scrapy爬虫学习系列五:图片的抓取和下载
系列文章列表:
scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy01.html
scrapy爬虫学习系列二:scrapy简单爬虫样例学习: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_007_scrapy02.html
scrapy爬虫学习系列三:scrapy部署到scrapyhub上: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_004_scrapyhub.html
scrapy爬虫学习系列四:portia的学习入门: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_010_scrapy04.html
scrapy爬虫学习系列五:图片的抓取和下载: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_011_scrapy05.html
scrapy爬虫学习系列六:官方文档的学习: https://github.com/zhaojiedi1992/My_Study_Scrapy
注意: 我自己新建的一个QQ群(新建的),欢迎大家加入一起学习一起进步 ,群号646187336
这篇文章主要对一个车标网(http://car.bitauto.com/qichepinpai)的图片进行抓取,并按照图片的alt属性值去设置输出图片命名。
本文的最终源码下载地址(github):https://github.com/zhaojiedi1992/caricon
1.创建工程和爬虫
C:\Users\Administrator>e: E:\>cd scrapytest E:\scrapytest>scrapy startproject caricon
New Scrapy project 'caricon', using template directory 'C:\\Program Files\\Anaconda3\\lib\\site-packages\\scrapy\\templa
tes\\project', created in:
E:\scrapytest\caricon You can start your first spider with:
cd caricon
scrapy genspider example example.com E:\scrapytest>cd caricon E:\scrapytest\caricon>scrapy genspider car car.bitauto.com/qichepinpai
Created spider 'car' using template 'basic' in module:
caricon.spiders.car
4.修改item
添加字段,修改后为如下内容:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class CariconItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
alt = scrapy.Field()
- image_urls : 作为项目的图片网址(需要我们指定url)。
