并发容器学习—ConcurrentSkipListMap与ConcurrentSkipListSet 原

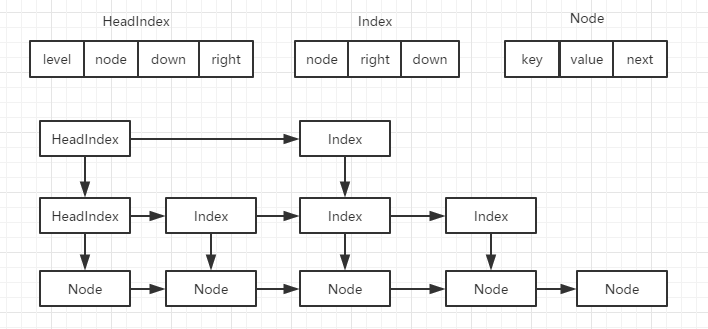
static final class Node<K,V> {
final K key; //存储键
volatile Object value; //存储值
volatile Node<K,V> next; //下个结点
Node(K key, Object value, Node<K,V> next) {
this.key = key;
this.value = value;
this.next = next;
}
Node(Node<K,V> next) {
this.key = null;
this.value = this;
this.next = next;
}
//不安全的操作变量,用于实现CAS操作
private static final sun.misc.Unsafe UNSAFE;
//value的内存地址偏移量
private static final long valueOffset;
//下个结点的内存地址偏移量
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
valueOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("value"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
static class Index<K,V> {
final Node<K,V> node; //链表中结点的引用
final Index<K,V> down; //指向下一层的Index索引
volatile Index<K,V> right; //右边的索引
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
//不安全的操作变量
private static final sun.misc.Unsafe UNSAFE;
private static final long rightOffset; //right的内存偏移量
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Index.class;
rightOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("right"));
} catch (Exception e) {
throw new Error(e);
}
}
}static final class HeadIndex<K,V> extends Index<K,V> {
final int level; //层级索引
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}
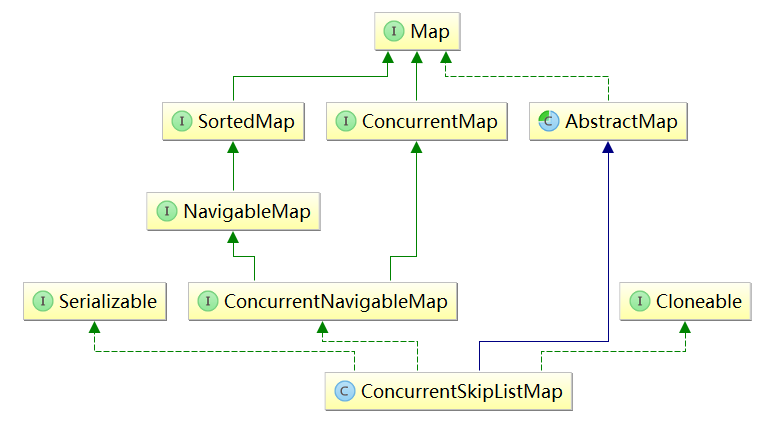
public interface ConcurrentNavigableMap<K,V>
extends ConcurrentMap<K,V>, NavigableMap<K,V>
{
//返回当前map的子map,即将fromKey到toKey的子集合截取出来,fromInclusive和toInclusive
//表示子集合中是否包含fromKey和toKey这两个临界键值对
ConcurrentNavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive);
//返回不大于toKey的子集合,是否包含toKey由inclusive决定
ConcurrentNavigableMap<K,V> headMap(K toKey, boolean inclusive);
//返回不小于fromKey的子集合,是否包含fromKey由inclusive决定
ConcurrentNavigableMap<K,V> tailMap(K fromKey, boolean inclusive);
//返回大约fromKey,且小于等于toKey的子集合
ConcurrentNavigableMap<K,V> subMap(K fromKey, K toKey);
//返回小于toKey的子集合
ConcurrentNavigableMap<K,V> headMap(K toKey);
//返回大于等于fromKey的子集合
ConcurrentNavigableMap<K,V> tailMap(K fromKey);
//返回一个排序是反序的map(即将原本正序的Map进行反序排列)
