OO第二次博客
过去三周里,我们完成了多线程电梯的程序设计与构造。这是我第一次接触多线程编程。我感觉最大的困难在于多个线程中的操作,谁先谁后,不是像以前写的单线程程序那样严格确定,所以心里常常会比较慌。尤其是因为多线程运行有一定随机性,常常可能会发生bug无法复现的情况,或者是代码有风险但碰巧测试运行时没有出现问题。
一.设计策略总结
电梯问题的多线程设计,与理论课上学习的生产者消费者模型是比较类似的。请求队列支持插入新的请求和弹出请求(给电梯)。仿照生产者消费者模型,把读线程看作生产者,把电梯线程看作消费者,可以完成多线程的同步控制。
由于我能力有限,对于多部电梯的情形,我的调度方案是只考虑单个电梯的状态,决定是否将请求分配给该电梯,并没有选择综合所有电梯的状态。因此电梯运行性能会比较差,但避免了复杂的多线程协同问题。
二.程序结构分析


第一次作业的需求比较简单,所以各个模块内容都比较少,大概也是因此,各项指标都还不错。电梯类中的working方法是令电梯完成一个请求,由于这次作业没有捎带,也不需要在每一层完成输出,我把所有的内容都混在一起写了,所以指标要偏高一些。
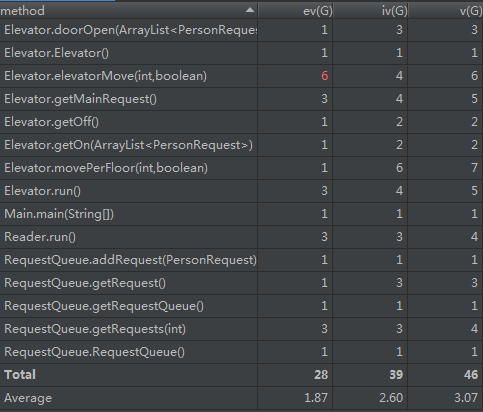
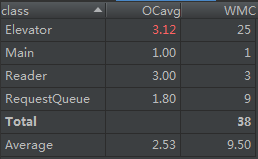
第二次作业加入了捎带,整个电梯类变得复杂多了,主类和读入类几乎没有变化,请求队列类只多了一种取请求的方式,来支持捎带。电梯类的elevatormove方法是让电梯到达目标楼层,分上行和下行两类情况,对途中每一层都调用moveperfloor方法,视情况可能会执行开门,乘客出入,关门行为,以及可能的捎带操作,并完成相应的输出,因此这个方法几乎全是条件循环,指标偏高。
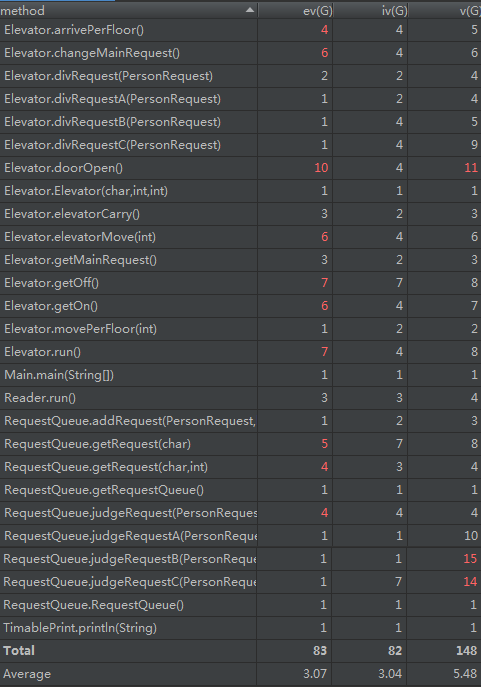
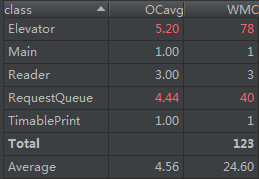
