第十八节、基于传统图像处理的目标检测与识别(HOG+SVM附代码)
其实在深度学习中我们已经介绍了目标检测和目标识别的概念、为了照顾一些没有学过深度学习的童鞋,这里我重新说明一次:目标检测是用来确定图像上某个区域是否有我们要识别的对象,目标识别是用来判断图片上这个对象是什么。识别通常只处理已经检测到对象的区域,例如,人们总是会在已有的人脸图像的区域去识别人脸。
传统的目标检测方法与识别不同于深度学习方法,后者主要利用神经网络来实现分类和回归问题。在这里我们主要介绍如何利用OpecnCV来实现传统目标检测和识别,在计算机视觉中有很多目标检测和识别的技术,这里我们主要介绍下面几块内容:
- 方向梯度直方图HOG(Histogram of Oriented Gradient);
- 图像金字塔;
- 滑动窗口;
上面这三块内容其实后面两块我们之前都已经介绍过,由于内容也比较多,这里不会比较详细详细介绍,下面我们从HOG说起。
一 HOG
HOG特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,是与SIFT、SURF、ORB属于同一类型的描述符。HOG不是基于颜色值而是基于梯度来计算直方图的,它通过计算和统计图像局部区域的梯度方向直方图来构建特征。HOG特征结合SVM分类器已经被广泛应用到图像识别中,尤其在行人检测中获得了极大的成功。
1、主要思想
此方法的基本观点是:局部目标的外表和形状可以被局部梯度或边缘方向的分布很好的描述,即使我们不知道对应的梯度和边缘的位置。(本质:梯度的统计信息,梯度主要存在于边缘的地方)
2、实施方法
首先将图像分成很多小的连通区域,我们把它叫做细胞单元,然后采集细胞单元中各像素点的梯度和边缘方向,然后在每个细胞单元中累加出一个一维的梯度方向直方图。
为了对光照和阴影有更好的不变性,需要对直方图进行对比度归一化,这可以通过把这些直方图在图像的更大的范围内(我们把它叫做区间或者block)进行对比度归一化。首先我们计算出各直方图在这个区间中的密度,然后根据这个密度对区间中的各个细胞单元做归一化。我们把归一化的块描述符叫作HOG描述子。
3、目标检测
将检测窗口中的所有块的HOG描述子组合起来就形成了最终的特征向量,然后使用SVM分类器进行行人检测。下图描述了特征提取和目标检测流程。检测窗口划分为重叠的块,对这些块计算HOG描述子,形成的特征向量放到线性SVM中进行目标/非目标的二分类。检测窗口在整个图像的所有位置和尺度上进行扫描,并对输出的金字塔进行非极大值抑制来检测目标。(检测窗口的大小一般为$128\times{64}$)

二 算法的具体实现
1、图像标准化(调节图像的对比度)
为了减少光照因素的影响,降低图像局部的阴影和光照变化所造成的影响,我们首先采用Gamma校正法对输入图像的颜色空间进行标准化(或者说是归一化)。
所谓的Gamma校正可以理解为提高图像中偏暗或者偏亮部分的图像对比效果,能够有效地降低图像局部的阴影和光照变化。更详细的内容可以点击这里查看图像处理之gamma校正。
Gamma校正公式为:
$$f(I)=I^\gamma$$
其中$I$为图像像素值,$\gamma$为Gamma校正系数。$\gamma$系数设定影响着图像的调整效果,结合下图,我们来看一下Gamma校正的作用:
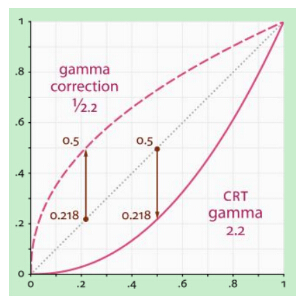
$\gamma<1$在低灰度值区域内,动态范围变大,图像对比度增加强;在高灰度值区域,动态范围变小,图像对比度降低,同时,图像的整体灰度值变大;
$\gamma>1$在低灰度值区域内,动态范围变小,图像对比度降低;在高灰度值区域,动态范围变大,图像对比度提高,同时,图像的整体灰度值变小;

左边的图像为原图,中间图像的$\gamma=\frac{1}{2.2}$,右图$\gamma=2.2$。
作者在他的博士论文里有提到,对于涉及大量的类内颜色变化,如猫,狗和马等动物,没标准化的RGB图效果更好,而牛,羊的图做gamma颜色校正后效果更好。是否用gamma校正得分析具体的训练集情况。
2、图像平滑(具体视情况而定)
对于灰度图像,一般为了去除噪点,所以会先利用高斯函数进行平滑:高斯函数在不同的平滑尺度下对灰度图像进行平滑操作。Dalal等实验表明moving from σ=0 to σ=2 reduces the recall rate from 89% to 80% at 10?4 FPPW,即不做高斯平滑人体检测效果最佳,使得漏检率缩小了约一倍。不做平滑操作,可能原因:HOG特征是基于边缘的,平滑会降低边缘信息的对比度,从而减少图像中的有用信息。
3、边缘方向计算
计算图像每个像素点的梯度、包括方向和大小:
$$G_x(x,y)=I(x+1,y)-I(x-1,y)$$
$$G_y(x,y)=I(x,y+1)-I(x,y-1)$$
上式中$G_x(x,y)、G_y(x,y)$分别表示输入图像在像素点$(x,y)$处的水平方向梯度和垂直方向梯度,像素点在$(x,y)$的梯度幅值和梯度方向分别为:
$$G(x,y)=\sqrt{G_x(x,y)^2+G_y(x,y)^2}$$
$$\alpha=arctan\frac{G_y(x,y)}{G_x(x,y)}$$
4、直方图计算
