WebGIS中GeoHash编码的研究和扩展
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/。
1.背景
1.1普通地理编码流程
将采集的POI入库后,数据库里保存有该POI的位置描述、X、Y等信息。当需要进行逆编码查询时,前端传入坐标的X、Y值,后台构建查询范围查询,并且对查询出来的值进行距离排序。
1.2普通地理编码的几点劣势
a.前端查询url中的X、Y值为真实值,可能会暴露相关真实信息。
b.前端查询的url因为X、Y值的长度而变得比较长。
c.后台中,需要同时对X列、Y列做查询判断。
d.因为传入的X、Y值总在变化,数据库中的查询很难进行缓存优化。
e.数据库中保存的是真实X、Y数据,增加了存储空间。
2 GeoHash算法简介
2.1算法背景
Geohash的初衷是如何用尽量短的URL来标志地图上的某个位置,而地图上的位置一般是用经纬度来表示,问题就转化为如何把经纬度转化为一个尽量短的URL。
2.2GeoHash算法的描述
具体来说GeoHash算法的主要思想是对某一数字通过二分法进行无限逼近。这里以经纬度区间(经度(-180,180),纬度(-90,90))为例子来进行讲解。
2.2.1 哈夫曼编码
假设纬度值为48,精确到1度即可,则其编码流程如下所示:
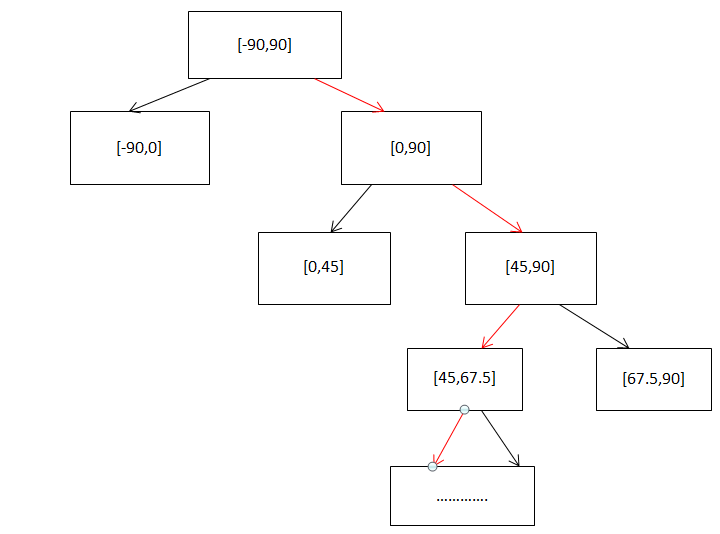
以左向为0,右向为1,最后48精确到1度的编码为:11000010。
对经度同样可以做该编码逼近。
2.2.2编码融合
对经纬度分别做了编码后,需要将两个编码进行融合。融合规则为:将经度和纬度的编码合并,奇数位是纬度,偶数位是经度。
比如:纬度39.92324精确到0.001后的编码为1011 1000 1100 0111 1001。经度116.3906精确到0.001后的编码为1101 0010 1100 0100 0100。两者融合后的编码为:11100 11101 00100 01111 00000 01101 01011 00001。
2.2.3 编码字符串化
这里使用Base32算法对编码进行字符串 化,Base32的规则如下:
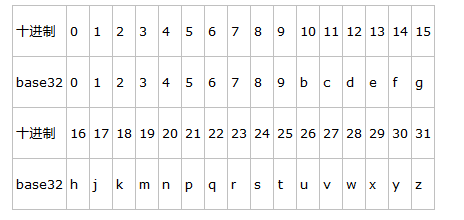
我们将39.92324, 116.3906(11100 11101 00100 01111 00000 01101 01011 00001)进行Base32的字符串化后获得字符串:wx4g0ec1。