第三次作业的度量结果就比较差了。主类和读入类没有太多变化,但电梯类和请求队列类问题比较大。我的调度器是整合在请求队列里的,而电梯得到请求后会根据自身停靠情况来做请求的拆分,并在执行完前半段请求后,把后半段不能执行的请求送回请求队列,等待其他电梯来获取该请求。我的调度和请求拆分都写的不好,条件判断复杂。此外,由于加入了电梯容量限制,常常需要判断乘客是否进入了电梯,使结构复杂了一些,这也是和前面的两次作业比较大的不同。 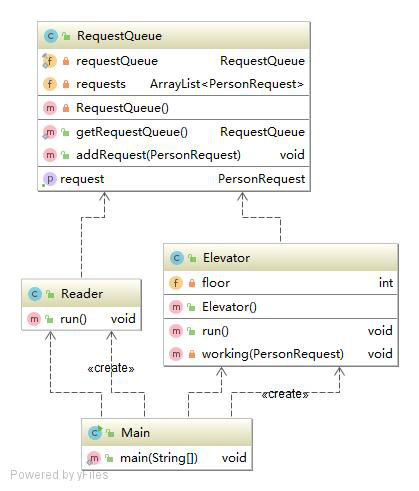
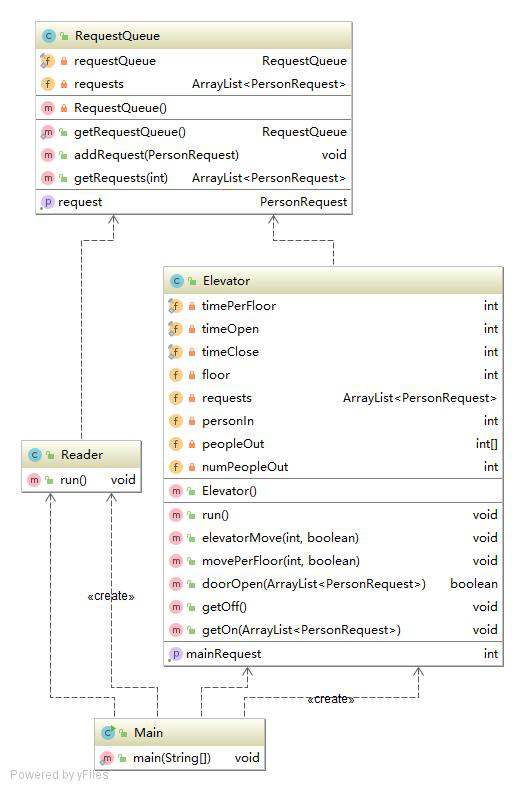
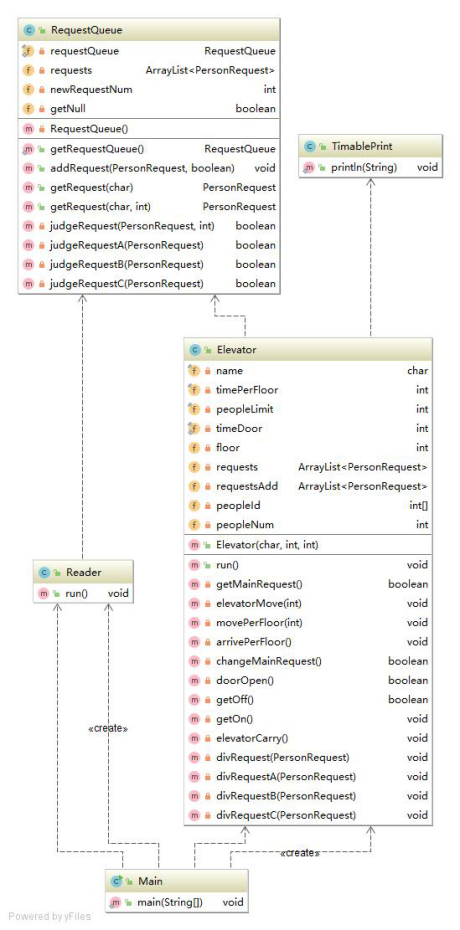
至于类图,三次作业基本差不多,主要是电梯类随着新需求的加入,变得复杂了许多。主类创建了读线程和电梯线程,并完成输出时间戳的初始化。读入线程把请求读进来放进请求队列中。电梯线程每当没有请求时,就向请求队列取新的请求,然后按照请求去运行,顺路捎带。请求队列相当于是一个线程交互的平台,在第三次作业中还会参与请求的分配工作,执行最初步的判断。
从SOLID原则的角度分析,我的架构问题很大。首先我并没有利用继承和接口,也就不存在L和I原则。S原则要求的单一功能,我的电梯类感觉比较混乱,各种功能都包含在内了。至于O原则,我的请求队列谁都能添加和取出请求,并没有写成封闭的。D原则感觉好复杂,我不理解具体要写成什么样子才是“依赖于抽象”,大概指的是对象的交互的媒介吧,要写的更巧妙一些。
三.Bug分析
第二次电梯和第三次电梯作业我都出现了bug。
第二次作业的bug是因为我记录了电梯主请求的乘客编号,但是误以为编号是正整数,而实际上指导书上写的是非负整数。弱测并没有出现过编号为0的情形,第一次作业也没有判断过乘客编号,所以我完全没有注意到。强测中出现了乘客编号为0,所以我的代码就出错了。我的捎带方案是电梯达到请求的起点楼层时,就捎带该乘客,乘客会立即进入电梯。因此,只有主请求,它有可能不是被捎带上的请求,它的乘客有可能还没有上车,所以我把主请求的乘客编号单独存下来了。
