python全栈开发中级班全程笔记(第二模块)第一部分:文件处理
第二模块
第一部分:文件处理与函数
#插曲之人丑就要多读书:读书能够提高个人素质与内涵,提升个人修养与能力,以及层次的提升。
推荐书籍:追风筝的人、白鹿原
电影:阿甘正传、辛德勒的名单
第一节:三元运算
定义:三元运算又称三目运算,是对简单条件的再次简写。

代码验证:
例:
>>> a = 3 #假设这是条件
>>> b = 7
>>> a,b
(3, 7) >>> val = a if a > b else b #val 先赋值 a ,判断条件不成立,就赋值 b
>>> val
7 #注意一行代码只能有一个变量, >>> val = a if a < b else b # 如果判断条件成立,就赋值 a
>>> val
3
#:语法大致意思是先 ( val = a ),再判断,如果成立,执行前面,否则,就是后面,( else b ) 否则,就是 b
#:注意这里有点绕,要把语法理解对 else 后面没有 等号 ( val = b ,简化成 else b )
第二节 : 文件处理
一、 读取文件(pycharm 操作)
pycharm 代码验证下
例:pycharm 写
f = open( file = "python高亮彩色字符实现方法",mode = "r" , encoding = "utf-8")
data = f.read() #读取文件
print(data)
f.close() #关闭文件 当然这种情况是读取文件和写 pycharm 的内存地址在一个文件路径中,不用填写文件路径
***第一行代码的意思就是,打开文件,以 r 读取模式,编码为 utf - 8 (如果不是utf-8 存的,会报错,需要以什么存,就以什么写)把这个操作过程赋变量名 f ,以方便后续操作。再把打开文件的步骤赋个变量名 便于后续操作,打印文件,再关闭文件
*#*#*#如果读取文件和 pycharm 编写程序的文件路径不在一个目录下,或者在其他盘,就要用到读写文件全部路径
f = open(file = "C:/Users/57098/Desktop/python字体颜色.txt",mode = "r",encoding ="gbk" ) #修改斜杠方向后的方法不用再路径前加 “r”
#注意这个文件路径的斜杠方向,斜杠在复制文件地址时,可以修改为反向斜杠,也可不修改
f = open(file = r"C:\Users\\57098\Desktop\python字体颜色.txt",mode = "r",encoding ="gbk" ) #不修改斜杠方向的写法
#这个不修改文件路径中斜杠的方向需要在读取文件路径前加一个 “r” 表示读取文件路径
data = f.read()
print(data)
f.close() #以上是可以在pycharm 上面正常实现的,注意用什么编码格式存储就要以什么代码格式读取,否则会出现乱码或者报错!
#*#*#* 以上就是读取本地文件的方法,注意后两种的斜杠方向与“ r ” 的关系
二 、 二进制模式(pycharm 操作)
例:pycharm写
# -*- coding:utf-8 -*-
f = open(file = "python高亮彩色字符实现方法",mode = "rb" ) #注意,二进制模式就是不定义编码格式,“rb” 代表读成二进制格式
data = f.read()
print(data)
f.close()
#就会把所有的字符以二进制打开,全部是二进制符号
*#*#什么情况下要这么打开呢? (1)在你不知道文件编码的格式。(2)具有一定的加密作用,比如:你们说好了这是某一个编码格式的文件,为了让别人不可读,网络传输加密,等对方收到了文件再进行解码处理。这样就很好的保护了文件。
三、智能检测文件编码的工具
以上2种代码的不同之处就是:1个是知道编码格式,通过编码格式读取;另一种是不知道编码格式只能 “ rb” 以二进制格式读取。
如果一个文件我们真的不知道是什么编码格式,虽然我们不知道是什么格式,但是二进制格式是有一定规律的,有一定的编码检测工具是可以推测判断的。
而有一个专门的模块工具,是专门检测二进制格式大概使用什么编码格式编写的。
这个工具属于第三方工具,需单独下载叫:chardet

**一个安装第三方工具箱的方法:pip 是一个安装第三方工具的语法,有很多作用,先不一一讲解,先说下 python 版本和 pip 有直接关系
如果是 python2 版本,就要写 pip2 ,如果是 python 3 版本,就要用 pip3
***代码验证
例:
C:\Users\57098>pip3 install chardet
Collecting chardet
Downloading https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca55ec7510b22e4c51f14098443b8
/chardet-3.0.4-py2.py3-none-any.whl (133kB)
100% |████████████████████████████████| 143kB 503kB/s
Installing collected packages: chardet
Successfully installed chardet-3.0.4
You are using pip version 9.0.3, however version 18.1 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.
