《Predict Anchor Links across Social Networks via an Embedding Approach》阅读笔记
基本信息
文献:Predict Anchor Links across Social Networks via an Embedding Approach
时间:2016
期刊:IJCAI
引言
预测跨社交网络的锚链接对于一系列应用具有重要意义,包括跨网络信息扩散和跨域推荐。一个具有挑战性的问题是:如果只有网络的结构信息可用,我们是否能够以及在多大程度上解决锚链预测问题。
有关锚链接的信息通常在实际情况下不可用,因为大多数用户没有动机或不愿意在不同的在线社交网络中明确关联他们的身份。这就引出了锚链接预测的问题,即,识别跨不同社交网络的隐藏锚链接。利用网络结构进行锚链预测的现有方法分为两大类:
第一类方法是以无监督的方法来解决,因此不需要任何关于跨网络的显式对应的信息。这些方法将锚链接预测问题看作一个网络结构对齐问题,通过在网络中找到节点之间的某些结构相似性来进行解决,但这种方法通常是 NP-Hard 的组合优化问题。因此,这些方法要么限于具有中等规模的网络,要么仅适用于稀疏假设下的大规模网络。
第二类方法是采用监督的方法,即通过已知的锚链接的监督来解决锚链接预测问题。大多数现有的监督方法直接采用社交网络的结构特征,例如度,聚类系数,涉及的三角形的数量,共同的邻居等。在没有捕获社交网络的内在结构规律的情况下,这些方法对网络结构特别敏感,因此网络结构的轻微变化或噪声可能导致显着不同的结果。
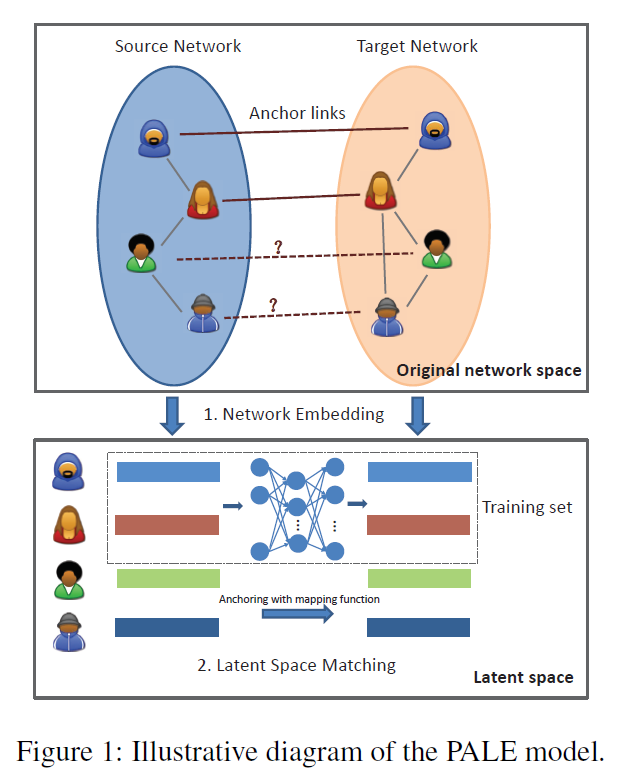
为了弥补这些差距,作者提出了一个新的监督方法,称为 PALE(Predicting Anchor Links via Embedding)来解决锚链接预测问题。该模型包含两个锚链接感知阶段,即嵌入和匹配。
嵌入(Embedding):该阶段主要是将每个网络嵌入到一个低维向量空间来学习每个节点的有效表示。通过这种方式,可以很好地捕获网络的主要结构规律,同时滤除无关紧要的一些细节。同时,利用观察到的锚链作为监督信息,网络嵌入也保留了特定的结构规律,该方法使我们的模型对网络结构的微小变化具有鲁棒性。
