flume learning---Flume 集群搭建
在flume搭建集群模式时,首先需要进入conf目录,
1.cp flume-env.sh.template flume-env.sh
2.cp flume-conf.properties.template flume-telent.conf
然后vi flume-env.sh  ,添加本机的java_home
,添加本机的java_home
3.分别将两台主机一台担任采集(shizhan01),一台担任客户端读取(shizhan02)
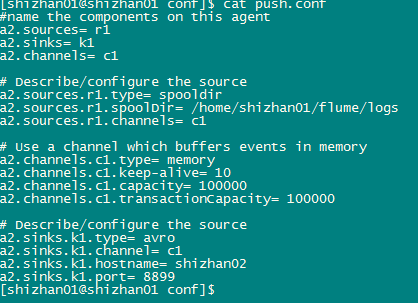
采集端的配置
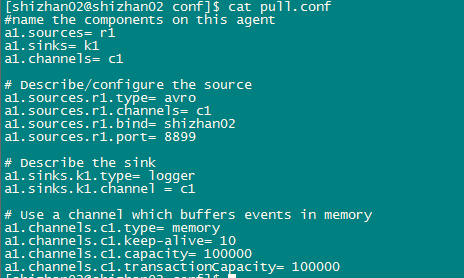
输出端的配置
4.接下来需要首先启动输出端(shizhan02), ./bin/flume-ng agent -c conf -f conf/pull.conf -n a1 -Dflume.root.logger=INFO,console
5.启动采集端./bin/flume-ng agent -n a2 -c conf -f conf/push.conf -Dflume.root.logger=INFO,console
6,在对应的监控目录/home/shizhan01/flume/logs/下创建文件
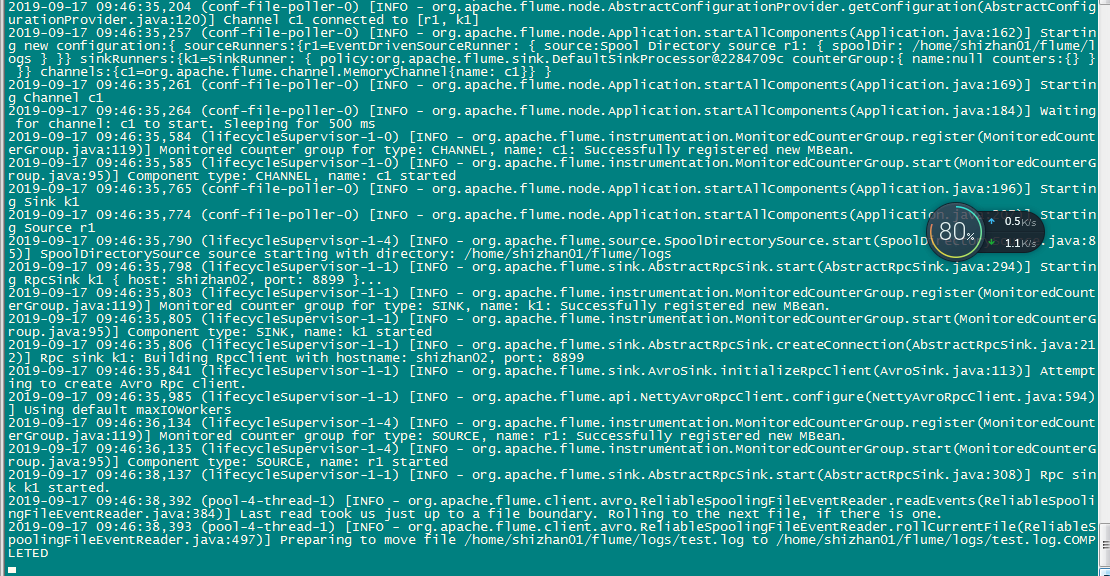
7.采集端出现此情况说明采集成功,接下来需要验证输出端
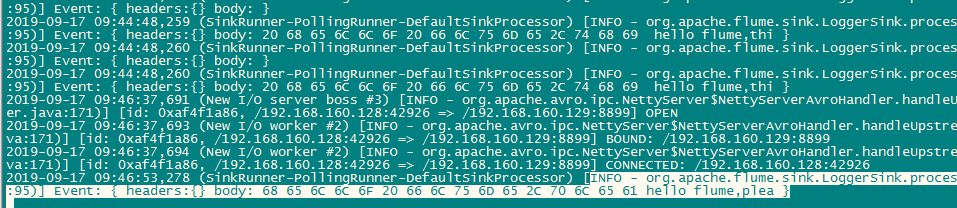
8.在输出端可以看到此段日志,说明输出成功
flume learning---Flume 集群搭建的更多相关文章
- Flume 学习笔记之 Flume NG高可用集群搭建
Flume NG高可用集群搭建: 架构总图: 架构分配: 角色 Host 端口 agent1 hadoop3 52020 collector1 hadoop1 52020 collector2 had ...