3.基于GeoHash算法的扩展
3.1互联网GeoHash算法的局限
互联网GeoHash算法主要针对的是经纬度系统,所以其算法中的编码范围、编码精确度都相对固定。
范围为[-90,90],[-180,180]。
在纬度相等的情况下:
经度每隔0.00001度,距离相差约1米;
每隔0.0001度,距离相差约10米;
每隔0.001度,距离相差约100米;
每隔0.01度,距离相差约1000米;
每隔0.1度,距离相差约10000米。
在经度相等的情况下:
纬度每隔0.00001度,距离相差约1.1米;
每隔0.0001度,距离相差约11米;
每隔0.001度,距离相差约111米;
每隔0.01度,距离相差约1113米;
每隔0.1度,距离相差约11132米。
Geohash,如果geohash的位数是6位数的时候,大概为附近1千米。
但是假如需要编码的坐标为平面坐标时,以上算法必须进行相关修改才能使用。
3.2GeoHash算法扩展
3.2.1 根据所需精确度获取编码长度
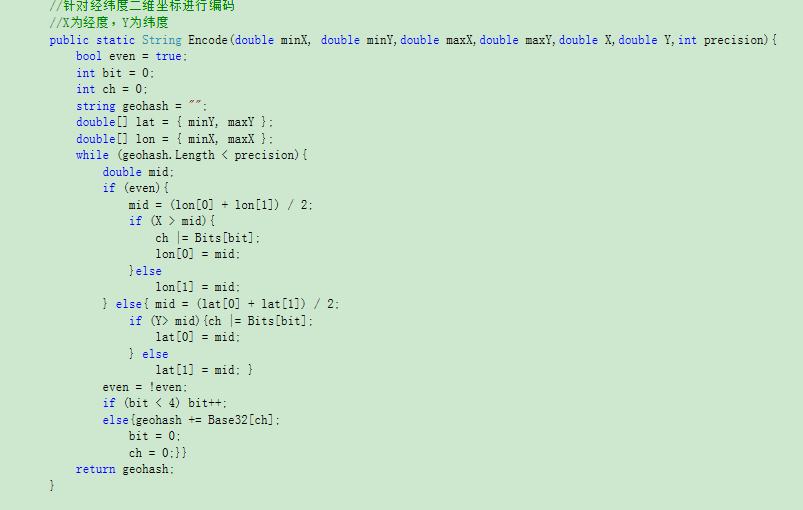
这里以平面坐标系为例子。平面坐标的单位是M,如果想要编码的精确度精确到1M,则需要算出此时需要保留的编码长度应该是多少。具体算法与哈夫曼编码的思路基本相同,以下是代码截取:

这里,需要知道编码范围、编码精确位数。因为5位数的编码等于一个Base32字符串,所以最后返回的值除以5。
当然,这里是经纬度坐标系也可以,只要规定好范围以及编码精确位数即可。
3.2.2 编码算法优化
编码时,编码范围不再是固定的经纬度范围,而是根据传递进来的范围值来进行编码。具体代码如下:
4.性能测试
4.1数据准备
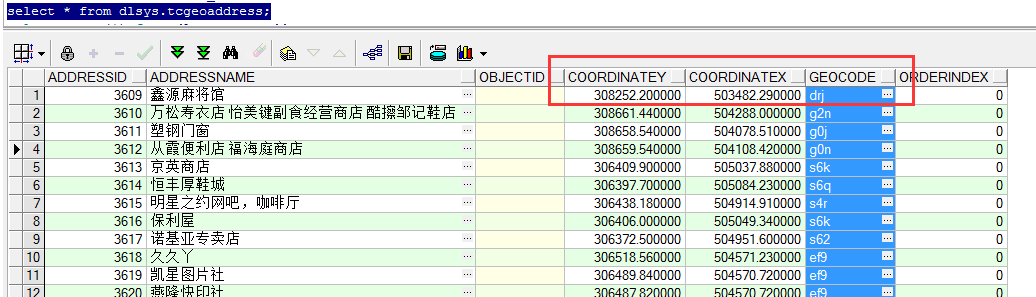
这里我准备了13万条数据(测试数据中大量重复数据):

数据为平面坐标系数据,对所有数据已经进行了GeoHash编码,为了方便测试,这里同样存入了X、Y坐标。
4.2 普通编码查询 VS GeoHash编码查询
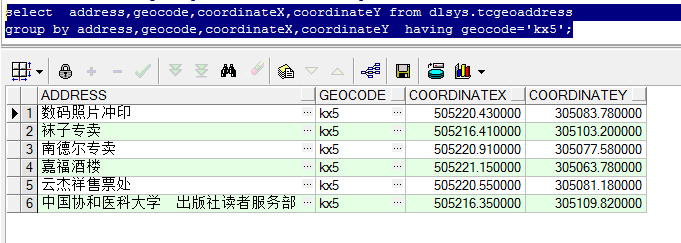
测试坐标点为:505214.06,305104.09。对其进行精确到100M的GeoHash编码,编码值为:kx5。
4.2.1范围查询命中率
4.2.1.1普通查询命中率
查询中为了去掉重复项,所以稍显繁琐。
