初学者易上手的SSH-hibernate04 一对一 一对多 多对多
这章我们就来学习下hibernate的关系关联,即一对一(one-to-one),一对多(one-to-many),多对多(many-to-many)。这章也将是hibernate的最后一章了,用于初学者可以了。
首先讲述一对一:就以一个人对应一张身份证为列子。
第一步:新建表 persion(人)与card(身份证) 表结构如下 两个pid都给的varchar是为了在主键生成策略中使用uuid
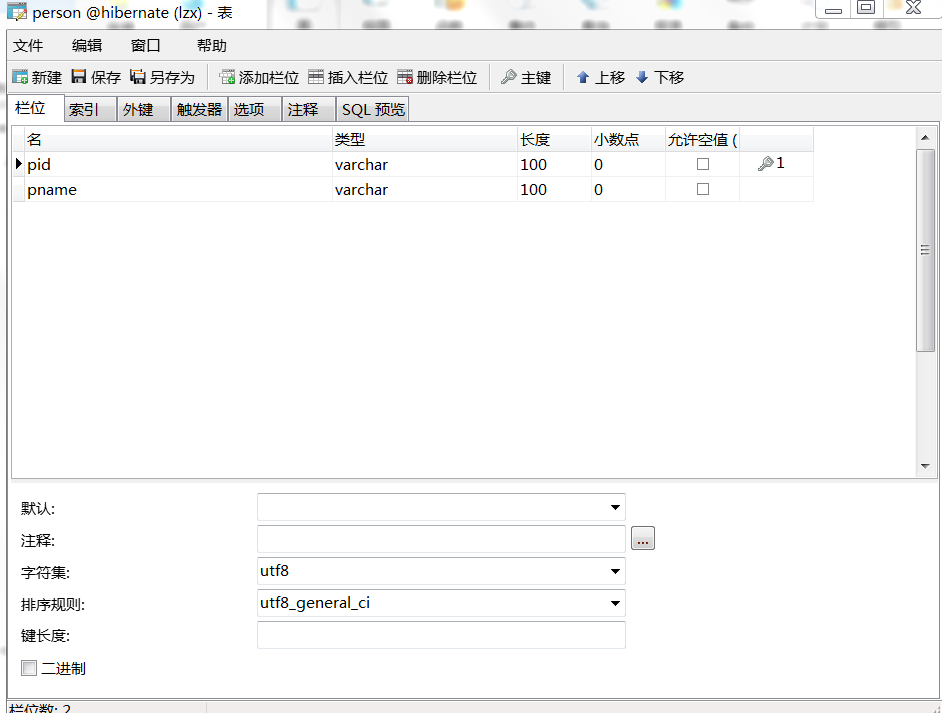

第二步:项目/com.entity下新建两个实体类,与数据库对应,然后封装构造,有参构造中去掉pid。建好后再新建这两个类的hbm.xml文件,在persion.hbm.xml中将<id/>节点中的主键生成策略改成uuid
<id name="pid" type="java.lang.String">
<column name="PID" />
//改uuid
<generator class="uuid" />
</id>
将card.hbm.xml中的<id/>节点中的主键生成策略改成foreign,等于外键的意思
<id name="pid" type="java.lang.String">
<column name="PID" />
<!-- 主键生成策略 改成外键 -->
<generator class="foreign">
</generator>
</id>
第三步:就要开始建立一对一关系了:先在persion实体类中定义一个card的对象,记住不要实例化(new),然后封装。
private Card card;
public Card getCard() {
return card;
} public void setCard(Card card) {
this.card = card;
}
接着在card实体类中定义一个persion的对象,也不要实例化(new),然后封装。
private Person person;
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
第四步:就要开始建立一对关系的配置了。在persion.hbm.xml<class/>节点中添加<one-to-one/>节点;其中name属性值为persion实体类中定义的card对象的变量名。
<one-to-one name="card" class="com.entity.Card" cascade="all"></one-to-one>
在card.hbm.xml<class/>节点中添加<one-to-one/>节点;其中name属性值为card实体类中定义的persion对象的变量名。
<one-to-one name="person" class="com.entity.Person"></one-to-one>
还要在card.hbm.xml主键生成策略中添加一个参数<param/>,其中name属性值为固定写法,persion为card实体类中定义的persion对象的变量名。
<id name="pid" type="java.lang.String">
<column name="PID" />
<!-- 主键生成策略 改成外键 -->
<generator class="foreign">
<param name="property">person</param>
</generator>
</id>
配置到这里就完了。那么有人肯定会有疑问?
