Python之jieba库的使用
jieba库,它是Python中一个重要的第三方中文分词函数库。
1.jieba的下载
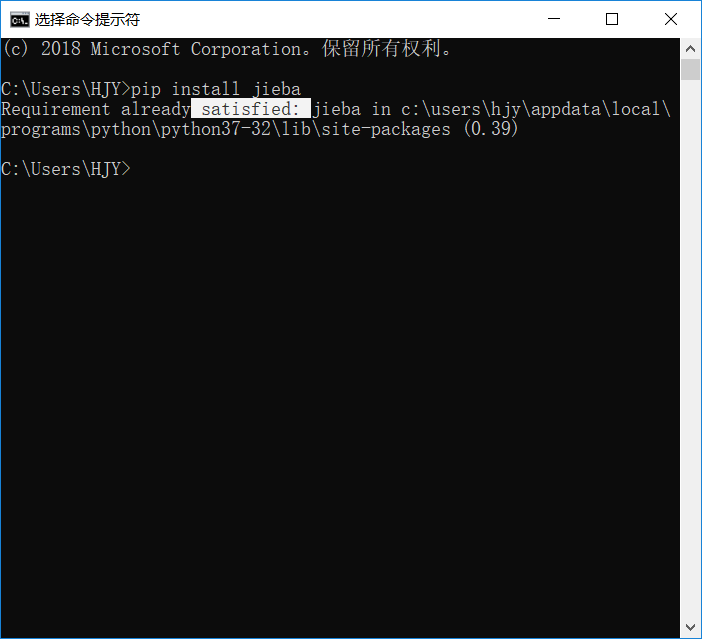
由于jieba是一个第三方函数库,所以需要另外下载。电脑搜索“cmd”打开“命令提示符”,然后输入“pip install jieba”,稍微等等就下载成功。
(注:可能有些pip版本低,不能下载jieba库,需要手动升级pip至19.0.3的版本,在安装jieba库)
当你再次输入“pip install jieba”,显示如图,jieba库就下载成功。
2.jieba库的3种分词模式
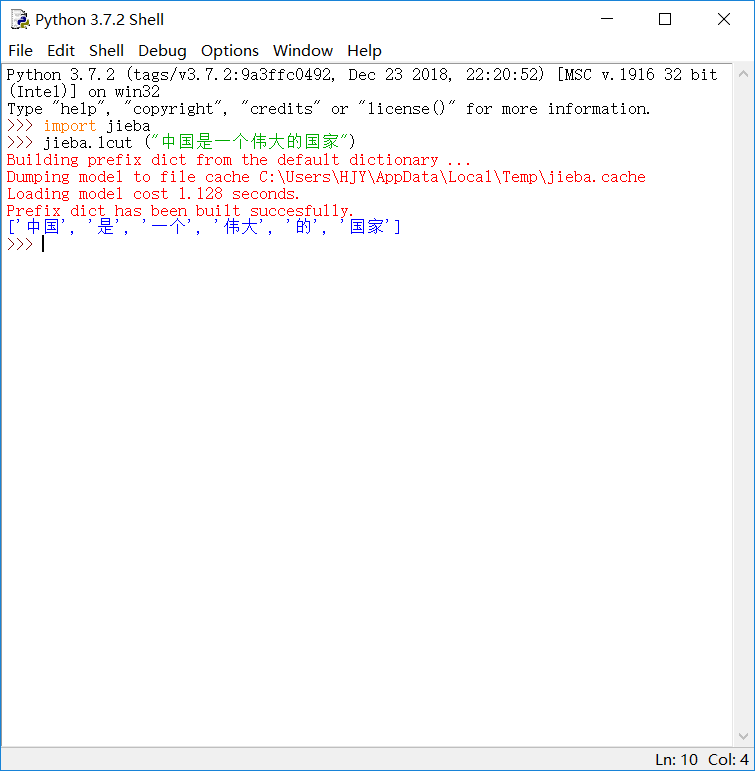
精确模式:将句子最精确地切开,适合文本分析。
例:
全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能消除歧义。
例:(“国是”,黑人问号)

搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
例:(没什么不同,可能我还没发现它的用处)

3.jieba应用
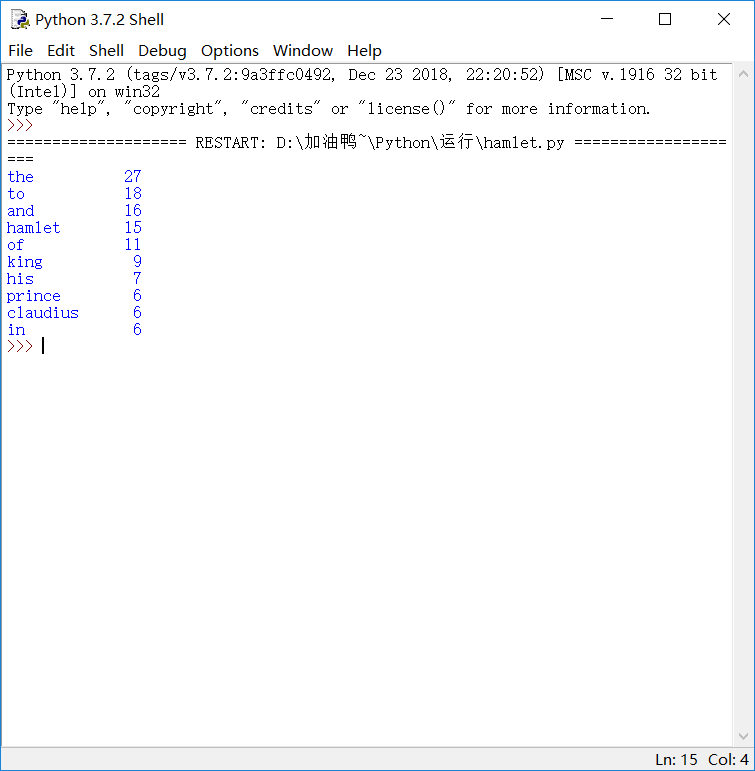
我选取了哈姆雷特(https://en.wikipedia.org/wiki/Hamlet#Act_I)的一小片段,txt形式存放在我的一个文件夹里,对它进行分词,输入代码:
def get_text():
txt = open("D://加油鸭~//hamlet.txt", "r",encoding='UTF-8').read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ") # 将文本中特殊字符替换为空格
return txt hamletTxt = get_text() # 打开并读取文件
words = hamletTxt.split() # 对字符串进行分割,获得单词列表
counts = {} for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1 # 分词计算 items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word,count))
得到结果,如图:
最后,我们还可以做词云图,这个呢我下次再给大家分享吧,再见~
Python之jieba库的使用的更多相关文章
- python之jieba库
jieba “结巴”中文分词:做最好的 Python 中文分词组件 "Jieba" (Chinese for "to stutter") Chinese tex ...