ConcurrentNavigableMap<K,V> descendingMap();
//返回所有key组成的set集合
public NavigableSet<K> navigableKeySet();
//返回所有key组成的set集合
NavigableSet<K> keySet();
//返回一个key的set视图,并且这个set中key是反序的
public NavigableSet<K> descendingKeySet();
}
public class ConcurrentSkipListMap<K,V> extends AbstractMap<K,V>
implements ConcurrentNavigableMap<K,V>, Cloneable, Serializable {
//特殊值,用于
private static final Object BASE_HEADER = new Object();
//跳表的头索引
private transient volatile HeadIndex<K,V> head;
//比较器,用于key的比较,若为null,则使用自然排序(key自带的Comparable实现)
final Comparator<? super K> comparator;
//键的视图
private transient KeySet<K> keySet;
//键值对的视图
private transient EntrySet<K,V> entrySet;
//值的视图
private transient Values<V> values;
//反序排列的map
private transient ConcurrentNavigableMap<K,V> descendingMap;
private static final int EQ = 1;
private static final int LT = 2;
private static final int GT = 0;
//空构造
public ConcurrentSkipListMap() {
this.comparator = null;
initialize();
}
//带比较器的构造方法
public ConcurrentSkipListMap(Comparator<? super K> comparator) {
this.comparator = comparator;
initialize();
}
//带初始元素集合的构造方法
public ConcurrentSkipListMap(Map<? extends K, ? extends V> m) {
this.comparator = null;
initialize();
putAll(m);
}
//使用m集合的比较器构造方法
public ConcurrentSkipListMap(SortedMap<K, ? extends V> m) {
this.comparator = m.comparator();
initialize();
buildFromSorted(m);
}
//初始化变量
private void initialize() {
keySet = null;
entrySet = null;
values = null;
descendingMap = null;
//新建HeadIndex结点,head指向该头结点
head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null),
null, null, 1);
}
}
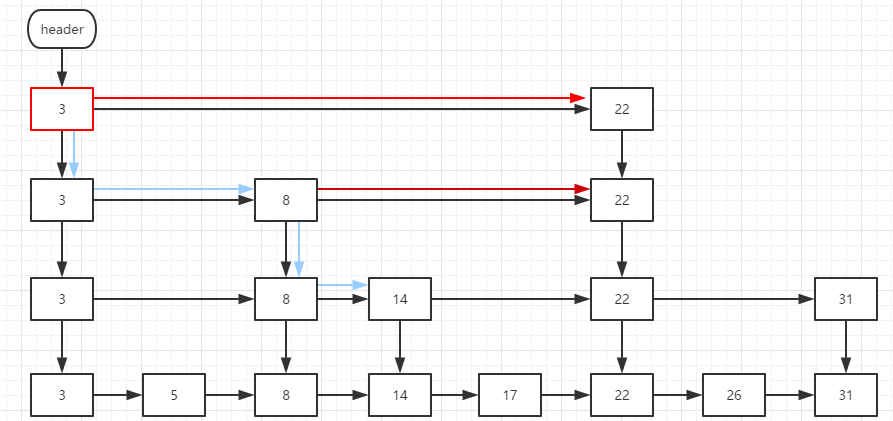
public V put(K key, V value) {
if (value == null) //这里可以知道Value要求不能为null
throw new NullPointerException();
return doPut(key, value, false); //实际执行put操作的方法
}
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node<K,V> z; // added node
if (key == null) //有序的map,key不能为null,否则无法比较
throw new NullPointerException();
Comparator<? super K> cmp = comparator; //获取比较器,若无则为null,使用自然排序
outer: for (;;) { //外层循环
//findPredecessor查找key的前驱索引对应的结点b
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