persion.hbm.xml 中的<one-to-one/>中cascade="all"是什么意思?
cascade这个属性就相当与两张表的关联属性,有以下属性值
none:所有情况下均不进行关联操作。这是默认值。
all:所有情况下均进行关联操作
save-update:在执行save/update/saveOrUpdate时进行关联操作。
delete:在执行delete时进行关联操作。
all-delete-orphan:当对象图中产生孤儿节点时,在数据库中删除该节点
就拿delete来说吧,就是删除persion的对象数据时,对应的card对象数据也将被删除。
第五步:hibernate.cfg.xml配置文件中加上实体类.hbm.xml的映射关系<mapping/>
<mapping resource="com/entity/Card.hbm.xml" />
<mapping resource="com/entity/Person.hbm.xml" />
第六步:就要开始测试了:建立一个测试类,其中写个junit的@Test测试方法。
既然用了@Tset,那么就在再用下@Before(方法执行之前触发)与@Aafter(方法执行之后触发),这样我们就可以将重复的代码写在这两个方法里面,减轻代码量
private Configuration configuration; private SessionFactory factory;
private Session session;
private Transaction transaction;
@Before
public void Before() {
configuration = new Configuration().configure();
factory = configuration.buildSessionFactory();
session = factory.openSession();
transaction = session.beginTransaction();
}
@After
public void after() {
// 关闭seeion
session.close();
// 关闭SessionFactory
factory.close();
}
增加:注意要互相添加值(互设)
@Test
public void add() {
// 增加
Person p = new Person("哈哈");
Card c = new Card("431088192215523305");
互设
p.setCard(c);
c.setPerson(p);
//这里因为建立cascade关联关系,所以只要添加设立了关系那端即可
session.save(p);
transaction.commit();
}
查询:
// 查询
Person p = session.get(Person.class,
"4028abee5f2a0142015f2a0144280000");
System.out.println(p+"--"+p.getCard());
其余我就不再测试了。
接下来讲述一对多:以一个省份对应多个城市为例子。
