爬虫(三):urllib模块
1. urllib模块
1.1 urllib简介
urllib 是 Python3 中自带的 HTTP 请求库,无需复杂的安装过程即可正常使用,十分适合爬虫入门
urllib 中包含四个模块,分别是:
request:请求处理模块
parse:URL 处理模块
error:异常处理模块
robotparser:robots.txt 解析模块
1.2 urllib使用
1.2.1 request 模块
request模块是urllib中最重要的一个模块,一般用于发送请求和接收响应
(1)urlopen 方法
urllib.request.urlopen()
urlopen 方法无疑是 request 模块中最常用的方法之一,常见的参数说明如下:
url:必填,字符串,指定目标网站的 URL
data:指定表单数据
该参数默认为 None,此时urllib使用GET方法发送请求
当给参数赋值后,urllib使用POST方法发送请求,并在该参数中携带表单信息(bytes 类型)
timeout:可选参数,用来指定等待时间,若超过指定时间还没获得响应,则抛出一个异常
该方法始终返回一个HTTPResponse对象,HTTPResponse对象常见的属性和方法如下:
read():返回响应体(bytes 类型),通常需要使用decode('utf-8')将其转化为str类型
import urllib.request def load_data():
url = "http://www.baidu.com/"
#get的请求
#http请求
#response:http相应的对象
response = urllib.request.urlopen(url)
# print(response)
#读取内容 bytes类型
data = response.read()
# print(data)
#将文件获取的内容转换成字符串
str_data = data.decode("utf-8")
# print(str_data)
#将数据写入文件
with open("baidu.html","w",encoding="utf-8")as f:
f.write(str_data)
#将字符串类型转换成bytes
str_name = "baidu"
bytes_name =str_name.encode("utf-8")
# print(bytes_name) #python爬取的类型:str bytes
#如果爬取回来的是bytes类型:但是你写入的时候需要字符串 decode("utf-8")
#如果爬取过来的是str类型:但你要写入的是bytes类型 encode(""utf-8")
load_data()
大家可以将我注释的输出内容去掉注释,看看到底输出了什么内容。
(2)urlretrleve方法
这个方法可以方便的将网页上的一个文件保存到本地,以下代码可以非常方便的将百度的首页下载到本地。
from urllib import request
request.urlretrieve('http://www.baidu.com/','baidu.html')
(3) Request对象
我们还可以给urllib.request.urlopen()方法传入一个 Request 对象作为参数
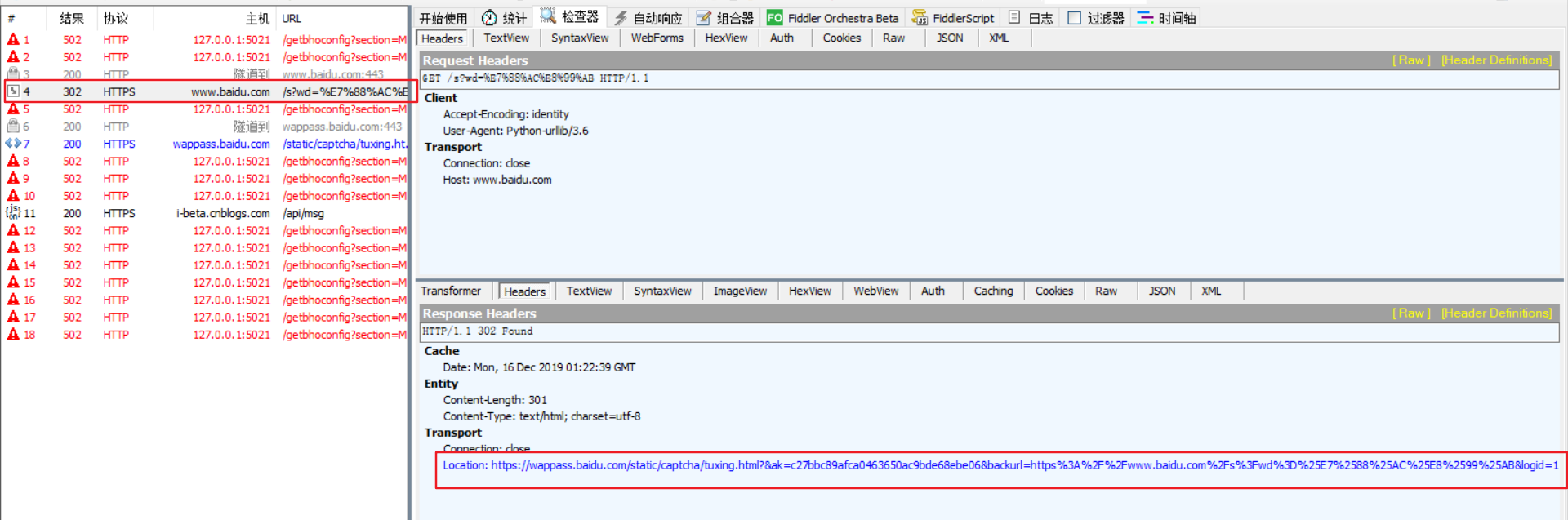
为什么还需要使用Request对象呢?因为在上面的参数中我们无法指定请求头部,而它对于爬虫而言又十分重要很多网站可能会首先检查请求头部中的USER-AGENT字段来判断该请求是否由网络爬虫程序发起但是通过修改请求头部中的USER_AGENT字段,我们可以将爬虫程序伪装成浏览器,轻松绕过这一层检查这里提供一个查找常用的USER-AGENT的网站:https://techblog.willshouse.com/2012/01/03/most-common-user-agents/
urllib.request.Request()
参数说明如下:
url:指定目标网站的 URL
data:发送POST请求时提交的表单数据,默认为None
headers:发送请求时附加的请求头部,默认为 {}
origin_req_host:请求方的host名称或者 IP 地址,默认为None
unverifiable:请求方的请求无法验证,默认为False
method:指定请求方法,默认为None
import urllib.request def load_data():
url = "http://www.baidu.com/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
req = urllib.request.Request(url, headers=headers, method='GET')
response = urllib.request.urlopen(req) html = response.read().decode("utf-8")
