Spark Java API 之 CountVectorizer
Spark Java API 之 CountVectorizer
由于在Spark中文本处理与分析的一些机器学习算法的输入并不是文本数据,而是数值型向量。因此,需要进行转换。而将文本数据转换成数值型的向量有很多种方法,CountVectorizer是其中之一。
A CountVectorizer converts a collection of text documents into a vector representing the word count of text documents.
在构建向量时,有两个重要的参数:VocabSize和MinDF。前者表示词典的大小,后者表示当文档中某个Term出现的次数小于MinDF时,则不计入词典(该Term不属于词典中的 单词)。
比如说现在有两篇文档:【"w1", "w2", "w4", "w5", "w2"】,【"w1", "w2", "w3"】
CountVectorizer cv = new CountVectorizer().setInputCol("text").setOutputCol("feature")
.setVocabSize(3).setMinDF(2);
根据上面代码中的参数设置,词典大小为3,即一共可以有三个Term。由于在所有的文档中,"w1"出现2次,"w2"出现2次,因此计入词典。而"w3"、"w4"、"w5"只出现一次,不属于词典中的单词(Term)。如下图所示:词典中只有两个Term
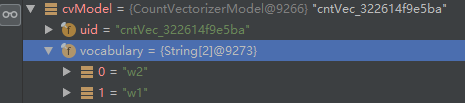
When the dictionary is not defined CountVectorizer iterates over the dataset twice to prepare
the dictionary based on frequency and size.
CountVectorizer 首先扫描Dataset(文本数据)生成词典,然后再次扫描生成向量模型(CountVectorizerModel)
在构造Dataset 时,需要指定模式。用模式来解释Dataset中每一行的数据。
StructType schema = new StructType(new StructField[]{
new StructField("text", new ArrayType(DataTypes.StringType, true), false, Metadata.empty())
});
A field inside a StructType. param: name The name of this field. param: dataType The data type of this field. param: nullable Indicates if values of this field can be
nullvalues. param: metadata The metadata of this field. The metadata should be preserved during transformation if the content of the column is not modified
第一个参数是:名称;第二个参数是dataType 数据类型;第三个参数是标识该字段的值是否可以为空;第四个参数为字段的元数据信息。
整个示例代码:
import org.apache.spark.ml.feature.CountVectorizer;
import org.apache.spark.ml.feature.CountVectorizerModel;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import java.util.Arrays;
import java.util.List;
public class CounterVectorExample {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("CountVectorizer").master("spark://172.25.129.170:7077").getOrCreate();
List<Row> data = Arrays.asList(
// RowFactory.create(Arrays.asList("a", "b", "c")),
// RowFactory.create(Arrays.asList("a", "b", "b", "c", "a")),
// RowFactory.create(Arrays.asList("a", "b", "a", "b"))
RowFactory.create(Arrays.asList("w1", "w2", "w3")),
RowFactory.create(Arrays.asList("w1", "w2", "w4", "w5", "w2"))
);
StructType schema = new StructType(new StructField[]{
new StructField("text", new ArrayType(DataTypes.StringType, true), false, Metadata.empty())
});
Dataset<Row> df = spark.createDataFrame(data, schema);
CountVectorizer cv = new CountVectorizer().setInputCol("text").setOutputCol("feature")
.setVocabSize(3).setMinDF(2);
CountVectorizerModel cvModel = cv.fit(df);
//prior dictionary
CountVectorizerModel cvm = new CountVectorizerModel(new String[]{"a", "b", "c"}).setInputCol("text")
.setOutputCol("feature");
// cvm.
cvModel.transform(df).show(false);
spark.stop();
}
}
输出结果默认是以稀疏向量表示:
A sparse vector represented by an index array and a value array.
param: size size of the vector. param: indices index array, assume to be strictly increasing. param: values value array, must have the same length as the index array.
第一个字段代表:向量长度,由于这里词典中只有2个Term,因此转换出来的向量长度为2;第二个字段:索引下标;第三个字段:索引位置处相应的向量元素值。由上图中位置0处的Term是 w2,位置1处的Term是w1,因此,输出:
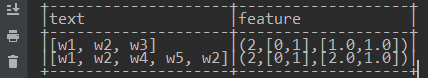
当然,我们也可以预先定义词典:在构造CountVectorizerModel的时候指定词典:【"w1", "w2", "w3"】
//prior dictionary
CountVectorizerModel cvm = new CountVectorizerModel(new String[]{"w1", "w2", "w3"}).setInputCol("text").setOutputCol("feature");
cvm.transform(df).show(false);
对于文本:[w1,w2,w3],每个Term都在词典中,且出现了一次,因此稀疏特征向量表示为:(3,[0,1,2],[1.0,1.0,1.0])。其中,3代表向量的长度为3维向量;[0,1,2]表示向量的索引;[1.0,1.0,1.0]表示,在相应的索引处,每个元素值为1.0(即各个Term只出现了一次)。而对于文本[w1, w2, w4, w5, w2],因为w4和w5不在词典中,w1出现一次,w2出现2次,故其特征如下:

可以看出:对于CountVectorizerModel,向量长度就是词典的大小。
系列文章:
原文:https://www.cnblogs.com/hapjin/p/9899164.html
Spark Java API 之 CountVectorizer的更多相关文章
- Spark Java API 计算 Levenshtein 距离
Spark Java API 计算 Levenshtein 距离 在上一篇文章中,完成了Spark开发环境的搭建,最终的目标是对用户昵称信息做聚类分析,找出违规的昵称.聚类分析需要一个距离,用来衡量两 ...