#注意了,如果没安装过的,要在打开CMD指令中直接输入 pip3 install chardet 不能在进入 python 交互内输入,否则会报错,
安装好以后就需要调用,这个时候进去 python 交互器,调用安装过的第三方工具箱
例:
C:\Users\57098>python
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import chardet
>>> # 注意语法应用,import chardet
工具箱导入之后,就要应用工具箱,将不知道编码格式的文件从 python 中打开,进行判断编码格式的成功率,
例:
>>> f = open(r"C:\Users\57098\Desktop\python字体颜色.txt","rb") #注意路径前加"r"
>>> data = f.read() #变量赋值,以便于后期操作 >>> data
b\xb7\xd6\xb5\xc4\xc8\xfd\xb8\xf6\xb2 #发现已经变成二进制串,(为了看着清爽省略了一部分二进制串)
>>> >>> chardet.detect(data) #推测编码格式语法,把data传进括号内
{'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
#发现出现一个字典,里面的内容为推测结果,判断为GB2312的成功率在 99% ,语言为中文,证明就是GBK(GB2312)
这个时候就可以去里面进行验证,
>>> data.decode("gbk") #这是解码的语法
>>> data.decode("gb2312") #gbk 和 gb2312 两者都可以
'1.实现过程\r\n\r\n终端的字符颜色是用转义序列控制的,是文本模式下的系统显示功能,和具体的语言无关。控制字符颜色的转义序列是以ESC开头,
即用\\033来完成 \r\n\r\n \r\n2.书写过程\r\n开头部分: \\033[显示方式;前景色;背景色m\r\n结尾部分: \\033[0m\r\n \r\n
注意:\r\n开头部分的三个参数:显示方式,前景色,背景色是可选参数,可以只写其中的某一个;另外由于表示三个参数不同含义的数值都是唯一的没有重复的,
所以三个 参数的书写先后顺序没有固定要求,系统都能识别;但是,建议按照默认的格式规范书写。\r\n结尾部分其实也可以省略,但是为了书写规范,
建议\\033[***开头,\\033[0m结尾。 \r\n \r\n \r\n3.参数\r\n显示方式: 0(默认值)、1(高亮)、22(非粗体)、4(下划线)、24(非下划线)、