匹配(Matching):该阶段主要是将节点的低维表示作为特征,并以已经观察到的锚链接作为监督信息,从而学习两个低维空间之间的映射函数。为了使得两个潜在空间可以灵活地进行非线性相关,作者采用了多层感知器(MLP)来学习映射函数。最后,对于一个网络中的每个节点,我们根据学习的映射函数识别另一个网络中最可能的对应节点。
除了鲁棒性之外,作者提出的模型的另一个重要优点是网络结构的低维表示可以容易地与内容和人口统计特征相结合,以进一步提高锚链预测的准确性。
Predict Anchor Links via Embedding
令 \(G=\lbrace V,E \rbrace\) 表示一个社交网络,\(V\) 表示节点集合,\(E\subset (V\times V)\) 表示边集合。在生活中,存在一些用户同时涉及到两个不同的社交网络中,从而两个社交网络间的锚链接。为了不失一般性,将其中一个网络作为源网络,另一个网络作为目标网络,分别用 \(G^s\) 和 \(G^t\) 表示。对于源网络的每一个节点,我们的目的是在目标网络中识别其对应的节点(如果存在的话)。这可以正式表述为以下锚链接预测问题。
Anchor link prediction:
给定两个社交网络 \(G^s=\lbrace V^s,E^s \rbrace\) 和 \(G^t=\lbrace V^t,E^t \rbrace\) ,和一个已经观察到的锚链接集合 \(T=\lbrace (v,u)|v\in V^s, u\in V^t \rbrace\),该问题旨在识别 \(G^s\) 和 \(G^t\) 间的其它隐藏锚链接。
作者通过将两个社交网络分别表示为两个低维空间 \(Z^s\) 和 \(Z^t\) ,然后再学习两个嵌入空间的映射函数: \(\phi:Z^s \to Z^t\)。因此,PALE 模型的目的就是通过最小化下列目标函数来找到最佳的 \(Z^s\), \(Z^t\) 和 \(\phi\) 。
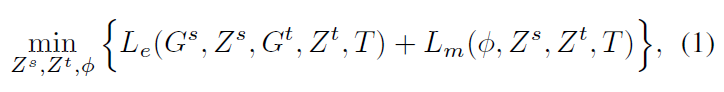
其中,\(L_e(G^s,Z^s,G^t,Z^t,T)\) 表示将源网络 \(G^s\) 和目标网络 \(G^t\) 分别转化为低维空间 \(Z^s\) 和 \(Z^t\) 的损失,而 \(L_m(\phi, Z^s,Z^t,T)\) 是匹配时的损失函数,反映了匹配函数 \(\phi\) 是否将在 \(T\) 中已知的锚链接正确预测。
然而,由于 \(Z^s\), \(Z^t\) 和 \(\phi\) 之间的相互依赖,上述的目标函数很难得到有效地最优解。因此,作者采用了两阶段的嵌入和匹配的方法来转而去找到一个近似解。如下图所示:
