MDS 多活配置
CephFS 介绍及使用经验分享
WebRTC SFU中发送数据包的丢失反馈juejin.im
目录
- Ceph架构介绍
- NFS介绍
- 分布式文件系统比较
- CephFS介绍
- MDS介绍
- 5.1 单活MDS介绍
- 5.2 单活MDS高可用
- CephFS遇到的部分问题
- 6.1 客户端缓存问题
- 6.2 务端缓存不释放
- 6.3 客户端夯住或者慢查询
- 6.4 客户端失去连接
- 6.5 主从切换问题
- CephFS问题解决方案
- 7.1 服务端缓存警告问题
- 7.2 客户端夯住问题
- 7.2.1 MDS锁的问题
- 7.3 MDS主从切换问题
- 7.3.1 为什么mds切换耗时比较高?
- 7.3.2 MDS切换循环?
- 7.4 客户端失去连接
- 总结及优化方案推荐
- 多活MDS
- 9.1 简介
- 9.2 多活MDS优势
- 9.3 多活MDS特点
- 9.4 CephFS Subtree Partitioning
- 9.4.1 介绍
- 9.5 Subtree Pinning(static subtree partitioning)
- 9.6 动态负载均衡
- 9.6.1 介绍
- 9.6.2 可配置的负载均衡
- 9.6.3 负载均衡策略
- 9.6.4 通过lua灵活控制负载均衡
- 9.6.5 内部结构图
- 多活负载均衡-实战演练
- 10.1 集群架构
- 10.2 扩容活跃MDS
- 10.3 多活MDS压测
- 10.4 多活MDS-动态负载均衡
- 10.5 多活MDS-静态分区(多租户隔离)
- 10.6 多活MDS-主备模式
- 多活负载均衡-总结
- 11.1 测试报告
- 11.2 结论
- MDS状态说明
- 12.1 MDS主从切换流程图
- 12.2 MDS状态
- 12.3 State Diagram
- 深入研究
- 13.1 MDS启动阶段分析
- 13.2 MDS核心组件
- 13.3 MDSDaemon类图
- 13.4 MDSDaemon源码分析
- 13.5 MDSRank类图
- 13.6 MDSRank源码分析
1. Ceph架构介绍
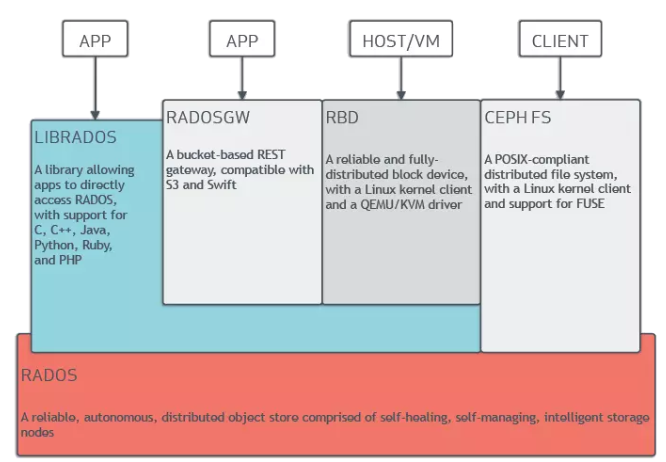
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。
特点如下:
- 高性能
- a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
- b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
- c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
- 高可用性
- a. 副本数可以灵活控制。
- b. 支持故障域分隔,数据强一致性。
- c. 多种故障场景自动进行修复自愈。
- d. 没有单点故障,自动管理。
- 高可扩展性
- a. 去中心化。
- b. 扩展灵活。
- c. 随着节点增加而线性增长。
- 特性丰富
- a. 支持三种存储接口:块存储、文件存储、对象存储。
- b. 支持自定义接口,支持多种语言驱动。
使用场景:
- 块存储 (适合单客户端使用)
- 典型设备:磁盘阵列,硬盘。
- 使用场景:
- a. docker容器、虚拟机远程挂载磁盘存储分配。
- b. 日志存储。
- ...
- 文件存储 (适合多客户端有目录结构)
- 典型设备:FTP、NFS服务器。
- 使用场景:
- a. 日志存储。
- b. 多个用户有目录结构的文件存储共享。
- ...
- 对象存储 (适合更新变动较少的数据,没有目录结构,不能直接打开/修改文件)
- 典型设备:s3, swift。
- 使用场景:
- a. 图片存储。
- b. 视频存储。
- c. 文件。
- d. 软件安装包。
- e. 归档数据。
- ...