将图像划分成小的细胞单元(细胞单元可以是矩形的或者环形的),比如大小为$8\times{8}$,然后统计每一个细胞单元的梯度直方图,即可以得到一个细胞单元的描述符,将几个细胞单元组成一个block,例如$2\times{2}$个细胞单元组成一个block,将一个block内每个细胞单元的描述符串联起来即可以得到一个block的HOG描述符。
在说到统计一个细胞单元的梯度直方图时,我们一般考虑采用9个bin的直方图来统计这$8\times{8}$个像素的梯度信息,即将cell的梯度方向0~180°(或0~360°,即考虑了正负)分成9个方向块,如下图所示:
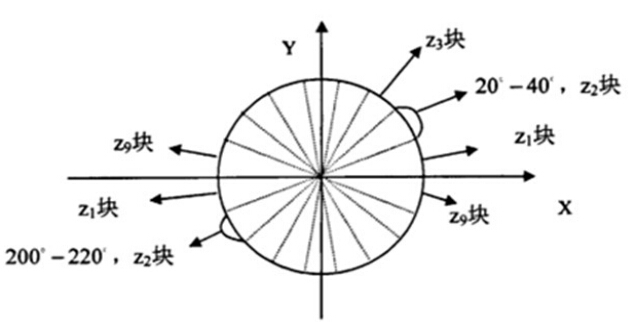
如果cell中某一个像素的梯度方向是20~40°,直方图第2个bin的计数就要加1,这样对cell中的每一个像素用梯度方向在直方图中进行加权投影(权值大小等于梯度幅值),将其映射到对应的角度范围块内,就可以得到这个cell的梯度方向直方图了,就是该cell对应的9维特征向量。对于梯度方向位于相邻bin的中心之间(如20°、40°等)需要进行方向和位置上的双线性插值。
采用梯度幅值量级本身得到的检测效果最佳,而使用二值的边缘权值表示会严重降低效果。采用梯度幅值作为权重,可以使那些比较明显的边缘的方向信息对特征表达影响增大,这样比较合理,因为HOG特征主要就是依靠这些边缘纹理。
根据Dalal等人的实验,在行人目标检测中,在无符号方向角度范围并将其平均分成9份(bins)能取得最好的效果,当bin的数目继续增大效果改变不明显,故一般在人体目标检测中使用bin数目为9范围0~180°的度量方式。
5、对block归一化
由于局部光照的变化,以及前景背景对比度的变化,使得梯度强度的变化范围非常大,这就需要对梯度做局部对比度归一化。归一化能够进一步对光照、阴影、边缘进行压缩,使得特征向量对光照、阴影和边缘变化具有鲁棒性。
具体的做法:将细胞单元组成更大的空间块(block),然后针对每个块进行对比度归一化。最终的描述子是检测窗口内所有块内的细胞单元的直方图构成的向量。事实上,块之间是有重叠的,也就是说,每个细胞单元的直方图都会被多次用于最终的描述子的计算。块之间的重叠看起来有冗余,但可以显著的提升性能 。
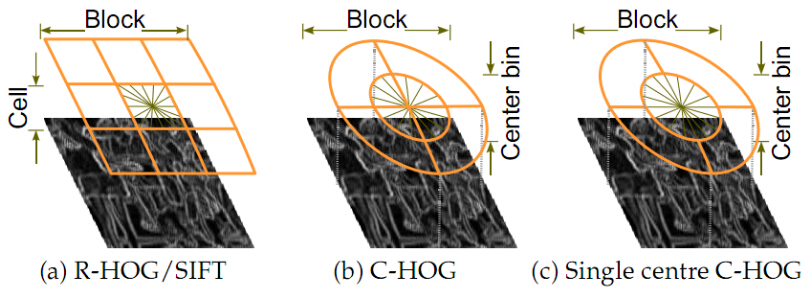
通常使用的HOG结构大致有三种:矩形HOG(简称为R-HOG),圆形HOG和中心环绕HOG。它们的单位都是Block(即块)。Dalal的试验证明矩形HOG和圆形HOG的检测效果基本一致,而环绕形HOG效果相对差一些。
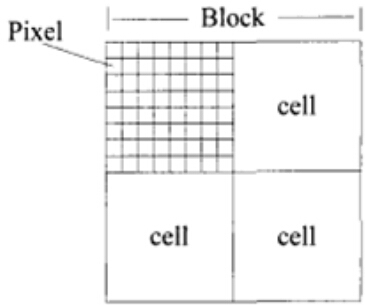
如上图,一个块由$2\times{2}$个cell组成,每一个cell包含$8\times{8}$个像素点,每个cell提取9个直方图通道,因此一个块的特征向量长度为$2\times{2}\times{9}$。
假设$v$是未经归一化的特征向量。 $\|v\|_k$是$v$的$k$范数,$k=1,2$,是一个很小的常数,对块的特征向量进行归一化,一般有以下四种方法:
- $L_2-norm$:$v←\frac{v}{\sqrt{\|v\|_2^2+\xi^2}}$($\xi$是一个很小的数,主要是为了防止分母为0);
- $L_2-Hys$:先计算$L_2$范数,然后限制$v$的最大值为0.2,再进行归一化;
- $L_1-norm$:$v←\frac{v}{|v\|_1+\xi}$;
- $L_1-sqrt$:$v←\sqrt{\frac{v}{\|v\|_1+\xi}}$;
在人体检测系统中进行HOG计算时一般使用$L_2-norm$,Dalal的文章也验证了对于人体检测系统使用$L_2-norm$的时候效果最好。
6、样本HOG特征提取
最后一步就是对一个样本中所有的块进行HOG特征的提取,并将它们结合成最终的特征向量送入分类器。
那么一个样本可以提取多少个特征呢?之前我们已经说过HOG特征的提取过程:
- 首先把样本图片分割为若干个像素的单元,然后把梯度方向划分为9个区间,在每个单元里面对所有像素的梯度方向在各个方向区间进行直方图统计,得到一个9维的特征向量;
- 每相邻4个单元构成一个块,把一个块内的特征向量串联起来得到一个36维的特征向量;
- 用块对样本图像进行扫描,扫描步长为一个单元的大小,最后将所有的块的特征串联起来,就得到一个样本的特征向量;
例如:对于$128\times{64}$的输入图片(后面我所有提到的图像大小指的是$h\times{w}$),每个块由$2\times{2}$个cell组成,每个cell由$8\times{8}$个像素点组成,每个cell提取9个bin大小的直方图,以1个cell大小为步长,那么水平方向有15个扫描窗口,垂直方向有7个扫描窗口,也就是说,一共有$15*7*2*2*9=3780$个特征。
7、行人检测HOG+SVM
这里我们介绍一下Dalal等人的训练方法:
- 提取正负样本的HOG特征;
- 用正负样本训练一个初始的分类器,然后由分类器生产检测器;
- 然后用初始分类器在负样本原图上进行行人检测,检测出来的矩形区域自然都是分类错误的负样本,这就是所谓的难例(hard examples);
- 提取难例的HOG特征并结合第一步中的特征,重新训练,生成最终的检测器 ;