- python 学习jieba库遇到的问题及解决方法
昨天在课堂上学习了jieba库,跟着老师写了同样的代码时却遇到了问题: jieba分词报错AttributeError: module 'jieba' has no attribute 'cut' 文 ...
- python 利用jieba库词频统计
1 #统计<三国志>里人物的出现次数 2 3 import jieba 4 text = open('threekingdoms.txt','r',encoding='utf-8').re ...
- python实例:利用jieba库,分析统计金庸名著《倚天屠龙记》中人物名出现次数并排序
本实例主要用到python的jieba库 首先当然是安装pip install jieba 这里比较关键的是如下几个步骤: 加载文本,分析文本 txt=open("C:\\Users\\Be ...
- python第三方库------jieba库(中文分词)
jieba“结巴”中文分词:做最好的 Python 中文分词组件 github:https://github.com/fxsjy/jieba 特点支持三种分词模式: 精确模式,试图将句子最精确地切开, ...
- python jieba库的基本使用
第一步:先安装jieba库 输入命令:pip install jieba jieba库常用函数: jieba库分词的三种模式: 1.精准模式:把文本精准地分开,不存在冗余 2.全模式:把文中所有可能的 ...
- python 读写txt文件并用jieba库进行中文分词
python用来批量处理一些数据的第一步吧. 对于我这样的的萌新.这是第一步. #encoding=utf-8 file='test.txt' fn=open(file,"r") ...
- python入门之jieba库的使用
对于一段英文,如果希望提取其中的的单词,只需要使用字符串处理的split()方法即可,例如“China is a great country”. 然而对于中文文本,中文单词之间缺少分隔符,这是中文 ...
- Python基础库之jieba库的使用(第三方中文词汇函数库)
各位学python的朋友,是否也曾遇到过这样的问题,举个例子如下: “I am proud of my motherland” 如果我们需要提取中间的单词要走如何做? 自然是调用string中的spl ...
随机推荐
- H5横向滚动提示
<marquee>啦啦啦,Hello World</marquee>
- 记录pycharm快捷键出错的其中一个原因
#pycharm使用小技巧 最近在使用pycharm,所遇到的一些快捷键失效的问题.如ctrl+c,ctrl+v等:包括键入时,总是需要用“i”来实现等问题. 究其缘故,是在安装pycharm时, ...
- nopcommerce 4.1 core 插件 相关1
nop中 插件机制是比较值得学习的: Nop 插件学习: 1. 项目里面的生成必须是采用 直接编辑项目文件,参考nop原本的项目文件 动态加载插件的方法-mvc3 参考: using System.L ...
- java——类、对象、方法
一.类 1.Java语言把一组对象中相同属性和方法抽象到一个Java源文件就形成了类. 一个java文件可以有多个类,但是每一个类都会生成一个class字节码文件. 如果class 前加public ...
- spring jpa 语法
摘自http://www.cnblogs.com/BenWong/p/3890012.html Table 2.3. Supported keywords inside method names Ke ...
- 使用mybatis-generator工具自动生成mybatis代码
使用mybatis-generator工具自动生成mybatis代码 步骤如下: 1.引入maven 依赖,在项目pom.xml文件中添加 <plugin> <groupId> ...
- jsonp实现ajax跨域
前端 dataType为jsonp,若不指定回调函数名则默认为callback $.ajax({ url:headUrl+'/img/getImgList', type:'GET', dataType ...
- react native获取组件高度,宽 度等
import React,{Component} from 'react'import { View, Text, Image, StyleSheet, TouchableHighlight, Tou ...
- .Net Core+Angular6 学习 第一部分(创建web api)
. 创建.net core web api 1.1 选择一个empty 模式,里面只有简单的2个class 1.2 配置web api 的路由. 1.2.1 打开Startup.cs,首先引用conf ...
- java面向对象编程--Josephu问题(丢手帕问题)
Josephu问题为:设编号为1,2,...n的n个人围坐一圈,约定编号为k(1<=k<=n)的人从1开始报数,数到m的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推 ...