系统架构:
Ceph 生态系统架构可以划分为四部分:
- Clients:客户端(数据用户)
- mds:Metadata server cluster,元数据服务器(缓存和同步分布式元数据)
- osd:Object storage cluster,对象存储集群(将数据和元数据作为对象存储,执行其他关键职能)
- mon:Cluster monitors,集群监视器(执行监视功能)
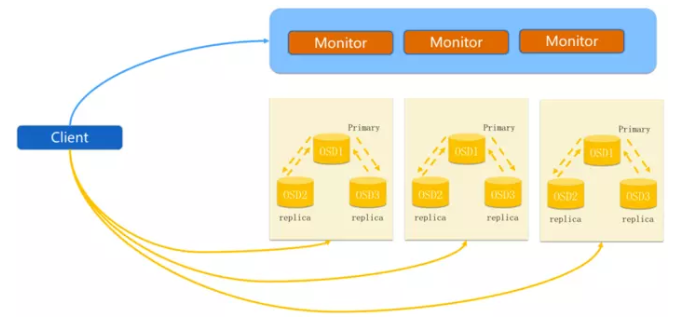
2. NFS介绍
1. NAS(Network Attached Storage)
- 网络存储基于标准网络协议NFSv3/NFSv4实现数据传输。
- 为网络中的Windows / Linux / Mac OS 等各种不同操作系统的计算机提供文件共享和数据备份。
- 目前市场上的NAS存储是专门的设备,成本较高,且容量不易动态扩展,数据高可用需要底层RAID来保障。
- CephFS属于NAS的解决方案的一种,主要优势在成本,容量扩展和高性能方案。
2. NFS(Network File System)
- NFS即网络文件系统,通过使用NFS,用户和程序可以像访问本地文件一样访问远端系统上的文件。
- NFS客户端和NFS服务器之间正是通过NFS协议进行通信的。
- 目前NFS协议版本有NFSv3、NFSv4和NFSv4.1,NFSv3是无状态的,NFSv4是有状态,NFSv3和NFSv4是基于Filelayout驱动的,而NFSv4.1是基于Blocklayout驱动。本文主要使用NFSv4协议。
3. 分布式文件系统比较
| 名称 | 功能 | 适合场景 | 优缺点 |
|---|---|---|---|
| MFS | 1. 单点MDS 2. 支持FUSE 3. 数据分片分布 4. 多副本 5. 故障手动恢复 |
大量小文件读写 | 1. 运维实施简单 2. 但存在单点故障 |
| Ceph | 1. 多个MDS,可扩展 2. 支持FUSE 3. 数据分片(crush)分布 4. 多副本/纠删码 5. 故障自动恢复 |
统一小文件存储 | 1. 运维实施简单 2. 故障自愈,自我恢复 3. MDS锁的问题 4. J版本很多坑, L版本可以上生产环境 |
| ClusterFS | 1. 不存在元数据节点 2. 支持FUSE 3. 数据分片分布 4. 镜像 5. 故障自动恢复 |
适合大文件 | 1. 运维实施简单 2. 不存储元数据管理 3. 增加了客户端计算负载 |
| Lustre | 1. 双MDS互备,不可用扩展 2. 支持FUSE 3. 数据分片分布 4. 冗余(无) 5. 故障自动恢复 |
大文件读写 | 1. 运维实施复杂 2. 太庞大 3. 比较成熟 |
4. CephFS介绍

说明:
- CephFS 是个与 POSIX 标准兼容的文件系统。
- 文件目录和其他元数据存储在RADOS中。
- MDS缓存元信息和文件目录信息。
- 核心组件:MDS、Clients、RADOS。
- Client <–> MDS
元数据操作和capalities。 - Client <–> OSD
数据IO。 - MDS <–> OSD
元数据IO。
- Client <–> MDS
- 挂载方式:
- ceph-fuse ... 。
- mount -t ceph ... 。
- 可扩展性
- client读写osd 。
- 共享文件系统
- 多个clients可以同时读写 。
- 高可用
- MDS主备模式,Active/Standby MDSs 。
- 文件/目录Layouts
- 支持配置文件/目录的Layouts使用不同的Ppool 。
- POSIX ACLs
- CephFS kernel client默认支持。
- CephFS FUSE client可配置支持 。
- NFS-Ganesha
- 一个基于 NFSv3\v4\v4.1 的NFS服务器
- 运行在大多数 Linux 发行版的用户态空间下,同时也支持 9p.2000L 协议。
- Ganesha通过利用libcephfs库支持CephFS FSAL(File System Abstraction Layer,文件系统抽象层),可以将CephFS重新Export出去。
- Client Quotas
- CephFS FUSE client支持配置任何目录的Quotas。
- 负载均衡
- 动态负载均衡。
- 静态负载均衡。
- hash负载均衡。
5. MDS介绍
5.1 单活MDS介绍

说明:
- MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
- 元数据的内存缓存,为了加快元数据的访问。
- 保存了文件系统的元数据(对象里保存了子目录和子文件的名称和inode编号)
- 保存cephfs日志journal,日志是用来恢复mds里的元数据缓存
- 重启mds的时候会通过replay的方式从osd上加载之前缓存的元数据
- 对外提供服务只有一个active mds。
- 所有用户的请求都只落在一个active mds上。
5.2 单活MDS高可用
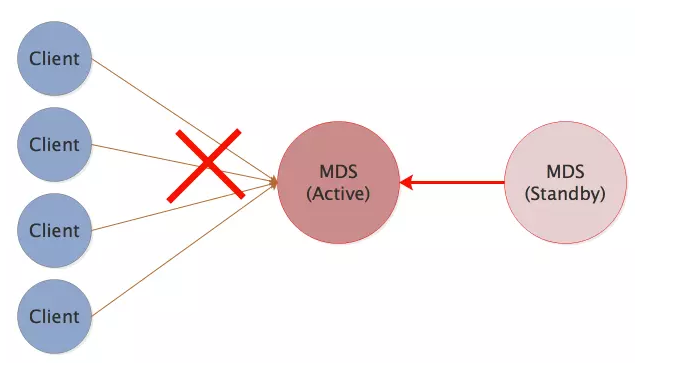
说明:
- 对外提供服务只有一个active mds, 多个standby mds。
- active mds挂掉,standby mds会立马接替,保证集群高可用性。
- standby mds
- 冷备就是备份的mds,只起到一个进程备份的作用,并不备份lru元数据。主备进程保持心跳关系,一旦主的mds挂了,备份mds replay()元数据到缓存,当然这需要消耗一点时间。
- 热备除了进程备份,元数据缓存还时时刻刻的与主mds保持同步,当 active mds挂掉后,热备的mds直接变成主mds,并且没有replay()的操作,元数据缓存大小和主mds保持一致。
6. CephFS遇到的部分问题
6.1 客户端缓存问题
消息: Client name failing to respond to cache pressure
说明: 客户端有各自的元数据缓存,客户端缓存中的条目(比如索引节点)也会存在于 MDS 缓存中,
所以当 MDS 需要削减其缓存时(保持在 mds_cache_size 以下),它也会发消息给客户端让它们削减自己的缓存。如果某个客户端的响应时间超过了 mds_recall_state_timeout (默认为 60s ),这条消息就会出现。
6.2 服务端缓存不释放
如果有客户端没响应或者有缺陷,就会妨碍 MDS 将缓存保持在 mds_cache_size 以下, MDS 就有可能耗尽内存而后崩溃。
6.3 客户端夯住或者慢查询
- 客户端搜索遍历查找文件(不可控)。
- session的 inode太大导致mds负载过高。
- 日志级别开的太大,从而导致mds负载高。
- mds锁问题,导致客户端夯住。
- mds性能有限,目前是单活。
6.4 客户端失去连接
客户端由于网络问题或者其他问题,导致客户端不可用。
6.5 主从切换问题
- 主从切换耗时长。
- 主从切换循环选举。
7. CephFS问题解决方案
7.1 服务端缓存警告问题
v12 luminous版本已修复:
github.com/ceph/ceph/c…
mds: fix false "failing to respond to cache pressure" warning
- MDS has cache pressure, sends recall state messages to clients
- Client does not trim as many caps as MDS expected. So MDS
does not reset session->recalled_at - MDS no longer has cache pressure, it stop sending recall state
messages to clients. - Client does not release its caps. So session->recalled_at in
