[大数据学习研究]2.利用VirtualBox模拟Linux集群
1. 在主机Macbook上设置HOST
前文书已经把虚拟机的静态IP地址设置好,以后可以通过ip地址登录了。不过为了方便,还是设置一下,首先在Mac下修改hosts文件,这样在ssh时就不用输入ip地址了。
sudo vim /etc/hosts
或者
sudo vim /private/etc/hosts
这两个文件其实是一个,是通过link做的链接。注意要加上sudo, 以管理员运行,否则不能存盘。
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
255.255.255.255 broadcasthost
::1 localhost
50.116.33.29 sublime.wbond.net
127.0.0.1 windows10.microdone.cn
# Added by Docker Desktop
# To allow the same kube context to work on the host and the container:
127.0.0.1 kubernetes.docker.internal192.168.56.100 hadoop100
192.168.56.101 hadoop101
192.168.56.102 hadoop102
192.168.56.103 hadoop103
192.168.56.104 hadoop104
# End of section
2. 复制虚拟机
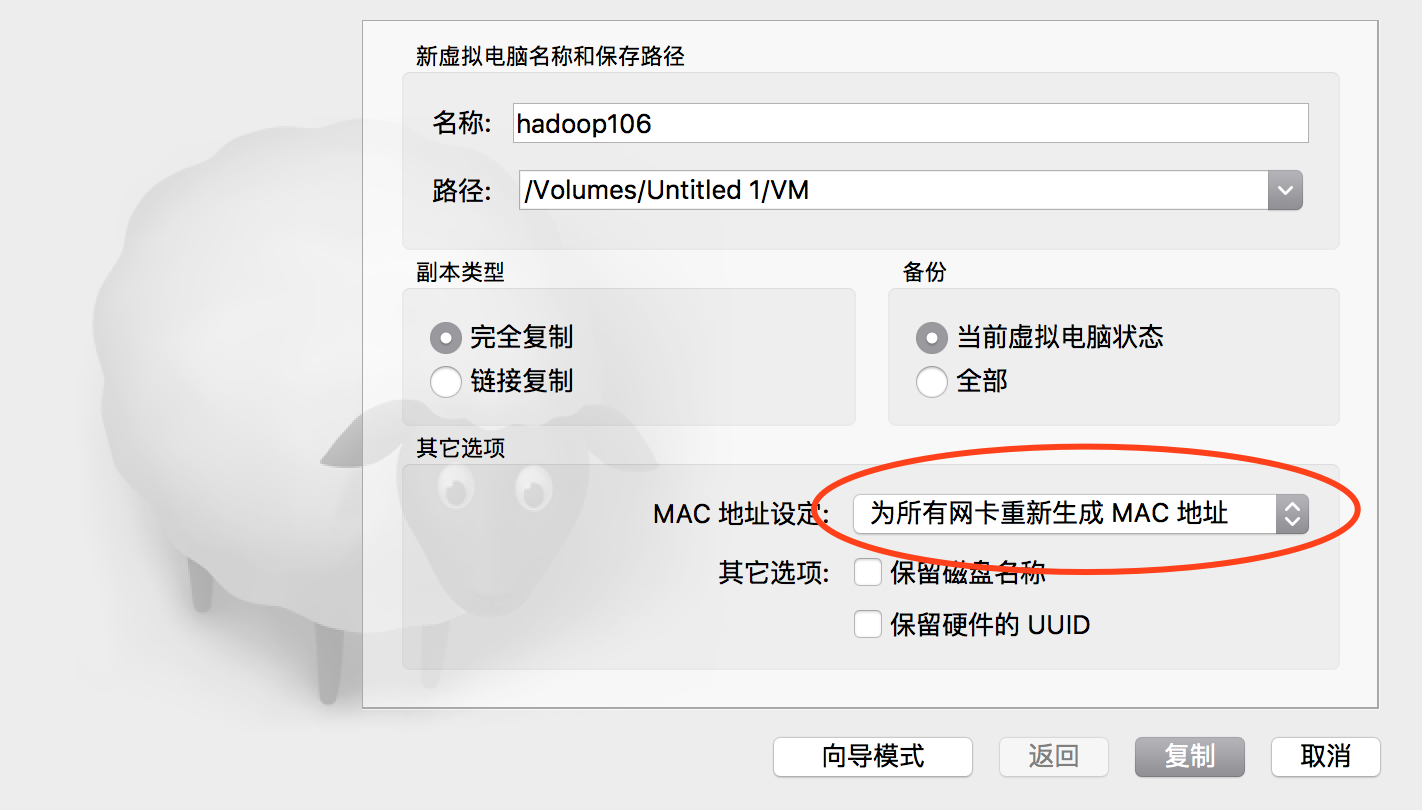
然后我们需要由上次配好的这一台虚拟机,复制出来多台,以便形成一个集群。首先关闭虚拟,在上面点右键,选复制,出现如下对话框,我选择把所有网卡都重新生成Mac地址,以便模拟完全不同的计算器环境。
3. 修改每一台的HOST, IP地址
复制完毕后,记得登录到虚拟机,按照前面提到的方法修改一下静态IP地址,免得IP地址冲突。
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
另外,最好也在每台Linux 虚拟机里也设置一下HOSTNAME,以便这些虚拟机之前相互通讯时也可以使用hostname。需要依次把几台机器的hostname都设置好。
[root@hadoop101 ~]# hostnamectl set-hostname hadoop107
[root@hadoop101 ~]# hostname
hadoop107
4. xcall让服务器集群同时运行命令
因为我们同时有好几台机器,如果挨个挨个的登录上去操作,难免麻烦,可以写个shell脚本,以后从其中一台发起命令,让所有机器都执行就方便多了。下面是个例子。 我有hadopp100,hadopp101、hadopp102、hadopp103、hadopp104这个五台虚拟机。我希望以hadopp100为堡垒,统一控制所有其他的机器。 在/user/local/bin 下创建一个xcall的文件,内容如下:
touch /user/local/bin/xcall
chmod +x /user/local/bin/xcall
vi /user/local/bin/xcall
#!/bin/bash
pcount=$#
if((pcount==0));then
echo no args;
exit;
