elasticsearch之分词插件使用
elasticsearch对英文会拆成单个单词,对中文会拆分成单个字。下面来看看是不是这样。
首先测试一下英文:
GET /blog/_analyze
{
"text": "Installation and Upgrade Guide"
}
返回结果如下:
{
"tokens": [
{
"token": "installation",
"start_offset": 0,
"end_offset": 12,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "and",
"start_offset": 13,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "upgrade",
"start_offset": 17,
"end_offset": 24,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "guide",
"start_offset": 25,
"end_offset": 30,
"type": "<ALPHANUM>",
"position": 3
}
]
}
接下来测试一下中文:
GET /blog/_analyze
{
"text": "加媒称美军利用威克岛遏制中国"
}
返回结果如下:
{
"tokens": [
{
"token": "加",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "媒",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "称",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "美",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
},
{
"token": "军",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
},
{
"token": "利",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "用",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "威",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 7
},
{
"token": "克",
"start_offset": 8,
"end_offset": 9,
"type": "<IDEOGRAPHIC>",
"position": 8
},
{
"token": "岛",
"start_offset": 9,
"end_offset": 10,
"type": "<IDEOGRAPHIC>",
"position": 9
},
{
"token": "遏",
"start_offset": 10,
"end_offset": 11,
"type": "<IDEOGRAPHIC>",
"position": 10
},
{
"token": "制",
"start_offset": 11,
"end_offset": 12,
"type": "<IDEOGRAPHIC>",
"position": 11
},
{
"token": "中",
"start_offset": 12,
"end_offset": 13,
"type": "<IDEOGRAPHIC>",
"position": 12
},
{
"token": "国",
"start_offset": 13,
"end_offset": 14,
"type": "<IDEOGRAPHIC>",
"position": 13
}
]
}
为了能够对中文进行更好的分词,我们需要安装第三方的分词插件,目前比较成熟的是ik(elasticsearch-analysis-ik),官方地址:https://github.com/medcl/elasticsearch-analysis-ik。
安装方式
方式一:到这里下载已编译好的包,解压到elasticsearch安装根目录下的plugins文件夹。
方式二:elasticsearch 版本在5.5.1以上,可以使用 elasticsearch-plugin 安装,方式如下:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.3/elasticsearch-analysis-ik-6.2.3.zip
方式三:elasticsearch-analysis-ik是用maven构建的java项目,和打包自己写的java程序没啥区别。所以只需下载代码到本地,使用 mvn package打包后,解压到elasticsearch安装根目录下的plugins文件夹下即可。
注意,安装好后,记得重启elasticsearch。安装好后大概就是下面这样子。
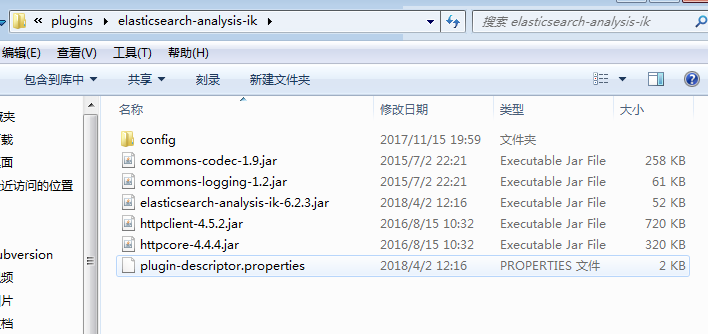
测试安装是否成功
ik分词有两种分词方式:ik_max_word 和 ik_smart ,区别在于:
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
下面我们再来测试一把:
GET /blog/_analyze
{
"text": "加媒称美军利用威克岛遏制中国",
"analyzer": "ik_max_word"
}
返回结果如下:
{
"tokens": [
{
"token": "加",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "媒",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "称",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "美军",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 3