5( 闪烁)、25(非闪烁)、7(反显)、27(非反显)\r\n前景色: 30(黑色)、31(红色)、32(绿色)、 33(黄色)、34(蓝色)、35(洋 红)、
36(青色)、37(白色)\r\n背景色: 40(黑色)、41(红色)、42(绿色)、 43(黄色)、44(蓝色)、45(洋 红)、46(青色)、47(白色)
\r\n\r\n4.常见开头格式\r\n\\033[0m 默认字体正常显示,不高亮\r\n\\033[32;0m 红色字体正常显示
\r\n\\033[1;32;40m 显示 方式: 高亮 字体前景色:绿色 背景色:黑色
\r\n\\033[0;31;46m 显示方式: 正常 字体前景色:红色 背景色:青色
\r\n二、高亮输出实例\r\n s = "hello, world"\r\n # 默认字体输出:\r\n print(\'\\033[0m%s\\033[0m\' % s)\r\n
\r\n # 高亮显示:\r\n print(\'\\033[1;31;40m%s\\033[0m\' % s)\r\n print(\'\\033[1;32;40m%s\\033[0m\' % s)
\r\n print(\'\\033[1;33;40m%s\\033[0m\' % s)\r\n print(\'\\033[1;34;40m%s\\033[0m\' % s)
\r\n print(\'\\033[1;35;40m%s\\033[0m\' % s)\r\n print(\'\\033[1;36;40m%s\\033[0m\' % s)'
>>> #解码成功
#*#*以上就是 chcardet detect 智能解码的用法,
四、写模式操作文件
1、前面学的读文件,都是一下子读出所有文件,但是如果文件巨大,占据内存太多影响运行速度,就不好了。
有没有方法让我们能够把巨大的文件读一点处理一点(这样不占用系统内存)直到把整个文件处理完,
这就涉及到循环,就是从头到尾,循环把文件读完,
循环的语法:
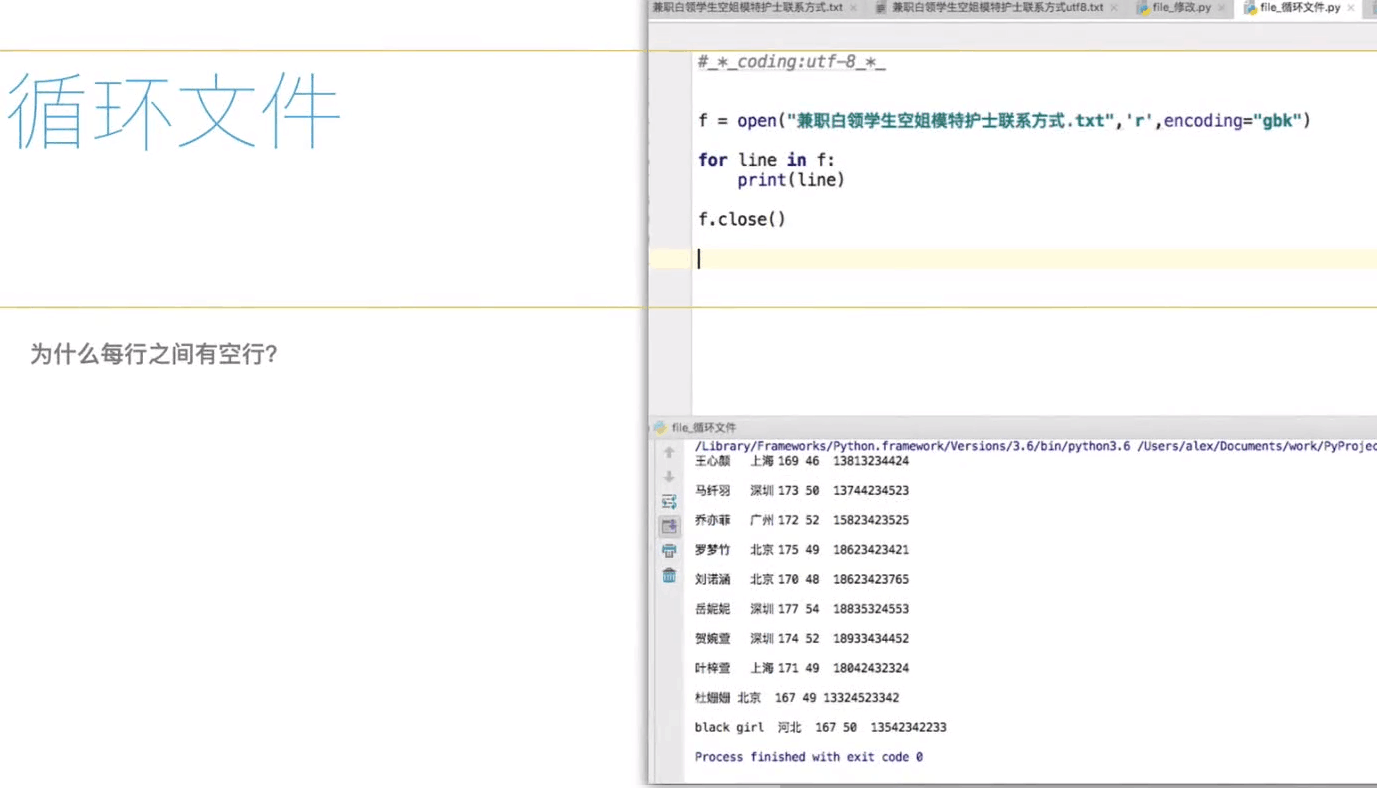
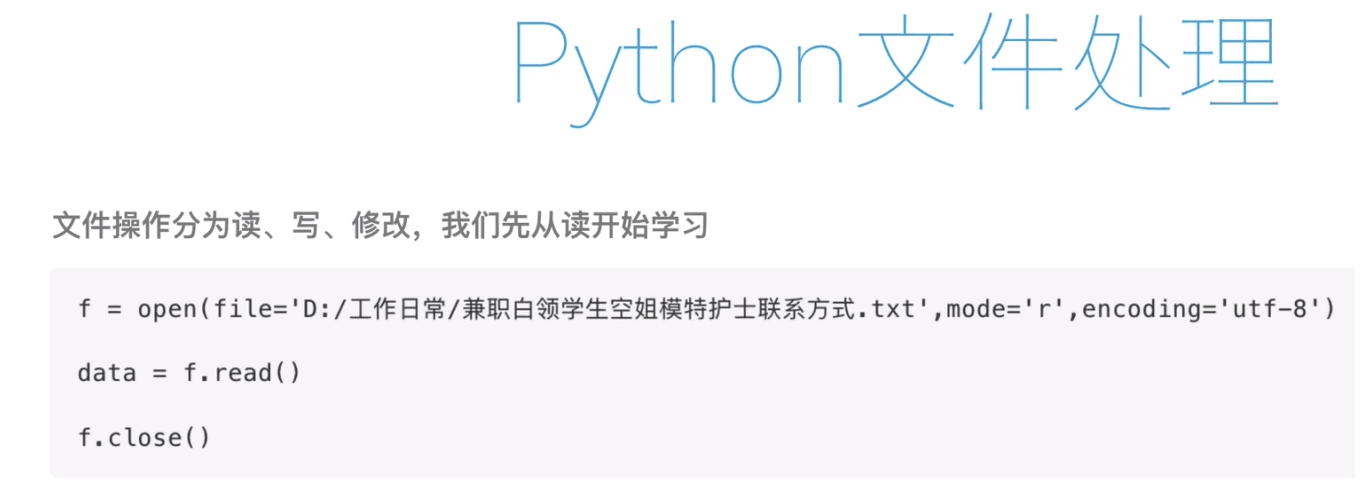
直接 open 这个文件,进行 for 循环 。line 代表每行
下面(pycharm)代码验证下
例;
f = open(file = "C:/Users/57098/Desktop/python字体颜色.txt",mode = "r",encoding ="gbk" )
