Linux简易APR内存池学习笔记(带源码和实例)
先给个内存池的实现代码,里面带有个应用小例子和画的流程图,方便了解运行原理,代码 GCC 编译可用。可以自己上网下APR源码,参考代码下载链接:
http://pan.baidu.com/s/1hq6A20G
贴两个之前学习的时候参考的文章地址,大家可以参考:
http://www.cnblogs.com/bangerlee/archive/2011/09/01/2161437.html
http://blog.csdn.net/flyingfalcon/article/details/2627965
一.引言
简单介绍下内存池。使用内存池技术是为了避免用户向系统申请和释放内存不当而造成内存泄露问题,且频繁的内存分配都可能导致效率的下降甚至程序崩溃。使用内存池来管理内存就能很好地避免上面的问题,并且不会产生或很少产生内存碎片。
内存池通常是一块很大的内存空 间,一次性被分配成功,然后需要的时候直接去池中取,而不需要重新分配,这样避免的频繁的malloc操作,而且另一方面,即时内存的使用者忘记释放内存 或者根本就不想分配,那么这些内存也不会丢失,它们仍然保存在内存池中,当内存池被销毁的时候这些内存将自动的被销毁。
内存池的实现方法有很多,这里只是就我手头上代码资料的学习笔记,但内存池的原理应该都是相近的,可做参考。
二.内存池结构
2.1. 内存分配结点
内是APR内存池中最基本的单元,为了能够方便的对分配的内存进行管理,APR内存池中使用了内存结点的概念来描述每次分配的内存块。对应的结构名为apr_memnode_t,定义如下:

1 /*内存分配结点*/
2 struct apr_memnode_t
3 {
4 pthread_mutex_t m_tLock; /**< Lock */
5 apr_memnode_t *next; /**< next memnode */
6 apr_memnode_t **ref; /**< reference to self */
7 int index; /**< size */
8 apr_allocator_t *m_pool; /**< pointer to memory pool*/
9 char *m_bData; /**< pointer to free memory address*/
10 #ifdef PRINTF
11 int m_iFreeFlg; /**< 重复释放标识 */
12 #endif
13 };
部分结构成员说明:
next:结点链表上的下一个内存分配结点(内存单元)
ref:指向内存分配结点本身,该变量主要用来记录当前结点的首地址,即使身在结点内部,也可以通过ref指针得到该结点并对该结点进行操作(手头上的代码没使用这个成员,预留)
index:指示了内存分配结点的大小,同时指示了该结点所在结点链表的索引下标值,索引值转换为实际内存大小为:index*apr_allocator_t->m_BoundarySize 字节,即索引值和增量大小相乘;index的本意是索引,但这里更重要的另一种概念是指内存大小,这两者含义是相结合共存的!
m_pool:指向所属的内存分配器
m_bData:实际分配给用户使用的内存地址
内存分配结点结构如下:

2.2. 内存分配器
内存池中,使用内存分配器对内存分配结点进行管理,包括内存的申请、释放、销毁等。其结构名为apr_allocator_t,定义如下:
1 /*内存分配器*/
2 struct apr_allocator_t
3 {
4 int max_index; /**< 当前内存池中已有的最大内存结点链表索引 */
5 int max_free_index; /**< 内存池的内存空间所能容纳的最大数值 */
6 int current_free_index; /**< 当前内存池空间还能容纳的数值 */
7 pthread_mutex_t m_tLock; /**< 内存池互斥锁 */
8 int *owner; /**< 指示该分配器属于哪个内存池 */
9 apr_memnode_t **free; /**< 指向一组链表的头结点,该链表中每个结点指向内存结点组成的链表 */
10
11 int m_MinAlloc; /**< 限定分配的最小规则内存结点大小 */
12 int m_MaxIndex; /**< 限定能够分配的最大规则内存链表索引 */
13 int m_ArpUint32Max; /**< 限定单次所能分配的最大内存结点 */