MDS keeps unchanged
7.2 客户端夯住问题
7.2.1 MDS锁的问题
7.2.1.1 场景模拟
- A用户以只读的方式打开文件,不关闭文件句柄。然后意外掉线或者掉电,B用户读写这个文件就会夯住。
- 读写代码
//read.c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <pthread.h>
int main()
{
int i = 0;
for(i = 0; ;i++)
{
char *filename = "test.log";
int fd = open(filename, O_RDONLY);
printf("fd=[%d]", fd);
fflush(stdout);
sleep(5);
}
}
//write.c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <pthread.h>
int main()
{
int i = 0;
for(i = 0; ;i++)
{
char *filename = "test.log";
int fd = open(filename, O_CREAT | O_WRONLY | O_APPEND, S_IRUSR | S_IWUSR);
write(fd, "aaaa\n", 6);
printf("fd=[%d] buffer=[%s]", fd, "aaaa");
close(fd);
fflush(stdout);
sleep(5);
}
}- A用户执行read, B用户执行write。
- a. A用户,kill -9 ceph-fuse pid 时间点是19:55:39。
b. 观察A,B用户的情况如下。
 image.png
image.png- c. 观察mds的日志
2018-12-13 19:56:11.222816 7fffee6d0700 0 log_channel(cluster) log [WRN] : 1 slow requests, 1 included below; oldest blocked for > 30.670943 secs
2018-12-13 19:56:11.222826 7fffee6d0700 0 log_channel(cluster) log [WRN] : slow request 30.670943 seconds old, received at 2018-12-13 19:55:40.551820: client_request(client.22614489:538 lookup #0x1/test.log 2018-12-13 19:55:40.551681 caller_uid=0, caller_gid=0{0,}) currently failed to rdlock, waiting
2018-12-13 19:56:13.782378 7ffff0ed5700 1 mds.ceph-xxx-osd02.ys Updating MDS map to version 229049 from mon.0
2018-12-13 19:56:33.782572 7ffff0ed5700 1 mds.ceph-xxx-osd02.ys Updating MDS map to version 229050 from mon.0
2018-12-13 20:00:26.226405 7fffee6d0700 0 log_channel(cluster) log [WRN] : evicting unresponsive client ceph-xxx-osd01.ys (22532339), after 303.489228 seconds总结:
- 可以发现kill之后A用户是不可用的状态。
- 与此同时B用户也是不可用的状态,过了300s才恢复。
- 与此同时mds日志显示,有慢查询夯住的client.22614489正好是B用户。
- mds日志中发现,夯住都是在等待读锁。(currently failed to rdlock, waiting)
- mds日志中发现, 夯住后过了300s 驱逐异常客户端A用户。
- 有两种情况可以自动剔除客户:
- 在活动的MDS守护程序上,如果客户端尚未通过mds_session_autoclose秒(默认为300秒)与MDS进行通信(客户端每隔20s 向mds发送心跳链接handle_client_session),则会自动将其逐出。
- 在MDS启动期间(包括故障转移),MDS通过称为重新连接的状态。 在此状态下,它等待所有客户端连接到新的MDS守护程序。 如果任何客户端在时间窗口(mds_reconnect_timeout,默认值为45秒)内未能这样做,那么它们将被逐出。
- 调节mds session autoclose(默认300s)可以尽快释放异常会话,让其他客户端尽快可用。
7.3 MDS主从切换问题
7.3.1 为什么mds切换耗时比较高?
- 分析日志(发现执行rejoin_start,rejoin_joint_start动作耗时比较高)。
2018-04-27 19:24:15.984156 7f53015d7700 1 mds.0.2738 rejoin_start
2018-04-27 19:25:15.987531 7f53015d7700 1 mds.0.2738 rejoin_joint_start
2018-04-27 19:27:40.105134 7f52fd4ce700 1 mds.0.2738 rejoin_done
2018-04-27 19:27:42.206654 7f53015d7700 1 mds.0.2738 handle_mds_map i am now mds.0.2738
2018-04-27 19:27:42.206658 7f53015d7700 1 mds.0.2738 handle_mds_map state change up:rejoin --> up:active跟踪代码分析(在执行process_imported_caps超时了, 这个函数主要是打开inodes 加载到cache中)。
 image.png
image.png
7.3.2 MDS切换循环?
MDS守护进程至少在mds_beacon_grace中未能向监视器发送消息,而它们应该在每个mds_beacon_interval发送消息。此时Ceph监视器将自动将MDS切换为备用MDS。 如果MDS的Session Inode过多导致MDS繁忙,只从切换未能及时发送消息,就可能会出现循环切换的概率。一般建设增大mds_beacon_grace。
mds beacon grace
描述: 多久没收到标识消息就认为 MDS 落后了(并可能替换它)。
类型: Float
默认值: 15
7.4 客户端失去连接
client: fix fuse client hang because its pipe to mds is not ok
There is a risk client will hang if fuse client session had been killed by mds and
the mds daemon restart or hot-standby switch happens right away but the client
did not receive any message from monitor due to network or other whatever reason
untill the mds become active again.Thus cause client didn't do closed_mds_session
lead the seession still is STATE_OPEN but client can't send any message to
mds because its pipe is not ok.
