741
0.105240296296 0.134042666667 0.62667437037 0.134042666667
0.103617066667 0.131681145679 0.633020641975 0.131681145679
0.102672458272 0.130303676049 0.636720189629 0.130303676049
0.10212147042 0.129500792625 0.638876944329 0.129500792625
0.10180031705 0.129032709162 0.640134264625 0.129032709162
0.101613083665 0.128759834878 0.640867246578 0.128759834878
0.101503933951 0.128600756262 0.641294553524 0.128600756262
0.101440302505 0.128508018225 0.641543661044 0.128508018225
0.10140320729 0.128453954625 0.64168888346 0.128453954625
0.10138158185 0.128422437127 0.641773543895 0.128422437127
0.101368974851 0.128404063344 0.64182289846 0.128404063344
0.101361625338 0.128393351965 0.641851670733 0.128393351965
0.101357340786 0.128387107543 0.641868444129 0.128387107543
0.101354843017 0.128383467227 0.64187822253 0.128383467227
0.101353386891 0.128381345029 0.641883923053 0.128381345029
0.101352538012 0.128380107849 0.641887246292 0.128380107849
0.10135204314 0.128379386609 0.641889183643 0.128379386609
0.101351754644 0.128378966148 0.641890313062 0.128378966148
0.101351586459 0.128378721031 0.641890971481 0.128378721031
0.101351488412 0.128378578135 0.64189135532 0.128378578135
0.101351431254 0.128378494831 0.641891579087 0.128378494831
0.101351397932 0.128378446267 0.641891709536 0.128378446267
0.101351378507 0.128378417955 0.641891785584 0.128378417955
0.101351367182 0.128378401451 0.641891829918 0.128378401451
0.10135136058 0.128378391829 0.641891855763 0.128378391829
0.101351356732 0.12837838622 0.64189187083 0.12837838622
0.101351354488 0.12837838295 0.641891879614 0.12837838295
0.10135135318 0.128378381043 0.641891884735 0.128378381043
0.101351352417 0.128378379932 0.64189188772 0.128378379932
0.101351351973 0.128378379284 0.64189188946 0.128378379284
0.101351351714 0.128378378906 0.641891890474 0.128378378906
0.101351351562 0.128378378686 0.641891891065 0.128378378686
0.101351351474 0.128378378558 0.64189189141 0.128378378558
0.101351351423 0.128378378483 0.641891891611 0.128378378483
0.101351351393 0.128378378439 0.641891891728 0.128378378439
可以看到pagerank值已经基本趋于稳定,并与第四步的分数表示一致。
2014.11.16注:上面写的map-reduce计算过程在多节点集群下有问题,在第二个map输入时,由于数据分片导致一部分结点的出链与pagerank值不在同一个块中,导致该结点对其他结点的贡献被忽略。单节点下不会出现这个问题。(感谢网友@桔子 的指正)。
PageRank的简介就介绍到这里了,如果想深入可以参考原论文或者下面的参考文献
参考文献
1.《Mining of Massive Datasets》
2.《An introduction to information retrival》
4.js可视化展示PageRank计算过程(可能需要梯子),可访问作者博客.
感谢阅读,转载请注明出处:http://www.cnblogs.com/fengfenggirl/
PageRank算法简介及Map-Reduce实现的更多相关文章
- PageRank 算法简介
有两篇文章一篇讲解(下面copy)< PageRank算法简介及Map-Reduce实现>来源:http://www.cnblogs.com/fengfenggirl/p/pagerank ...
- 谷歌pagerank算法简介
在这篇博客中我们讨论一下谷歌pagerank算法.这是参考的原博客连接:http://blog.jobbole.com/71431/ PageRank的Page可是认为是网页,表示网页排名,也可以认为 ...
- PageRank算法--从原理到实现
本文将介绍PageRank算法的相关内容,具体如下: 1.算法来源 2.算法原理 3.算法证明 4.PR值计算方法 4.1 幂迭代法 4.2 特征值法 4.3 代数法 5.算法实现 5.1 基于迭代法 ...