第一步:一样要新建两张表,province(省份)与城市(city),表结构如下:

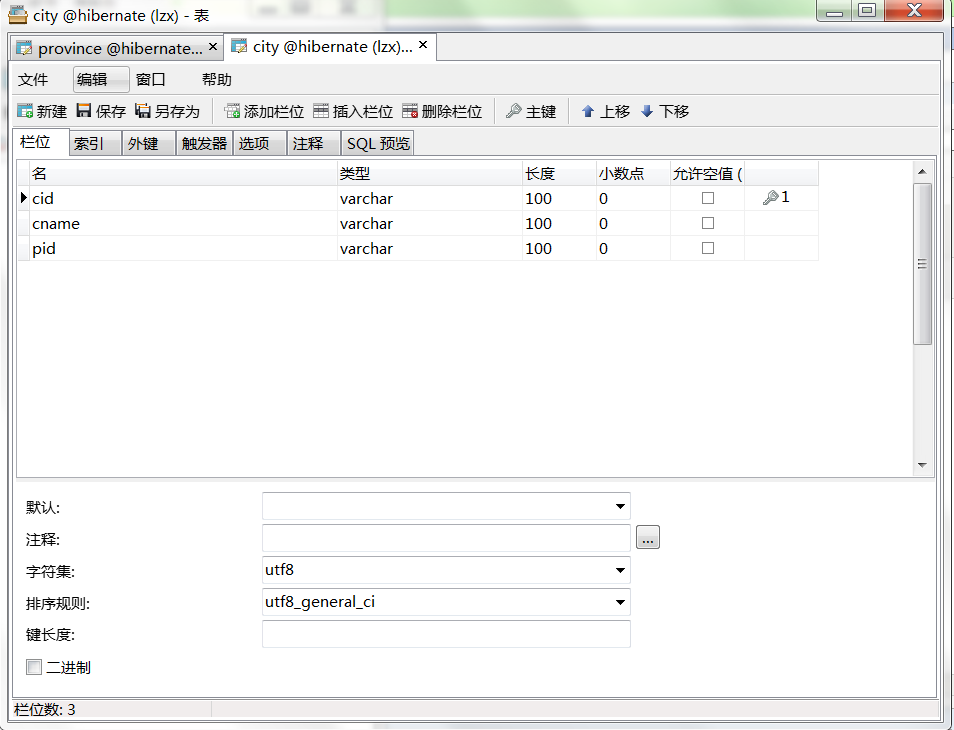
第二步:项目/com.entity下新建两个实体类,与数据库对应,然后封装构造,有参构造中去掉表主键。建好后再新建这两个类的hbm.xml文件,在province.hbm.xml与city.hbm.xml中将<id/>节点中的主键生成策略改成uuid。
第三步:在province(一端)实体类中定义并实例化city(多端)的集合,(set与list)以set为例。然后封装即可。
private Set<City> cities = new HashSet<>();
public Set<City> getCities() {
return cities;
}
public void setCities(Set<City> cities) {
this.cities = cities;
}
第四步:在city(多端)实体类中定义province(一端)对象,封装。注意:这个时候要将pid(多端表中一端表外键)这个属性在city的实体类中去掉(数据库表中依然存在),因为已经定义的province的对象,同时请将city.hbm.xml中所对应生成pid的<property/>节点也去掉!
private Province province;
public Province getProvince() {
return province;
}
public void setProvince(Province province) {
this.province = province;
}
第五步:在一端的hbm.xml中<class/>节点中添加如下代码:
<!--name 一端类中定义多端的集合名 table 表名 -->
<set name="cities" table="city" inverse="true" cascade="save-update">
<key>
<!-- 一端(province)主键名 -->
<column name="pid" />
</key>
<!-- 多端类(city)全限定名 -->
<one-to-many class="com.entity.City" />
</set>
在多端的hbm.xml中<class/>节点中添加如下代码:
<!--name="多端类中定义一端的集合名" class="一端类全限定名" -->
<many-to-one name="province" class="com.entity.Province">
<!-- 多端表中外键名(一端主键名) -->
<column name="pid" />
</many-to-one>
第六步:hibernate.cfg.xml配置文件中加上实体类.hbm.xml的映射关系<mapping/>
<mapping resource="com/entity/Province.hbm.xml" />
<mapping resource="com/entity/City.hbm.xml" />
这样配置就可以了,那么疑问又来了?在一端的hbm.xml<set/>中inverse又是什么?
