Python破解js加密实例(有道在线翻译)
在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如:
- 加cookie,身份验证UserAgent
- 图形验证,还有很难破解的滑动验证
- js签名验证,对传输数据进行加密处理
对于js加密
经过加密传输的就是密文,但是加密函数或者过程一定是在浏览器完成,
也就是一定会把js代码暴露给使用者
通过阅读加密算法,就可以模拟出加密过程,从而达到破解
怎样判断网站有没有使用js加密,很简单,例如有道在线翻译
- 1.打开【有道在线翻译】网页:http://fanyi.youdao.com/
- 2.【右键检查】,选中【Network】
- 3.【输入单词】
- 4.在请求中,找到关于翻译内容的Form Data,可以看到有下面两项说明js加密
“salt”: “1523100789519”,
“sign”: “b8a55a436686cd8973fa46514ccedbe”,
分析js
- 一定要按照下面的顺序,不然的话会有很多无用的东西干扰
- 1.打开【有道在线翻译】网页:http://fanyi.youdao.com/
- 2.【右键检查】,选中【Network】
- 3.【输入单词】,【抓取js代码】
- 操作截图:
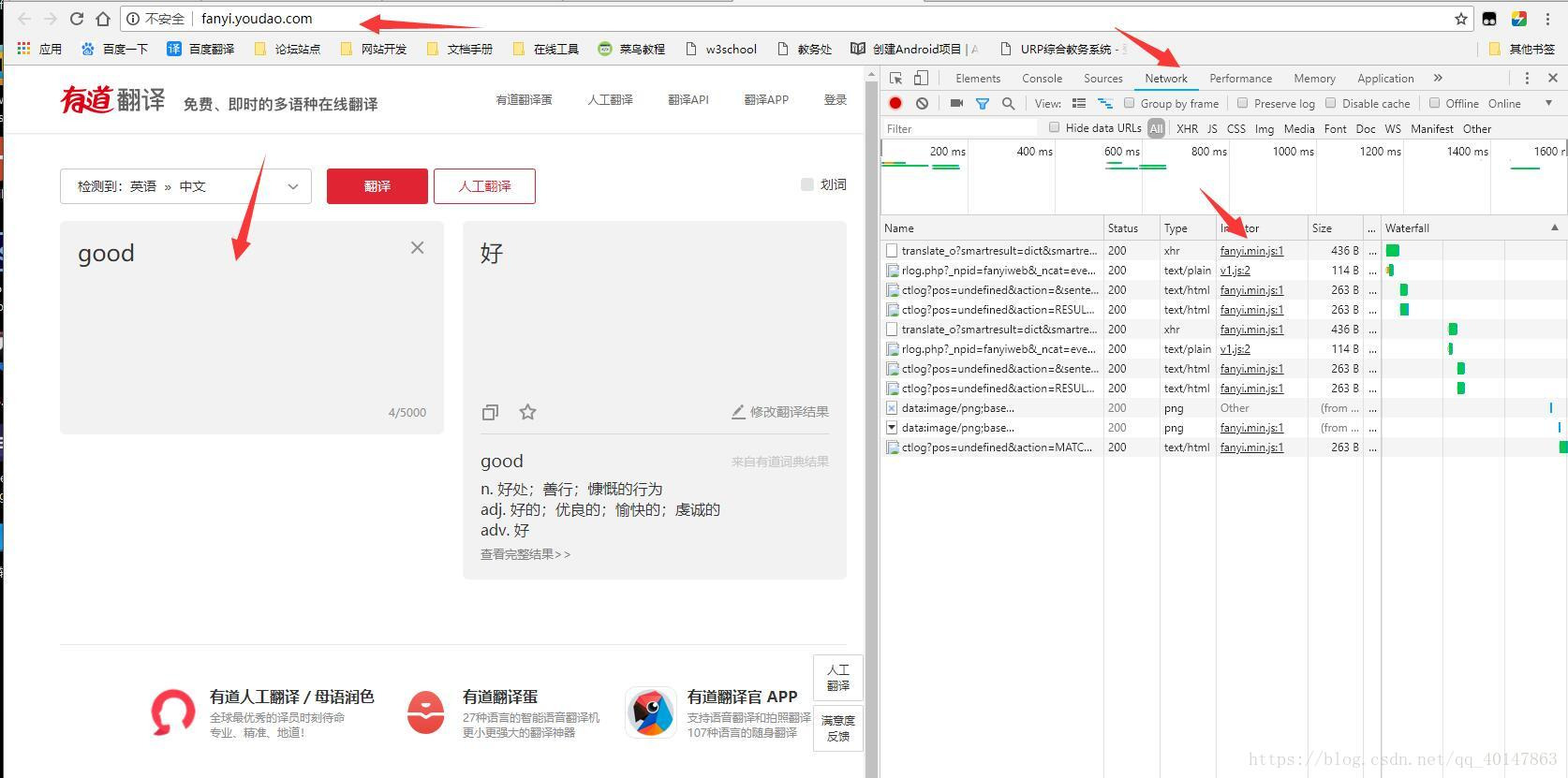
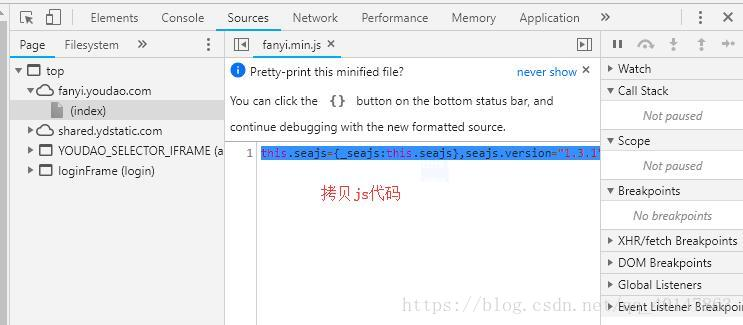
- 我们得到的js代码是一行代码,是压缩后的min代码,我们需要进行格式转换
- 4.打开在线代码格式化网站:http://tool.oschina.net/codeformat/js
- 5.将拷贝的一行格式的js代码,粘贴在表单中,点击【格式化】
- 操作截图:
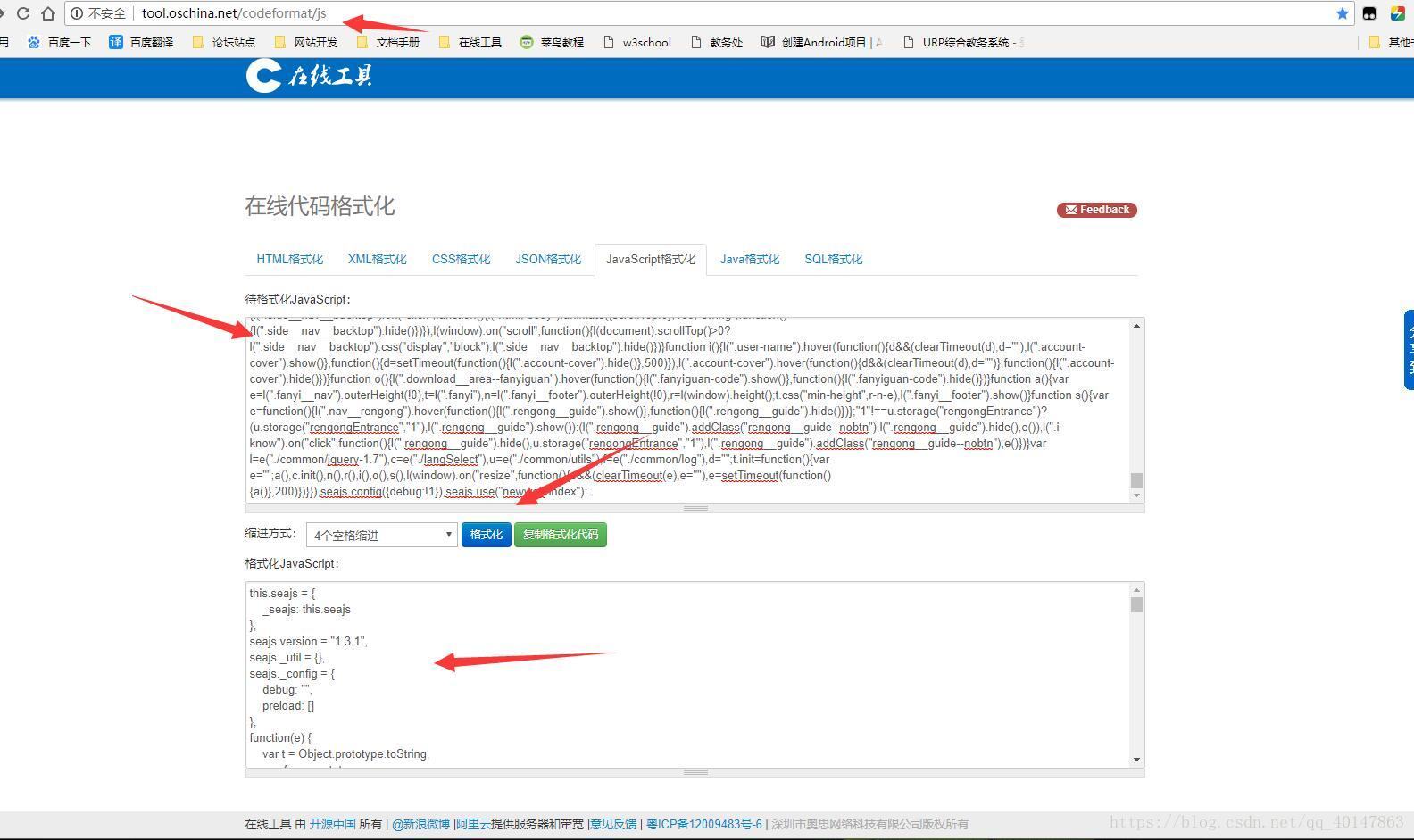
- 然后将格式化后的js代码,拷贝到一个可以搜索的代码编码器,备用
- 编写第2个版本
- 案例v18文件:
- https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py18js2.py
# 破解js加密,版本2
'''
通过在js文件中查找salt或者sign,可以找到
1.可以找到这个计算salt的公式
r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10))
2.sign:n.md5("fanyideskweb" + t + r + "ebSeFb%=XZ%T[KZ)c(sy!");