嵌入阶段
该阶段将每一个网络都嵌入到一个低维潜在空间,每个节点 \(v_i\) 被表示为一个低维向量 \(z_i\)。该问题的关键是对社交网络中那些未观察到的边的处理,即那些还未明确建立地或者没有爬取成功的社交关系。当将网络嵌入潜在空间时,这些缺失的边可能导致不可靠的表示。
跨网络扩展
因此,作者提出了一个基于已经观察到的锚链接和其它网络的社交结构来识别隐藏的边的策略。如果两个节点在一个社交网络中没有关联关系,但是他们在另一个社交网络中的对应节点间存在关联关系,则应该在当前网络中增加这两个节点间的边,如 Figure 2 所示:
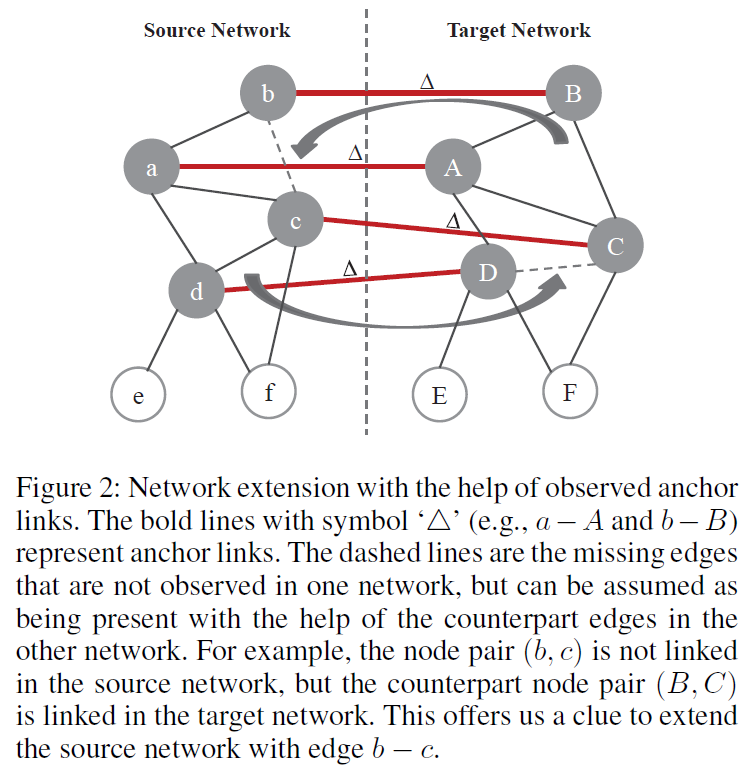
即,对于给定的两个社交网络 \(G^s\) 和 \(G^t\),以及它们之间的已观察到的锚链接集合 \(T\)。源网络 \(G^s\) 的扩展网络 \(\tilde{G}^s\) 可以表示为:
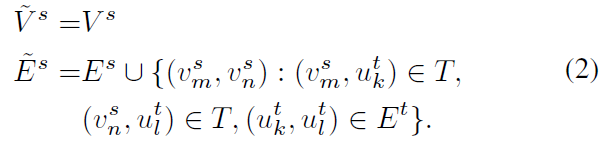
注意,在该模型中,扩网络扩展并不是强制要求的。该步骤只是为了更好地进行网络表示。
网络嵌入
由于是独立地将两个网络嵌入到两个向量空间,所以该部分对于源网络和目标网络使用不加上标的统一表示。对于一对节点 \(v_i\) 和 \(v_j\),给定他们的 \(d\) 维表示 \(z_i\) 和 \(z_j\),则它们之间观察到边的概率为:
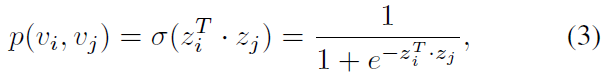
为了学习网络的潜在表示,作者采用极大似然估计的方法,即根据给定的网络结构来反推出最有可能出现该结构的节点表示,即最大化以下目标函数:
\[L=\prod_{(i,j)\in \tilde{E}}{p(v_i,v_j)}\]
将其转化为对数似然函数:
\[\sum_{(i,j)\in \tilde{E}}{\log p(v_i,v_j)}=\sum_{(i,j)\in \tilde{E}}{\log \sigma(z_i^T\cdot z_j)}\]
作者进一步引入了负采样机制,但是这部分的原理本人没有弄懂:
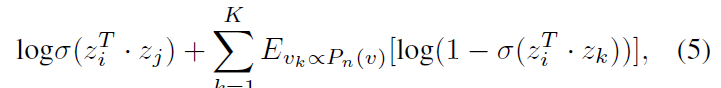
直接使用极大似然估计会存在什么问题?
负采样的原理和机制是怎么样的?
负采样的推理过程?