//判断b结点是否是链表的尾结点,即b结点是否还有后继结点
//若有后继结点(n不为null表示有后继结点),那么要将key对应的结点插入b和n之间
//若b为尾结点,则key对应结点将为新的尾结点
if (n != null) {
Object v; int c;
Node<K,V> f = n.next; //获取n的后继结点
//判断n还是不是b的后继结点
//若n不在是b的后继结点,说明已经有线程抢先在b结点之后插入一个新结点
//退出内层循环,重新定位插入
if (n != b.next)
break;
//判断n结点是否要被删除(value为null表示逻辑删除),辅助删除后重新定位key
if ((v = n.value) == null) { // n is deleted
n.helpDelete(b, f); //让当前线程去辅助删除(物理删除)
break;
}
//判断b是否要被删除,若要被删除,则退出当前循环,重新定位key
if (b.value == null || v == n) // b is deleted
break;
//判断n结点的键与key的大小
//这里开始精准定位key在链表中的位置,找出key实际在链表中的前驱结点
//key比n结点的key大,则继续比较后续结点的key
if ((c = cpr(cmp, key, n.key)) > 0) {
b = n;
n = f;
continue;
}
//若key与n.key相等(c==0),说明key对应的结点已经存在
//那么根据onlyIfAbsent来决定是否覆盖旧value值
if (c == 0) {
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv; //更新成功,直接返回旧值
}
break; //更新失败继续循环尝试
}
// else c < 0; fall through
}
//到这说明b就是key的前驱结点
//新建key的结点z,并尝试更新b的next为z,成功就退出外层循环
//更新失败继续尝试
z = new Node<K,V>(key, value, n);
if (!b.casNext(n, z))
break; // restart if lost race to append to b
break outer;
}
}
/**
* 上面的步骤是将新结点插入到跳表最底层的链表中
* 接下来则是要向上生成各层的索引,是否生成某一层次的索引通过抛硬币的方式
* 决定,即从最底层开始随机决定是否在上一层建议索引,若为true则在上一层生成索引
* 并且继续抛硬币决定是否再往上层建立索引;若失败则布建立索引,直接结束
*/
//生成一个随机数
int rnd = ThreadLocalRandom.nextSecondarySeed();
//判断是否要更新层级(随机数必须是正偶数才更新层级)
//这里决定的是当前新增的结点是否要向上建立索引
if ((rnd & 0x80000001) == 0) { // test highest and lowest bits
int level = 1, max;
//决定level的等级,也就是结点要向上建立基层索引
//level的值有rnd从低二位开始有几个连续的1决定
//例如:rnd==0010 0100 0001 1110 那么level就为5
//由此可以看出跳表的最高层次不能超过31层(level<=31)
while (((rnd >>>= 1) & 1) != 0)
++level;
Index<K,V> idx = null;
HeadIndex<K,V> h = head;
//判断level是否超过当前跳表的最高等级(即是否大于头索引的level)
//若未超过,那么直接建立一个从1到level的纵向索引列
if (level <= (max = h.level)) {
//新建一个索引列,后建的索引的down指针指向前一个索引
for (int i = 1; i <= level; ++i)
idx = new Index<K,V>(z, idx, null);
}
//若新建结点的level大于头结点的level,则要新建一个新的level层
else { // try to grow by one level
level = max + 1; // 只能新增一层,为一个结点就新增2层以上没有意义
@SuppressWarnings("unchecked")
Index<K,V>[] idxs = (Index<K,V>[])new Index<?,?>[level+1];
//新建一个结点z的索引列,并将这个索引列的所有索引都放到数组中
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K,V>(z, idx, null);