md5 一共需要四个参数,第一个和第四个都是固定值得字符串,第三个是所谓的salt,
第二个参数是输入的需要翻译的单词
Python学习交流群:857662006
'''
from urllib import request, parse def getSalt():
'''
salt的公式r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10))
把它翻译成python代码
'''
import time, random salt = int(time.time()*1000) + random.randint(0, 10) return salt def getMD5(v):
import hashlib
md5 = hashlib.md5() md5.update(v.encode('utf-8'))
sign = md5.hexdigest() return sign def getSign(key, salt): sign = "fanyideskweb" + key + str(salt) + "ebSeFb%=XZ%T[KZ)c(sy!"
sign = getMD5(sign)
return sign def youdao(key):
# url从http://fanyi.youdao.com输入词汇右键检查得到
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=true" salt = getSalt()
# data从右键检查FormData得到
data = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": str(salt),
"sign": getSign(key, salt),
"doctype": "json",
"version": "2.1",
"keyform": "fanyi.web",
"action": "FY_BY_REALTIME",
"typoResult": "false" }
print(data)
# 对data进行编码,因为参数data需要bytes格式
data = parse.urlencode(data).encode() # headers从右键检查Request Headers得到
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": len(data),
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "OUTFOX_SEARCH_USER_ID=685021846@10.168.8.76; OUTFOX_SEARCH_USER_ID_NCOO=366356259.5731474; _ntes_nnid=1f61e8bddac5e72660c6d06445559ffb,1535033370622; JSESSIONID=aaaVeQTI9KXfqfVBNsXvw; ___rl__test__cookies=1535204044230",
"Host": "fanyi.youdao.com",
"Origin": "http://fanyi.youdao.com",
"Referer": "http://fanyi.youdao.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
} req = request.Request(url=url, data=data, headers=headers)
rsp = request.urlopen(req) html = rsp.read().decode()
print(html) if __name__ == '__main__':
youdao("girl")
运行结果
返回翻译后的值,才算是成功
注意
按照步骤,熟悉流程最重要
---------------------
原文:https://blog.csdn.net/qq_40147863/article/details/82079649
Python破解js加密实例(有道在线翻译)的更多相关文章
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译) 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签 ...
- 爬虫破解js加密(一) 有道词典js加密参数 sign破解
在爬虫过程中,经常给服务器造成压力(比如耗尽CPU,内存,带宽等),为了减少不必要的访问(比如爬虫),网页开发者就发明了反爬虫技术. 常见的反爬虫技术有封ip,user_agent,字体库,js加密, ...
- Python爬虫—破解JS加密的Cookie
前言 在GitHub上维护了一个代理池的项目,代理来源是抓取一些免费的代理发布网站.上午有个小哥告诉我说有个代理抓取接口不能用了,返回状态521.抱着帮人解决问题的心态去跑了一遍代码.发现果真是这样. ...