So we should create pipe to mds guarantee any meta request can be sent to
server.When mds recevie the message will send a CLOSE_SESSION to client
becasue its session for this client is STATE_CLOSED.After the previous
steps the old session of client can be closed and new session and pipe
can be established and the mountpoint will be ok.
8. 总结及优化方案推荐
- A用户读数据意外掉线,B用户的操作都会抗住等待A用户恢复,如果恢复不了,直到一定时间会自动剔除A用户。(锁的粒度很大,坑很大)
- 调节mds session autoclose(默认300s),尽快剔除有问题的客户端。
- On an active MDS daemon, if a client has not communicated with the MDS for over session_autoclose (a file system variable) seconds (300 seconds by default), then it will be evicted automatically
- 有两种情况可以自动驱逐客户:
- 在活动的MDS守护程序上,如果客户端尚未通过mds_session_autoclose秒(默认为300秒)与MDS进行通信(客户端每隔20s 向mds发送心跳链接handle_client_session),则会自动将其逐出。
- 在MDS启动期间(包括故障转移),MDS通过称为重新连接的状态。 在此状态下,它等待所有客户端连接到新的MDS守护程序。 如果任何客户端在时间窗口(mds_reconnect_timeout,默认值为45秒)内未能这样做,那么它们将被逐出。
- 如果mds负载过高或者内存过大,限制MDS内存,减少资源消耗。mds limiting cache by memory github.com/ceph/ceph/p…
- 如果mds负载过高或者内存过大,官方提供的mds 主动删除cache,补丁在review过程中个,目标版本是ceph-14.0.0 github.com/ceph/ceph/p…
- mds在主处理流程中使用了单线程,这导致了其单个MDS的性能受到了限制,最大单个MDS可达8k ops/s,CPU利用率达到的 140%左右。
- ceph-fuse客户端Qos限速,避免IO一瞬间涌进来导致mds抖动(从客户端限制IOPS,避免资源争抢,对系统资源带来冲击)
- 剔除用户可以释放inode数量,但是不能减少内存,如果此时切换主从可以加快切换速度。
- 多活MDS 在12 Luminous 官方宣称可以上生产环境。
- 当某个文件系统客户端不响应或者有其它异常行为时,此时会对客户端进行驱逐,为了防止异常客户端导致数据不一致。
9. 多活MDS
9.1 简介
也叫: multi-mds 、 active-active MDS
每个 CephFS 文件系统默认情况下都只配置一个活跃 MDS 守护进程。在大型系统中,为了扩展元数据性能你可以配置多个活跃的 MDS 守护进程,它们会共同承担元数据负载。
CephFS 在Luminous版本中多元数据服务器(Multi-MDS)的功能和目录分片(dirfragment)的功能宣称已经可以在生产环境中使用。
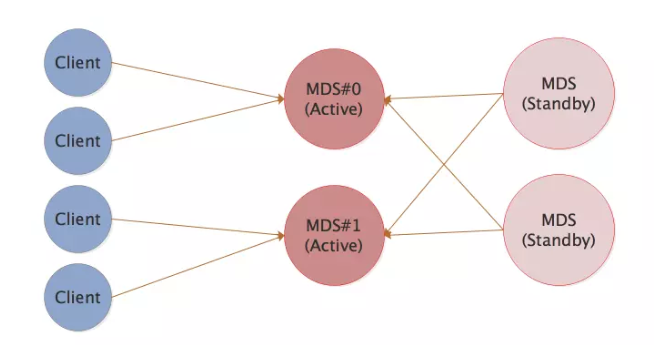
9.2 多活MDS优势
- 当元数据默认的单个 MDS 成为瓶颈时,配置多个活跃的 MDS 守护进程,提升集群性能。
- 多个活跃的 MDS 有利于性能提升。
- 多个活跃的MDS 可以实现MDS负载均衡。
- 多个活跃的MDS 可以实现多租户资源隔离。
9.3 多活MDS特点
- 它能够将文件系统树分割成子树。
- 每个子树可以交给特定的MDS进行权威管理。
- 从而达到了随着元数据服务器数量的增加,集群性能线性地扩展。
- 每个子树都是基于元数据在给定目录树中的热动态创建的。
- 一旦创建了子树,它的元数据就被迁移到一个未加载的MDS。
- 后续客户端对先前授权的MDS的请求被转发。

9.4 CephFS Subtree Partitioning
9.4.1 介绍

说明:
为了实现文件系统数据和元数据的负载均衡,业界一般有几种分区方法:
- 静态子树分区
- 即通过手工分区方式,将数据直接分配到某个服务节点上,出现负载
不均衡时,再由管理员手动重新进行分配。 - 这种方式适应于数据位置固定的场景,不适合动态扩展、或者有可能出现异常的场景。
- 即通过手工分区方式,将数据直接分配到某个服务节点上,出现负载
- Hash计算分区
- 即通过Hash计算来分配数据存储的位置。
- 这种方式适合数据分布均衡、且需要应用各种异常的情况,但不太适合需要数据分布固定、环境变化频率很高的场景。
- 动态子树分区
- 通过实时监控集群节点的负载,动态调整子树分布于不同的节点。
- 这种方式适合各种异常场景,能根据负载的情况,动态的调整数据分布,不过如果大量数据的迁移肯定会导致业务抖动,影响性能。
9.5 Subtree Pinning(static subtree partitioning)
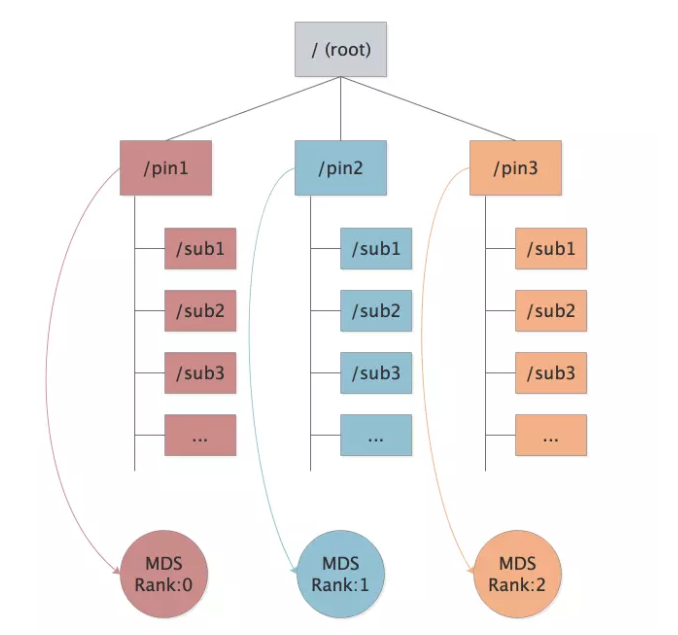
说明:
- 通过pin可以把mds和目录进行绑定 。
- 通过pin可以做到不同用户的目录访问不同的mds。
- 可以实现多租户MDS负载均衡。
- 可以实现多租户MDS负载资源隔离。
9.6 动态负载均衡
9.6.1 介绍
多个活动的MDSs可以迁移目录以平衡元数据负载。何时、何地以及迁移多少的策略都被硬编码到元数据平衡模块中。
Mantle是一个内置在MDS中的可编程元数据均衡器。其思想是保护平衡负载(迁移、复制、碎片化)的机制,但使用Lua定制化平衡策略。
大多数实现都在MDBalancer中。度量通过Lua栈传递给均衡器策略,负载列表返回给MDBalancer。这些负载是“发送到每个MDS的数量”,并直接插入MDBalancer“my_targets”向量。
暴露给Lua策略的指标与已经存储在mds_load_t中的指标相同:auth.meta_load()、all.meta_load()、req_rate、queue_length、cpu_load_avg。
它位于当前的均衡器实现旁边,并且它是通过“ceph.conf”中的字符串启用的。如果Lua策略失败(无论出于何种原因),我们将回到原来的元数据负载均衡器。
均衡器存储在RADOS元数据池中,MDSMap中的字符串告诉MDSs使用哪个均衡器。
This PR does not not have the following features from the Supercomputing paper:
- Balancing API: all we require is that balancer written in Lua returns a
targetstable, where each index is the amount of load to send to each MDS - "How much" hook: this let's the user define
meta_load() - Instantaneous CPU utilization as metric
Supercomputing '15 Paper: sc15.supercomputing.org/schedule/ev…
9.6.2 可配置的负载均衡

参考:
9.6.3 负载均衡策略

9.6.4 通过lua灵活控制负载均衡

参考:
9.6.5 内部结构图

参考:
10. 多活负载均衡-实战演练
10.1 集群架构
- mon: ceph-xxx-osd02.ys,ceph-xxx-osd03.ys,ceph-xxx-osd01.ys