for (;;) {
h = head; //获取头索引
int oldLevel = h.level; //获取旧层次level
//判断旧层次level是否发生改变(即是否有其他线程抢先更新了跳表的level,出现竞争)
if (level <= oldLevel) // lost race to add level
break; //竞争失败,直接结束当前循环
HeadIndex<K,V> newh = h;
Node<K,V> oldbase = h.node;
//生成新的HeadIndex节点
//正常情况下,循环只会执行一次,如果由于其他线程的并发操作导致 oldLevel 的值不稳定,那么会执行多次循环体
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
//尝试更新头索引的值
if (casHead(h, newh)) {
h = newh;
idx = idxs[level = oldLevel];
break;
}
}
}
//将新增的idx插入跳表之中
splice: for (int insertionLevel = level;;) {
int j = h.level; //获取最高level
//查找需要清理的索引
for (Index<K,V> q = h, r = q.right, t www.michenggw.com= idx;;) {
//其他线程并发操作导致头结点被删除,直接退出外层循环
//这种情况发生的概率很小,除非并发量实在太大
if (q == null || t == null)
break splice;
//判断q是否为尾结点
if (r != null) {
Node<K,V> n = r.node; //获取索引r对应的结点n
// compare before deletion check avoids needing recheck
int c = cpr(cmp, key, n.key); //比较新增结点的key与n.key的大小
//判断n是否要被删除
if (n.value == null) {
if (!q.unlink(r)) //删除r索引
break;
r = q.right;
continue;
}
//c大于0,说明当前结点n.key小于新增结点的key
// 继续向右查找一个结点的key大于新增的结点key的索引
//新结点对应的索引要插入q,r之间
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
//判断是否
if (j == insertionLevel) {
//尝试着将 t 插在 q 和 r 之间,如果失败了,退出内循环重试
if (!q.link(r, t))
break; // restart
//如果插入完成后,t 结点被删除了,那么结束插入操作
if (t.node.value == null) {
// 查找节点,查找过程中会删除需要删除的节点
findNode(key);
break splice;
}
//到达最底层,没有要插入新索引的索引层了
if (--insertionLevel == 0)
break splice;
}
//向下继续链接其它index 层
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
}
return null;
}
//查找key在map中的位置的前驱结点
private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) {
if (key == null)
throw new NullPointerException(); // don't postpone errors
for (;;) {
//获取head头索引,遍历跳表
for (Index<K,V> q = head, r = q.right, d;;) {
//判断是否有后继索引,若有
if (r != null) {
Node<K,V> n = r.node; //获取索引对应的结点
K k = n.key; //获取结点对应的key
//判断结点的value是够为null,为null表示结点已经被删除了
//一个结点从链表中被删除时,会将value赋为null,因为此时跳表其他层级的索引还可能
//会引用着该结点,value赋null,标识该结点已经被废弃,对应的索引(如果存在)也应该从跳表中删除
//那么调用unlink方法删除索引
if (n.value == null) {
//尝试将r索引移除出跳表,成功就继续查找
//失败就继续尝试
if (!q.unlink(r))
break; // restart
r = q.right; // reread r