- python爬虫---js加密和混淆,scrapy框架的使用.
python爬虫---js加密和混淆,scrapy框架的使用. 一丶js加密和js混淆 js加密 对js源码进行加密,从而保护js代码不被黑客窃取.(一般加密和解密的方法都在前端) http:// ...
- python爬虫_从零开始破解js加密(一)
除了一些类似字体反爬之类的奇淫技巧,js加密应该是反爬相当常见的一部分了,这也是一个分水岭,我能解决基本js加密的才能算入阶. 最近正好遇到一个比较简单的js,跟大家分享一下迅雷网盘搜索_838888 ...
- Python 爬虫js加密破解(四) 360云盘登录password加密
登录链接:https://yunpan.360.cn/mindex/login 这是一个md5 加密算法,直接使用 md5加密即可实现 本文讲解的是如何抠出js,运行代码 第一部:抓包 如图 第二步: ...
- Python 爬虫js加密破解(三) 百度翻译 sign
第一步: 模拟抓包分析加密参数 第二步: 找到加密字段 调试出来的sign和抓取得到的数据一致,都是 275626.55195 第三部: 分析js加密方法 第四部:运行js代码: 仅供交流学习使用
- 记第一次破解js加密代码
首先,我要爬的是这个网站:http://www.66ip.cn/nm.html,我想做个直接调用网站的接口获取代理的爬虫 这个接口看上去似乎很简单,直接输入需要的代理条件后,点击提取即可 点击提取后就 ...
- python爬虫之有道在线翻译
今天初学了python这门课 老师简单的讲解了一下 python的安装环境,配置环境变量,当前主流Python使用的是3.x版本, 下午简单的讲解了python的起源,发展以及在各个方面的应用 然后晚 ...
随机推荐
- ojdbc.jar在maven中报错(下载不了)
一.问题 由于oracle的版权问题,java连接oracle的jar(ojdbc.jar)在maven的中央仓库下载不到,然后导致maven项目报错. 二.解决 第一步:下载ojdbc.jar 由于 ...
- qt构建错误: dependent "*.h" does not exist.
项目中需要维护一套qt工程,今天发现一个头文件名称中单词拼写错误,就改正了,结果重新构建提示: dependent "*.h" does not exist. 原因:修改了文件后, ...
- Xcode模拟器无法启动解决办法
今天遇到模拟器无法启动问题,点击模拟器或者Xcode build模拟器就一直跳,跳一会就不跳了,然后查看模拟器状态,显示为无响应.或者黑屏,等半天不动. 如果你有类似情况可以尝试在终端执行以下命令: ...
- Vue实战狗尾草博客后台管理系统第三章
Vue实现狗尾草博客后台管理系统第三章 本章节,咱们开发管理系统侧边栏及面包屑功能. 先上一张效果图 样式呢,作者前端初审,关于设计上毫无美感可言,大家可根据自己情况设计更好看的哦~ 侧边栏 这里我们 ...
- Zeppelie连接jdbc的使用
1. 下载 wget http://apache.mirror.cdnetworks.com/zeppelin/zeppelin-0.8.1/zeppelin-0.8.1-bin-all.tgz 2. ...
- MySQL日常使用遵循的规范建议
一 . 基础规范 1.必须使用InnoDB存储引擎 解读:支持事务:支持行级锁:支持MVCC多版本控制:支持外键:死锁自动检测:并发性能更好.CPU及内存缓存页优化使得资源利用率更高. 2. 表字符 ...
- Ubuntu 镜像制作 官方教程
rufus工具下载:下载链接 官方教程:官方教程链接 软件界面预览: 资源来源自网络,如果对您有帮助,请点击推荐~. 我尝试了这个方法可以用.电脑重启时,选择从U盘启动,就能安装系统. 参考链接: h ...
- Linux—网络通讯管理命令
一.ping命令 . ping 主机名 . ping 域名 [root@localhost ~]# ping www.baidu.com . ping IP地址 [root@localhost ~]# ...
- [视频教程] 配置mysql用户的权限并查询数据
MySQL安装后,需要允许外部IP访问数据库.修改加密配置与增加新用户,配置用户权限修改配置文件,增加默认加密方式的配置项. 当连接数据库的时候会报验证方法不存在的错误,这是因为新版本mysql的加密 ...
- 『010』NoSQL
『010』索引-Database NoSQL [001]- 点我快速打开文章[01-Redis 简单介绍] 更新中