14 int m_BoundaryIndex; /**< 限定内存结点大小的递增指数,以2为底的指数 */
15 int m_BoundarySize; /**< 限定内存结点大小的递增值 */
16
17 /*内存池销毁*/
18 void (*Destruct)(void *pthis);
19 /*从内存池申请内存*/
20 void *(*mempool_alloc)(void *pthis, int _size);
21 /*从内存池释放内存*/
22 void (*mempool_free)(void* _node);
23 /*给内存结点加锁*/
24 void (*node_lock)(void* _node);
25 /*给内存结点解锁*/
26 void (*node_unlock)(void* _node);
27 }
部分结构成员说明:
max_index:free指针数组的下标索引,free[max_index-1]指向已有的最大内存结点链表;
max_free_index:内存池的内存空间所能容纳的最大数值,指的是所有内存分配结点apr_memnode_t->index的加权值;
m_MaxIndex:最大内存索引不代表最大内存大小,超过该内存大小的内存结点被分配到free[0]链表中;
2.3. 内存池结构
内存池的运行结构图如下:
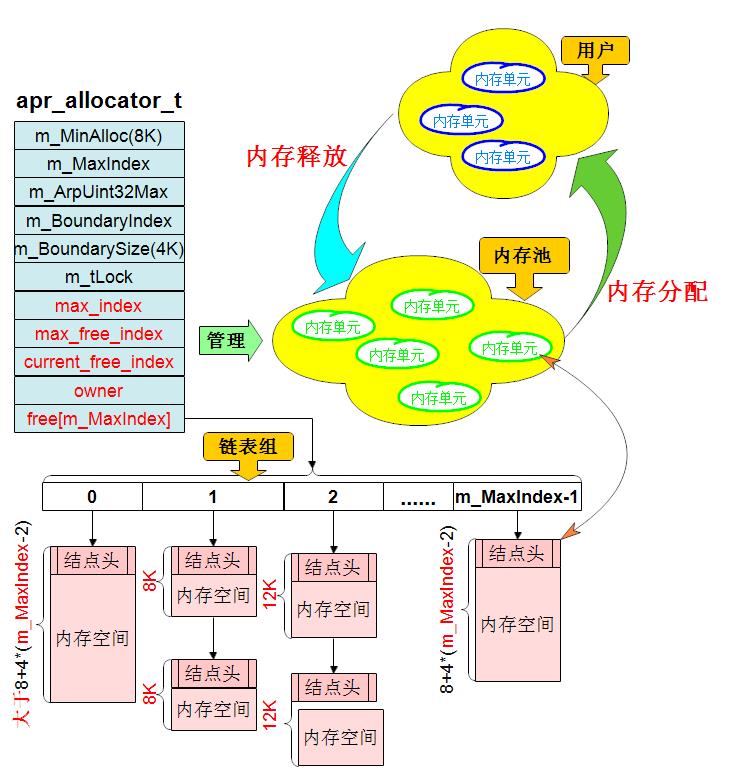
上图中内存单元和内存结点为同一个概念,这里罗列几个要点:
(1) 用户正在使用的内存单元和内存池中的内存单元是不属于同个区域的,用户使用的是分配出去的内存单元,而内存池保存的是待分配的内存单元,即空闲的内存块。(这一点容易和线程池的概念混淆)
(2) 初始创建内存池时,内存池里是没有内存单元的。用户申请内存单元时,会遍历链表组寻找是否有适合的内存单元,有则从内存池中分配出去,没有则重新malloc()一块内存给用户,用户使用完后释放到内存池中或直接释放回系统。
(3) free数组的下标从1到m_MaxIndex-1,分别指向一条内存结点大小固定的链表,下标增加1,结点的大小增加4k(m_BoundarySize),可根据实际设定。最小的内存分配结点为free[1]所指向的链表,大小为8k(m_MinAlloc),可设定。因此free[m_MaxIndex-1]所指向的链表的结点大小为8+4*(m_MaxIndex-2)k,这也是内存池使用者所能申请的最大”规则结点“,超过该大小的内存结点将使用下标free[0]指向的链表进行管理。
三.内存池管理
3.1. 内存大小计算
首先了解下内存是如何做到取整分配的,主要用到下面这个宏:
#define APR_ALIGN(size, boundary) (((size) + ((boundary) - 1)) & ~((boundary) - 1)) /**< 将size往上"取整到"大于size的最小的boundary的倍数*/
宏用来计算最接近size的boundary的整数倍的整数,并且大于size,boundary必须为2的倍数。其它使用的宏,如APR_ALIGN_DEFAULT (size)实际上转化为APR_ALIGN (size,8),即进行“8字节对齐”。
另外两个用来计算结构体对齐大小的宏:
#define SIZEOF_ALLOCATOR_T APR_ALIGN_DEFAULT(sizeof(apr_allocator_t)) /**< 内存分配器结构大小*/
#define APR_MEMNODE_T_SIZE APR_ALIGN_DEFAULT(sizeof(apr_memnode_t)) /**< 内存结点结构大小*/
这两个宏实际上就是将结构体内存分配结点apr_memnode_t和内存分配器apr_allocator_t的大小进行8字节对齐。
对于每次空间申请,先对齐空间大小:
1 size = APR_ALIGN(_size + APR_MEMNODE_T_SIZE, allocator->m_BoundarySize); /**< 转换为4K倍数 */
2 if (size < allocator->m_MinAlloc)
3 {
4 size = allocator->m_MinAlloc; /**< 允许分配的最小内存 */
5 }
结果是size的值变成4096(m_BoundarySize = 4k,2的12次方)的倍数,即我们申请的内存结点的实际大小(结点头+内存空间)。然后与最小分配规则内存进行对比,最小内存单元为8K,即m_MinAlloc = 8K。