这种二次训练的处理过程显著提高了每个检测器的表现,一般可以使得每个窗口的误报率(FPPW False Positives Per Window)下降5%。
三 手动实现HOG特征
虽然opencv已经实现了HOG算法,但是手动实现的目的是为了加深我们对HOG的理解,本代码参考了博客80行Python实现-HOG梯度特征提取并做了一些调整:
代码主要包括以下步骤:
- 图像灰度化,归一化处理;
- 首先计算图像每一个像素点的梯度幅值和角度;
- 计算输入图像的每个cell单元的梯度直方图(注意,我们在实现梯度直方图的时候,使用到的是双线性插值,这和上面介绍的理论略微有区别),形成每个cell的descriptor,比如输入图像为$128\times{64}$ 可以得到$16\times{8}$个cell,每个cell由9个bin组成;
- 将$2\times{2}$个cell组成一个block,一个block内所有cell的特征串联起来得到该block的HOG特征descriptor,并进行归一化处理,将图像内所有block的HOG特征descriptor串联起来得到该图像的HOG特征descriptor,这就是最终分类的特征向量;
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 24 18:23:04 2018 @author: zy
""" #代码来源GitHub:https://github.com/PENGZhaoqing/Hog-feature
#https://blog.csdn.net/ppp8300885/article/details/71078555
#https://www.leiphone.com/news/201708/ZKsGd2JRKr766wEd.html import cv2
import numpy as np
import math
import matplotlib.pyplot as plt class Hog_descriptor():
'''
HOG描述符的实现
'''
def __init__(self, img, cell_size=8, bin_size=9):
'''
构造函数
默认参数,一个block由2x2个cell组成,步长为1个cell大小
args:
img:输入图像(更准确的说是检测窗口),这里要求为灰度图像 对于行人检测图像大小一般为128x64 即是输入图像上的一小块裁切区域
cell_size:细胞单元的大小 如8,表示8x8个像素
bin_size:直方图的bin个数
'''
self.img = img
'''
采用Gamma校正法对输入图像进行颜色空间的标准化(归一化),目的是调节图像的对比度,降低图像局部
的阴影和光照变化所造成的影响,同时可以抑制噪音。采用的gamma值为0.5。 f(I)=I^γ
'''
self.img = np.sqrt(img*1.0 / float(np.max(img)))
self.img = self.img * 255
#print('img',self.img.dtype) #float64
#参数初始化
self.cell_size = cell_size
self.bin_size = bin_size
self.angle_unit = 180 / self.bin_size #这里采用180°
assert type(self.bin_size) == int, "bin_size should be integer,"
assert type(self.cell_size) == int, "cell_size should be integer,"
assert 180 % self.bin_size == 0, "bin_size should be divisible by 180" def extract(self):
'''
计算图像的HOG描述符,以及HOG-image特征图
'''
height, width = self.img.shape
'''
1、计算图像每一个像素点的梯度幅值和角度
'''
gradient_magnitude, gradient_angle = self.global_gradient()
gradient_magnitude = abs(gradient_magnitude)
'''
2、计算输入图像的每个cell单元的梯度直方图,形成每个cell的descriptor 比如输入图像为128x64 可以得到16x8个cell,每个cell由9个bin组成
'''
cell_gradient_vector = np.zeros((int(height / self.cell_size), int(width / self.cell_size), self.bin_size))
#遍历每一行、每一列
for i in range(cell_gradient_vector.shape[0]):
for j in range(cell_gradient_vector.shape[1]):
#计算第[i][j]个cell的特征向量
cell_magnitude = gradient_magnitude[i * self.cell_size:(i + 1) * self.cell_size,