Inverse:负责控制关系,默认为false,也就是关系的两端都能控制,但这样会造成一些问题,更新的时候会因为两端都控制关系,于是重复更新。一般来说有一端要设为true。那么SQL语句的维护关系就在多端进行操作。
第七步:测试:@Test就与一对一的测试方法一样即可
增加:
Province p = new Province("湖南");
City c = new City("长沙");
City c1 = new City("株洲");
City c2 = new City("湘潭");
//互设
p.getCities().add(c);
p.getCities().add(c1);
p.getCities().add(c2);
c.setProvince(p);
c1.setProvince(p);
c2.setProvince(p);
session.save(p);
transaction.commit();
查询:
City c = (City) session.createQuery("from City where cname=?").setParameter(, "长沙").uniqueResult();
System.out.println(c.getProvince().getPid());
其余的方法就不测试了。
最后讲述多对多:就以多个角色对应多个权限,多个权限对应多个角色为例子:
第一步:还是老样子建表:角色表(users),权限表(role),还要一张中间表(users_role),表结构如下:

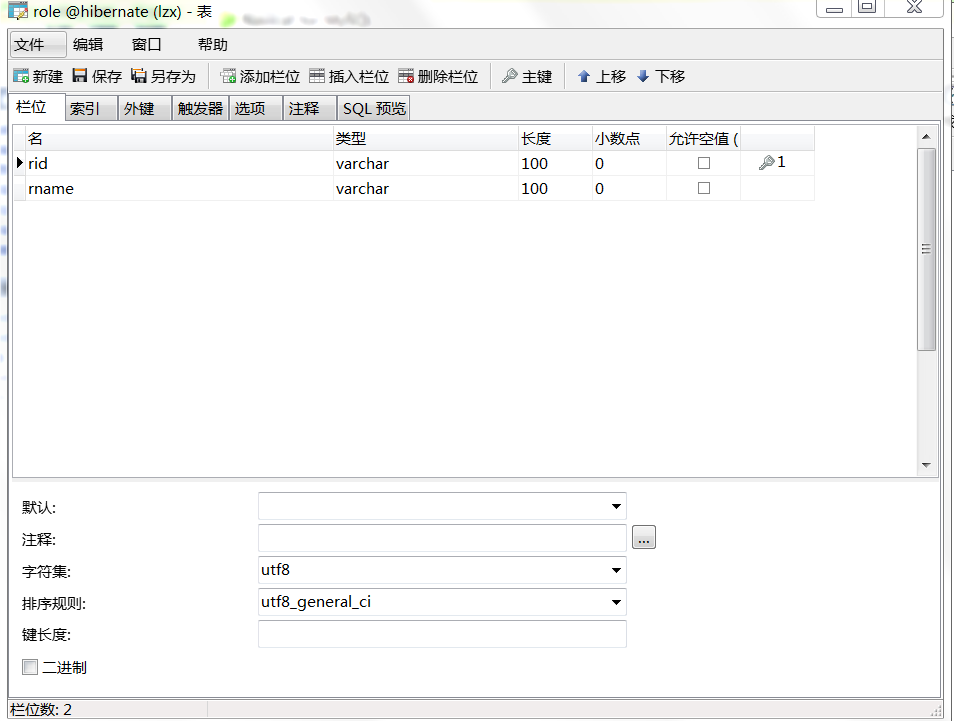
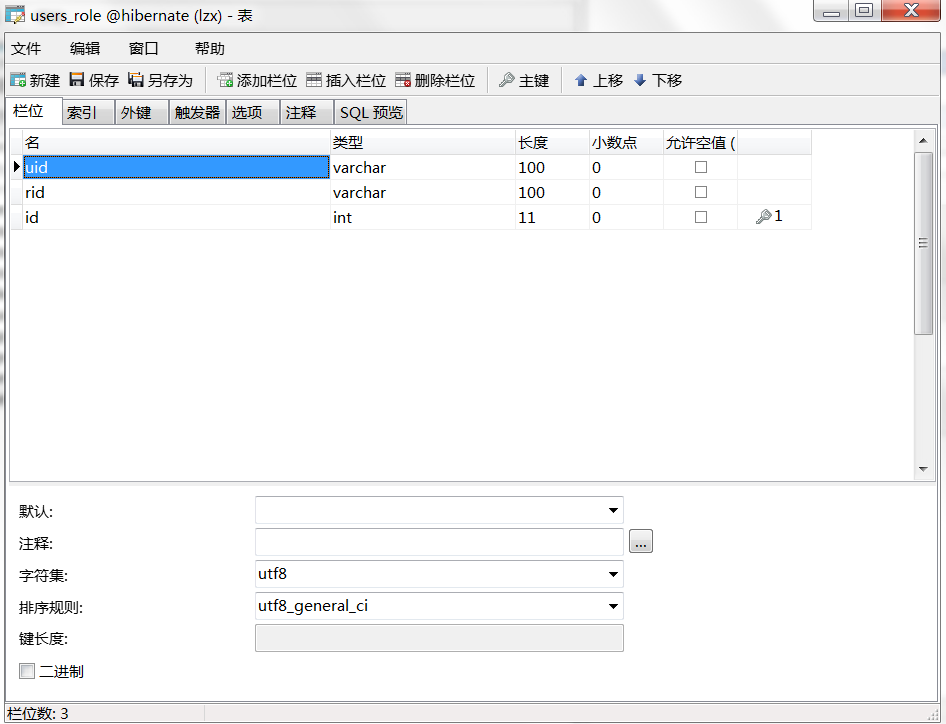
第二步:项目/com.entity下新建两个实体类,中间表不用,与数据库对应,然后封装构造,有参构造中去掉表主键。建好后再新建这两个类的hbm.xml文件,在hbm.xml中将<id/>节点中的主键生成策略改成uuid。
第三步:在这两个实体类中定义并实例化对方的集合,(set与list)以set为例。然后封装即可。
第四步:在users.hbm.xml中添加如下代码:
//name=集合对象名 table=中间表名
<set name="roles" table="users_role" inverse="true" cascade="save-update">
//该类主键名
<key column="uid"></key>
//calss set集合中对象的全路径名 column外键名(set集合中对象的主键名)
<many-to-many class="com.entity.Role" column="rid" />
</set>
在role.hbm.xml中添加如下代码:
//name=集合对象名 table=中间表名
<set name="users" table="users_role" inverse="true" cascade="save-update">