- mgr: ceph-xxx-osd03.ys(active), standbys: ceph-xxx-osd02.ys
- mds: test1_fs-1/1/1 up {0=ceph-xxx-osd02.ys=up:active}, 2 up:standby
- osd: 36 osds: 36 up, 36 in
- rgw: 1 daemon active
10.2 扩容活跃MDS
10.2.1 设置max_mds为2
$ ceph fs set test1_fs max_mds 210.2.2 查看fs状态信息
$ ceph fs status
test1_fs - 3 clients
========
+------+--------+------------------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------------------+---------------+-------+-------+
| 0 | active | ceph-xxx-osd02.ys | Reqs: 0 /s | 3760 | 14 |
| 1 | active | ceph-xxx-osd01.ys | Reqs: 0 /s | 11 | 13 |
+------+--------+------------------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs_metadata | metadata | 194M | 88.7T |
| cephfs_data | data | 0 | 88.7T |
+-----------------+----------+-------+-------+
+------------------------+
| Standby MDS |
+------------------------+
| ceph-xxx-osd03.ys |
+------------------------+
MDS version: didi_dss version 12.2.8 (ae699615bac534ea496ee965ac6192cb7e0e07c0) luminous (stable)10.2.3 总结
- 每一个 CephFS 文件系统都有自己的 max_mds 配置,它控制着会创建多少 rank 。
- 有空闲守护进程可接管新 rank 时,文件系统 rank 的实际数量才会增加 。
- 通过设置max_mds增加active mds。
- 新创建的 rank (1) 会从 creating 状态过渡到 active 状态。
- 创建后有两个active mds, 一个standby mds。
10.3 多活MDS压测
10.3.1 用户挂载目录
$ ceph-fuse /mnt/
$ df
ceph-fuse 95330861056 40960 95330820096 1% /mnt10.3.2 filebench压测
10.3.3 查看fs mds负载
$ ceph fs status
test1_fs - 3 clients
========
+------+--------+------------------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------------------+---------------+-------+-------+
| 0 | active | ceph-xxx-osd03.ys | Reqs: 5624 /s | 139k | 133k |
+------+--------+------------------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs_metadata | metadata | 238M | 88.7T |
| cephfs_data | data | 2240M | 88.7T |
+-----------------+----------+-------+-------+
+------------------------+
| Standby MDS |
+------------------------+
| ceph-xxx-osd01.ys |
| ceph-xxx-osd02.ys |
+------------------------+
MDS version: didi_dss version 12.2.8 (ae699615bac534ea496ee965ac6192cb7e0e07c0) luminous (stable)10.3.4 总结
- fuse模式 mds性能 5624 ops/s。
- 虽然有两个active mds, 但是目前请求都会落在rank0上面。
- 默认多个active mds负载并没有均衡。
10.4 多活MDS-动态负载均衡
10.4.1 Put the balancer into RADOS
rados put --pool=cephfs_metadata_a greedyspill.lua ../src/mds/balancers/greedyspill.lua10.4.2 Activate Mantle
ceph fs set test1_fs max_mds 2
ceph fs set test1_fs balancer greedyspill.lua10.4.3 挂载压测
$ ceph fs status
test1_fs - 3 clients
========
+------+--------+------------------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------------------+---------------+-------+-------+
| 0 | active | ceph-xxx-osd03.ys | Reqs: 2132 /s | 4522 | 1783 |
| 1 | active | ceph-xxx-osd02.ys | Reqs: 173 /s | 306 | 251 |
+------+--------+------------------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs_metadata | metadata | 223M | 88.7T |
| cephfs_data | data | 27.1M | 88.7T |
+-----------------+----------+-------+-------+
+------------------------+
| Standby MDS |
+------------------------+
| ceph-xxx-osd01.ys |
+------------------------+
MDS version: didi_dss version 12.2.8 (ae699615bac534ea496ee965ac6192cb7e0e07c0) luminous (stable)10.4.4 总结
- 通过lua可以灵活控制负载均衡策略。
- 测试结果发现,负载均衡效果并不好。
- 负载均衡目前来看坑比较深,目前不推荐使用。
10.5 多活MDS-静态分区(多租户隔离)
10.5.1 根据目录绑定不同的mds
#mds00绑定到/mnt/test0
#mds01绑定到/mnt/test1
#setfattr -n ceph.dir.pin -v <rank> <path>
setfattr -n ceph.dir.pin -v 0 /mnt/test0
setfattr -n ceph.dir.pin -v 1 /mnt/test110.5.2 两个客户端压测

10.5.3 观察fs 状态信息(2个压测端)
#检查mds请求负责情况
$ ceph fs status
test1_fs - 3 clients
========