print(html) load_data()
这个结果大家要使用抓包工具来查看。
1.2.2 parse模块
parse模块一般可以用于处理URL
(1)quote 方法
当你在URL中使用中文时,你会发现程序会出现莫名其妙的错误。
import urllib.request
url = 'https://www.baidu.com/s?wd=爬虫'
response = urllib.request.urlopen(url)

这个时候就靠quote方法了,它使用转义字符替换特殊字符,从而将上面的URL处理成合法的URL。
import urllib.request
import urllib.parse url = 'https://www.baidu.com/s?wd=' + urllib.parse.quote('爬虫')
response = urllib.request.urlopen(url)
data = response.read()
str_data = data.decode("utf-8")
print(str_data)
(2)urlencode 方法
urlencode方法就是将dict类型数据转化为符合URL标准的str类型数据。
import urllib.parse
params = {
'from':'AUTO',
'to':'AUTO'
}
data = urllib.parse.urlencode(params)
print(data)
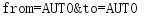
(3)urlparse 方法
urlparse方法用于解析URL,返回一个ParseResult对象.
该对象可以认为是一个六元组,对应 URL 的一般结构:
scheme/netloc/path/parameters/query/fragment
实例:
import urllib.parse
url = 'http://www.example.com:80/python.html?page=1&kw=urllib'
url_after = urllib.parse.urlparse(url)
print(url_after)
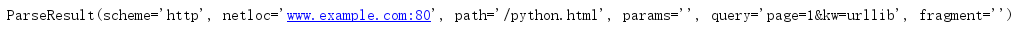
想要获得一个参数的值,只需要 url_after.参数 即可。
(4)parse_qs方法
可以将编码后的url参数进行解码。
from urllib import parse
params = {'name':'张三','age':10,'greet':'hello world'}
qs = parse.urlencode(params)
print(qs)
resuit = parse.parse_qs(qs)
print(resuit)

(5)urlsplit方法
我感觉这个方法和urlparse方法差不多,都是对url中各个组成部分进行分割。
from urllib import parse
url = 'http://www.baidu.com/s?wd=python&username=abc#1'
result = parse.urlsplit(url)
print('scheme:',result.scheme)
print('netloc:',result.netloc)
print('path:',result.path)
print('query:',result.query)
1.2.3 error模块
error模块一般用于进行异常处理,其中包含两个重要的类:URLError和HTTPError。
注意,HTTPError是URLError的子类,所以捕获异常时一般要先处理HTTPError,常用的格式如下:
import urllib.request
import urllib.error
import socket
try:
response = urllib.request.urlopen('http://www.baidu.com/', timeout=0.1)
except urllib.error.HTTPError as e:
print("Error Code: ", e.code)
print("Error Reason: ", e.reason)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('Time out')
else:
print('Request Successfully')
爬虫(三):urllib模块的更多相关文章
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- 练手爬虫用urllib模块获取
练手爬虫用urllib模块获取 有个人看一段python2的代码有很多错误 import re import urllib def getHtml(url): page = urllib.urlope ...