- Spark集群搭建简要
Spark集群搭建 1 Spark编译 1.1 下载源代码 git clone git://github.com/apache/spark.git -b branch-1.6 1.2 修改pom文件 ...
- Spark集群搭建【Spark+Hadoop+Scala+Zookeeper】
1.安装Linux 需要:3台CentOS7虚拟机 IP:192.168.245.130,192.168.245.131,192.168.245.132(类似,尽量保持连续,方便记忆) 注意: 3台虚 ...
- CDH 6.0.1 集群搭建 「Before install」
从这一篇文章开始会有三篇文章依次介绍集群搭建 「Before install」 「Process」 「After install」 继上一篇使用 docker 部署单机 CDH 的文章,当我们使用 d ...
- 分布式实时日志系统(一)环境搭建之 Jstorm 集群搭建过程/Jstorm集群一键安装部署
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
- Hadoop介绍及集群搭建
简介 Hadoop 是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台.允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理.它的核 ...
- apache-storm-1.0.2.tar.gz的集群搭建(3节点)(图文详解)(非HA和HA)
不多说,直接上干货! Storm的版本选取 我这里,是选用apache-storm-1.0.2.tar.gz apache-storm-0.9.6.tar.gz的集群搭建(3节点)(图文详解) 为什么 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- Ambari HDP集群搭建全攻略
世界上最快的捷径,就是脚踏实地,本文已收录[架构技术专栏]关注这个喜欢分享的地方. 最近因为工作上需要重新用Ambari搭了一套Hadoop集群,就把搭建的过程记录了下来,也希望给有同样需求的小伙伴们 ...
- 实时计算框架:Flink集群搭建与运行机制
一.Flink概述 1.基础简介 Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算.Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算.主要特性包 ...
随机推荐
- java后端_百度一面
参考: https://www.nowcoder.com/discuss/215891?type=2&order=0&pos=10&page=1 1.会啥框架.不会. 2.锁的 ...
- 帝国CMS(EmpireCMS) v7.5后台任意代码执行
帝国CMS(EmpireCMS) v7.5后台任意代码执行 一.漏洞描述 EmpireCMS 7.5版本及之前版本在后台备份数据库时,未对数据库表名做验证,通过修改数据库表名可以实现任意代码执行. 二 ...
- VSCode 远程开发(带免密)
VSCode 远程开发(带免密) 简介 Visual Studio Code(以下简称 VS Code)从1.35.0版本正式提供可以在本地编辑远程开发环境的文件的功能,具体实现如下图 安装完成Rem ...
- web 前端开发学习路线
初级 HTML 5 HTML 5 与 HTML 4 的区别 HTML 5 新增的主体结构元素 HTML 5 新增的非主体结构元素 HTML 5 表单新增元素与属性 HTML 5 表单新增元素与属性(续 ...
- 结合suctf-upload labs-RougeMysql再学习
这篇主要记录一下这道题目的预期解法 做这道题首先要在自己的vps搭建一个rouge mysql,里面要填写需要读取客户端的文件名,即我们上传的phar文件路径 先搭一个rouge mysql测试看看: ...
- Raven 2 靶机渗透
0X00 前言 Raven 2中一共有四个flag,Raven 2是一个中级boot2root VM.有四个标志要捕获.在多次破坏之后,Raven Security采取了额外措施来强化他们的网络服务器 ...
- node.js 初学 自我笔记整理 day01
node.js 概念问题: Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境. npm是一个node的包管理工具 ,也是一个网站 ,还是一条命令.N ...
- C++的精度控制
#include <iostream> #include <iomanip> using namespace std; int main( void ) { const dou ...
- java学习之- 线程继承Thread类
标签(空格分隔): 线程 在java.lang包中有个Thread子类,大家可以自行查阅文档,及范例: 如何在自定义的代码中,自定义一个线程呢? 1.通过对api的查找,java已经提供了对线程这类事 ...
- CSS文本超出用省略号代替的方法
{ white-space:nowrap; overflow:hidden; text-overflow:ellipsis; }