continue;
}
//比较当前索引中结点的键k与key的大小
//若key大于k,则继续查找比较下个索引
if (cpr(cmp, key, k) > 0) {
q = r;
r = r.right; //下个右边索引
continue;
}
}
//若是key小于k,则判断是够到达跳表的最底层的上一层,
//若是到达最底层的上一层,则说明当前索引就是key的前驱索引,node就是对应的结点
//若不是最底层的上一层,则继续比较查找
if ((d = q.down) == null)
return q.node;
q = d;
r = d.right;
}
}
}
//Index中的方法,断开两个索引之间的联系
final boolean unlink(Index<K,V> succ) {
return node.value != null && casRight(succ, succ.right);
}
//CAS方式更新当前索引的右边索引
final boolean casRight(Index<K,V> cmp, Index<K,V> val) {
return UNSAFE.compareAndSwapObject(this, rightOffset, cmp, val);
}
//帮助将b结点从链表中删除
void helpDelete(Node<K,V> b, Node<K,V> f) {
//判断是否有其他线程已经将n删除(有竞争),若是已经删除直接返回
if (f == next && this == b.next) {
//判断f是否为null,即当前要删除的this结点是否为尾结点
//若this为尾结点,则尝试更新this的后继为new Node<K,V>(f),这里没看懂。。
if (f == null || f.value != f) // not already marked
casNext(f, new Node<K,V>(f));
else
b.casNext(this, f.next); //尝试将当前结点this的前驱结点b的next更新为this的后继结点f
}
}
//CAS方式更新当前结点的后继为val
boolean casNext(Node<K,V> cmp, Node<K,V> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
public V get(Object key) {
return doGet(key);
}
private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) { //外层循环
//查找key的前驱索引对应的结点
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
//n为null,说明b是为结点,则key不存在
if (n == null)
break outer;
Node<K,V> f = n.next;
//b的后继不为n,说明b的后继别其他线程改变,重新定位key
if (n != b.next) // inconsistent read
break;
//判断n是否已经被删除,若是则辅助删除,并重新定位key
if ((v = n.value) www.shengchanyule.com== null) { // n is deleted
n.helpDelete(b, f);
break;
}
//判断b是否已经被删除,若是则辅助删除,并重新定位key
if (b.value == null || v == n) // b is deleted
break;
//判断n是否是要查找的结点
//c==0,表示key==n.key,找到要查找的额结点
、 //c若是小于0,那么key就不存在,结束查找
//c大于0,说明还没找到,则继续遍历查找
if ((c = cpr(cmp, key, n.key)) == 0) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
if (c < 0)
break outer;
b = n;
n = f;
}
}
return null;
}
public V remove(Object key) {
return doRemove(key,www.iqushipin.com null);
}
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
//findPredecessor查找key的前驱索引对应的结点
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
//n为null,说明b是为结点,则key不存在
if (n == null)