- MapReduce实现PageRank算法(稀疏图法)
前言 本文用Python编写代码,并通过hadoop streaming框架运行. 算法思想 下图是一个网络: 考虑转移矩阵是一个很多的稀疏矩阵,我们可以用稀疏矩阵的形式表示,我们把web图中的每一个 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:pagerank算法
实验目的 了解PageRank算法 学会用mapreduce解决实际的复杂计算问题 实验原理 1.pagerank算法简介 PageRank,即网页排名,又称网页级别.Google左侧排名或佩奇排名. ...
- Hadoop简介(1):什么是Map/Reduce
看这篇文章请出去跑两圈,然后泡一壶茶,边喝茶,边看,看完你就对hadoop整体有所了解了. Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Red ...
- 【转】Map/Reduce简介
转自:http://blog.csdn.net/opennaive/article/details/7514146 1. MapReduce是干啥的 因为没找到谷歌的示意图,所以我想借用一张Hadoo ...
- map reduce
作者:Coldwings链接:https://www.zhihu.com/question/29936822/answer/48586327来源:知乎著作权归作者所有,转载请联系作者获得授权. 简单的 ...
- Hadoop应用开发实战(flume应用开发、搜索引擎算法、Pipes、集群、PageRank算法)
Hadoop是2013年最热门的技术之一,通过北风网robby老师<深入浅出Hadoop实战开发>.<Hadoop应用开发实战>两套课程的学习,普通Java开发人员可以在最快的 ...
随机推荐
- #研发解决方案介绍#Recsys-Evaluate(推荐评测)
郑昀 基于刘金鑫文档 最后更新于2014/12/1 关键词:recsys.推荐评测.Evaluation of Recommender System.piwik.flume.kafka.storm.r ...
- input 默认值为灰色,输入时清楚默认值
input 默认值为灰色,输入时清楚默认值 <input value="please input your name" onFocus="if(value==def ...
- asp.net之treeview无法显示树结点图标(IP与域名的表现竟不一样)
背景 今天接到客户的电话,说部署上去的项目树型的treeview无法正常显示,显示成了好几个大红叉.如: 排查 于是我通过远程登录到服务器,在本地测试了一会发现没有这个问题存在,无论是通过IP ...
- 获取下拉框的value和值
jsp: <td class="formItem_content"> <select name="label" id = "labe ...
- php cli方式下获取服务器ip
(未整理....) (1)php cli方式下获取服务器ip [php] function getServerIp(){ $ss = exec('/sbin/ifconfig et ...
- android canvas d
(以下转自:http://blog.csdn.net/longyi_java/article/details/6930480) 1.基本的绘制图片方法 //Bitmap:图片对象,left:偏移左边的 ...
- MySQL Database on Azure
在国际版的Microsoft Azure上,MySQL服务是与ClearDB合作运营的.由于ClearDB无法在中国地区提供服务,因此微软中国的研发团队开发了专门面向中国市场的MySQL Databa ...
- MMORPG大型游戏设计与开发(客户端架构 part5 of vegine)
客户端异常捕获,是一件必然的事情,特别是在开发的时候就更需要这些有利于找出问题原因的捷径.区别于服务器的是,客户端基本上是以界面为主,你很难在正常运行程序的情况下进行一些输出的监视,如一些日志的记录. ...
- Android+Sqlite 实现古诗阅读应用(三)
往期传送门: Android+Sqlite 实现古诗阅读应用(一) Android+Sqlite 实现古诗阅读应用(二) 加入截图分享的功能. 很多应用都有分享的功能,我也想在我的古诗App里加入这个 ...
- POJ 1228 Grandpa's Estate --深入理解凸包
题意: 判断凸包是否稳定. 解法: 稳定凸包每条边上至少有三个点. 这题就在于求凸包的细节了,求凸包有两种算法: 1.基于水平序的Andrew算法 2.基于极角序的Graham算法 两种算法都有一个类 ...