+------+--------+------------------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------------------+---------------+-------+-------+
| 0 | active | ceph-xxx-osd03.ys | Reqs: 3035 /s | 202k | 196k |
| 1 | active | ceph-xxx-osd02.ys | Reqs: 3039 /s | 70.8k | 66.0k |
+------+--------+------------------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs_metadata | metadata | 374M | 88.7T |
| cephfs_data | data | 4401M | 88.7T |
+-----------------+----------+-------+-------+
+------------------------+
| Standby MDS |
+------------------------+
| ceph-xxx-osd01.ys |
+------------------------+
MDS version: didi_dss version 12.2.8 (ae699615bac534ea496ee965ac6192cb7e0e07c0) luminous (stable)10.5.4 结论
- 通过ceph.dir.pin把目录绑定到不同的mds上,从而实现多租户隔离。
- 两个客户端各自写入自己所在目录持续压测20分钟。
- 两个客户端压测结果分别是:3035 ops/s,3039 ops/s。
- 两个客户端cpu消耗非常接近。
- 两个active mds 目前都有请求负载,实现了多个客户端的负载均衡。
10.6 多活MDS-主备模式
10.6.1 查看mds状态
$ ceph fs status
test1_fs - 4 clients
========
+------+--------+------------------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------------------+---------------+-------+-------+
| 0 | active | ceph-xxx-osd02.ys | Reqs: 0 /s | 75.7k | 72.6k |
| 1 | active | ceph-xxx-osd01.ys | Reqs: 0 /s | 67.8k | 64.0k |
+------+--------+------------------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs_metadata | metadata | 311M | 88.7T |
| cephfs_data | data | 3322M | 88.7T |
+-----------------+----------+-------+-------+
+------------------------+
| Standby MDS |
+------------------------+
| ceph-xxx-osd03.ys |
+------------------------+
MDS version: didi_dss version 12.2.8 (ae699615bac534ea496ee965ac6192cb7e0e07c0) luminous (stable)10.6.2 停掉mds2
$ systemctl stop ceph-mds.target10.6.3 查看mds状态信息
$ ceph fs status
test1_fs - 2 clients
========
+------+--------+------------------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------------------+---------------+-------+-------+
| 0 | replay | ceph-xxx-osd03.ys | | 0 | 0 |
| 1 | active | ceph-xxx-osd01.ys | Reqs: 0 /s | 67.8k | 64.0k |
+------+--------+------------------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs_metadata | metadata | 311M | 88.7T |
| cephfs_data | data | 3322M | 88.7T |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
+-------------+
MDS version: didi_dss version 12.2.8 (ae699615bac534ea496ee965ac6192cb7e0e07c0) luminous (stable)10.6.4 压测观察
#进行压测rank0, 发现请求能正常落在mds3上
$ ceph fs status
test1_fs - 4 clients
========
+------+--------+------------------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------------------+---------------+-------+-------+
| 0 | active | ceph-xxx-osd03.ys | Reqs: 2372 /s | 72.7k | 15.0k |
| 1 | active | ceph-xxx-osd01.ys | Reqs: 0 /s | 67.8k | 64.0k |
+------+--------+------------------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs_metadata | metadata | 367M | 88.7T |
| cephfs_data | data | 2364M | 88.7T |
+-----------------+----------+-------+-------+
+------------------------+
| Standby MDS |
+------------------------+
| ceph-xxx-osd02.ys |
+------------------------+
MDS version: didi_dss version 12.2.8 (ae699615bac534ea496ee965ac6192cb7e0e07c0) luminous (stable)10.6.5 总结
- 多active mds,如果主mds挂掉, 备mds会接替主的位置。
- 新的主会继承静态分区关系。
11. 多活负载均衡-总结
11.1 测试报告
| 工具 | 集群模式 | 客户端数量(压测端) | 性能 |
|---|---|---|---|
| filebench | 1MDS | 2个客户端 | 5624 ops/s |
| filebench | 2MDS | 2个客户端 | 客户端1:3035 ops/s 客户端2:3039 ops/s |
11.2 结论
- 单活mds
- 性能是 5624 ops/s左右。
- 通过主备模式可以实现高可用。
- 多活mds 默认
- 用户的请求都只会在 rank 0 上的mds。
- 多活mds 动态负载均衡 (目前12.2版本不推荐使用)
- 测试效果多个mds负载不均衡。
- 可以通过lua灵活调节负载均衡策略。
- 资源来回迁移等各种问题,目前感觉坑还是很大。
- 多活mds 静态分区 (推荐使用,外界社区也有用到生产环境)
- 可以实现不同目录绑定到不同的mds上。