break outer;
Node<K,V> f = n.next;
//b的后继不为n,说明b的后继别其他线程改变,重新定位key
if (n != b.next) // inconsistent read
break;
//判断n是否已经被删除,若是则辅助删除,并重新定位key
if ((v = n.value) == null) { // n is deleted
n.helpDelete(b, f);
break;
}
//判断b是否已经被删除,若是则辅助删除,并重新定位key
if (b.value == null || www.shengchangyule.net v == n) // b is deleted
break;
//key不存在,直接结束删除
if ((c = cpr(cmp, key, n.key)) < 0)
break outer;
//当前结点不是要删除的结点,继续遍历查找
if (c > 0) {
b = n;
n = f;
continue;
}
//找到要删除的结点,但已被别的线程抢先删除,则直接结束删除
if (value != null && !value.equals(v))
break outer;
//尝试逻辑删除,失败则继续尝试
if (!n.casValue(v, null))
break;
//给节点添加删除标识(next节点改为一个指向自身的节点)
//然后把前继节点的next节点CAS修改为next.next节点(彻底解除n节点的链接)
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key); // 清除已删除的结点
else {
//删除n节点对应的index,findPredecessor中有清除索引的步骤
findPredecessor(key, cmp); // clean index
//判断是否要减少跳表的层级
if (head.right == null)
tryReduceLevel();
}
@SuppressWarnings("unchecked") V vv = (V)v;
return vv; //返回删除结点的value
}
}
return null;
}
//自环起来标志该结点要被删除
boolean appendMarker(Node<K,V> f) {
return casNext(f, new Node<K,V>(f));
}
//遍历底层链表来统计结点的个数
public int size() {
long count = 0;
for (Node<K,V> n = findFirst(www.syylegw.com/); n != null; n = n.next) {
if (n.getValidValue() != null)
++count;
}
return (count www.365soke.com>= Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) count;
}
//获取底层链表的头结点
final Node<K,V> findFirst(www.078881.cn/ ) {
for (Node<K,V> b, n;;) {
if ((n = (b = head.node).next) == null)
return null;
if (n.value != null)
return n;
n.helpDelete(b, n.next); //协助删除已被标记删除的结点
}
}
并发容器学习—ConcurrentSkipListMap与ConcurrentSkipListSet 原的更多相关文章
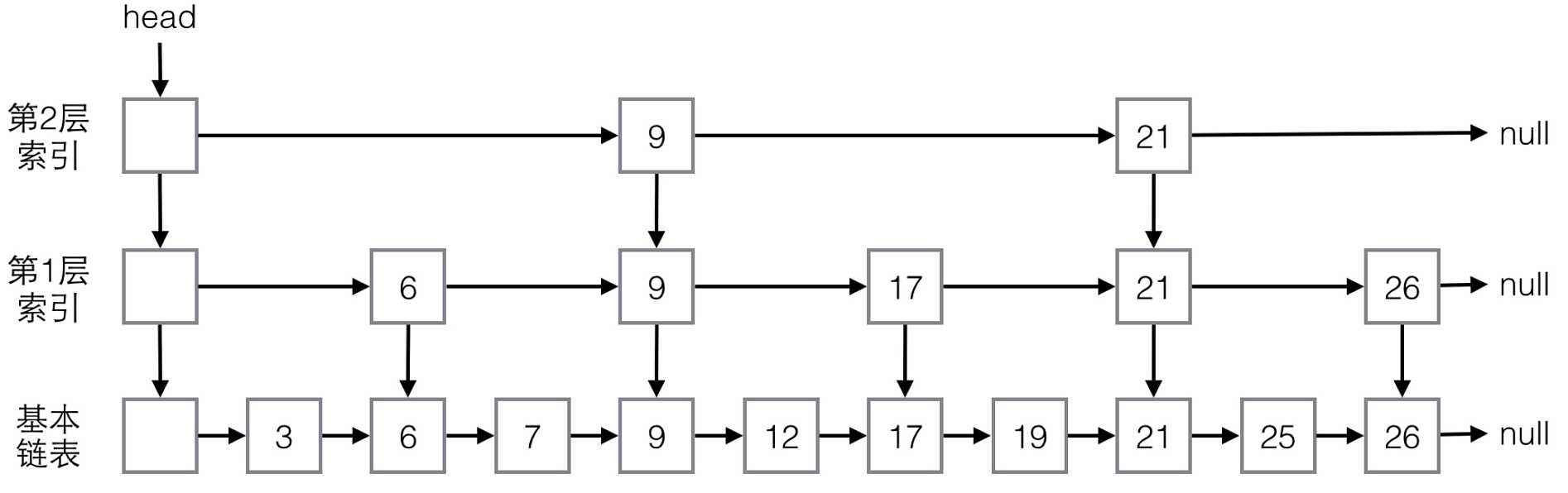
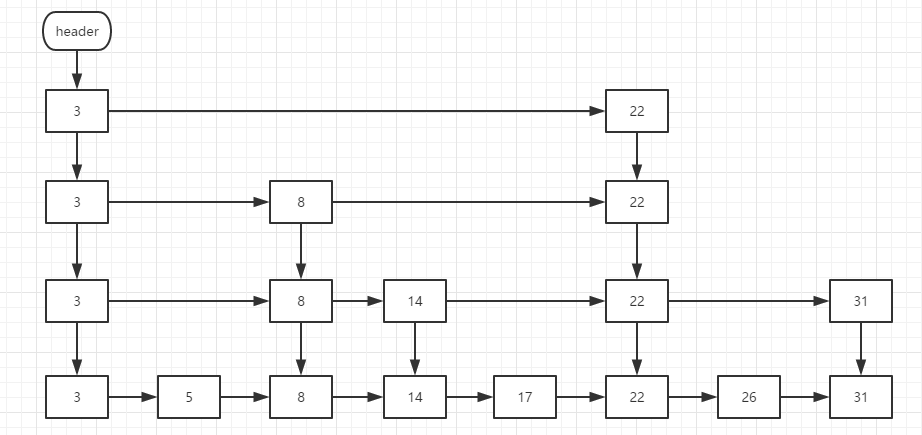
- 计算机程序的思维逻辑 (75) - 并发容器 - 基于SkipList的Map和Set
上节我们介绍了ConcurrentHashMap,ConcurrentHashMap不能排序,容器类中可以排序的Map和Set是TreeMap和TreeSet,但它们不是线程安全的.Java并发包中与 ...
- Java编程的逻辑 (75) - 并发容器 - 基于SkipList的Map和Set
本系列文章经补充和完善,已修订整理成书<Java编程的逻辑>,由机械工业出版社华章分社出版,于2018年1月上市热销,读者好评如潮!各大网店和书店有售,欢迎购买,京东自营链接:http: ...
- 【Java并发工具类】Java并发容器
前言 Java并发包有很大一部分都是关于并发容器的.Java在5.0版本之前线程安全的容器称之为同步容器.同步容器实现线程安全的方式:是将每个公有方法都使用synchronized修饰,保证每次只有一 ...