index = (size >> allocator->m_BoundaryIndex) - 1; /**< 换算内存大小对应的索引值 */
最后,通过左移与链表组的下标索引进行关联,即free[index]。m_BoundaryIndex = 12,即size除于4K。
3.2. 内存池创建
1 apr_allocator_t * AllocatorPoolCreate()
2 {
3 apr_allocator_t *new_allocator;
4 if ((new_allocator = (apr_allocator_t*)malloc(SIZEOF_ALLOCATOR_T)) == NULL)
5 {
6 return NULL;
7 }
8
9 memset(new_allocator, 0, SIZEOF_ALLOCATOR_T);
10 new_allocator->max_free_index = APR_ALLOCATOR_MAX_FREE_UNLIMITED; /**< 内存空间不作限制 */
11 if ((new_allocator->free = (apr_memnode_t**)malloc(APR_MEMNODE_T_SIZE * DEFAULT_MAX_INDEX)) == NULL)
12 {
13 free(new_allocator);
14 return NULL;
15 }
16
17 memset(new_allocator->free, 0, APR_MEMNODE_T_SIZE * DEFAULT_MAX_INDEX);
18 ...... //略
19 pthread_mutex_init(&(new_allocator->m_tLock), NULL);
20 return new_allocator;
21 }
首先,创建内存分配器并为其申请内存空间,同样创建结点链表组并分配内存空间。初始化成员变量,其中,需要注意的是new_allocator->max_free_index被赋值为APR_ALLOCATOR_MAX_FREE_UNLIMITED,值为0。这条代码的意思是,内存池的最大可容纳内存空间不作限制,即不存在内存池空间受限将内存单元直接返回给系统。
3.3. 内存池销毁
内存池的销毁较简单,就是将内存池申请的内存空间全部释放给系统。需要注意的是空间释放的顺序,先释放内存结点,再释放链表组,最后释放内存分配器。
3.4. 内存申请
内存申请就是用户向内存池申请内存空间,内存池查找自身内存空间中合适的内存单元并分配给用户,也可能不存在满足要求的内存单元,则需要重新从系统申请。内存申请的策略如下:
(1) 根据申请空间的大小size,生成索引index,如果索引数值在1~max_index范围内,那就在index~ max_index范围内的链表中返回一块内存;
(2) 如果索引数值index > max_index-1,则在free[0]链表中查找一块合适的内存;
(3) 经上两步仍未找到空闲内存块,则通过malloc(size)返回一块新生成的内存;
在这里说明一下max_index 和 m_MaxIndex这两个变量之间的关系:max_index <= m_MaxIndex。m_MaxIndex 指的是最大规则内存结点链表组的索引大小,即创建内存池时申请的链表组大小,刚创建时所有的链表都是为空,free[1~ m_MaxIndex-1] == NULL;max_index 指的是当前链表组存在的最大可用索引,即 free[max_index]!=NULL,不过 free[0~ max_index-1] 之间不一定存在可用内存结点,free[max_index+1~ m_MaxIndex]==NULL。
下面就内存申请的3个策略代码进行分析:
//策略(1)
1 if (index <= allocator->max_index)
2 { /**< 表明当前的内存池内有内存结点可分配 */
3 pthread_mutex_lock(&(allocator->m_tLock));
4
5 max_index = allocator->max_index;
6 ref = &allocator->free[index]; /**< 取链表上的对应索引结点 */
7 i = index;
8
9 while (*ref == NULL && i < max_index)
10 { /**< 遍历链表直到找到可分配的内存结点 */
11 ref++;
12 i++;
13 }
14
15 if ((node = *ref) != NULL)