//该类主键名
<key column="rid"></key>
//calss set集合中对象的全路径名 column外键名(set集合中对象的主键名)
<many-to-many class="com.entity.Users" column="uid" />
</set>
第六步:hibernate.cfg.xml配置文件中加上实体类.hbm.xml的映射关系<mapping/>
<mapping resource="com/entity/Users.hbm.xml" />
<mapping resource="com/entity/role.hbm.xml" />
最后测试:
增加:
Users u = new Users("哈哈");
Role r = new Role("草鸡管理员");
Role r1 = new Role("普通管理员");
Role r2 = new Role("垃圾管理员");
u.getRoles().add(r);
u.getRoles().add(r1);
u.getRoles().add(r2);
r.getUsers().add(u);
r1.getUsers().add(u);
r2.getUsers().add(u);
transaction.commit();
查询:
Users s = session.get(Users.class, "4028abee5f664493015f6644959b0001");
for (Role r : s.getRoles()) {
System.out.println(r);
}
//List<Users> ls = session.createQuery("from Users u left outer join fetch u.roles r where r.rid='4028abee5f664493015f6644958a0000'").list();
// for (Users users : ls) {
// System.out.println(users.getRoles());
// }
到此,hibernate结束!
初学者易上手的SSH-hibernate04 一对一 一对多 多对多的更多相关文章
- JPA级联(一对一 一对多 多对多)注解【实际项目中摘取的】并非自己实际应用
下面把项目中的用户类中有个:一对一 一对多 多对多的注解对应关系列取出来用于学习 说明:项目运行正常 问题类:一对多.一对一.多对多 ============一对多 一方的设置 @One ...
- Python进阶----表与表之间的关系(一对一,一对多,多对多),增删改查操作
Python进阶----表与表之间的关系(一对一,一对多,多对多),增删改查操作,单表查询,多表查询 一丶表与表之间的关系 背景: 由于如果只使用一张表存储所有的数据,就会操作数 ...