第三次作业的bug是,电梯在前往主请求的起点楼层前,就由于捎带而把电梯装满了,因此主请求的乘客上不来;但我没有考虑这种情况,我会让电梯继续前往主请求的终点请求,到达后,由于乘客还没上来,自然也不会下,并且电梯主请求不会更换,因此又要去主请求的起点楼层;如果到了以后电梯仍然满员,就会循环下去;特别的,当来回过程中没有乘客离开电梯,就陷入了死循环。最简单的修正方法是如果主请求的乘客上不来,就更换主请求,换成任何一个乘客已经进入电梯了的请求即可。
两次作业的bug都与多线程没有什么关系,而是电梯运行的一些细节考虑失当,而且是设计时完全没有想到过的问题。特别是第三次作业,我对于电梯加入乘客数量限制,会造成多大的影响,分析不够全面。
四.心得体会
线程安全方面,由于我的设计规避了很多风险,并不涉及到复杂的线程安全问题。如果我的调度方案要综合所有电梯的状态,那么就需要处理“先判断后修改”的情形。
多线程的设计原则,应该是尽可能减少线程同步的发生。如果多线程程序中大量出现线程锁,这样的性能是非常差的。我的电梯程序中只有请求队列里出现线程同步,这是比较简单的多线程情形。
程序的设计原则,需要考虑未来可能加入的新需求,提取把架构设计好。好的代码应当具备高的可扩展性。我三次作业的大框架基本是一致的,但是电梯类每次改变都比较大。这点在今后还需要多学习,争取能设计出好的架构。
OO第二次博客的更多相关文章
- OO第二次博客作业——电梯调度
OO第二次博客作业——电梯调度 前言 最近三周,OO课程进入多线程学习阶段,主要通过三次电梯调度作业来学习.从单部电梯的傻瓜式调度到有性能要求的调度到多部电梯的调度,难度逐渐提升,对同学们的要求逐渐变 ...
- OO第二次博客作业—17373247
OO第二次博客作业 零.写在前面 OO第二单元宣告结束,在这个单元里自己算是真正对面向对象编程产生了比较深刻的理解,也认识到了一个合理的架构为编程带来的极大的便利. (挂三次评测分数 看出得分接近等差 ...
- OO第二次博客作业(第二单元总结)
在我开始写这次博客作业的时候,窗外响起了希望之花,由此联想到乘坐自己写的电梯FROM-3-TO--1下楼洗澡,然后······ 开个玩笑,这么辣鸡的电梯肯定不会投入实际使用的,何况只是一次作业.还是从 ...