其中,第一项对已观察的边进行建模,第二个期望项从一个空模型中采样负边(negative edges),每个节点以概率 \(P_n(v)\sim d_v^{3/4}\),\(K\) 为采样的负边的数目,\(d_v\) 为节点的度。通过分别对两个社交网络中所有边按照公式(5)求和并进行最大化就能得到两个社交网络的潜在表示,最大化的过程可以将其转化为最小化而使用随机梯度下降的方法。
负采样
本文提到的负采样机制参考了 skip-gram 模型,具体内容可以参看 文献一 和 基于 Negative Sampling 的模型。
该思想是采用了噪音对比估计(Noise Contrastive Estimation, NCE),该方法认为一个好的模型应该能够通过逻辑回归将数据与噪声区分开来。由于 Skipgram 模型仅关注学习高质量的向量表示,因此只要向量表示保持其质量,我们就可以自由地简化 NCE 。采用公式(4)的方式定义负采样来替换 Skip-gram 目标函数中的每一个 \(\log P(w_O|w_I)\) 项。因此,任务是使用逻辑回归将目标词 \(w_O\) 与从噪声分布 \(P_n(w)\) 抽样的词区分开,其中对于每个数据样本存在 k 个负样本。负采样和 NCE 之间的主要区别在于 NCE 需要样本和噪声分布的数值概率,而负采样仅使用样本。
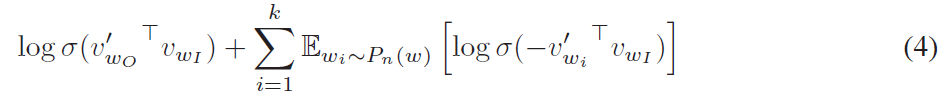
匹配阶段
在匹配阶段,基于学习到的两个网络的潜在表示,其目的是利用已知的锚链接 \((v_l^s,u_n^t)\in T\) 以及对应的潜在表示 \(z_l^s\) 和 \(z_n^t\) 来学习一个映射函数 \(\phi\)。映射函数的目的是使得在源网络 \(Z^s\) 中的节点表示 \(z_l^s\) ,经过映射函数 \(\phi\) 后,其与在目标网络 \(Z^t\) 中对应节点的距离应该最小。令 \(\Theta\) 表示映射函数的所有参数,则损失函数可以如下定义:
\[L_m(\phi,Z^s,Z^t,T)=\sum_{(v_l^s,u_n^t)\in T}{||\phi(z_l^s;\Theta)-z_n^t||_F}\]
对于映射函数,作者分别考虑了线性和非线性函数。