},
{
"token": "利用",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "威",
"start_offset": 7,
"end_offset": 8,
"type": "CN_CHAR",
"position": 5
},
{
"token": "克",
"start_offset": 8,
"end_offset": 9,
"type": "CN_CHAR",
"position": 6
},
{
"token": "岛",
"start_offset": 9,
"end_offset": 10,
"type": "CN_CHAR",
"position": 7
},
{
"token": "遏制",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 8
},
{
"token": "中国",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 9
}
]
}
从上面的返回结果来看,分词插件就安装成功了。下面简单举个例子:
1、创建index和mapping,并指定title字段使用ik_max_word方式进行分词
PUT /blog
{
"mappings": {
"news": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
2、添加一些数据,最好有点关联,这样搜索才能看到效果:
POST /blog/news/_bulk?pretty
{"index":{"_id":"1"}}
{"title": "台退将警告台当局:美国把台湾当筹码 想玩你!" }
{"index":{"_id":"2"}}
{"title":"美媒:中国以前遭美污蔑走防守路线 现在战斗力太强"}
{"index":{"_id":"4"}}
{"title":"美国在南海设“红线”和炮舰政策 不会吓倒中国"}
{"index":{"_id":"5"}}
{"title":"美媒:美国想单方面遏制中国?结果可能很惨"}
{"index":{"_id":"6"}}
{"title":"美媒炒作俄可能“割光缆” 担心俄或借此反制西方"}
{"index":{"_id":"7"}}
{"title":"金一南:逼中国与俄罗斯结盟 将是西方最大灾难!"}
{"index":{"_id":"8"}}
{"title":"旧战场焕发新生?加媒称美军利用威克岛遏制中国"}
3、接着,我们来搜索一把
GET /blog/news/_search
{
"query": { "match": { "title": "结果可能很惨" } }
}
返回结果如下:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 2.1470046,
"hits": [
{
"_index": "blog",
"_type": "news",
"_id": "5",
"_score": 2.1470046,
"_source": {
"title": "美媒:美国想单方面遏制中国?结果可能很惨"
}
},
{
"_index": "blog",
"_type": "news",
"_id": "6",
"_score": 0.99096406,
"_source": {
"title": "美媒炒作俄可能“割光缆” 担心俄或借此反制西方"
}
}
]
}
}
字典配置
ik配置文件位于config文件夹中,具体位置就像下面这样。

- IKAnalyzer.cfg.xml:用来配置自定义词库
- main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些词语,都会被分在一起
- quantifier.dic:放了一些计量单位相关的词
- suffix.dic:放了一些后缀
- surname.dic:中国的姓氏
- stopword.dic:英文停用词,会在分词的时候,直接被忽略,不会建立在倒排索引中
自定义词库
可能在ik的原生词典里,对一些新生的流行语并没有,比如尬聊、蓝瘦香菇、中二病、斜杠青年。那么就需要我们自己建立词库了。
在IKAnalyzer.cfg.xml配置文件中,配置我们自定义字典的路径。

在mydict.dic文件中写入想要扩展的词语:
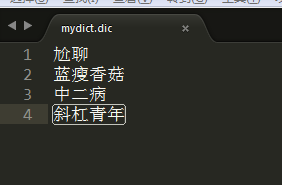
重启elasticsearch,测试一下生效否:
GET /blog/_analyze
{
"text": "蓝瘦香菇",
"analyzer": "ik_max_word"
}
返回结果如下:
{
"tokens": [
{
"token": "蓝瘦香菇",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 0
},
{
"token": "香菇",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}
]
}
可见,我们扩展的词语生效了。
热更新 IK 分词使用方法
每次都是在elasticsearch的扩展词典中,手动添加新词语,弊端很多,比如:
- 每次添加完,都要重启es才能生效,非常麻烦
- es是分布式的,可能有数百个节点,总不能每次都一个一个节点上面去修改
热更新就是不需要elasticsearch重启,直接我们在外部某个地方添加新的词语,elasticsearch中立即热加载到这些新词语。
具体方式直接看官方这里吧。
elasticsearch之分词插件使用的更多相关文章
- ElasticSearch(三) ElasticSearch中文分词插件IK的安装
正因为Elasticsearch 内置的分词器对中文不友好,会把中文分成单个字来进行全文检索,所以我们需要借助中文分词插件来解决这个问题. 一.安装maven管理工具 Elasticsearch 要使 ...