for line in f :
print(line) f.close() #注意每执行完文件操作都会 f.close() 操作 执行后的代码:
1.实现过程 终端的字符颜色是用转义序列控制的,是文本模式下的系统显示功能,和具体的语言无关。控制字符颜色的转义序列是以ESC开头,即用\033来完成 2.书写过程 开头部分: \033[显示方式;前景色;背景色m 结尾部分: \033[0m # 发现每个间隔都有换空行
那么,为什么有换空行的现象呢,我们来代码看下。
例:
>>> f = open(r"C:\Users\57098\Desktop\python字体颜色.txt","r",encoding = 'gbk')
>>> a = f.read()
>>> a
'1.实现过程\n终端的字符颜色是用转义序列控制的,是文本模式下的系统显示功能,和具体的语言无关。
\n控制字符颜色的转义序列是以ESC开头,即用\\033来完成 \n2.书写过程\n开头部分: \\033[显示方式;前景色;背景色m\n结尾部分: \\033[0m
\n注意:\n开头部分的三个参数:显示方式,前景色,背景色是可选参数,可以只写其中的某一个;
\n另外由于表示三个参数不同含义的数值都是唯一的没有重复的,\n所以三个参数的书写先后顺序没有固 定要求,系统都能识别;但是,建议按照默认的格式规范书写。
\n结尾部分其实也可以省略,但是为了书写规范,建议\\033[***开头,\\033[0m结尾。
\n3.参数\n显示方式: 0(默认值)、1(高亮)、22(非粗体)、4(下划线)、24(非下划线)、 5(闪烁)、25(非闪烁)、
\n7(反显)、27(非反显)\n前景色: 30(黑色)、31(红色)、32(绿色)、 33(黄色)、34(蓝色)、35(洋 红)、36(青色)、37(白色)
\n背景色: 40(黑色) 、41(红色)、42(绿色)、 43(黄色)、44(蓝色)、45(洋 红)、46(青色)、47(白色)\n'
>>>
#可以看到,每隔一段文字,中间都有 \n (换行符),与 for 循环的 print(自动换行) 本身存在的换行符加一起,就会导致换空行
2、写文件 -- 创建模式操作( pycharm 创建文件)
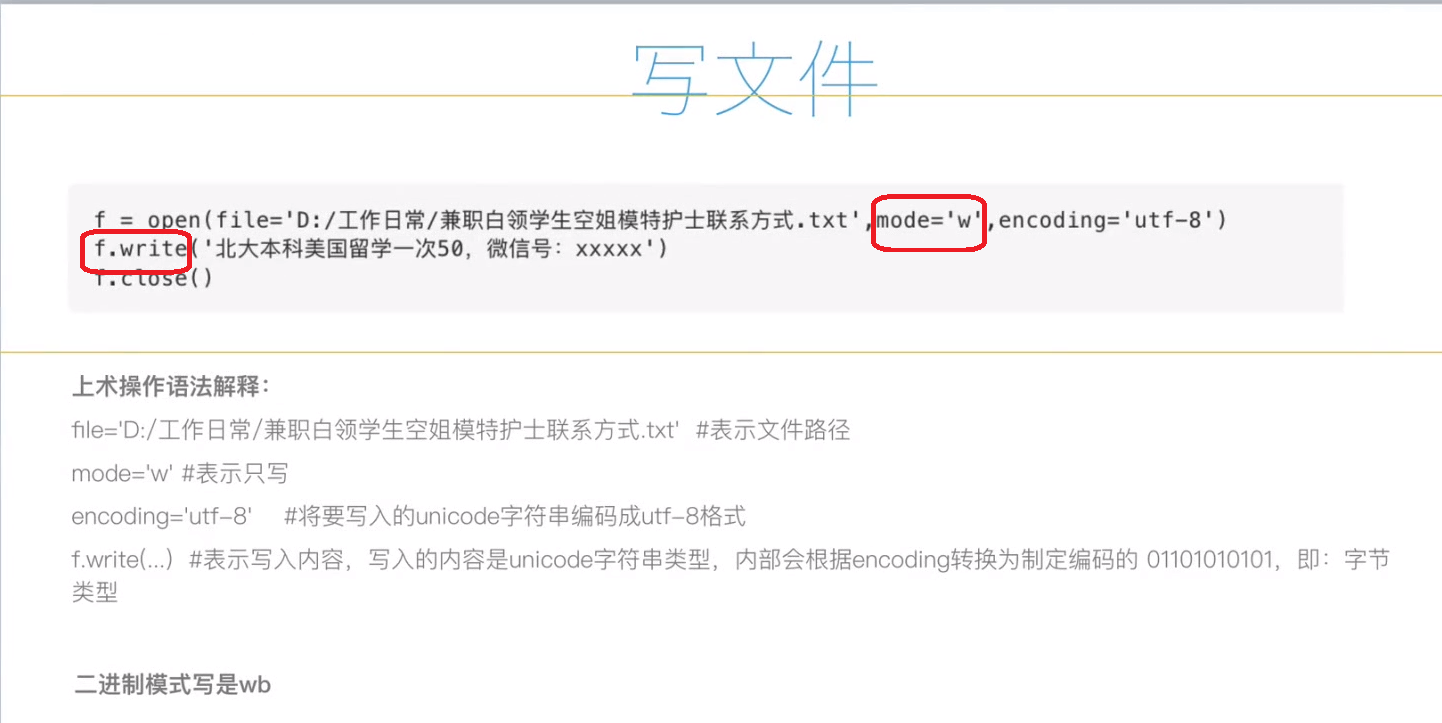
- **写文件和读文件差不多,就是模式不一样,
- 读取文件用 “r” ,下边是 f.read(),
- 写文件用 “w”,下边是 f.write (要写的内容 . encoding = "写文件编码(gbk、utf-8....)")