j * self.cell_size:(j + 1) * self.cell_size]
cell_angle = gradient_angle[i * self.cell_size:(i + 1) * self.cell_size,
j * self.cell_size:(j + 1) * self.cell_size]
cell_gradient_vector[i][j] = self.cell_gradient(cell_magnitude, cell_angle) #将得到的每个cell的梯度方向直方图绘出,得到特征图
hog_image = self.render_gradient(np.zeros([height, width]), cell_gradient_vector) '''
3、将2x2个cell组成一个block,一个block内所有cell的特征串联起来得到该block的HOG特征descriptor
将图像image内所有block的HOG特征descriptor串联起来得到该image(检测目标)的HOG特征descriptor,
这就是最终分类的特征向量
'''
hog_vector = []
#默认步长为一个cell大小,一个block由2x2个cell组成,遍历每一个block
for i in range(cell_gradient_vector.shape[0] - 1):
for j in range(cell_gradient_vector.shape[1] - 1):
#提取第[i][j]个block的特征向量
block_vector = []
block_vector.extend(cell_gradient_vector[i][j])
block_vector.extend(cell_gradient_vector[i][j + 1])
block_vector.extend(cell_gradient_vector[i + 1][j])
block_vector.extend(cell_gradient_vector[i + 1][j + 1])
'''块内归一化梯度直方图,去除光照、阴影等变化,增加鲁棒性'''
#计算l2范数
mag = lambda vector: math.sqrt(sum(i ** 2 for i in vector))
magnitude = mag(block_vector) + 1e-5
#归一化
if magnitude != 0:
normalize = lambda block_vector, magnitude: [element / magnitude for element in block_vector]
block_vector = normalize(block_vector, magnitude)
hog_vector.append(block_vector)
return np.asarray(hog_vector), hog_image def global_gradient(self):
'''
分别计算图像沿x轴和y轴的梯度
'''
gradient_values_x = cv2.Sobel(self.img, cv2.CV_64F, 1, 0, ksize=5)
gradient_values_y = cv2.Sobel(self.img, cv2.CV_64F, 0, 1, ksize=5)
#计算梯度幅值 这个计算的是0.5*gradient_values_x + 0.5*gradient_values_y
#gradient_magnitude = cv2.addWeighted(gradient_values_x, 0.5, gradient_values_y, 0.5, 0)
#计算梯度方向
#gradient_angle = cv2.phase(gradient_values_x, gradient_values_y, angleInDegrees=True)
gradient_magnitude, gradient_angle = cv2.cartToPolar(gradient_values_x,gradient_values_y,angleInDegrees=True)
#角度大于180°的,减去180度
gradient_angle[gradient_angle>180.0] -= 180
#print('gradient',gradient_magnitude.shape,gradient_angle.shape,np.min(gradient_angle),np.max(gradient_angle))
return gradient_magnitude, gradient_angle def cell_gradient(self, cell_magnitude, cell_angle):
'''
为每个细胞单元构建梯度方向直方图 args:
cell_magnitude:cell中每个像素点的梯度幅值
cell_angle:cell中每个像素点的梯度方向
return:
返回该cell对应的梯度直方图,长度为bin_size
'''
orientation_centers = [0] * self.bin_size
#遍历cell中的每一个像素点