- ElasticSearch 中文分词插件ik 的使用
下载 IK 的版本要与 Elasticsearch 的版本一致,因此下载 7.1.0 版本. 安装 1.中文分词插件下载地址:https://github.com/medcl/elasticsearc ...
- Windows10安装Elasticsearch IK分词插件
安装插件 cmd切换到Elasticsearch安装目录下 C:\Users\Administrator>D: D:\>cd D:\Program Files\Elastic\Elasti ...
- elasticsearch安装分词插件
在常用的中文分词器.拼音分词器.繁简体转换插件.国内用的就多的分别是:elasticsearch-analysis-ikelasticsearch-analysis-pinyinelasticsear ...
- ElasticSearch(四) ElasticSearch中文分词插件IK的简单测试
先来一个简单的测试 # curl -XPOST "http://192.168.9.155:9200/_analyze?analyzer=standard&pretty" ...
- Elasticsearch1.x 和Elasticsearch2.x 拼音分词插件lc-pinyin安装教程
Elasticsearch1.x 基于lc-pinyin和ik分词实现 中文.拼音.同义词搜索 https://blog.csdn.net/chennanymy/article/category/60 ...
- elasticsearch分词插件的安装
IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Luen ...
- Elasticsearch安装ik中文分词插件(四)
一.IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Lu ...
- 在ElasticSearch中使用 IK 中文分词插件
我这里集成好了一个自带IK的版本,下载即用, https://github.com/xlb378917466/elasticsearch5.2.include_IK 添加了IK插件意味着你可以使用ik ...
随机推荐
- KL散度
摘自: https://www.jianshu.com/p/43318a3dc715?from=timeline&isappinstalled=0 一.解决的问题 量化两种概率分布P和Q可以使 ...
- JAVA进阶8
间歇性混吃等死,持续性踌躇满志系列-------------第8天 1.遍历输出HashSet中的全部元素 import java.util.HashSet; import java.util.Ite ...
- Django之Xadmin
零.预备知识 单例对象 方式一:__new__方法 方式二:模块导入,只要在引入的文件中实例了这个对象,不管引道哪里,这个对象都指向同一个内存空间 class My_singleton(object) ...
- workqueue --最清晰的讲解【转】
转自:https://www.cnblogs.com/zxc2man/p/6604290.html 带你入门: 1.INIT_WORK(struct work_struct *work, void ( ...
- 在Linux中调试段错误(core dumped)
在Linux中调试段错误(core dumped) 在作比赛的时候经常遇到段错误, 但是一般都采用的是printf打印信息这种笨方法,而且定位bug比较慢,今天尝试利用gdb工具调试段错误. 段错误( ...
- css 初始化样式
@charset "UTF-8"; /* reset */ html,body,div,h1,h2,h3,h4,h5,h6,p,dl,dt,dd,ol,ul,li,fieldset ...
- RSF 分布式 RPC 服务框架的分层设计
RSF 是个什么东西? 一个高可用.高性能.轻量级的分布式服务框架.支持容灾.负载均衡.集群.一个典型的应用场景是,将同一个服务部署在多个Server上提供 request.response 消息通知 ...
- youtube-dl下载youtube视频时查看分辨率以及选择分辨率下载
1.查看分辨率: youtube-dl -F https://www.youtube.com/watch?v=_NMf1TpiFwY 2.根据分辨率下载,比如下载1280*720的mp4,前面的数字是 ...
- docker 安装mysql数据库 <二>
一.下载mysql数据库 #网易镜像中心https://c.163.com/hub#/m/home/ #采用网易加速地址,不加速时下载非常的慢 docker pull hub.c..com/libra ...
- VICA 架构设计
本文记录最近完成的一个通用实时通信客户端的架构. 背景 我们公司是做税务相关的软件,有针对大客户 MIS 系统,也有针对中小客户的 SaaS 平台.这些系统虽然都是 B/S 的,但是也需要使用 Act ...