- images :下载的影像信息(这个字段不是我们填充的)。
注意: 上面的alt字段是我自己加的,image_urls ,images这2个字段是请求图片的默认字段,必须要有的,建议使用默认字段。你要是喜欢折腾可以参考这个网址:https://docs.scrapy.org/en/latest/topics/media-pipeline.html#usage-example
3.修改爬虫
这里我们先使用火狐浏览器的Firefinder插件找找我们需要提取的图片,图片如下:
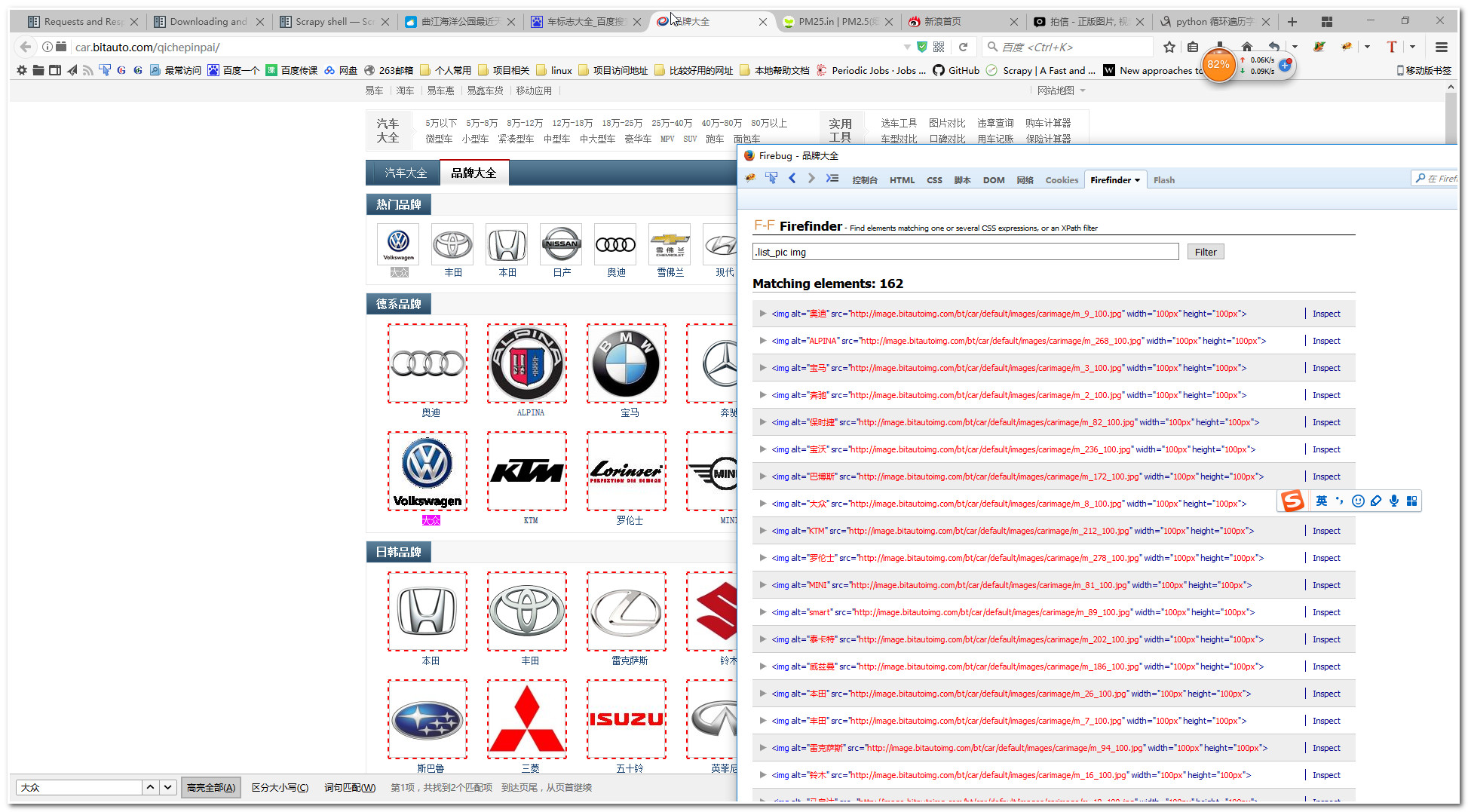
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class CariconPipeline(object):
def process_item(self, item, spider):
return item
from scrapy.contrib.pipeline.images import ImagesPipeline
from scrapy.http import Request
from scrapy.exceptions import DropItem
import os class MyImagesPipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
#url_file_name= request.url.split('/')[-1]
#image_guid = hashlib.sha1(to_bytes(url)).hexdigest()
alt_name=request.meta["alt"]
return 'full/%s%s' % (alt_name, os.path.splitext(request.url)[-1]) def get_media_requests(self, item, info):
yield Request(item["image_urls"][0], meta={'alt':item["alt"]})
代码简介:通常我们使用官方的那个imagepipeline导出的文件是SHA1 hash 你的url作为文件名,很难区别啊,这里使用到了request方法的meta参数,把我们的图片的alt属性传递过去,这样我们返回文件名的时候就可以使用这个alt的名字来区别了。(但是如果alt重复又替换了原来的图片的)
注意,firefinder这个插件依赖与firebug的,你可以在你的浏览器找类似firefinder的工具。
6.修改setttings.py文件
修改下面片段为如下内容:
ITEM_PIPELINES = {
'caricon.pipelines.MyImagesPipeline': 300,
}
IMAGES_STORE = r'e:\test\pic\'
当然我们这里可以使用官方的imagepipeline(scrapy.pipelines.images.ImagesPipeline)
6.运行爬虫
E:\scrapytest\caricon>scrapy crawl car
7.查看结果
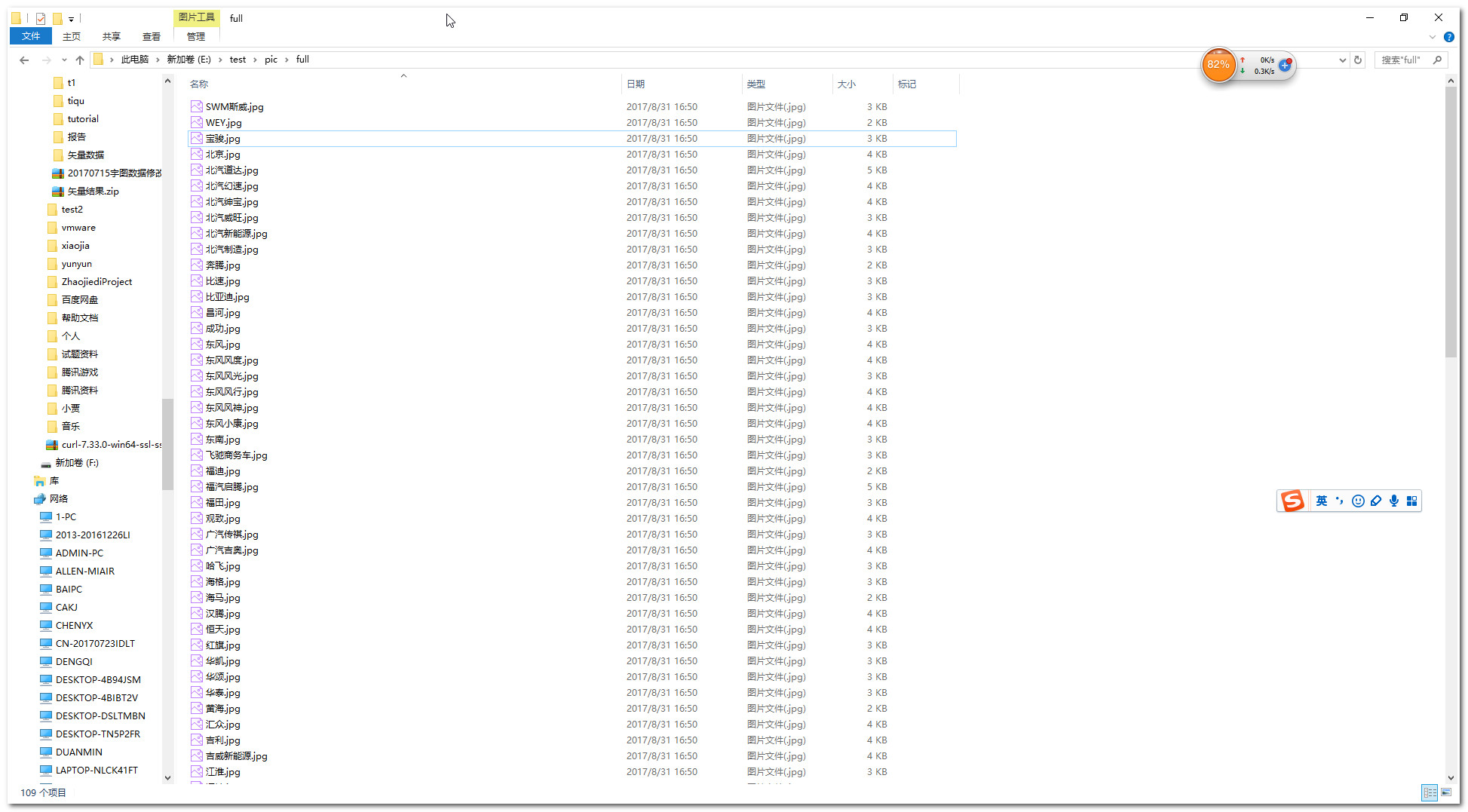
scrapy爬虫学习系列五:图片的抓取和下载的更多相关文章
- scrapy爬虫学习系列四:portia的学习入门