- 写文件涉及到转码,python3 默认编码 utf - 8 ,如果用 GBK 保存,读的时候就要 decoding = “utf-8”,转换下
如图
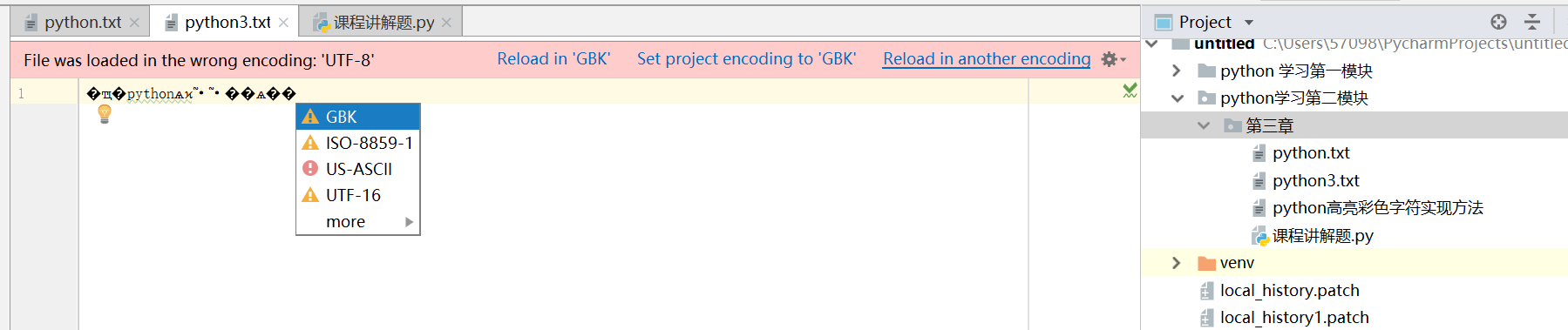
- 发现文件已经自动创建,但是乱码了,pycharm 会有提示,点击提示的地方会显示要转的编码格式。
- 再点击 GBK 可以转成 GBK 格式,然后会有提示,点击 (convert)就会转码成功。
- 注意:转码不要乱转,有可能导致丢失,转不回来,面临重新编写,比较麻烦。
下面代码验证下:
例:
f = open("python3.txt","w",encode = "gbk") #语法很简单 f.write("我的python学习之路之路飞学诚") #(要写的内容)
f.close()
也可写二进制模式:
例:
f = open("python3.txt","wb") #二进制模式就是把 encoding 去掉 'w' 换成“wb”(读“rb” ,写“wb”)代表某格式的二进制模式。
f.write("我的python学习之路之路飞学诚".encode("gbk"))#需要把encoding换成 encode(要读的编码,不写默认编码utf-8),加到写的内容后面
f.close()
**以上是每写一个文件都要创建一个新的 txt 文件,那能不能在原来的文件里直接写呢
下面代码验证下:
例:
f = open("python3.txt","w",encoding = "utf-8") #这次我把编码设置成utf-8(不用转码) f.write("人生苦短,我学python,珍惜时光,python最好") #直接改掉之前写进去的内容
f.close() 执行之后的结果 人生苦短,我学python,珍惜时光,python最好 #发现之前写进去的内容已经被覆盖掉。
注意了,w 属于创建模式,如果重复在一个文件,或者说在同一个路径下的相同文件里用 w 写入内容,它只会保留最后的写入,把之前的清空。所以在用 w 的时候要注意了,w 属于创建文件,如果以后写入更多的内容,一定不能在一个文件里重复使用,否则会前功尽弃,要慎重。
五、写文件 -- 追加文件(pycharm 操作)
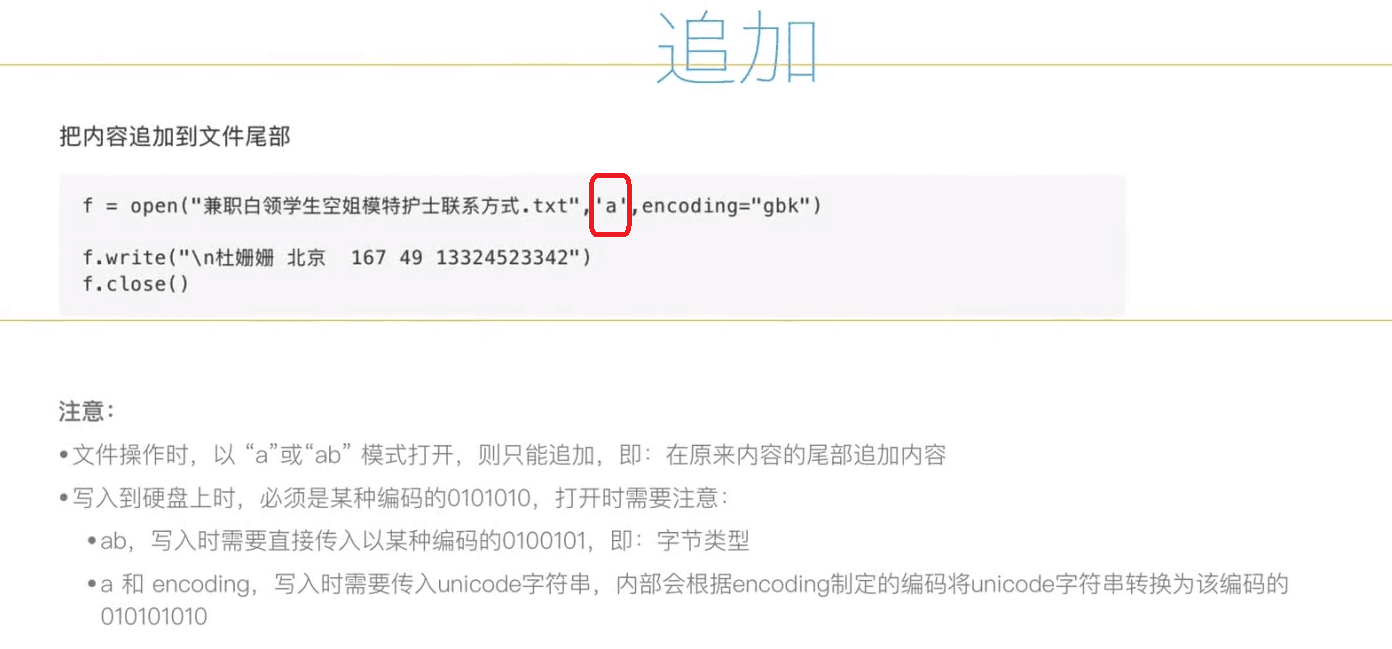
追加文件和创建文件差不多,只不过把模式 w 改成了 a (可以理解为 append 的简写)
下面代码验证下:
例:
f = open(file="python3.txt",mode = "ab" ) #只修改模式 “a 或者 ab”都可以
f.write("\n青春焕彩的年纪".encode("utf-8")) #一定加上换行符(\n) 否则不会换行,会在原本基础上直接加在后面
#注意:写入的编码格式必须和以前一样,否则会出现乱码。
f.close() 执行之后的效果: 人生苦短,我学python,珍惜时光,python最好
人生苦短,我学python,珍惜时光,python最好
我的python学习之路,hello world
青春焕彩的年纪 #发现已经换行追加
六、文件操作 -- 混合操作文件
上面已经学会了读文件,创建写入和追加 ,
有没有一种模式 既能读 ,同时又能写呢,这种模式就叫读写混合模式(能看也能写)

这种模式很简单,就是把模式改成 r+ 就叫读写模式,其他的都一样。(常用到)
w+ 为写读模式,就是把之前的覆盖掉再把重新写进去的给你读,其他的都一样。(不怎么用)
r+ 模式代码验证下:
例:
f = open(file="python3.txt",mode = "r+",encoding = "utf-8" ) #把模式改成 r+