- mybatis 一对一 一对多 多对多
一对一 一对多 多对多
- 使用NHibernate(7)-- 一对一 && 一对多 && 多对多
1, 一对一. 对于数据量比较大的时候,考虑查询的性能,肯能会把一个对象的属性分到两个表中存放:比如用户和用户资料,经常使用的一般是Id和用户名,用户资料(学校,籍贯等)是不经常被查询的,所以就会分成 ...
- day 69-70 一对一 一对多 多对一联表查询
day 69 orm操作之表关系,多对多,多对一 多对一/一对多, 多对多{类中的定义方法} day69 1. 昨日内容回顾 1. 单表增删改查 2. 单表查询API 返回QuerySet对象的: 1 ...
- JPA 一对一 一对多 多对一 多对多配置
1 JPA概述 1.1 JPA是什么 JPA (Java Persistence API) Java持久化API.是一套Sun公司 Java官方制定的ORM 方案,是规范,是标准 ,sun公司自己并没 ...
- 初学者易上手的SSH-struts2 01环境搭建
首先,SSH不是一个框架,而是多个框架(struts+spring+hibernate)的集成,是目前较流行的一种Web应用程序开源集成框架,用于构建灵活.易于扩展的多层Web应用程序. 集成SSH框 ...
- 初学者易上手的SSH-struts2 05拦截器与自定义拦截器
因为自己对于struts2也不是很了解,这章将是struts2的最后一章了.那么这一章主要介绍的是拦截器以及怎么样来自定义一个拦截器. struts2的拦截器位于struts2-core(核心包)-& ...
- 初学者易上手的SSH-hibernate01环境搭建
这里我们继续学习SSH框架中的另一框架-hibernate.那么hibernate是什么?Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,使得Java程序 ...
随机推荐
- [ROS]激光驱动安装
参考资料: https://blog.csdn.net/hongliang2009/article/details/73302986 https://blog.csdn.net/bohaijun_12 ...
- 微信小程序 下拉加载
在 Page 中定义 onPullDownRefresh 处理函数,监听该页面用户下拉刷新事件. 例: Page({ onPullDownRefresh: function(){ wx.stopPul ...
- 配置成功java11后安装eclipse失败
前提是 1.java是成功配置的, 2.看清楚32bit,还是64bit,需要一致 THEN 方法一:去安装java11之前的版本,正确配置环境 方法二:java11中没有jre(不打紧).所以需要直 ...
- python虚拟环境迁移
python虚拟环境迁移: 注意事项:直接将虚拟环境复制到另一台机器,直接执行是会有问题的. 那么可以采用以下办法: 思路:将机器1虚拟环境下的包信息打包,之后到机器2上进行安装: (有两种情况要考虑 ...
- 5+移动App
1.5+ App开发入门指南 https://www.cnblogs.com/tuyile006/p/5395909.html 2.5+ App开发Native.js入门指南 http://ask.d ...
- docker实战---初级<1>
第1章 docker容器 1.1 什么是容器 容器就是在隔离的环境运行的一个进程,如果进程停止,容器就会销毁.隔离的环境拥有自己的文件系统,ip地址,主机名等 1.2 容器与虚拟化的区别 linux容 ...
- 灵雀云受邀加入VMware 创新网络,共同助力企业数字化进程
11月15日,在VMware主办的“VMware创新网络”2018高峰论坛上,VMware发布了VMware创新网络(VMwareInnovation Network,VIN)的长期发展规划和 ...
- drf 多表
https://www.django-rest-framework.org/ 官方站 https://www.django-rest-framework.org/tutorial/quickstar ...
- Python-----多线程threading用法
threading模块是Python里面常用的线程模块,多线程处理任务对于提升效率非常重要,先说一下线程和进程的各种区别,如图 概括起来就是 IO密集型(不用CPU) 多线程计算密集型(用CPU) 多 ...
- day09-python基础
一.Linux基础 - 计算机以及日后我们开发的程序防止的服务器的简单操作 二.Python开发 a.开发 1.开发语言 高级语言:Python Java.PHP C# Go ruby C++... ...