- 从而实现多租户mds资源隔离。
- 随着mds增加可以线性增加集群性能。
- 两个客户端压测结果分别是:3035 ops/s,3039 ops/s。
- 多活mds 主备模式
- 其中一个active mds挂掉 stanbdy会立马接替。
- 接替过来的新主active mds 也会继承静态分区的关系。
12. MDS状态说明
12.1 MDS主从切换流程图
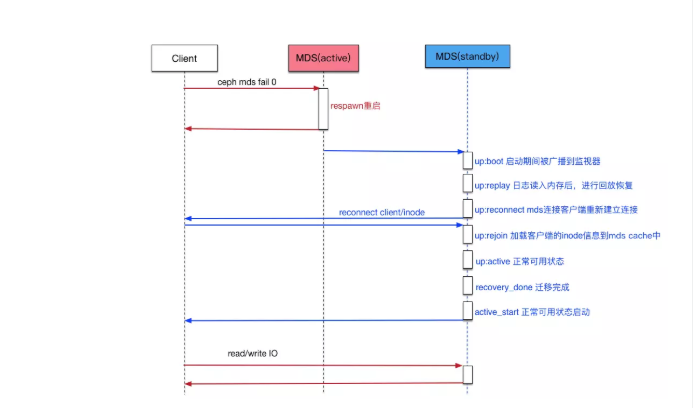
说明:
- 用户手动发起主从切换fail。
- active mds手动信号,发起respawn重启。
- standby mds收到信号,经过分布式算法推选为新主active mds。
- 新主active mds 从up:boot状态,变成up:replay状态。日志恢复阶段,他将日志内容读入内存后,在内存中进行回放操作。
- 新主active mds 从up:replay状态,变成up:reconnect状态。恢复的mds需要与之前的客户端重新建立连接,并且需要查询之前客户端发布的文件句柄,重新在mds的缓存中创建一致性功能和锁的状态。
- 新主active mds从up:reconnect状态,变成up:rejoin状态。把客户端的inode加载到mds cache。(耗时最多的地方)
- 新主active mds从up:rejoin状态,变成up:active状态。mds状态变成正常可用的状态。
- recovery_done 迁移完毕。
- active_start 正常可用状态启动,mdcache加载相应的信息。
12.2 MDS状态
| 状态 | 说明 |
|---|---|
| up:active | This is the normal operating state of the MDS. It indicates that the MDS and its rank in the file system is available.
这个状态是正常运行的状态。 这个表明该mds在rank中是可用的状态。 |
| up:standby | The MDS is available to takeover for a failed rank (see also :ref:mds-standby). The monitor will automatically assign an MDS in this state to a failed rank once available.
这个状态是灾备状态,用来接替主挂掉的情况。 |
| up:standby_replay | The MDS is following the journal of another up:active MDS. Should the active MDS fail, having a standby MDS in replay mode is desirable as the MDS is replaying the live journal and will more quickly takeover. A downside to having standby replay MDSs is that they are not available to takeover for any other MDS that fails, only the MDS they follow.
灾备守护进程就会持续读取某个处于 up 状态的 rank 的元数据日志。这样它就有元数据的热缓存,在负责这个 rank 的守护进程失效时,可加速故障切换。 一个正常运行的 rank 只能有一个灾备重放守护进程( standby replay daemon ),如果两个守护进程都设置成了灾备重放状态,那么其中任意一个会取胜,另一个会变为普通的、非重放灾备状态。 一旦某个守护进程进入灾备重放状态,它就只能为它那个 rank 提供灾备。如果有另外一个 rank 失效了,即使没有灾备可用,这个灾备重放守护进程也不会去顶替那个失效的。 |
| up:boot | This state is broadcast to the Ceph monitors during startup. This state is never visible as the Monitor immediately assign the MDS to an available rank or commands the MDS to operate as a standby. The state is documented here for completeness.
此状态在启动期间被广播到CEPH监视器。这种状态是不可见的,因为监视器立即将MDS分配给可用的秩或命令MDS作为备用操作。这里记录了完整性的状态。 |
| up:creating | The MDS is creating a new rank (perhaps rank 0) by constructing some per-rank metadata (like the journal) and entering the MDS cluster. |
| up:starting | The MDS is restarting a stopped rank. It opens associated per-rank metadata and enters the MDS cluster. |
| up:stopping | When a rank is stopped, the monitors command an active MDS to enter the up:stopping state. In this state, the MDS accepts no new client connections, migrates all subtrees to other ranks in the file system, flush its metadata journal, and, if the last rank (0), evict all clients and shutdown (see also :ref:cephfs-administration). |
| up:replay | The MDS taking over a failed rank. This state represents that the MDS is recovering its journal and other metadata.
日志恢复阶段,他将日志内容读入内存后,在内存中进行回放操作。 |
| up:resolve | The MDS enters this state from up:replay if the Ceph file system has multiple ranks (including this one), i.e. it's not a single active MDS cluster. The MDS is resolving any uncommitted inter-MDS operations. All ranks in the file system must be in this state or later for progress to be made, i.e. no rank can be failed/damaged or up:replay.
用于解决跨多个mds出现权威元数据分歧的场景,对于服务端包括子树分布、Anchor表更新等功能,客户端包括rename、unlink等操作。 |
| up:reconnect | An MDS enters this state from up:replay or up:resolve. This state is to solicit reconnections from clients. Any client which had a session with this rank must reconnect during this time, configurable via mds_reconnect_timeout.