for i in range(cell_magnitude.shape[0]):
for j in range(cell_magnitude.shape[1]):
#梯度幅值
gradient_strength = cell_magnitude[i][j]
#梯度方向
gradient_angle = cell_angle[i][j]
#双线性插值
min_angle, max_angle, weight = self.get_closest_bins(gradient_angle)
orientation_centers[min_angle] += (gradient_strength * (1 - weight))
orientation_centers[max_angle] += (gradient_strength *weight)
return orientation_centers def get_closest_bins(self, gradient_angle):
'''
计算梯度方向gradient_angle位于哪一个bin中,这里采用的计算方式为双线性插值
具体参考:https://www.leiphone.com/news/201708/ZKsGd2JRKr766wEd.html
例如:当我们把180°划分为9个bin的时候,分别对应对应0,20,40,...160这些角度。
角度是10,副值是4,因为角度10介于0-20度的中间(正好一半),所以把幅值
一分为二地放到0和20两个bin里面去。
args:
gradient_angle:角度
return:
start,end,weight:起始bin索引,终止bin的索引,end索引对应bin所占权重
'''
idx = int(gradient_angle / self.angle_unit)
mod = gradient_angle % self.angle_unit
return idx % self.bin_size, (idx + 1) % self.bin_size, mod / self.angle_unit def render_gradient(self, image, cell_gradient):
'''
将得到的每个cell的梯度方向直方图绘出,得到特征图
args:
image:画布,和输入图像一样大 [h,w]
cell_gradient:输入图像的每个cell单元的梯度直方图,形状为[h/cell_size,w/cell_size,bin_size]
return:
image:特征图
'''
cell_width = self.cell_size / 2
max_mag = np.array(cell_gradient).max()
#遍历每一个cell
for x in range(cell_gradient.shape[0]):
for y in range(cell_gradient.shape[1]):
#获取第[i][j]个cell的梯度直方图
cell_grad = cell_gradient[x][y]
#归一化
cell_grad /= max_mag
angle = 0
angle_gap = self.angle_unit
#遍历每一个bin区间
for magnitude in cell_grad:
#转换为弧度
angle_radian = math.radians(angle)
#计算起始坐标和终点坐标,长度为幅值(归一化),幅值越大、绘制的线条越长、越亮
x1 = int(x * self.cell_size + cell_width + magnitude * cell_width * math.cos(angle_radian))
y1 = int(y * self.cell_size + cell_width + magnitude * cell_width * math.sin(angle_radian))
x2 = int(x * self.cell_size + cell_width - magnitude * cell_width * math.cos(angle_radian))
y2 = int(y * self.cell_size + cell_width - magnitude * cell_width * math.sin(angle_radian))
cv2.line(image, (y1, x1), (y2, x2), int(255 * math.sqrt(magnitude)))
angle += angle_gap
return image if __name__ == '__main__':
#加载图像
img = cv2.imread('./image/person.jpg')
width = 64
height = 128
img_copy = img[320:320+height,570:570+width][:,:,::-1]
gray_copy = cv2.cvtColor(img_copy,cv2.COLOR_BGR2GRAY) #显示原图像
plt.figure(figsize=(6.4,2.0*3.2))
plt.subplot(1,2,1)
plt.imshow(img_copy) #HOG特征提取