对于线性映射函数,\(\Theta\) 是一个 \(d\times d\) 维的矩阵,即:
\[\phi(z_l^s;\Theta)=\Theta \times z_l^s\]
其目的是找到一个最好的矩阵 \(\Theta\) ,使得对于所有标记的锚链接对 \((v_l^s,u_n^t)\in T\) 都有 \(\Theta \times v_l^s\) 非常近似于 \(v_n^t\) 。
对于非线性映射函数,作者采用了多层感知器(MLP)来捕获源空间和目标空间的非线性关系。以这种方式,在网络嵌入阶段中获得的两个空间不需要线性对齐,这为嵌入阶段提供了更大的灵活性以捕获网络的结构规律。
锚链接预测
预测阶段,对于源网络中的任意一个节点 \(v_l^s\),首先获取其嵌入表示 \(z_l^s\);然后根据学习到的映射函数 \(\phi(z_l^s; \Theta)\) 将其映射到目标向量空间;最后通过识别与 \(\phi(z_l^s; \Theta)\) 最接近的对应节点 \(u_n^t\) 来预测锚链接,对应节点可以通过以下方式查找:
\[\min_n||\phi(z_l^s; \Theta)-z_n^t||_F\]
对于源网络的每个节点,都可以通过上述方式提供目标网络中的一个候选节点列表。从而用
hits指标评估。
时间复杂度
在嵌入阶段,一个网络 \(G\) 的总时间复杂度为 \(O(kd|E|)\),其中 \(k\) 为迭代次数,\(d\) 是嵌入向量的维度,\(|E|\) 是网络中边的数目。
在潜在空间匹配阶段,线性映射函数和非线性映射函数有不同的时间复杂度。线性映射函数的时间复杂度为 \(O(|T|d^3)\);而使用 MLP 作为非线性映射函数,其时间复杂度为 \(O(kd|T|)\)。
在预测阶段,对于任意一个节点,识别其在目标网络中的对应节点的时间复杂度为 \(O(|V|d^2)\)。
实验
实验采用两个数据集,一个是基于 Facebook 采样的两个子网络,另一个则是不同研究领域的两个共同作者网络。对比方案分别为:
- Degree-Based Alignment:即依据节点的度来进行匹配,作为一个基线方法;