- 在 IntelliJ IDEA 中配置 Spark(Java API) 运行环境
1. 新建Maven项目 初始Maven项目完成后,初始的配置(pom.xml)如下: 2. 配置Maven 向项目里新建Spark Core库 <?xml version="1.0& ...
- spark (java API) 在Intellij IDEA中开发并运行
概述:Spark 程序开发,调试和运行,intellij idea开发Spark java程序. 分两部分,第一部分基于intellij idea开发Spark实例程序并在intellij IDEA中 ...
- spark java API 实现二次排序
package com.spark.sort; import java.io.Serializable; import scala.math.Ordered; public class SecondS ...
- spark java api数据分析实战
1 spark关键包 <!--spark--> <dependency> <groupId>fakepath</groupId> <artifac ...
- 【Spark Java API】broadcast、accumulator
转载自:http://www.jianshu.com/p/082ef79c63c1 broadcast 官方文档描述: Broadcast a read-only variable to the cl ...
- Spark基础与Java Api介绍
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3832405.html 一.Spark简介 1.什么是Spark 发源于AMPLab实验室的分布式内存计 ...
- 利用SparkLauncher 类以JAVA API 编程的方式提交Spark job
一.环境说明和使用软件的版本说明: hadoop-version:hadoop-2.9.0.tar.gz spark-version:spark-2.2.0-bin-hadoop2.7.tgz jav ...
- Spark:java api实现word count统计
方案一:使用reduceByKey 数据word.txt 张三 李四 王五 李四 王五 李四 王五 李四 王五 王五 李四 李四 李四 李四 李四 代码: import org.apache.spar ...
随机推荐
- 如何用Nginx解决前端跨域问题?
前言 在开发静态页面时,类似Vue的应用,我们常会调用一些接口,这些接口极可能是跨域,然后浏览器就会报cross-origin问题不给调. 最简单的解决方法,就是把浏览器设为忽略安全问题,设置--di ...
- centos下 telnet访问百度
先在命令行输入以下命令: telnet www.baidu.com 80 点击确认之后出现如下界面 然后接着输入以下两行命令 GET /index.html HTTP/1.1 Host: www.ba ...
- Kafka 0.11.0.0 实现 producer的Exactly-once 语义(英文)
Exactly-once Semantics are Possible: Here’s How Kafka Does it I’m thrilled that we have hit an excit ...
- 011_如何decode url及图片转为base64文本编码总结
一.咱们经常会遇到浏览器给encode后的url,如何转换成咱们都能识别的url呢?很简单,talk is easy,Please show me your code,如下所示: (1)英文decod ...
- 22 python 初学(类,面向对象)
python: 函数式 + 面向对象 函数式可以做所有的事,是否合适? 面向对象: 一.定义: 函数: def + 函数名(参数) 面向对象: class -> 名字叫 Bar 类 def ...
- 性能测试中的最佳用户数、最大用户数、TPS、响应时间、吞吐量和吞吞吐率
一:最佳用户数.最大用户数 转:http://www.cnblogs.com/jackei/archive/2006/11/20/565527.html 二: 事务.TPS 1:事务:就是用户某一步 ...
- Linux内核入门到放弃-内核活动-《深入Linux内核架构》笔记
中断 中断类型 同步中断和异常.这些由CPU自身产生,针对当前执行的程序 异步中断.这是经典的中断类型,由外部设备产生,可能发生在任意时间. 在退出中断中,内核会检查下列事项. 调度器是否应该选择一个 ...
- 5-STM32物联网开发WIFI(ESP8266)+GPRS(Air202)系统方案数据篇(配置保存数据的数据库)
配置信息如下:这是我的python软件和APP软件默认连接的配置 数据库名称:iot 编码utf8 表格名字:historicaldata 字段 id 自增,主键 date ...
- 【Android】pidcat 不显示日志输出
问题: 直接安装了 pidcat : brew install pidcat ,装完以后执行 pidcat <package name> ,发现没有日志输出,adb devices 也能 ...
- HashMap 与 HashSet 联系
HashMap实现 Map接口 HashSet实现Collection接口 HashSet底层是HashMap 好的 记住这个就可以了 HashSet只存放key, value: private ...