大数据之路day01_1--Java下载、安装等配置
从今天开始,我就正式的走上大数据的道路了,如果说我为啥要去学习大数据,可能我的初衷是以后可以接触到人工智能方面的技术,后来在自学的过程中发现,学习人工智能,需要扎实的算法,以及对大量数据的处理,再者,渐渐的我想先系统的学习以下大数据这块的知识,从Java环境搭建到最后的机器学习,到深度学习,一步一个脚印的去实现,只有把基础打好了,后面的露才会好走,谁也不可能一口吃成胖子。马云的成功,在我看来,他发现了未来技术成长曲线,坚持自己想法,并与之去实现。从一开始的无人问津到后来的一个小举动引到各大媒体的注意,这是成功的表现,亦是对自己的考验。梦想还是要有的,万一实现了呢!
1、下载并且安装JDK (网速慢的可以用我的网盘) 注意:尽量不要去下载最新的JDK,有不少的代码并不兼容。后期还要进行修改,很烦的。
链接:https://pan.baidu.com/s/1nhEc7FXv7ES5L893YL1cXA
提取码:224n
一路傻瓜式默认安装,其中遇到装JRE的时候的安装目录是自己创建的,可以不下载,但是不大,就下吧。(这里简单的说一下,JRE是运行JAVA的,JDK是用来开发的)
2、配置环境变量
上一步安装后我的是这样:

接下来开始配置环境变量:
(1)右击此电脑--->点击属性
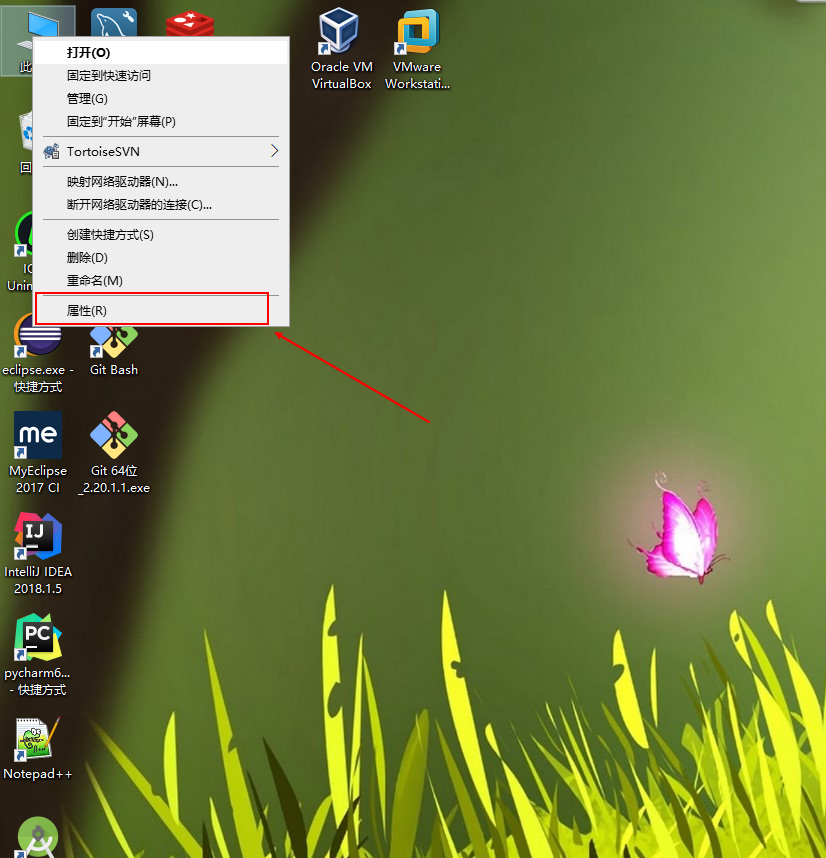
(2)点击高级系统设置---->环境变量
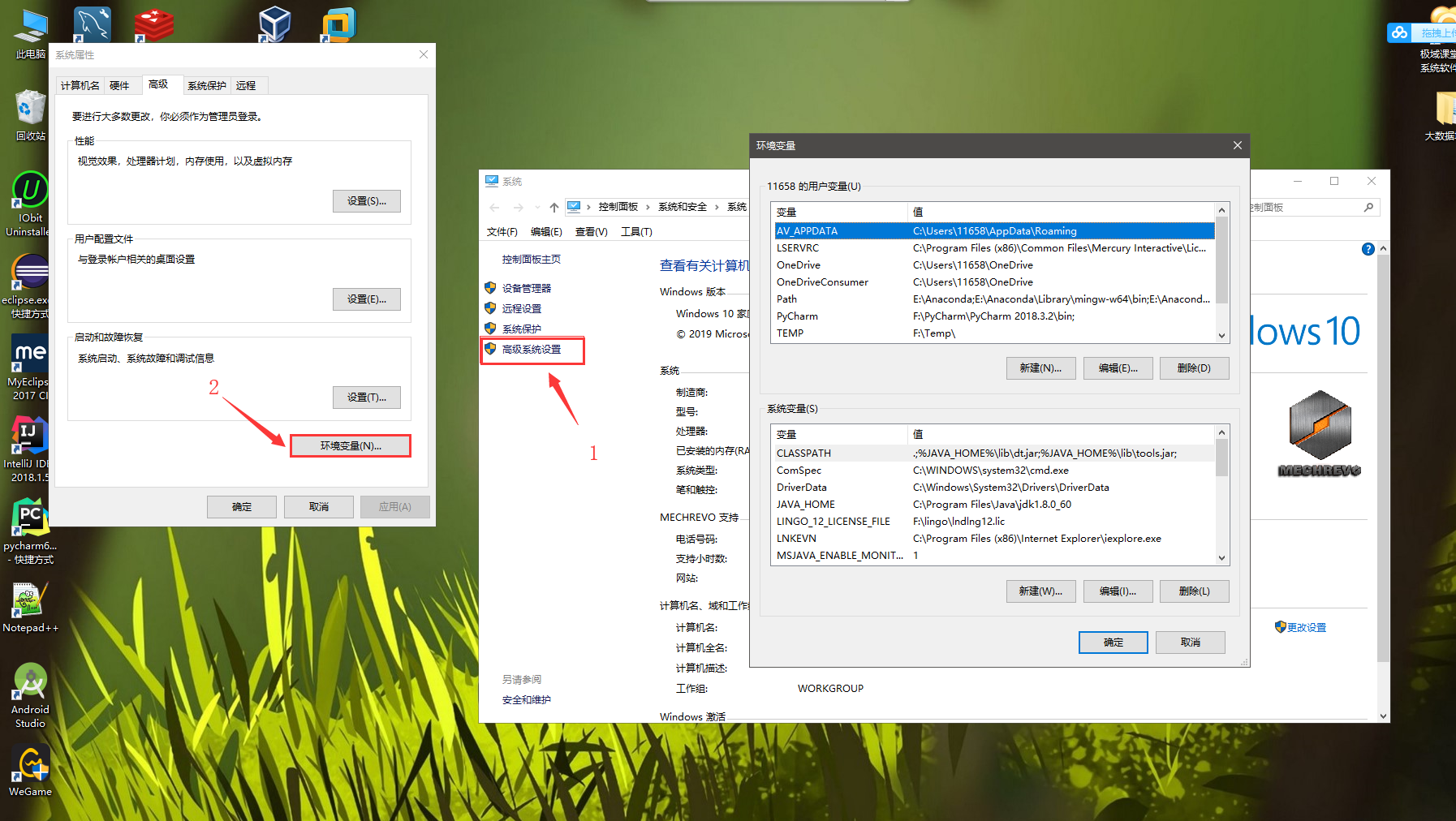
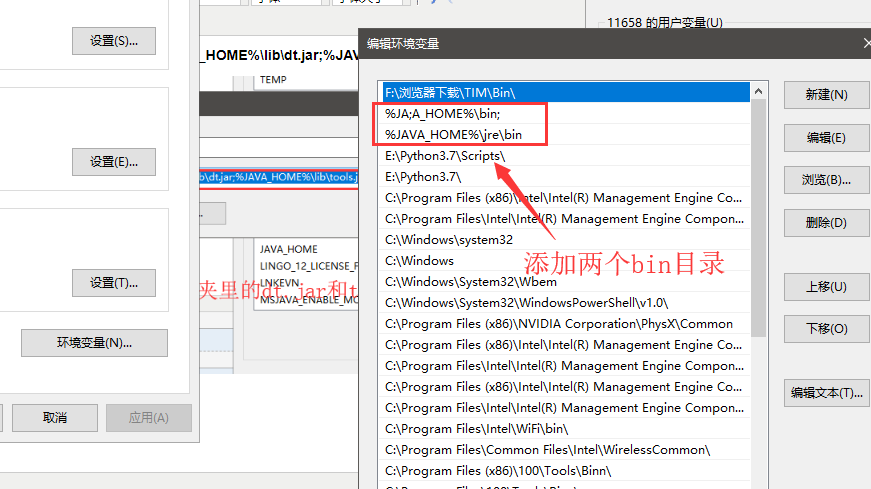
(3)在系统变量里我们要配置三个变量 JAVA_HOME 、 CLASSPATH 、 Path (没有的变量自己新建)
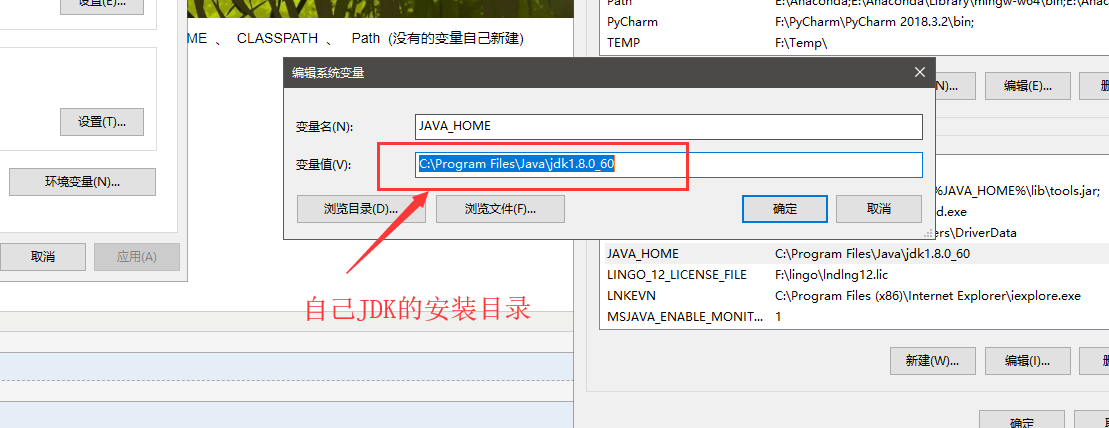
a、JAVA_HOME 这是我对应的变量值: C:\Program Files\Java\jdk1.8.0_60 (不要直接复制,因为每个人的安装路径可能不一样)