hog = Hog_descriptor(gray_copy, cell_size=8, bin_size=9)
hog_vector, hog_image = hog.extract()
print('hog_vector',hog_vector.shape)
print('hog_image',hog_image.shape) #绘制特征图
plt.subplot(1,2,2)
plt.imshow(hog_image, cmap=plt.cm.gray)
plt.show()
程序运行结果为:
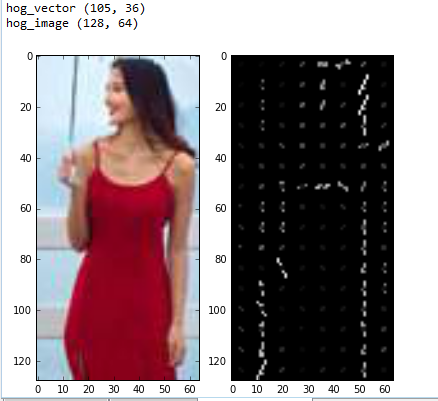
我们可以看到当输入图像大小为$128\times{64}$时,得到的HOG特征向量为$105\times{36}=3780$,这和我们计算的一样,左边的图为需要提取HOG特征的原图,右图为所提取得到的特征图,我们使用线段长度表示每一个cell中每一个bin的幅值大小(同时线段的亮度也与幅值大小成正比),线段倾斜角度表示cell中每一个bin的角度,从右图上我们可以大致观察到这个人的边缘信息以及梯度变化,因此利用该特征可以很容易的识别出人的主要结构。
四 目标检测中的问题
虽然我们已经介绍了HOG特征的提取,但是在想把HOG特征应用到目标检测上,我们还需考虑两个问题:
- 尺度:对于这个问题可以通过举例说明:假如要检测的目标(比如人)是较大图像中的一部分,要把要检测的图像和训练图像比较。如果在比较中找不到一组相同的梯度,则检测就会失败(即使两张图像都有人)。
- 位置:在解决了尺度问题后,还有另一个问题:要检测的目标可能位于图像上的任一个地方,所以需要扫描图像的每一个地方,以取保找到感兴趣的区域,并且尝试在这些区域检测目标。即使待检测的图像中的目标和训练图像中的目标一样大,也需要通过某种方式让opencv定位该目标。
1、图像金字塔
图像金字塔有助于解决不同尺度下的目标检测问题,图像金字塔使图像的多尺度表示,如下图所示:

构建图像金字塔一般包含以下步骤(详细内容可以参考尺度空间理论):
- 获取图像;
- 使用任意尺度的参数来调整(缩小)图像的大小;
- 平滑图像(使用高斯模糊);
- 如果图像比最小尺度还大,从第一步开会重复这个过程;
在人脸检测之Haar分类器这一节我们利用haar特征和级联分类器Adaboost检测人脸时我们使用过一个函数detectMultiScale(),这个函数就涉及这些内容,级联分类器对象尝试在输入图像的不同尺度下检测对象,该函数有一个比较重要的参数scaleFactor(一般设置为1.3),表示一个比率:即在每层金字塔中所获得的图像与上一层图像的比率,scaleFactor越小,金字塔的层数就越多,计算就越慢,计算量也会更大,但是计算结果相对更精确。
下面我们在对人进行检测时候也会再次使用到这个函数。
2、滑动窗口
滑动窗口是用在计算机视觉的一种技术,它包括图像中要移动部分(滑动窗口)的检查以及使用图像金字塔对各部分进行检测。这是为了在多尺度下检测对象。
滑动窗口通过扫描较大图像的较小区域来解决定位问题,进而在同一图像的不同尺度下重复扫描。
使用这种方法进行目标检测会出现一个问题:区域重叠,针对区域重叠问题,我们可以利用非极大值抑制(详细内容可以参考第二十七节,IOU和非极大值抑制),来消除重叠的窗口。
五 使用opencv检测人
下面我们介绍使用OpenCV自带的HOGDescriptor()函数对人进行检测:
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 24 16:43:37 2018 @author: zy
""" '''
HOG检测人
'''
import cv2
import numpy as np def is_inside(o,i):
'''
判断矩形o是不是在i矩形中 args:
o:矩形o (x,y,w,h)
i:矩形i (x,y,w,h)
'''
ox,oy,ow,oh = o
ix,iy,iw,ih = i
return ox > ix and oy > iy and ox+ow < ix+iw and oy+oh < iy+ih def draw_person(img,person):
'''
在img图像上绘制矩形框person args:
img:图像img
person:人所在的边框位置 (x,y,w,h)
'''
x,y,w,h = person
cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,255),2) def detect_test():
'''
检测人
'''
img = cv2.imread('./image/person.jpg')
rows,cols = img.shape[:2]
sacle = 1.0
#print('img',img.shape)
img = cv2.resize(img,dsize=(int(cols*sacle),int(rows*sacle)))
#print('img',img.shape) #创建HOG描述符对象
#计算一个检测窗口特征向量维度:(64/8 - 1)*(128/8 - 1)*4*9 = 3780
'''
winSize = (64,128)