查询范围为(CoordinateX < 505314.06 and CoordinateX > 505114.06 and CoordinateY < 305204.09 and CoordinateY >305004.09)具体如下,共查询到:12项。

4.2.1.2 GeoHash查询命中率
因为编码已经精确到100M了,所以直接等于该编码即可,查询得到的结果为6项。
4.2.1.3 对比分析
对比两种查询,很明显GeoHash编码查询法查询到的数据要少一些。仔细分析可见:在传统查询中,距离在50M以内的前6项,均出现在了GeoHash查询中。但是其他6项则没有。
我们可以推断为,虽然编码精度设置的为100M,但是最后一位的编码应该具体是精确到了100/2=50M 的范围。
所以,我们可以推断:GeoHash是能大致查询出要求范围的数据的,精确度比较高,但是查询所得数据量比真实的范围查询要少。
4.2.2 查询效率
4.2.2.1普通查询
清除查询缓存后,进行范围查询,需要0.281S。
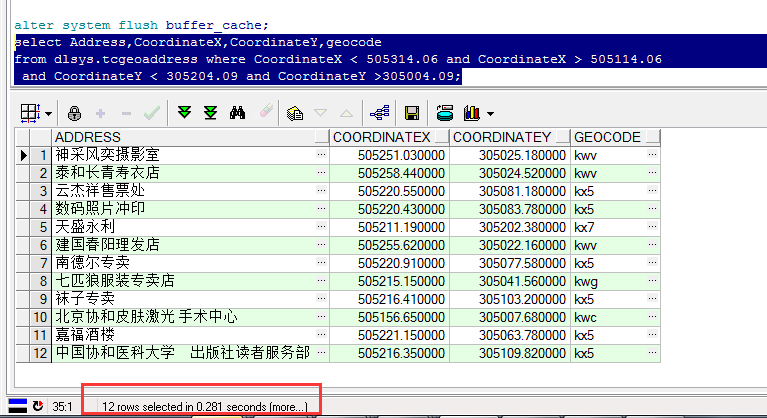
在X、Y上分别建立索引后,需要0.172S。

4.2.2.2 GeoHash查询
不建立索引,需要耗时0.499S。
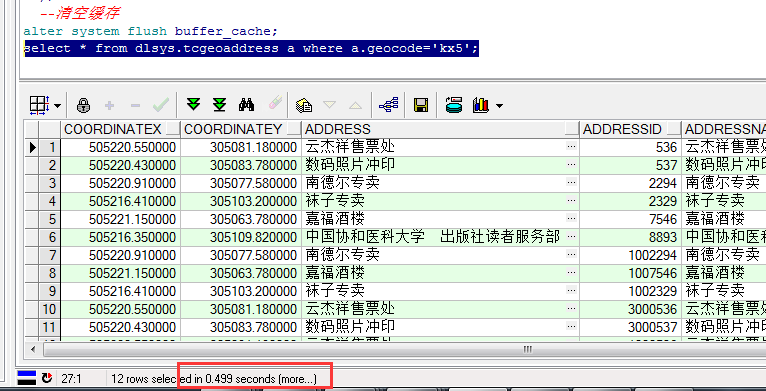
建立索引后,耗时0.156S。
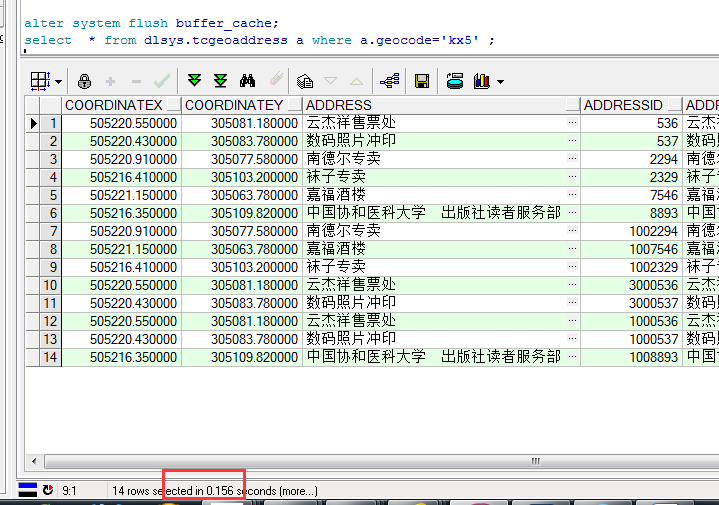
第二次命中时,耗时:0.031S。
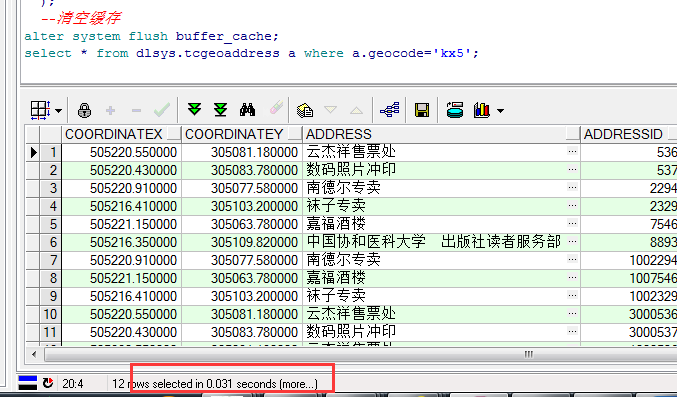
4.2.2.3查询性能对比分析
4.2.2.3.1查询时间
不考虑网络环境、查询时电脑本身CPU等性能偶然影响,单纯测试结果如下:
|
查询类型 (数据量13W) |
无索引查询时间 |
有索引查询时间 |
二次命中时间 |
|
普通地理编码查询 |
0.281S |
跟索引建立方式有关系,单纯在XY上建立索引,时间反而更久,需要:0.172S |
0.094S |
|
GeoHash编码查询 |
0.499S |
0.156S |
0.031S |
可见GeoHash因为是字符串查询,其本身是比较耗时的。但是当做了索引后,其查询速度是快于普通查询的,而且其二次命中时查询速度比普通查询二次命中会更快。其原因比较简单:单列索引、单列命中显然是高于多列的。
4.2.3.2 资源消耗分析
普通查询的资源消耗信息:

GeoHash查询的资源消耗信息:

其中:
cardinality是指计划中这一步所处理的行数。
cost指cbo中这一步所耗费的资源,这个值是相对值,和cpu_cost、io_cost是有关系的。
cost是由其他几个因素共同决定的,这里暂时不进行深入的研究。一般情况下,在一张表只有一条记录的情况下,cpu_cost会有个初始值(常见的是2万多或3万多),随着记录的增加,cpu_cost也成比例的增加。对于io_cost来说,如果访问的记录在一个db_block中,值是不变的。
bytes指cbo中这一步所处理所有记录的字节数,是估算出来的一组值。
对比性能分析表可见:
GeoHash表中的cardinality和bytes是明显低于普通查询的,究其原因也还是因为其只需查询一列即可。
5.总结
GeoHash算法的几个特点:
a.GeoHash编码后,获得的位置信息为范围信息,而非真实的坐标精确值。
b.GeoHash编码后,将X、Y坐标融合成一个值,数据库存在中既可以减少存储空间,也便于优化查询。尤其是编码后,一定范围内的点均是同样编码,兴趣点查询的二次命中率会大大提高,进一步加快查询速度。
c.GeoHash的编码可以容易的表示出范围包含关系,这样非常便于进行范围查询。
d.查询时前端URL长度变短。
6.三个问题
6.1如何查询最近点
GeoHash查询出来的仅仅是某个范围内的数据,需要对返回的数据在进行距离运算,排序后最近的便是。其优化效率主要体现在范围查询上。
6.2查询效率能优化多少?
测试在1W条数据以下时不明显。
10W条附近时,开始有0.1S间的小差距。
类推,当数据量越大时,效果越明显。
6.3两个点离的越近,geohash的结果相同的位数越多,对么?
这一点是有些用户对geohash的误解,虽然geo确实尽可能的将位置相近的点hash到了一起,可是这并不是严格意义上的(实际上也并不可能,因为毕竟多一维坐标),例如在方格4的左下部分的点和大方格1的右下部分的点离的很近,可是它们的geohash值一定是相差的相当远,因为头一次的分块就相差太大了,很多时候我 们对geohash的值进行简单的排序比较,结果貌似真的能够找出相近的点,并且似乎还是按照距离的远近排列的,可是实际上会有一些点被漏掉了。
上述这个问题,可以通过搜索一个格子,周围八个格子的数据,统一获取后再进行过滤。这样就在编码层次解决了这个问题。
既然不能做到将相近的点hash值也相近,那么geohash的意义何在呢?