- Matching Across Domains(MAD):它通过奇异值分解来匹配同构网络上的共享节点,采用无监督方法;
- Multi-Network Anchoring(MNA):它从部分对齐的社交网络中提取成对的社交特征,然后将锚链接预测问题解决为分类问题;
- Collective Random Walk(CRW):在具有锚链接的网络上进行随机游走以识别另一网络中的每个节点的对应物;
- PALE(LIN):PALE 模型加上线性映射函数;
- PALE(MLP):PALE 模型加上 MLP 作为非线性映射函数。
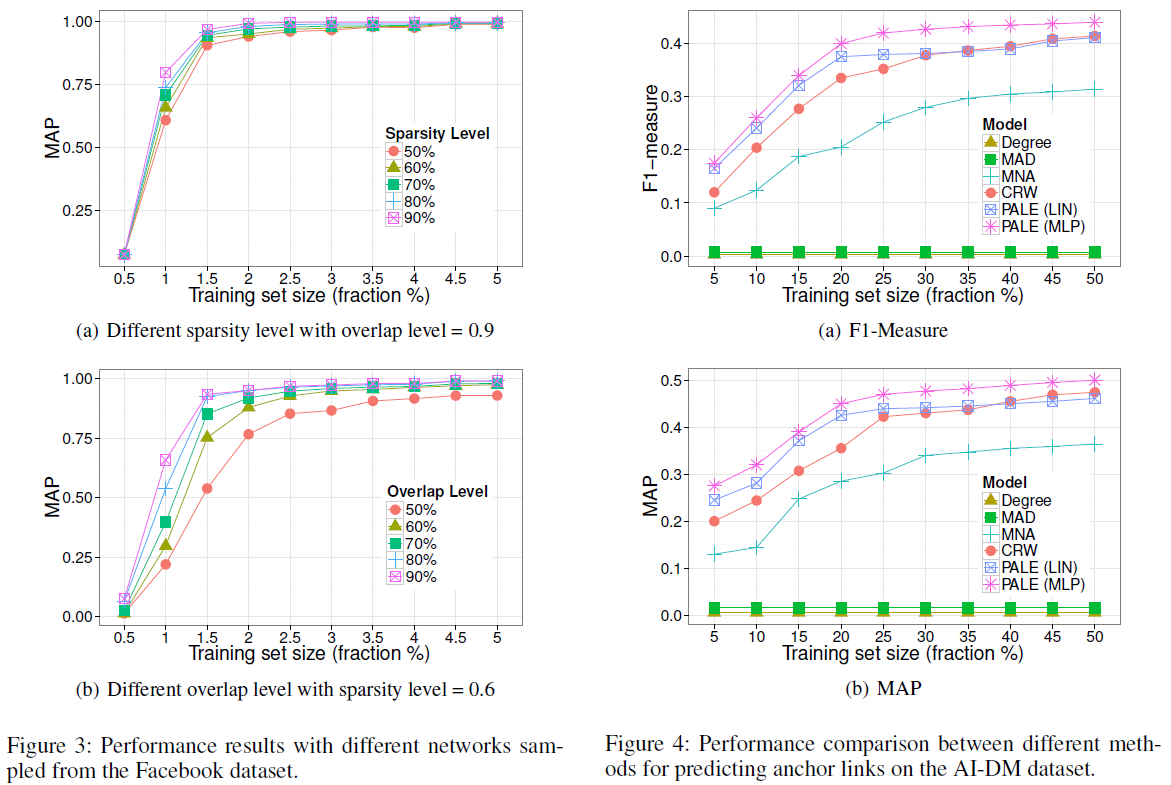
评估指标采用 F1-measure 和 MAP@30。
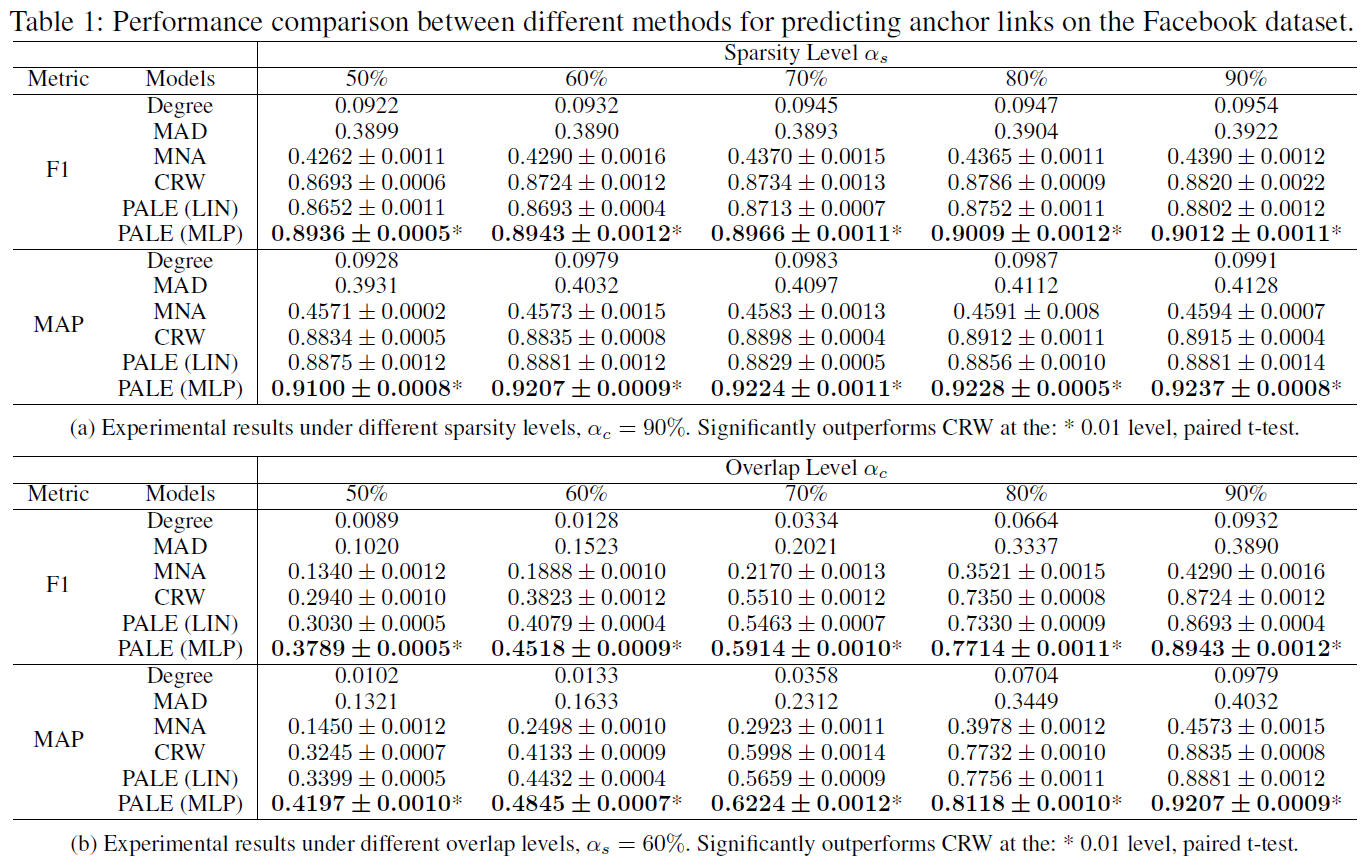
基于 Facebook 的实验
第一个数据集为 Facebook 数据集,作者首先过滤了那些度小于 5 的节点,最终保留了 40710 个用户和 766519 条边。接着作者基于过滤的数据采样得到两个子网络,每个网络都保留了原始网络中的所有节点。而对于每一条边,利用 [0, 1] 均匀分布来生成一个随机值。如果 \(p\leq 1-2\alpha_s+\alpha_s\alpha_c\),直接丢弃这条边;如果 \(1-2\alpha_s+\alpha_s\alpha_c < p \leq 1-\alpha_s\),则将其只保留在第一个子网络中;如果 \(1-\alpha_s< p \leq 1-\alpha_s\alpha_c\) ,则将其只保留在第二个子网络中;否则,将该条边同时保留在两个子网络中。通过上述方式,两个子网络都平均保留了原始网络中的 \(\alpha_s\) 比例的边。参数 \(\alpha_c\) 表明了两个子网络中有多少比例的边是共享的。
由于两个子网络都保留了原始网络中的所有节点,所以源网络和目标网络中的每对对应的节点都是可以作为 ground truth 的锚链接,实验选择其中的 \(\alpha_t\) 作为监督锚链接集合 \(T\),并分别在不同的稀疏级别 \(\alpha_s\) 和不同的覆盖级别 \(\alpha_c\) 上进行实验。
基于共同作者网络的实验