blockSize = (16,16)
blockStride = (8,8)
cellSize = (8,8)
nbins = 9
hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins)
'''
hog = cv2.HOGDescriptor()
#hist = hog.compute(img[0:128,0:64]) 计算一个检测窗口的维度
#print(hist.shape)
detector = cv2.HOGDescriptor_getDefaultPeopleDetector()
print('detector',type(detector),detector.shape)
hog.setSVMDetector(detector) #多尺度检测,found是一个数组,每一个元素都是对应一个矩形,即检测到的目标框
found,w = hog.detectMultiScale(img)
print('found',type(found),found.shape) #过滤一些矩形,如果矩形o在矩形i中,则过滤掉o
found_filtered = []
for ri,r in enumerate(found):
for qi,q in enumerate(found):
#r在q内?
if ri != qi and is_inside(r,q):
break
else:
found_filtered.append(r) for person in found_filtered:
draw_person(img,person) cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows() if __name__=='__main__':
detect_test()
输出如下:

其中有一点我们需要注意,opencv自带的检测器大小是3781维度的,这是因为在默认参数下,我们从$128\times{64}$的检测窗口中提取的特征向量为3780维度,而我们的检测器采用的是支持向量机,最终的检测方法是基于线性判别函数$wx+b=0$。在训练检测器时,当把特征维度为3780的特征送到SVM中训练,得到的$w$维度也为3780,另外还有一个偏置$b$,因此检测器的维度为3781。
detector = cv2.HOGDescriptor_getDefaultPeopleDetector()
print('detector',type(detector),detector.shape)
另外我在啰嗦一下:在训练的时候,我们的正负样本图像默认大小都应该是$128\times{64}$的,然后提取样本图像的HOG特征,也就是3780维度的特征向量,送入到SVM进行训练,最终的目的就是得到这3781维度的检测器。
在测试的时,检测窗口(大小为$128\times{64}$)在整个图像的所有位置和尺度上进行扫描,然后提取提取每一个窗口的HOG特征,送入检测器进行判别,最后还需要对输出的金字塔进行非极大值抑制。例如:这里有张图是$720\times{475}$的,我们选$200\times{100}$大小的patch,把这个patch从图片里面抠出来,然后再把大小调整成$128\times{64}$,计算HOG特征,并送入检测器判别是否包含目标。

但是当我们想检测其他目标时,比如一辆车这时候高与宽的比可能就不是2:1了,这时候我们就需要修改HOG对象的配置参数:
#计算一个检测窗口特征向量维度:(64-8)/8*(128-8)/8*4*9 = 3780
winSize = (64,128)
blockSize = (16,16)
blockStride = (8,8)
cellSize = (8,8)
nbins = 9
hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins)
上面的是默认参数,针对不同的目标检测我们一般需要修改为适合自己目标大小的参数:
- winSize:检查窗口大小,一般为blockStride的整数倍;
- blockSize:块大小,一般为cellSize的整数倍;
- blockStride:块步长,一般为cellSize的整数倍;
- cellSize:每一个细胞单元大小;
- nbins:每一个细胞单元提取的直方图bin的个数;
计算公式:
沿$x$轴块的个数$m = [(winSize_x - blockSize_x)/blockStride_x+1]$向下取整;
沿$y$轴块的个数$n = [(winSize_y - blockSize_y)/blockStride_x+1]$向下取整;
一个block内的特征向量维度为$c = (blockSize_x/cellSize_x) * (blockSize_y/cellSize_y)*nbins$;
那么特征向量维度 $t = m*n* c$
我们再来形象的说明检测窗口的特征向量维度是如何计算的,因为这个很重要:

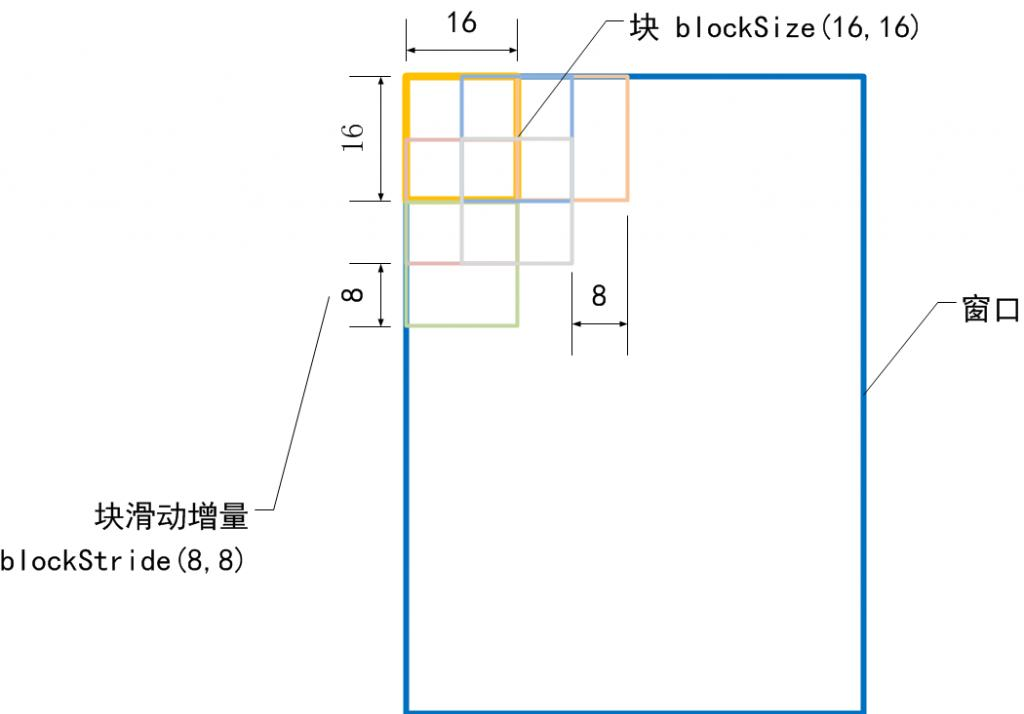
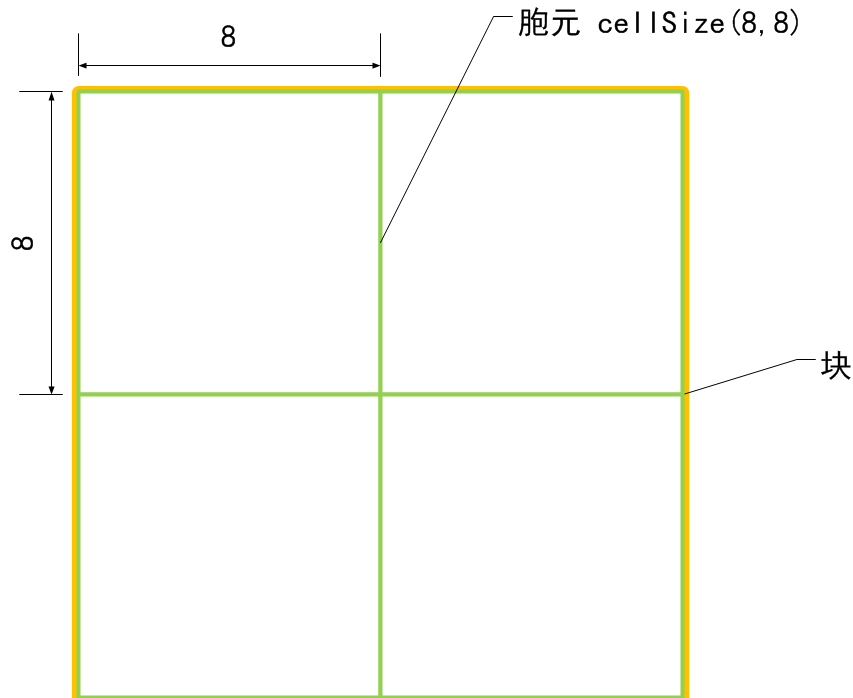
看明白了吧?如果再不明白,那你再看看上面的原理吧!!!!!