- 渐入OO课的深处,探索多线程的秘密——OO第二次博客总结
一次又一次的挑战,一次又一次全新的知识,我来到了多线程的面前 第五次作业 1.度量分析 >第五次作业由于很大程度上调用的是前两次电梯的一些代码,所以存在的问题与前几次也十分相似.同时由于第一次使 ...
- 2019年北航OO第二次博客总结
一.多线程电梯系列作业设计策略 1. 第一次作业——"FAFS傻瓜电梯" 第一次作业是先来先服务的"傻瓜电梯",我当时觉得这个设计未免太简单了,于是就在傻瓜电梯 ...
- oo第二次博客作业
多线程协同与同步控制总结 第五次作业-多线程电梯 本次作业是我第一次接触多线程,建立了请求模拟器.调度器和电梯运行三种线程.请求模拟器负责在输入后识别有效请求:调度器在扫描有效请求后将新的请求加入请求 ...
- OO第二次博客作业--第二单元总结
第一次作业 1. 设计策略 第一次作业,一共三个线程,主线程.输入线程和电梯线程,有一个共享对象--调度器(队列). 调度的策略大多集中到了电梯里,调度器反而只剩下一个队列. 2. 基于度量的分析 类 ...
- OO第二单元博客
三次作业的设计策略 第一次作业 多线程协同控制 第一次作业只需要两个线程和一个公共缓冲区: 负责读取输入并把它添加进命令队列的线程,即生产者 负责从命令队列中取出命令执行的线程,即消费者 再加上一个缓 ...
- oo第二单元博客总结
P1 设计结构 三次作业的架构都没有较大的改动,基本上都是靠调度器接受输入的请求并放入队列,然后调度器根据不同的电梯的当前状态来把请求分配至不同电梯的请求队列中,最后电梯再根据自己的请求队列去运行.因 ...
随机推荐
- Eigen::Matrix与array数据转换
1. 数组转化为Eigen::Matrix ]; cout << "colMajor matrix = \n" << Map<Matrix3i> ...
- HDU 5977 Garden of Eden
题解: 路径统计比较容易想到点分治和dp dp的话是f[i][j]表示以i为根,取了i,颜色数状态为j的方案数 但是转移这里如果暴力转移就是$(2^k)^2$了 于是用FWT优化集合或 另外http: ...
- es elasticsearch-head安装
---恢复内容开始--- 参考 https://www.jianshu.com/p/36d7f97a20cd 1.下载安装git clone git://github.com/mobz/elastic ...
- python 列表常用方法
1.在列表末尾添加新的对象 li=[11,22,33,'aa','bb','cc'] li.append('dd') print(li) 2.清空列表 li=[11,22,33,'aa','bb',' ...
- [PKUSC2018]星际穿越
[PKUSC2018]星际穿越 题目大意: 有一排编号为\(1\sim n\)的\(n(n\le3\times10^5)\)个点,第\(i(i\ge 2)\)个点与\([l_i,i-1]\)之间所有点 ...
- 软件工程团队:Spring计划会议及详细计划表
极限挑战! 小组Spring计划表: 11.15 进行软件需求分析,了解调查社会背景,确定要编写的软件,分配各小组成员的任务.确定小组会议每天召开地点时间. 3h 11.16 将任务进一步精确分配, ...
- 07-MYSQL多表查询
今日任务 完成对MYSQL数据库的多表查询及建表的操作 教学目标 掌握MYSQL中多表的创建及多表的查询 掌握MYSQL中的表关系分析并能正确建表 昨天内容回顾: 数据库的创建 : crea ...
- Vue使用中常见问题
1.安装sass时报未找到 1.原因应该同时安装:1.npm install --save-dev sass-loader 2.npm install --save-dev node-sass ...
- __x__(16)0906第三天__层叠样式表CSS简介
层叠样式表CSS Cascading Style Sheets 用来为网页创建样式表,通过样式表对网页进行装饰. 所谓层叠,就是将网页想象成一层一层的结构,层次高的将覆盖层次低的. CSS可以为网页的 ...
- ICL2019E
https://www.codechef.com/ICL2019/problems/ICL1906 两个整数,[0,1e5]操作1是让两个数同时减1(只有都大于0的时候才可以用)操作2可以让一个数乘 ...