恢复的mds需要与之前的客户端重新建立连接,并且需要查询之前客户端发布的文件句柄,重新在mds的缓存中创建一致性功能和锁的状态。mds不会同步记录文件打开的信息,原因是需要避免在访问mds时产生多余的延迟,并且大多数文件是以只读方式打开。 |
| up:rejoin | The MDS enters this state from up:reconnect. In this state, the MDS is rejoining the MDS cluster cache. In particular, all inter-MDS locks on metadata are reestablished. If there are no known client requests to be replayed, the MDS directly becomes up:active from this state. 把客户端的inode加载到mds cache |
| up:clientreplay | The MDS may enter this state from up:rejoin. The MDS is replaying any client requests which were replied to but not yet durable (not journaled). Clients resend these requests during up:reconnect and the requests are replayed once again. The MDS enters up:active after completing replay. |
| down:failed | No MDS actually holds this state. Instead, it is applied to the rank in the file system |
| down:damaged | No MDS actually holds this state. Instead, it is applied to the rank in the file system |
| down:stopped | No MDS actually holds this state. Instead, it is applied to the rank in the file system |
12.3 State Diagram
This state diagram shows the possible state transitions for the MDS/rank. The legend is as follows:
Color
- 绿色: MDS是活跃的。
- 橙色: MDS处于过渡临时状态,试图变得活跃。
- 红色: MDS指示一个状态,该状态导致被标记为失败。
- 紫色: MDS和rank为停止。
- 红色: MDS指示一个状态,该状态导致被标记为损坏。
Shape
- 圈:MDS保持这种状态。
- 六边形:没有MDS保持这个状态。
Lines
- A double-lined shape indicates the rank is "in".

13. 深入研究
MDS 多活配置的更多相关文章
- mds/journal.cc: 2929: FAILED assert解决
前言 在处理一个其他双活MDS无法启动环境的时候,查看mds的日志看到了这个错误mds/journal.cc: 2929: FAILED assert(mds->sessionmap.get_v ...
- Ceph 文件系统 CephFS 的实战配置,等你来学习 -- <4>
Ceph 文件系统 CephFS 的介绍与配置 CephFs介绍 Ceph File System (CephFS) 是与 POSIX 标准兼容的文件系统, 能够提供对 Ceph 存储集群上的文件访问 ...
- Ceph 存储集群1-配置:硬盘和文件系统、配置 Ceph、网络选项、认证选项和监控器选项
所有 Ceph 部署都始于 Ceph 存储集群.基于 RADOS 的 Ceph 对象存储集群包括两类守护进程: 1.对象存储守护进程( OSD )把存储节点上的数据存储为对象: 2.Ceph 监视器( ...
- 多MDS变成单MDS的方法
前言 之前有个cepher的环境上是双活MDS的,需要变成MDS,目前最新版本是支持这个操作的 方法 设置最大mds 多活的mds的max_mds会超过1,这里需要先将max_mds设置为1 ceph ...
- Ceph 存储集群第一部分:配置和部署
内容来源于官方,经过个人实践操作整理,官方地址:http://docs.ceph.org.cn/rados/ 所有 Ceph 部署都始于 Ceph 存储集群. 基于 RADOS 的 Ceph 对象存储 ...
- PHP从零开始-笔记-面向对象编程的概念
面向对象变成的概念 需要一一种不同的方式来考虑如何构造应用程序.通过对象可以在对应用程序所处理的显示任务.过程和思想进行编码是,实施更贴切的建模.OOP方法并不是将应用程序考虑成一个将大量数据从一个函 ...
- 002.RHCS-配置Ceph存储集群
一 前期准备 [kiosk@foundation0 ~]$ ssh ceph@serverc #登录Ceph集群节点 [ceph@serverc ~]$ ceph health #确保集群状态正常 H ...
- 网络编程的演进——从Apache到Nginx
Apache 1.Apache HTTP服务器是 Robert McCool 在1995年写成,并在1999年开始在Apache软件基金会的 框架下进行开发. 由于Apache HTTP服务器是基金会 ...
- cephfs分布式系统
cephfs分布式系统 CephFS:分布式文件系统 l 什么是CephFS: 分 ...
随机推荐
- IDEA快捷键汇总
[常用] Ctrl+Shift + Enter,语句完成 "!",否定完成,输入表达式时按 "!"键 Ctrl+E,最近的文件 Ctrl+Shift+E,最近更 ...
- Typescript I: 遍历Array的方法:for, forEach, every等
Typescript的官方文档 Iterators and Geneators (https://www.typescriptlang.org/docs/handbook/iterators-and- ...
- ASP.NET Core 1.0: API的输入参数
Web API是需要接受参数的,譬如,通常用于创建数据的POST method需要接受输入数据,而用于GET method也需要接受一些可选参数,譬如:为了性能起见,控制返回数据的数量是至关重要的. ...
- 将 /u 转变为 utf-8 编码
将 /u 转变为 utf-8 编码 PHP实例: $result = {"errno":-1,"message":"\u8bbf\u95ee\u5fa ...
- 在SQL Server数据库中执行存储过程很快,在c#中调用很慢的问题
记录工作中遇到的问题,分享出来: 原博客地址:https://blog.csdn.net/weixin_40782680/article/details/85038281 今天遇到一个比较郁闷的问题, ...
- 【NHOI2018】字符串变换
[题目描述] 给你一个全部由大小写字母组成的字符串,你每次可以将一个小写字母变换成对应的大写字母,或把一个大写字母变换成对应的小写字母.请问:至少要进行多少次变换才可以使整个字符串全部由大写字母或全部 ...
- JAVA网络通信底层调用LINUX探究
前言:该博客花了我一个下午得心血,全部手打,路过给个赞,拒绝抄袭!!!!!!!!!!!!!!!!!!!!!!!!! 简单的SOCKET通信程序 先从一段简单的JAVA程序性开始写起,这里我们才用半双工 ...
- day20 异常处理
异常处理: 一.语法错误 二.逻辑错误 为什么要进行异常处理? python解释器执行程序时,检测到一个错误,出发异常,异常没有被处理的话,程序就在当前异常处终止,后面的代码不会运行 l = ['lo ...
- day 17 re模块 正则表达式
import re 引用re模块 查找 finall:匹配所有,每一项都是列表中的一个元素 search:只匹配从左到右的第一个,得到的不是直接的结果而是一个变量,通过group方法获取结果,没 ...
- C#取视频某一帧图片
首先下载 ffmpeg http://ffmpeg.org/ 注意一定要从官网下载,其他地方可以会有问题 解压后在 bin 目录下找到 ffmpeg.exe 用到的使命是 -i 视频地址 -ss 第几 ...