16 {
17 if ((*ref = node->next) == NULL && i >= max_index)
18 { /**< 如果所分配的结点为最大可用内存结点,且该链表上只有一个内存结点 */
19 do
20 {
21 ref--;
22 max_index--;
23 }
24 while (*ref == NULL && max_index > 0);
25 allocator->max_index = max_index; /**< 重新设置最大可用内存索引 */
26 }
27
28 allocator->current_free_index += node->index; /**< 更新内存池还能容纳的内存大小 */
29 if (allocator->current_free_index > allocator->max_free_index)
30 {
31 allocator->current_free_index = allocator->max_free_index; /**< 当前可容纳的内存大小不能超过最大内存大小 */
32 }
33 pthread_mutex_unlock(&(allocator->m_tLock));
34 node->next = NULL;
35 node->m_bData = (char *)node + APR_MEMNODE_T_SIZE; /**< 用户使用的内存地址 */
36
37 #ifdef PRINTF
38 node->m_iFreeFlg = 0;
39 #endif
40 return node->m_bData;
41 }
42 pthread_mutex_unlock(&(allocator->m_tLock));
43 }
代码19行的循环用来对链表组进行整理,当free[max_index]链表下的唯一内存结点被分配后,内存池中可用的最大索引max_index应该等待更新,循环就是用来寻找新的最大可用索引;
代码35行为计算要分配内存的地址,这里的地址不是内存结点的地址,而是实际给用户使用的内存空间地址;
//策略(2)
1 else if (allocator->free[0])
2 { /**< 超过限定的规则内存大小,则在这里寻找合适的内存结点 */
3 pthread_mutex_lock(&(allocator->m_tLock));
4 ref = &allocator->free[0]; /**< 取free[0]头结点 */
5 while ((node = *ref) != NULL && index > node->index)
6 { /**< 遍历free[0]链表,寻找合适的内存结点 */
7 ref = &node->next;
8 }
9
10 if (node)
11 { /**< 找到可用的内存结点 */
12 *ref = node->next;
13 allocator->current_free_index += node->index;
14 if (allocator->current_free_index > allocator->max_free_index)
15 {
16 allocator->current_free_index = allocator->max_free_index;
17 }
18
19 pthread_mutex_unlock(&(allocator->m_tLock));
20 node->next = NULL;
21 node->m_bData = (char *)node + APR_MEMNODE_T_SIZE; /**< 用户使用的内存地址 */
22
23 #ifdef PRINTF
24 node->m_iFreeFlg = 0;
25 #endif
26 return node->m_bData;
27 }
28 pthread_mutex_unlock(&(allocator->m_tLock));
29 }
代码分析看注释。
//策略(3)
1 if ((node = (apr_memnode_t*)malloc(size)) == NULL) /**< 找不到可分配的内存结点则重新向系统申请 */
2 {
3 return NULL;
4 }
5 node->next = NULL;
6 node->index = index;
7 node->m_bData = (char *)node + APR_MEMNODE_T_SIZE;
8 node->m_pool = allocator;