六 总结
HOG的优点:
- 核心思想是所检测的局部物体外形能够被梯度或边缘方向的分布所描述,HOG能较好地捕捉局部形状信息,对几何和光学变化都有很好的不变性;
- HOG是在密集采样的图像块中求取的,在计算得到的HOG特征向量中隐含了该块与检测窗口之间的空间位置关系。
HOG的缺陷:
- 很难处理遮挡问题,人体姿势动作幅度过大或物体方向改变也不易检测(这个问题后来在DPM中采用可变形部件模型的方法得到了改善);
- 跟SIFT相比,HOG没有选取主方向,也没有旋转梯度方向直方图,因而本身不具有旋转不变性(较大的方向变化),其旋转不变性是通过采用不同旋转方向的训练样本来实现的;
- 跟SIFT相比,HOG本身不具有尺度不变性,其尺度不变性是通过缩放检测窗口图像的大小来实现的;
- 此外,由于梯度的性质,HOG对噪点相当敏感,在实际应用中,在block和cell划分之后,对于得到各个区域,有时候还会做一次高斯平滑去除噪点。
参考文章:
[3]HOG:用于人体检测的梯度方向直方图 Histograms of Oriented Gradients for Human Detection(原文翻译)
[4]HOG特征(Histogram of Gradient)学习总结
[8]图像学习之如何理解方向梯度直方图(Histogram Of Gradient)
[10]OpenCV 3计算机视觉
第十八节、基于传统图像处理的目标检测与识别(HOG+SVM附代码)的更多相关文章
- 第十九节、基于传统图像处理的目标检测与识别(词袋模型BOW+SVM附代码)
在上一节.我们已经介绍了使用HOG和SVM实现目标检测和识别,这一节我们将介绍使用词袋模型BOW和SVM实现目标检测和识别. 一 词袋介绍 词袋模型(Bag-Of-Word)的概念最初不是针对计算机视 ...
- 【目标检测】基于传统算法的目标检测方法总结概述 Viola-Jones | HOG+SVM | DPM | NMS
"目标检测"是当前计算机视觉和机器学习领域的研究热点.从Viola-Jones Detector.DPM等冷兵器时代的智慧到当今RCNN.YOLO等深度学习土壤孕育下的GPU暴力美 ...
- #Deep Learning回顾#之基于深度学习的目标检测(阅读小结)
原文链接:https://www.52ml.net/20287.html 这篇博文主要讲了深度学习在目标检测中的发展. 博文首先介绍了传统的目标检测算法过程: 传统的目标检测一般使用滑动窗口的框架,主 ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN,Faster R-CNN
基于深度学习的目标检测技术演进:R-CNN.Fast R-CNN,Faster R-CNN object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.obj ...
- 带你了解CANN的目标检测与识别一站式方案
摘要: 了解通用目标检测与识别一站式方案的功能与特性,还有实现流程,以及可定制点. 本文分享自华为云社区<玩转CANN目标检测与识别一站式方案>,作者: Tianyi_Li. 背景介绍 目 ...
- OpenCV 学习笔记 07 目标检测与识别
目标检测与识别是计算机视觉中最常见的挑战之一.属于高级主题. 本章节将扩展目标检测的概念,首先探讨人脸识别技术,然后将该技术应用到显示生活中的各种目标检测. 1 目标检测与识别技术 为了与OpenCV ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- (转)基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
随机推荐
- PJSUA2开发文档--第九章 PJSUA2应用程序示例
9. PJSUA2示例应用程序 9.1 示例应用程序 9.1.1 C++ pjsip-apps/src/samples/pjsua2_demo.cpp 是一个非常简单可用的C++示例应用程序. /* ...
- MVC文件的上传、删除
public ActionResult FileUpload() { Users users = new Users(); users = ( ...
- Python生成器、推导式之前襟后裾
生成器 函数体内有yield选项的就是生成器,生成器的本质是迭代器,由于函数结构和生成器结构类似,可以通过调用来判断是函数还是生成器,如下: def fun(): yield "我是生成器& ...
- CADisplayLink以及定时器的使用
第一种: 用CADisplayLink可以实现不停重绘. - (CADisplayLink *)link { if (!_link) { // 创建定时器,一秒钟调用rotation方法60次 _li ...
- .NET CORE学习笔记系列(3)——ASP.NET CORE多环境标识
在开发项目的过程当中,生产环境与调试环境的配置是不一样的.比如连接字符串. ASP .NET CORE 支持利用环境变量来动态配置 JSON 文件.ASP.NET Core 引用了一个特定的环境变量 ...
- Blink: How Alibaba Uses Apache Flink
This is a guest post from Xiaowei Jiang, Senior Director of Alibaba’s search infrastructure team. Th ...
- Kafka集成Kerberos之后如何使用生产者消费者命令
1.生产者1.1.准备jaas.conf并添加到环境变量(使用以下方式的其中一种)1.1.1.使用Kinit方式前提是手动kinit 配置内容为: KafkaClient { com.sun.secu ...
- 在虚拟机中,设置centos7静态ip
https://blog.csdn.net/qq_34182808/article/details/80065908
- R语言学习——实例标识符
> patientID<-c(1,2,3,4)> age<-c(25,34,28,52)> diabetes<-c("Type1"," ...
- 【转】Android调用Sqlite数据库时自动生成db-journal文件的原因
数据库为了更好实现数据的安全性,一半都会有一个Log文件方便数据库出现意外时进行恢复操作等.Sqlite虽然是一个单文件数据库,但麻雀虽小五脏俱全,它也会有相应的安全机制存在 这个journal文件便 ...