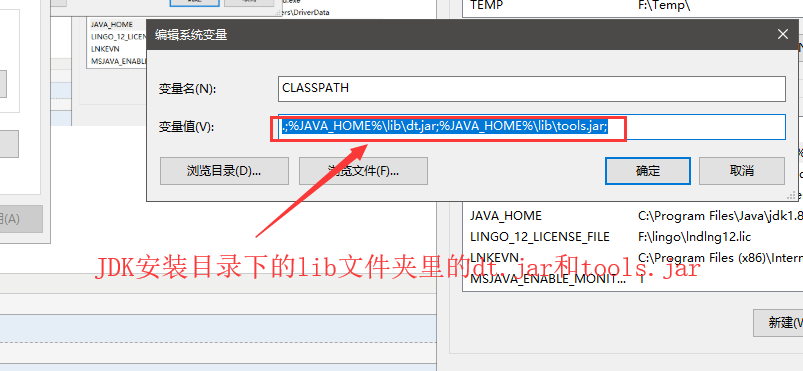
b、CLASSPATH 这是我对应的变量值: .;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;(在JAVA_HOME填对的情况下,这个可以直接复制)
c、Path 这是我对应的变量值: %JAVA_HOME%\bin; 和 %JAVA_HOME%\jre\bin
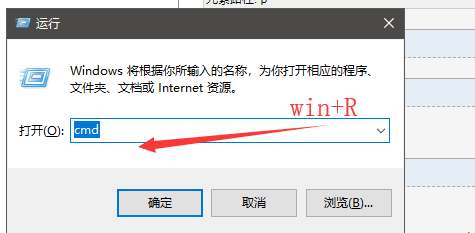
(4)win+R 键打开输入cmd
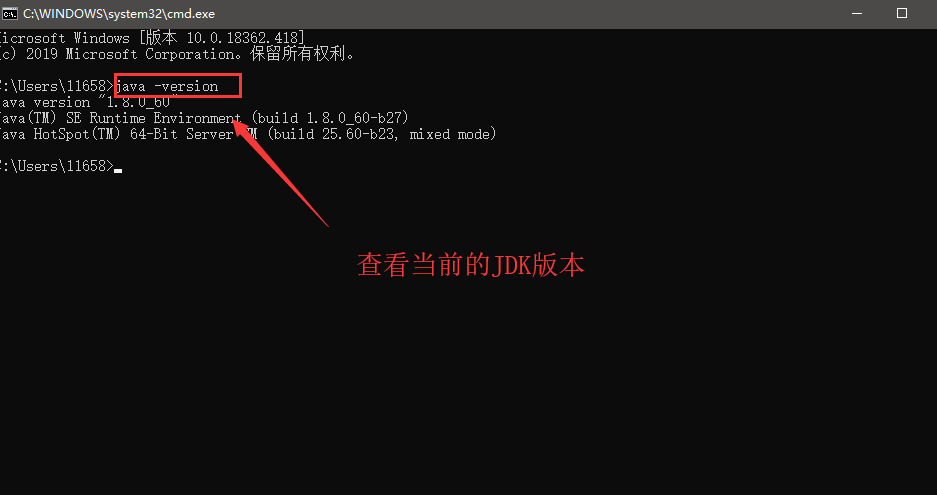
分别输入以下命令回车
a、java -version
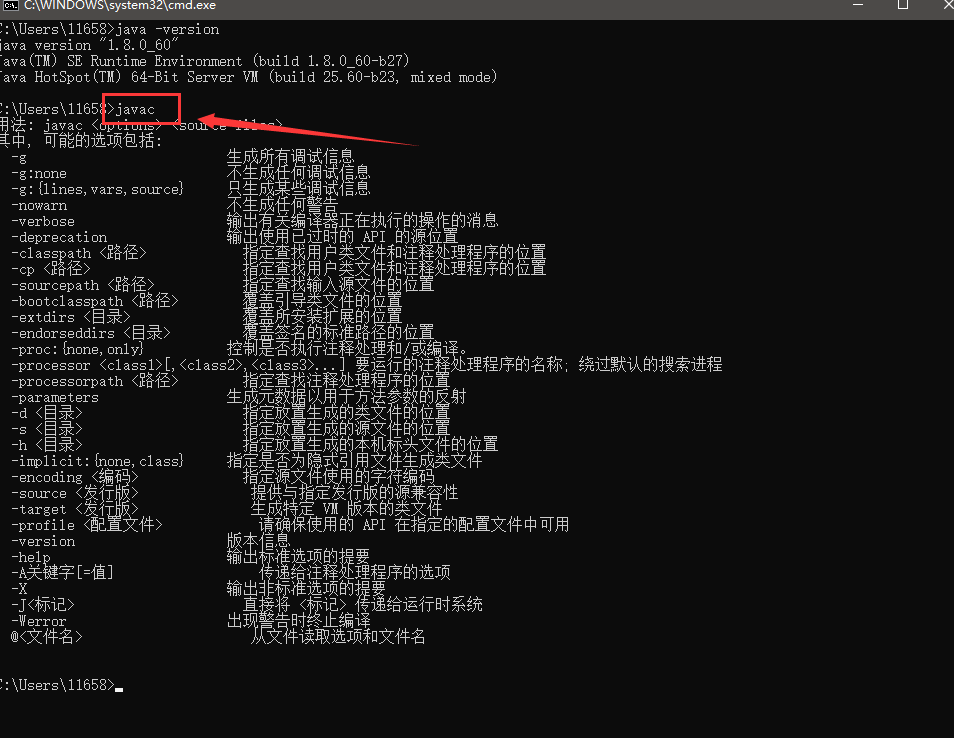
b、javac
c、java
(5)如果以上的命令输入结果和我截图一样,说明安装JDK,并且环境变量配置成功!!!!下一步,编写我们的第一个程序(“Hello World !”)。
大数据之路day01_1--Java下载、安装等配置的更多相关文章
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据之路week05--day02(Maven安装,环境变量的配置及基本使用)
今天我们就来学习一下maven,怎么说呢,maven更像是一种管理的工具,实现的原理是使用插件. 举个例子,比如说,一个公司需要做一个项目,这个项目又分成了很多的模块,每个模块又分成了许多的业务等等, ...
- C#码农的大数据之路 - 使用Ambari自动化安装HDP2.6(基于Ubuntu16.04)并运行.NET Core编写的MR作业
准备主机 准备3台主机,名称作用如下: 昵称 Fully Qualified Domain Name IP 作用 Ubuntu-Parrot head1.parrot 192.168.9.126 Am ...