data = f.read() #读文件操作
print(data) #打印文件
f.write("\n家乡-赵雷") #写入文件(可重复执行操作,每重复执行一次,写进去一次新的内容)
f.write("\n我们的时光-赵雷") #也可以一次写入多行
f.write("\n阿刁-赵雷")
f.write("\n吉姆餐厅-赵雷")
f.close() #关闭文件 执行后的效果: 人生苦短,我学python,珍惜时光,python最好
我的python学习之路,hello world
青春焕彩的年纪
青春已过,不再年轻,珍惜
青春已过,不再年轻,珍惜
我们的时光
快乐的时光, #可重复执行,只更改写入内容就可以了
家乡-赵雷
我们的时光-赵雷
阿刁-赵雷 #也可一次写入多行
吉姆餐厅-赵雷
w+ 模式代码验证:
例:
f = open(file="python3.txt",mode = "w+",encoding = "utf-8" ) #修改成写读模式(先写再读)
data = f.read()
print(data)
f.write("\n家乡-赵雷")
f.write("\n我们的时光-赵雷") #其他不变
f.write("\n阿刁-赵雷")
f.write("\n吉姆餐厅-赵雷")
f.close() 执行后的文件内容:
家乡-赵雷
我们的时光-赵雷 #发现只有新增加的内容,其他内容已经被清空,
阿刁-赵雷
吉姆餐厅-赵雷 #写读模式,不建议用,因为以后涉及的文件内容很多的情况下有可能导致源文件丢失
以上就是读写文件的方法,写读文件不建议用,因为可能导致文件丢失,尽量慎重使用或者远离
七、文件操作的其他功能
读写、追加、混合模式都讲了,还有几个模式,来了解下。

* fileno()返回文件句柄在内核中的索引值,学网络编程的时候,做 IO 多路复用时可以用到(就是返回一个数字)(先不学)
** flush()把文件从内存 buffer (缓存)里,强制刷新到硬盘。(普通的操作也可以保存文件,但需要在执行关闭文件这一步之后才会保存,否则会丢失,如果直接保存在硬盘,会影响读写速度。如果数据很重要,而且怕断电关机等意外情况,就需要用到这个)
代码验证下:
例:
>>> f =open(r"C:\Users\57098\Desktop\python写文件.txt",'w')
>>> f.write("\nasdfg1455221587772")
19 #返回写入字节长度
>>> f.flush() #强制刷新硬盘 执行结果: asdfg1455221587772 #文件存在了硬盘
*** readable() 判断是否可读文件。
例:
>>> f =open(r"C:\Users\57098\Desktop\python写文件.txt",'w')
>>> f.write("\nasdfg1455221587772")
19
>>> f.flush() #这是一个文件
>>> f.readable() #判断文件是否可读
False #返回错误就是不可读
#*注意了,open 文件的时候模式设置成 w 的,也属于不可读文件。
**** readline() 只读一行,遇到 \r 或 \n 为止。
例:
>>> f = open(r"C:\Users\57098\Desktop\python字体颜色.txt","r",encoding = "gbk")
>>> f.readline() #按每行读取文件
'1.实现过程\n' #已经实现
>>>
>>> f.readline() #如果要读取下一行,需重复上次操作。
'终端的字符颜色是用转义序列控制的\n' #一样会读取下一行
>>> f.readline()
'控制字符颜色的转义序列是以ESC开头 \n' #重复为之....