第二个数据集是由人工智能(AI)和数据挖掘(DM)领域的会议论文组成的共同作者网络,表示为 AI-DM。该数据集来源于 MAG ,这是一个异构图,包含出版物的数目信息,出版物之间的引文关系,以及作者和机构的信息。作者分别选择了 AI 和 DM 领域的 10 个会议,然后在这两组论文上建立了两个共同作者网络,并且过滤掉少于 3 个共同作者关系的作者。这两个网络间有 1154 个共同作者,形成了锚链接的 ground truth。
《Predict Anchor Links across Social Networks via an Embedding Approach》阅读笔记的更多相关文章
- 阅读《RobHess的SIFT源码分析:综述》笔记
今天总算是机缘巧合的找到了照样一篇纲要性质的文章. 如是能早一些找到就好了.不过“在你认为为时已晚的时候,其实还为时未晚”倒是也能聊以自慰,不过不能经常这样迷惑自己,毕竟我需要开始跑了! 就照着这个大 ...
- RobHess的SIFT源码分析:imgfeatures.h和imgfeatures.c文件
SIFT源码分析系列文章的索引在这里:RobHess的SIFT源码分析:综述 imgfeatures.h中有SIFT特征点结构struct feature的定义,除此之外还有一些特征点的导入导出以及特 ...
- RobHess的SIFT源码分析:综述
最初的目的是想做全景图像拼接,一开始找了OpenCV中自带的全景拼接的样例,用的是Stitcher类,可以很方便的实现全景拼接,而且效果很好,但是不利于做深入研究. 使用OpenCV中自带的Stitc ...
- 阅读《RobHess的SIFT源码分析:综述》笔记2
今天开始磕代码部分. part1: 1. sift特征提取. img1_Feat = cvCloneImage(img1);//复制图1,深拷贝,用来画特征点 img2_Feat = cvCloneI ...
- element-ui button组件 radio组件源码分析整理笔记(一)
Button组件 button.vue <template> <button class="el-button" @click="handleClick ...