9
10 #ifdef PRINTF
11 node->m_iFreeFlg = 0;
12 #endif
13
14 pthread_mutex_init(&(node->m_tLock), NULL); /**< 初始化内存结点的互斥锁 */
15 return node->m_bData;
代码8行m_pool成员指向所属的内存池。
3.5. 内存释放
内存释放是用户在使用完内存后将内存单元重新返还给内存池或系统,需要注意的是,在内存申请时从系统中新分配的内存是直接给用户使用,不划分在内存池里面,即并不挂接到内存分配器链表free[index]中。内存释放的策略如下:
(1) 如果结点的大小超过了当前内存池所能容纳的空间current_free_index,那么就不能将其简单的归还到索引链表中,而必须将其完全归还给操作系统;
(2) 如果index< m_MaxIndex,则意味着该结点属于“规则结点”的范围,因此可以将该结点返回到对应的“规则链表free[1~ m_MaxIndex-1]”中;
(3) 如果结点超过了“规则结点”的范围,但是并没有超过当前能够容纳的空间current_free_index,此时我们则可以将其置于free[0]链表的首部中;
下面就内存释放的3个策略代码进行分析:
//策略(1)
1 if (max_free_index != APR_ALLOCATOR_MAX_FREE_UNLIMITED && index > current_free_index)
2 { /**< 超过内存池所能容纳的数值 */
3 node->next = freelist;
4 freelist = node;
5 }
6 ...... //略
7 while (freelist != NULL)
8 { /**< 释放内存 */
9 node = freelist;
10 freelist = node->next;
11 pthread_mutex_destroy(&(node->m_tLock));
12 free(node);
13 node = NULL;
14 }
APR_ALLOCATOR_MAX_FREE_UNLIMITED 这个宏作为内存池大小不作限制的标志,代码中 freelist 链表用来保存释放给系统的内存结点。
//策略(2)
1 else if (index < allocator->m_MaxIndex)
2 { /**< 未超过最大规则内存结点大小 */
3 if ((node->next = allocator->free[index]) == NULL && index > max_index)
4 { /**< 超过当前最大可分配内存结点 */
5 max_index = index;
6 }
7
8 #ifdef PRINTF
9 node->m_iFreeFlg = 1;
10 #endif
11 allocator->free[index] = node; /**< 放入链表头 */
12
13 if (current_free_index >= index)
14 current_free_index -= index; /**< 更新可容纳的内存大小 */
15 else
16 current_free_index = 0;
17 }
代码分析看注释。
//策略(3)
1 else
2 { /**< 超过最大规则内存结点大小 */
3 #ifdef PRINTF
4 node->m_iFreeFlg = 1;
5 #endif
6 node->next = allocator->free[0];
7
8 allocator->free[0] = node; /**< 放入free[0]链表 */
9 if (current_free_index >= index)
10 current_free_index -= index; /**< 更新可容纳的内存大小 */
11 else
12 current_free_index = 0;
13 }
代码分析看注释。
Linux简易APR内存池学习笔记(带源码和实例)的更多相关文章
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
- [转]OpenTK学习笔记(1)-源码、官网地址
OpenTK源码下载地址:https://github.com/opentk/opentk OpenTK使用Nuget安装命令:OpenTK:Install-Package OpenTK -Versi ...