>>> f.readline()
***** seek () 把文件光标移到指定位置(读的字节)。
****** tell () 返回当前操作的光标位置(读的字节)。
******read()读取当前文件(读字符)
以上 2 个组合使用,下面我们验证下:
例:
>>> f =open(r"C:\Users\57098\Desktop\python写文件.txt",'r',encoding = "gbk")
>>> f.seek(4) #把光标移到2的位置 以字节读取
4
>>> f.read()
'男孩的路飞学城' #发现从光标4的位置开始读文件(\n和老)前4个字节
>>>f.tell() #返回光标位置
18
>>> f.read() #读取验证
'' #发现字符已经读完
>>> f.read(5) #read()是以字符读取文件的
'男孩的路飞' #发现是以前 5 个字符后读取的
以上规则(按字节、按字符)要记住,否则会出现很多问题
*******seekable () 判断文件是否可以 seek(这个知道就行了,基本用不到)
********writable()(判断文件呢是否可写)和 readable()(判断文件是否可读)差不多,都属于判断
最后一个 truncate()按当前长度或者指定长度截断文件(这种操作需要在 文件模式 r+ 下操作)
>>> f = open(r"C:\Users\57098\Desktop\python写文件.txt",'r+')
>>> f.read()
'老男孩的路飞学城'
>>> f.truncate(8) #从字节8的位置截断
8
>>> f.seek(0) #把光标移到 0
0
>>> f.read() #读取发现只剩下前 8 个字节了(gbk一个字符 = 2个字节)
'老男孩的'
>>> f.truncate() #()内不填值,会返回共多少个字节并从头截断(跟清空差不多)
8
>>> f.read()
'' #读取文件发现已经没有了(被截断完)
八、文件操作--文件修改*********重点**************

下面我们跟着方法来一段代码
例:
>>> f = open(r"C:\Users\57098\Desktop\python写文件.txt",'r+')
>>> f.read() #打开文件读取
'老男孩的路飞学城' #正常显示
>>> f.seek(4) #把光标移到第 4 个字节
4
>>> f.write("[路飞学城 lf]") #插入这段文字
9 #返回插入字节
>>> f.close() #关闭文件
>>> f = open(r"C:\Users\57098\Desktop\python写文件.txt",'r+')
>>> f.read() #再次打开文件
'老男[路飞学城]城' #发现把之前同样长度的字符覆盖了
注意了:这里涉及到硬盘存储原理,文件创建的时候,内存就把文件的位置固定了,你在里面插入其他的字符,会把之前的存储空间清理掉给新插入的字符用,导致被覆盖,没有插入,这是硬盘的存储原理导致的,无法改变,那么怎么才能修改成功呢,下面我们用代码实它。(占内存方法:重新创建新文件,把原更改的和不用更改的一起写进新文件,并更改文件名)
例:
import os # import 调用工具箱,os 是一个重命名的工具(原文件,替换后的文件)格式
f_name = "python3.txt" # 先给原文件赋值,便于操作
f_new = "%s.new"%f_name # 创建新文件并赋值,便于操作 old_str = "我的家乡,越来越年轻" #原文件中需要替换修改的赋值
new_str = "就像一件俗气的衣裳" #替换原文件内容赋值 name_str = "我们的时光,是快乐的时光" #原文件替换位置赋值
f_str = "岁月的年月,不会被现实改写" #替换原文件位置赋值 f = open(f_name,'r',encoding = "utf-8") #打开原文件赋值
f_n = open(f_new,'w',encoding = "utf-8") #创建新文件赋值
for line in f : # for 循环
if old_str in line : #判断需要修改的是否在原文件内
line = line.replace(old_str,new_str) #如果在,就替换掉
elif name_str in line:
line = line.replace(name_str,f_str)
f_n.write(line) #写入新文件
f.close() # 关闭 (文件操作规则,除了)
f_n.close()
os.rename(f_new,f_name) # linx 系统修改格式(苹果笔记本)
os.replace(f_name,f_new) #Windows系统修改格式 执行后效果: 文件名已经被命名为: python3.txt.new 家乡-赵雷
我们的时光-赵雷
阿刁-赵雷
吉姆餐厅-赵雷
就像一件俗气的衣裳
岁月的年月,不会被现实改写 #文件内容也已经被修改过
阿刁,大昭寺门前铺满阳光
吉姆餐厅,米尔大哥在忙着
画 - 赵雷
画一群鸟儿陪着我,在画上绿林和青坡
注意:代码中涉及到调用工具箱指令和调用工具,要写在编码的 首行 或文件头声明编码下面 便于代码操作
**以上是占内存的方法。
***下面我们实现不占内存的方法
例:
# 自己写占内存的更换方法
#任务是吧文件中的赵雷替换成我自己
f = open(file = r"python3.txt",mode = "r+",encoding = "utf-8")
data = f.read()
f.truncate()
a = "赵雷"
b = "毅龙"
f.seek(0)
f.write(data.replace(a,b))
f.close() 执行后: 家乡 -- 毅龙
吉姆餐厅 -- 毅龙
阿刁 -- 毅龙
成都 -- 毅龙
玛丽 -- 毅龙
鼓楼 -- 毅龙
朵 -- 毅龙
画 -- 毅龙
无法长大 -- 毅龙
——————————————————————第一部分结束线————————————————————————
python全栈开发中级班全程笔记(第二模块)第一部分:文件处理的更多相关文章
- python全栈开发中级班全程笔记(第二模块、第三章)(员工信息增删改查作业讲解)
python全栈开发中级班全程笔记 第三章:员工信息增删改查作业代码 作业要求: 员工增删改查表用代码实现一个简单的员工信息增删改查表需求: 1.支持模糊查询,(1.find name ,age fo ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- python全栈开发中级班全程笔记(第二模块、第四章(三、re 正则表达式))
python全栈开发笔记第二模块 第四章 :常用模块(第三部分) 一.正则表达式的作用与方法 正则表达式是什么呢?一个问题带来正则表达式的重要性和作用 有一个需求 : 从文件中读取所有联 ...