- Java并发指南14:Java并发容器ConcurrentSkipListMap与CopyOnWriteArrayList
原文出处http://cmsblogs.com/ 『chenssy』 到目前为止,我们在Java世界里看到了两种实现key-value的数据结构:Hash.TreeMap,这两种数据结构各自都有着优缺 ...
- Android并发编程 原子类与并发容器
在Android开发的漫漫长途上的一点感想和记录,如果能给各位看官带来一丝启发或者帮助,那真是极好的. 前言 上一篇博文中,主要说了些线程以及锁的东西,我们大多数的并发开发需求,基本上可以用synch ...
- 并发编程学习笔记(4)----jdk5中提供的原子类及Lock使用及原理
(1)jdk中原子类的使用: jdk5中提供了很多原子类,它会使变量的操作变成原子性的. 原子性:原子性指的是一个操作是不可中断的,即使是在多个线程一起操作的情况下,一个操作一旦开始,就不会被其他线程 ...
- Java高并发程序设计学习笔记(五):JDK并发包(各种同步控制工具的使用、并发容器及典型源码分析(Hashmap等))
转自:https://blog.csdn.net/dataiyangu/article/details/86491786#2__696 1. 各种同步控制工具的使用1.1. ReentrantLock ...
- Java 并发系列之六:java 并发容器(4个)
1. ConcurrentHashMap 2. ConcurrentLinkedQueue 3. ConcurrentSkipListMap 4. ConcurrentSkipListSet 5. t ...
- Java笔记(十六)并发容器
并发容器 一.写时复制的List和Set CopyOnWrite即写时复制,或称写时拷贝,是解决并发问题的一种重要思路. 一)CopyOnWriteArrayList 该类实现了List接口,它的用法 ...
随机推荐
- 42.Odoo产品分析 (四) – 工具板块(10) – 问卷(2)
查看Odoo产品分析系列--目录 接上一篇Odoo产品分析 (四) – 工具板块(10) – 问卷(1) 4 页面 即问卷,点开一项查看: 可以看出,网页就是问卷本身的子目录,其中指明了该目录包括哪 ...
- TextView走马灯
设置textView走马灯形式显示: android:marqueeRepeatLimit="marquee_forever" android:scrollHorizontally ...
- Easyui datagrid 修改分页组件的分页提示信息为中文
datagrid 修改分页组件的分页提示信息为中文 by:授客 QQ:1033553122 测试环境 jquery-easyui-1.5.3 问题描述 默认分页组件为英文展示,如下,希望改成中文展示 ...
- 对国内AR产业的预言
先丢预言,国内任何AR公司,包含几大块,医疗行业.手机制造商和自动驾驶,倘若没有能力进行系统设计,最后都要死,或者裁掉业务. AR本身不会演化为独立的业务,而是作为辅助性的工具进入传统已经存在的部门之 ...
- c/c++ gdb 调试带参数的程序
直接gdb pgname 参数1 这种方式,参数1是不会带到gdb里的 1,首先启动程序 gdb pgname 2,设置程序的参数 set args 参数1
- jQuery如何制作动画
下面为一组图片(四张)展示 1 2 3 4 页面代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN& ...
- ubuntu14.04 安装 php Composer时 composer:未找到命令
在Ubuntu14.04环境下,进行composer安装时,各个方面都很顺利,安装完成后,出现了如下的错误提示: 百思不得其解!本人的环境是Ubuntu14.04 ,安装过程也是严格按照compose ...
- HTML之间互相传参
如图所示,在index.html详情展示中给detailsPanel穿参数,在detailsPanel中获取到参数写ajax到后台获取json数据,那么如何在detailsPanel.html中获取传 ...
- Ubuntu18.04 安装jdk1.8
1.oracle官网下载压缩包,点击链接. 2.解压 1 tar -zxvf jdk-8u171-linux-x64.tar.gz 3.移动到制定目录 ##将文件从下载目录 挪到/usr/local下 ...
- 7 Best Free RAR Password Unlocker Software For Windows
Here is the list of Best Free RAR Password Unlocker Software for Windows. These software run differe ...