fiecho ---------running at localhost--------
$@
for((host=101;host<=104;host++));do
echo ---------running at hadoop$host-------
ssh hadoop$host $@
done
~
比如我用这个xcall脚本在所有机器上调用pwd名称,查看当前目录,会依次提示输入密码后执行。
[root@hadoop100 ~]# xcall pwd
---------running at localhost--------
/root
---------running at hadoop101-------
root@hadoop101's password:
/root
---------running at hadoop102-------
root@hadoop102's password:
/root
---------running at hadoop103-------
root@hadoop103's password:
/root
---------running at hadoop104-------
root@hadoop104's password:
/root
[root@hadoop100 ~]#
5. scp与rsync
然后我们说一下 scp这个工具。 scp可以在linux间远程拷贝数据。如果要拷贝整个目录,加 -r 就可以了。
[root@hadoop100 ~]# ls
anaconda-ks.cfg
[root@hadoop100 ~]# scp anaconda-ks.cfg hadoop104:/root/
root@hadoop104's password:
anaconda-ks.cfg 100% 1233 61.1KB/s 00:00
[root@hadoop100 ~]#
另外还可以用rsync, scp是不管目标机上情况如何,都要拷贝以便。 rsync是先对比一下,有变化的再拷贝。如果要远程拷贝的东西比较大,用rsync更快一些。 不如rsync在centOS上没有默认安装,需要首先安装一下。在之前的文章中,我们的虚拟机已经可以联网了,所以在线安装就可以了。
[root@hadoop100 ~]# xcall sudo yum install -y rsync
比如,把hadoop100机器上的java sdk同步到102上去:
[root@hadoop100 /]# rsync -r /opt/modules/jdk1.8.0_121/ hadoop102:/opt/modules/jdk1.8.0_121/
好了,到现在基本的工具和集群环境搭建起来了,后面就可以开始hadoop的学习了。
[大数据学习研究]2.利用VirtualBox模拟Linux集群的更多相关文章
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS6安装各种大数据软件 第六章:HBase分布式集群的配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- [大数据学习研究]1.在Mac上利用VirtualBox搭建本地虚拟机环境
1. 大数据和Hadoop 研究学习大数据,自然要从Hadoop开始. Hadoop不是一个简单的软件,而是有一些列软件形成的生态,其核心思想来自Google当初发布的三篇论文,后来做了开源的实现, ...