- python全栈开发中级班全程笔记(第二模块)第 二 部分:函数基础(重点)
python学习笔记第二模块 第二部分 : 函数(重点) 一.函数的作用.定义 以及语法 1.函数的作用 2.函数的语法和定义 函数:来源于数学,但是在编程中,函数这个概念 ...
- python 全栈开发,Day29(昨日作业讲解,模块搜索路径,编译python文件,包以及包的import和from,软件开发规范)
一.昨日作业讲解 先来回顾一下昨日的内容 1.os模块 和操作系统交互 工作目录 文件夹 文件 操作系统命令 路径相关的 2.模块 最本质的区别 import会创建一个专属于模块的名字, 所有导入模块 ...
- python全栈开发从入门到放弃之模块和包
一 模块 1 什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编 ...
- python全栈开发day16-正则表达式和re模块
1.昨日内容回顾 2.正则表达式(re模块是python中和正则表达式相关的模块) 1.作用 1).输入字符串是否符合匹配条件 2).从大段文字中匹配出符合条件的内容 2.字符组 [0-9a-zA-Z ...
- python全栈开发 * 进程池,线程理论 ,threading模块 * 180727
一.进程池 (同步 异步 返回值) 缺点: 开启进程慢 几个CPU就能同时运行几个程序 进程的个数不是无线开启的 应用: 100个任务 进程池 如果必须用多个进程 且是高计算型 没有IO型的程序 希望 ...
- 老男孩Python全栈第2期+课件笔记【高清完整92天整套视频教程】
点击了解更多Python课程>>> 老男孩Python全栈第2期+课件笔记[高清完整92天整套视频教程] 课程目录 ├─day01-python 全栈开发-基础篇 │ 01 pyth ...
随机推荐
- 荣耀7.0系统手机最简单激活Xposed框架的步骤
对于喜欢玩手机的小伙伴来说,很多时候会使用到Xposed框架及各类功能彪悍的模块,对于5.0以下的系统版本,只要手机能获得Root权限,安装和激活Xposed框架是比较简便的,但随着系统版本的不断更新 ...
- STL源码剖析-vector
STL(Standard Template Library) C++标准模板库,acm选手一定对它不陌生,除了算法,那几乎是“吃饭的家伙了”.我们使用库函数非常方便,且非常高效(相对于自己实现来说). ...
- Python 经典面试题汇总之网络篇
网络篇 1.简述 OSI 七层协议 物理层:定义物理设备标准,如网线的接口类型.光纤的接口类型.各种传输介质. 数据链路层:定义如何传输格式化数据,以及如何访问物理介质. 网络层:定义逻辑网络地址. ...
- C#零基础入门-3-第一个控制台程序
打开VS2017 文件 新建 项目 模板选择Visual C# Windows 控制台应用程序 快速写入Console.WriteLine 输入cw,然后快速按tab键两次即可.
- Navicat for MySQL破解版安装
https://pan.baidu.com/s/1OfFPvqrTqbUAC_Eqq2i0KA 提取码:jgep 点击第一个应用程序一路安装即可. 安装成功之后,再点击第二个应用程序PatchNavi ...
- 解析SQL Server之任务调度
在前面两篇文章中( 浅谈SQL Server内部运行机制 and 浅谈SQL Server数据内部表现形式 ),我们交流了一些关于SQL Server的一些术语,SQL Sever引擎 与SSMS抽象 ...
- Java:全局变量(成员变量)与局部变量
分类细则: 变量按作用范围划分分为全局变量(成员变量)和局部变量 成员变量按调用方式划分分为实例属性与类属性 (有关实例属性与类属性的介绍见另一博文https://blog.csdn.net/Drag ...
- 最新版jQuery v3.3.1的BUG以及解决办法(什么问题不重要,怎么解决问题才重要)
发现问题 最新版的 FineUIPro v5.2.0 中,我们将内置的 jQuery v1.12.4 升级到 jQuery v3.3.1 ,可以看升级记录: +升级到jQuery v3.3.1. ...
- postman Installation has failed: There was an error while installing the application. Check the setup log for more information and contact the author
Error msg: Installation has failed: There was an error while installing the application. Check the s ...
- Docker部署脚本
实现 1.检查内核版本 2.检查docker是否已安装 3.安装docker,如因网络等原因失败循环安装至安装完成 #!/bin/bash #file:docker_install.sh #From: ...