- 大数据高可用集群环境安装与配置(04)——安装JAVA运行环境
Hadoop运行在java环境,所以在安装Hadoop之前,需要安装好jdk 提前下载好jdk安装包(jdk-8u161-linux-x64.tar.gz),将它上传到指定的安装目录当中,然后运行安装 ...
- 大数据高可用集群环境安装与配置(07)——安装HBase高可用集群
1. 下载安装包 登录官网获取HBase安装包下载地址 https://hbase.apache.org/downloads.html 2. 执行命令下载并安装 cd /usr/local/src/ ...
- 大数据高可用集群环境安装与配置(06)——安装Hadoop高可用集群
下载Hadoop安装包 登录 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 镜像站,找到我们要安装的版本,点击进去复制下载链接 ...
- 大数据高可用集群环境安装与配置(09)——安装Spark高可用集群
1. 获取spark下载链接 登录官网:http://spark.apache.org/downloads.html 选择要下载的版本 2. 执行命令下载并安装 cd /usr/local/src/ ...
- 大数据高可用集群环境安装与配置(08)——安装Ganglia监控集群
1. 安装依赖包和软件 在所有服务器上输入命令进行安装操作 yum install epel-release -y yum install ganglia-web ganglia-gmetad gan ...
- 大数据高可用集群环境安装与配置(10)——安装Kafka高可用集群
1. 获取安装包下载链接 访问https://kafka.apache.org/downloads 找到kafka对应版本 需要与服务器安装的scala版本一致(运行spark-shell可以看到当前 ...
- 大数据高可用集群环境安装与配置(05)——安装zookeeper集群
1. 下载安装包 登录官网下载安装包 https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/ 2. 执行命令下载并安装 cd /usr/local ...
随机推荐
- JavaScript:如何获取某一天所在的星期
我们会遇到的需求的是,获取今天或者某一天所在星期的开始和结束日期. 我们这里来获取今天所在星期的始末日期,我们可以通过(new Date).getDay()来获取今天是星期几,然后再通过这个减去或者加 ...
- 线程池和lambda表达式
线程池1.什么是线程池.一个用来创建和管理线程的容器;2.线程池的作用.提高线程的复用性,降低资源消耗提高线程的响应速度,提高线程的可管理性3.线程的核心思想;线程的复用 4.线程池的创建Execut ...
- javascript语言学习
本课将和大家一起学习简单的js dom 操作,涵盖DOM API以及JQuery的方法. 相关简介 JavaScript一种直译式脚本语言,是一种动态类型.弱类型.基于原型的语 ...
- Python开发【第四篇】语句与函数
语句 statement 语句是由一些表达式组成,通常一条语句可以独立的执行来完成一部分事情,并且形成结果. 多条语句写在一行内要用分号分开 例子: print('hello world') #这是一 ...
- SpringBoot:1.开启SpringBoot之旅
什么是 Spring Boot Spring Boot是Spring团队设计用来简化Spring应用的搭建和开发过程的框架.该框架对第三方库进行了简单的默认配置,通过Spring Boot构建的应用程 ...
- pytest2-收集与执行测试用例规则
pytest收集测试用例规则 测试文件以test_开头(以_test结尾也可以) 测试类以Test开头,并且不能带有 init 方法 测试函数以test_开头(以_test结尾也可以) pytest执 ...
- Spring 源码阅读之 深入理解 finishBeanFactoryInitialization
源码入口 上篇博文中我们看到了将Spring环境中的 BeanPostProcessor找出来,添加到BeanFactory中的beanPostProcessors中,统一维护,本片博文继续往下拓展, ...
- 百万年薪python之路 -- HTML标签
HTML标签 html标签分类 html标签又叫做html元素,它分为块级元素和内联元素(也可以叫做行内元素),都是html规范中的概念. 标题 h1 h2 h3 h4 h5 h6 列表 ol ul ...
- Ubuntu 14.04 sudo免密码的方法| sudo不需要密码
Ubuntu 14.04 sudo免密码的方法| sudo不需要密码 cd /etc/sudoers.d sudo touch nopasswd4sudo sudo vi nopasswd4sudo ...
- day26作业
1.整理TCP三次握手.四次挥手图 2.基于TCP开发一款远程CMD程序 客户端连接服务器后,可以向服务器发送命令 服务器收到命令后执行,无论执行是否成功,无论执行几遍,都将执行结果返回给客户端 注意 ...