- element-ui 组件源码分析整理笔记目录
element-ui button组件 radio组件源码分析整理笔记(一) element-ui switch组件源码分析整理笔记(二) element-ui inputNumber.Card .B ...
- element-ui Carousel 走马灯源码分析整理笔记(十一)
Carousel 走马灯源码分析整理笔记,这篇写的不详细,后面有空补充 main.vue <template> <!--走马灯的最外层包裹div--> <div clas ...
- STL源码分析读书笔记--第二章--空间配置器(allocator)
声明:侯捷先生的STL源码剖析第二章个人感觉讲得蛮乱的,而且跟第三章有关,建议看完第三章再看第二章,网上有人上传了一篇读书笔记,觉得这个读书笔记的内容和编排还不错,我的这篇总结基本就延续了该读书笔记的 ...
- element-ui MessageBox组件源码分析整理笔记(十二)
MessageBox组件源码,有添加部分注释 main.vue <template> <transition name="msgbox-fade"> < ...
- element-ui switch组件源码分析整理笔记(二)
源码如下: <template> <div class="el-switch" :class="{ 'is-disabled': switchDisab ...
随机推荐
- PHP提取字符串中的图片地址
PHP提取字符串中的图片地址 $str='<p><img border="0" src="upfiles/2009/07/1246430143_1.jp ...
- qt下的时钟程序(简单美丽,继承自QWidget的Clock,用timer调用update刷新,然后使用paintEvent作画就行了,超详细中文注释)good
最近抽空又看了下qt,发现用它来实现一些东西真的很容易比如下面这个例子,绘制了个圆形的时钟,但代码却清晰易懂[例子源自奇趣科技提供的例子]因为清晰,所以就只写注释了,吼吼其实也就这么几行代码头文件 / ...
- ORA-09925: Unable to create audit trail file
当我修改ORACLE_SID为新的SID,想进行数据库还原时,用sqlplus报如下错误 [oracle@dbtest ~]$ sqlplus / as sysdba SQL Production : ...
- 改善C#程序的建议7:正确停止线程
原文:改善C#程序的建议7:正确停止线程 开发者总尝试对自己的代码有更多的控制.“让那个还在工作的线程马上停止下来”就是诸多要求中的一种.然而事与愿违,这里面至少存在两个问题: 第一个问题是:正如线程 ...
- Qt在Mac OS X下的编程环境搭建(配置Qt库和编译器,有图,很清楚)
尊重作者,支持原创,如需转载,请附上原地址:http://blog.csdn.net/libaineu2004/article/details/46234079 在Mac OS X下使用Qt开发,需要 ...
- 用汇编语言给XP记事本添加“自动保存”功能 good
[文章标题]: 用汇编语言给XP记事本添加“自动保存”功能 [文章作者]: newjueqi [作者邮箱]:zengjiansheng1@126.com [作者QQ]:190678908 [使用工具] ...
- asp.net mvc下实现微信公众号(JsApi)支付介绍
本文主要讲解asp.net mvc框架下公众号支付如何实现,公众号支付主要包括三个核心代码,前台调起支付js代码.对应js调用参数参数生成代码.支付成功处理代码. 一.微信支付方式介绍 微信提供了各种 ...
- sublime3使用笔记
1.ctrl+n 新建一个文件: 2.alt+shift+数字 分屏显示: 3.ctrl+alt+down(向下键) 连选很多行的指定开始位置: 如图: 紧接着再按shift+right(选中需要更改 ...
- SYN591-C型 时间间隔表
SYN591-C型 时间间隔表 脉冲计数器数显计数器电机转速表使用说明视频链接: http://www.syn029.com/h-pd-250-0_310_44_-1.html 请将此链接复制到 ...
- Python连载16-reduce函数&filter函数
一.reduce函数 本函数释义: (1)原意是归并,缩减 (2)把一个可迭代的对象最后归并成一个结果 (3)对于作为参数的函数要求:必须由两个参数,必须返回一个结果 import functools ...