- linux学习笔记-lrmi源码包的编译安装方法
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! 官方的lrmi包没有人更新了,如果碰到需要这个编译安装这个包,可以参考我的解决思路,如下: https://pkgs.org/这 ...
- Nginx学习笔记4 源码分析
Nginx学习笔记(四) 源码分析 源码分析 在茫茫的源码中,看到了几个好像挺熟悉的名字(socket/UDP/shmem).那就来看看这个文件吧!从简单的开始~~~ src/os/unix/Ngx_ ...
- MarkDown语法 学习笔记 效果源码对照
MarkDown基本语法学习笔记 Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式. 下面将对Markdown的基本使用做一个介绍 目 ...
- Vue2.x源码学习笔记-Vue源码调试
如果我们不用单文件组件开发,一般直接<script src="dist/vue.js">引入开发版vue.js这种情况下debug也是很方便的,只不过vue.js文件代 ...
- 【JVM学习笔记】字节码文件结构实例
上一篇笔记的内容大部分没有实际动手操作,因此决定完成这个完整的练习并记录下来. 另注,idea环境下有jclasslib插件用于更好的查看类似于javap结果的内容. 源代码如下: package c ...
- SLAM学习笔记 - ORB_SLAM2源码运行及分析
参考资料: DBow2的理解 单目跑TUM数据集的运行和函数调用过程 跑数据集不需要ros和相机标定,进入ORB_SLAM目录,执行以下命令: ./Examples/Monocluar/mono_tu ...
- python编程:从入门到实践--项目1-外星人入侵_学习笔记_源码
这里有九个.py文件,在工作的间隙,和老板斗智斗勇,终于完成了,实现了游戏的功能,恰逢博客园开通,虽然是对着书上的代码敲了一遍,但是对pygam这个库的了解增加了一些,作为一个python初学者,也作 ...
随机推荐
- JavaScript中Ajax的用法
XMLHttpRequest 对象的属性和方法: open(method,url,async) 规定请求的类型.URL 以及是否异步处理请求 send(string) 将请求发送到服务器. res ...
- 【转】Android-Input Getevent
https://source.android.com/devices/input/getevent Getevent getevent 工具可在设备上运行,并可提供关于输入设备和内核输入事件的实时转储 ...
- MySQL在高内存、IO利用率上的几个优化点
以下优化都是基于CentOS系统下的一些MySQL优化整理,有不全或有争议的地方望继续补充完善. 一.mysql层面优化 1. innodb_flush_log_at_trx_commit 设置为2设 ...
- SpringBoot中的ajax跨域问题
在控制类加入注释@CrossOrigin(allowCredentials = "true",allowedHeaders = "*",origins = {& ...
- JavaSpcript基础
函数 代码的复用:写一遍多次使用>把特定的功能语句打包放在一起 语法:function 名字(0,1,1多个参数){ 执行的语句 } 返回值return,把语句返回给函数 例子: functio ...
- awk统计文本里某一列重复出现的次数
比如这样的场景:现在有一个文本,里面是这样的内容: NOTICE: 12-14 15:11:13: parser. * 6685 url=[http://club.pchome.net/threa ...
- 自动删除Android工程中无用的资源
开发时间久了, 几个版本迭代之后, 工程中难免留下很多垃圾资源, 造成apk的包很大, 这里介绍一个工具, 可以自动扫描工程中, 没有使用的资源, 然后自动删除: 包括图片, xml, 文本等. 采用 ...
- AT24C0X I2C通信原理
/********************************************************************** * AT24C0X I2C通信原理 * 说明: * 之前 ...
- Visual C++ 6.0中if语句的常见问题
# include <stdio.h> int main (void) { > )//如果在第四行加分号的话,编译的时候就会在第六行出错 printf("你好\n" ...
- java效验只能为数字类型
首先要import java.util.regex.Pattern 和 java.util.regex.Matcher /** * 利用正则表达式判断字符串是否是数字 * @param str * @ ...