个人觉觉得geohash还是相当有用的一个算法,毕竟这个算法通过无穷的细分,能确保将每一个小块的geohash值确保在一定的范围之内,这样就为灵活的周边查找和范围查找提供了可能。
7.最后提一个有趣的问题——伦敦到纽约的距离怎么算

这个问题是前几天一个读博士的朋友问的我,思考这个问题挺有趣的。其中会涉及到长距离和短距离问题,推荐一篇类似博客:我们看到的地图一直都错得离谱(http://blog.sina.com.cn/s/blog_517eed9f0102w4rm.html);
-----欢迎转载,但保留版权,请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
如果您觉得本文确实帮助了您,可以微信扫一扫,进行小额的打赏和鼓励,谢谢 ^_^

WebGIS中GeoHash编码的研究和扩展的更多相关文章
- 空间搜索(圆范围)中Geohash编码方案和网格编码方案对比探讨
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 多个项目中实现范围(圆)搜索的方案为:依赖库表中的X和Y字段构 ...
- 中文在unicode中的编码范围
以前写过一篇贴子是写中文在unicode中的编码范围 unicode中文范围,但写的不是很详细,今天再次研究了下unicode,并给出详细的unicode取值范围. 本次研究的unicode对象是un ...
- NeurIPS 2018 中的贝叶斯研究
NeurIPS 2018 中的贝叶斯研究 WBLUE 2018年12月21日 雷锋网 AI 科技评论按:神经信息处理系统大会(NeurIPS)是人工智能领域最知名的学术会议之一,NeurIPS 2 ...
- python语言中的编码问题
在编程的过程当中,常常会遇到莫名其妙的乱码问题.很多人选择出了问题直接在网上找答案,把别人的例子照搬过来,这是快速解决问题的一个好办法.然而,作为一个严谨求实的开发者,如果不从源头上彻底理解乱码产生的 ...
- (十八)WebGIS中清空功能和地图定位功能的设计以及实现
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.背景 当地图中增加了很多元素后,对不同的元素需要进行一定的控制,最 ...
- (十六)WebGIS中偏移补偿量引发的问题之探讨
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.背景 在上一章里讲解地图平移功能的实现时,我在最后提出了两个问题: ...
- (十五)WebGIS中平移功能的设计和实现
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.前言 这一章我们将详细讲解WebGIS工具栏中另一个基础工具——平 ...
- (十三)WebGIS中工具栏的设计之命令模式
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.背景 从这一章节开始我们将正式进入WebGIS的工具栏中相关功能的 ...
- (十一)WebGIS中要素(Feature)的设计
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/. 1.前言 在GIS中元素一般分为点元素,线元素,面元素以及symbol ...
随机推荐
- (转)C# XMPP客户端与openfire通信(Matrix Xmpp 授权破解教程)
FROM:http://www.cnblogs.com/crabo/p/CRACK_MATRIX_XMPP.html 如此著名的XMPP , 居然试过jabber-net, agsXmpp,matri ...
- c++ 宏定义声明类,并在类中实现回调
#include <iostream> #include <windows.h> #include <string> using namespace std; ty ...
- Devexpress treeList
1.数据绑定最基本的两个属性:KeyFieldName和ParentFieldName. SELECT OfficeID,OfficeName,ParentOfficeID FROM tOffice ...
- .NET各大平台数据列表控件绑定原理及比较(WebForm、Winform、WPF)
说说WebForm: 数据列表控件: WebForm 下的列表绑定控件基本就是GridView.DataList.Repeater:当然还有其它DropDownList.ListBox等. 它们的共同 ...
- .NET面试题系列[13] - LINQ to Object
.NET面试题系列目录 名言警句 "C# 3.0所有特性的提出都是更好地为LINQ服务的" - Learning Hard LINQ是Language Integrated Que ...
- java中文乱码解决之道(四)-----java编码转换过程
前面三篇博客侧重介绍字符.编码问题,通过这三篇博客各位博友对各种字符编码有了一个初步的了解,要了解java的中文问题这是必须要了解的.但是了解这些仅仅只是一个开始,以下博客将侧重介绍java乱码是如何 ...
- MySQL mysqlslap压测
200 ? "200px" : this.width)!important;} --> 介绍 mysqlslap是mysql自带的一个性能压测工具:mysqlslap用于和其 ...
- WinRAR 4.20 beta2 key!注册文件 注册码
WinRAR 4.20 beta2 key!注册文件 注册码 WinRAR 4.20 beta2注册文件 WinRAR 4.20 beta2 working key ================= ...
- CentOS 7 网络配置
Virtual box 安装了CentOS 7最小模式后马上用ifconfig命令查看网络情况,发现该命令不存在. [root@centos1 ~]# ifconfig -bash: ifconfig ...
- Atitit 分区后的查询 mysql分区记录的流程与原理
Atitit 分区后的查询 mysql分区记录的流程与原理 1.1.1. ibd是MySQL数据文件.索引文件1 1.2. 已经又数据了,如何分区? 给已有的表加上分区 ]1 1.3. 分成4个区, ...