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列七:scrapy常见问题解决方案
1 常见错误 1.1 错误: ImportError: No module named win32api 官方参考:https://doc.scrapy.org/en/latest/faq.html# ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
随机推荐
- Vue.js的安装及简单使用
一.Vue简介 二.Vue.js的安装 2.1.npm安装 2.1.1.node.js介绍及安装 简介: 简单的说 Node.js 就是运行在服务端的 JavaScript. Node.js 是一个基 ...
- 如何使用 tf object detection
# 如何使用 tf object detection https://juejin.i m/entry/5a7976166fb9a06335319080 https://towardsdatascie ...
- Android 动画 (1) 基础
背景 坑, 最近打算在recyclerview item上加一个带动画的button,结果button无法连续点击,还以为是动画是同步的,必须要结束之后才能开始另一个动画,后来去掉recylervie ...
- CentOS7部分调优命令
一般CentOS的磁盘空间占用最大的就是日志文件,日志文件主要保存在./log目录里,因此通过以下命令可以检查目录的大小. du -ah --max-depth=1 du命令的一些常用参数: -a或- ...
- 算法第四版中 while (!StdIn.isEmpty()) 循环无法跳出问题
在IDEA中使用Ctrl+D就可以退出console输入
- SpringBoot报错:The server time zone value 'Öйú±ê׼ʱ¼ä' is unrecognized or represents more than one time zone
解决方法: 在数据库连接url配置后边加&serverTimezone=GMT%2B8 例: jdbc:mysql://127.0.0.1:3306/test改为jdbc:mysql://12 ...
- Shell 脚本处理用户输入
传递参数 跟踪参数 移动变量 处理选项 将选项标准化 获得用户的输入 bash shell提供了一些不同的方法来从用户处获取数据,包括命令行参数(添加在命令后数据),命令行选项(可以修改命令行为的单个 ...
- 34 文件地理数据库(GDB)变文件夹了怎么办
我们都知道文件地理数据库(GDB)是ArcGIS软件特有的格式,有其独特的设计之处,在文件资源管理器中显示为.gdb的文件夹,但是里面的文件却看不明白,而且将gdb文件夹在Windows资源管理器中直 ...
- Android中RadioGroup的初始化和简单的使用
一简介: RadioGroup作为一个单选按钮组,可以设置为性别选择男或则女,地址选择等等,作为一个android入门级选手,就简单的说一下RadioGroup组中RadioButton的布局和初始化 ...
- APP研发录笔记
一.消灭全局变量 在内存不足时,系统会回收一部分闲置的资源,由于App被切换到后台,所以之前存放的全局变量很容易被回收,这时再切换到前台继续使用,会报空指针崩溃.想彻底解决这个问题,就要使用序列化. ...