- [大数据学习研究] 4. Zookeeper-分布式服务的协同管理神器
本来这一节想写Hadoop的分布式高可用环境的搭建,写到一半,发现还是有必要先介绍一下ZooKeeper这个东西. ZooKeeper理念介绍 ZooKeeper是为分布式应用来提供协同服务的,而且Z ...
- 保姆级教程,带你认识大数据,从0到1搭建 Hadoop 集群
大数据简介,概念部分 概念部分,建议之前没有任何大数据相关知识的朋友阅读 大数据概论 什么是大数据 大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉.管理和处理的数据集合,是需 ...
- [大数据学习研究] 3. hadoop分布式环境搭建
1. Java安装与环境配置 Hadoop是基于Java的,所以首先需要安装配置好java环境.从官网下载JDK,我用的是1.8版本. 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中 ...
- [大数据学习研究] 错误排查,Hadoop集群部分DataNode不能启动
错误现象 不知道什么原因,今天发现我的hadoop集群启动后datanode只有一台了,我的集群本来有三台的,怎么只剩一台了呢? 用jps命令检查一下,发现果然有两台机器的DataNode没有启动. ...
- 大数据架构:搭建CDH5.5.1分布式集群环境
yum install -y ntp gcc make lrzsz wget vim sysstat.x86_64 xinetd screen expect rsync bind-utils ioto ...
- 大数据之ES系列——第一篇 ElasticSearch2.2 集群安装部署
第一部分 安装准备 准备三台主机节点: hc11.spads 192.168.160.181 hc12.spads 192.168.160.182 hc13.spads 192.168.160 ...
随机推荐
- JS扫雷小游戏
HTML代码 <title> 扫雷 </title> <!-- ondragstart:防拖拽生成新页面 oncontextmenu:屏蔽右键菜单--> <b ...
- arukas 樱花免费docker容器获取IP和端口
arukas 樱花免费docker容器,可以安装linux系统,但是每隔一段时间会重启,重启以后IP地址和映射到公网的端口都会变,获取IP和端口,我研究了很久终于找到了C#获取IP和端口的办法,用来搭 ...
- 一、Ansible入门篇
一.Ansible简介 Ansible是一个自动化运维的工具 基于python语言编写,因此机器需要具备python环境. 通过ssh的连接方式进行自动化部署,ansible优先使用OpenSSH,在 ...
- JMeter使用JSON Extractor插件实现将一个接口的JSON返回值作为下一个接口的入参
##补充## 接口响应数据,一般为JSON,HTML格式的数据. 对于HTML的响应结果提取,可以使用正则表达式,也可以通过XPath来提取:对于JSON格式的数据,可以用正则表达式,JSON Ext ...
- 人脸识别开发套件RJ45、继电器、OTG、RS232接口说明
人脸识别开发套件RJ45.继电器.OTG.RS232接口说明 接口说明 D801A 人脸抓拍识别一体机是一款高性能.高可靠性的人脸识别类产品.依托深度学习算法扩展人脸库数量,准确率更高,支 ...
- js全选与取消全选
实现全选与取消全选的效果 要求1(将军影响士兵):点击全选按钮,下面的复选框全部选中,取消全选按钮,下面的复选框全部取消 思路:复选框是否被选中,取决于check属性,将全选按钮的check属性值赋值 ...
- [AI] 论文笔记 - CVPR2018 Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation
写在前面 原始视频(30fps) 补帧后的视频(240fps) 本文是博主在做实验的过程中使用到的方法,刚好也做为了本科毕设的翻译文章,现在把它搬运到博客上来,因为觉得这篇文章的思路真的不错. 这篇文 ...
- com.sun.jersey.api.client.ClientHandlerException: java.net.ConnectException: Connection refused: connect
com.sun.jersey.api.client.ClientHandlerException: java.net.ConnectException: Connection refused: con ...
- Redis学习总结(二)--Redis数据结构
Redis支持六种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合). 结构类型 存储的值 string 可以是字符串.浮 ...
- python 16 模块
目录 模块 1. 自定义模块 1.1 模块分类 1.2 模块的导入 1.3 import 和 from 1.4 from 模块名 import * 1.5 模块的用法: 1.6 导入路径 2. tim ...