- 洗礼灵魂,修炼python(53)--爬虫篇—urllib模块
urllib 1.简介: urllib 模块是python的最基础的爬虫模块,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如 ...
- 爬虫之urllib模块
1. urllib模块介绍 python自带的一个基于爬虫的模块. 作用:可以使用代码模拟浏览器发起请求. 经常使用到的子模块:request,parse. 使用流程: 指定URL. 针对指定的URL ...
- 爬虫框架urllib 之(三) --- urllib模块
Mac本 需导入ssl import ssl ssl._create_default_https_context = ssl._create_unverified_context urllib.re ...
- Python 爬虫三 beautifulsoup模块
beautifulsoup模块 BeautifulSoup模块 BeautifulSoup是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查 ...
- Python爬虫urllib模块
Python爬虫练习(urllib模块) 关注公众号"轻松学编程"了解更多. 1.获取百度首页数据 流程:a.设置请求地址 b.设置请求时间 c.获取响应(对响应进行解码) ''' ...
- urllib模块学习
一.urllib库 概念:urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urll ...
- 爬虫开发.2urllib模块
一.urllib库 概念:urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urll ...
随机推荐
- Spring 核心技术与产品理念剖析(上)
IT 技术发展太快了,就像浪潮一样一波接着一波,朝你迎面扑来,稍不留神就会被巨浪卷至海底而不得翻身.我们必须要学会抓住那些不变的本质或规律,只有这样才能屹立潮头而不倒,乘风破浪,做这个巨变时代的弄潮儿 ...
- Kafka分区分配策略分析——重点:StickyAssignor
“ 为什么Kafka在RangeAssigor.RoundRobinAssignor的基础上,又新增了PartitionAssignor,它解决了什么问题?” 背景 用过Kafka的同学应该都知道Ka ...
- Python一秒搭建ftp服务器,帮助你在局域网共享文件
"老板 来碗面" "要啥面?" "内牛满面.." 最近项目上的事情弄得人心累,本来是帮着兄弟项目写套入口代码,搞着搞着就被拉着入坑了.搞开发 ...
- Python如何爬取实时变化的WebSocket数据
一.前言 作为一名爬虫工程师,在工作中常常会遇到爬取实时数据的需求,比如体育赛事实时数据.股市实时数据或币圈实时变化的数据.如下图: Web 领域中,用于实现数据'实时'更新的手段有轮询和 WebSo ...
- v-bind和v-model的本质区别和作用域
每篇一句 一场寂寞凭谁诉.算前言,总轻负. Vue视图数据展示方式和彼此的区别: {{插值表达式}} {{}}插值表达式里面 只能写表达式,不能写语句 文本输出,不会解析标签 不能作用在标签的属性上, ...
- jenkins的部署
一.jenkins相关工具安装 基于tomcat安装iptables -F setenforce 0 systemctl stop firewalld.service Jdk安装 wgt htt ...
- [TimLinux] JavaScript input框的onfocus/onblur/oninput/onchange事件介绍
1. onfocus事件 input框获取到焦点时,触发了该事件,比如获取到焦点时,修改input框的背景色.这个功能其实可以使用css的伪类:focus来定义. 2. onblur事件 这个与onf ...
- [TimLinux] Python 函数
1. 函数(function)与方法(method)的区别 方法:在类结构体中通过def语句声明的代码块称为方法,比如类方法(classmethod),实例方法,静态方法(staticmethod)等 ...
- CodeForces-999A-Mishka and Contest
Mishka started participating in a programming contest. There are nn problems in the contest. Mishka' ...
- OSC2019关于开源的见闻-开源让世界更美好 社会更文明
一.开源生态报告-红薯-开源中国创始人 1.协作乏力-大厂同样 2.协议许可证使用不当 新许可证-木兰 3.开发者对法律认识完全不够 著作权意识不够 红线意识不够 相关法律法规的熟悉不够 维权及其弱势 ...