python爬虫--爬虫介绍
一 爬虫
1、什么是互联网?
互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样
2、互联网建立的目的?
互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。
3、什么是上网?爬虫要做的是什么?
我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。
只不过,用户获取网络数据的方式是:
1.浏览器提交请求->下载网页代码->解析/渲染成页面。
而爬虫程序要做的就是:
2.模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中
1与2的区别在于: 我们的爬虫程序只提取网页代码中对我们有用的数据
4、爬虫
1.爬虫的定义:
向网站发起请求,获取资源后分析并提取有用数据的程序
2.爬虫的价值
互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
爬虫的分类
1.通用爬虫
通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 简单来讲就是尽可能的;把互联网上的所有的网页下载下来,放到本地服务器里形成备分,在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
2.聚焦爬虫
聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
2.1 robots协议
如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。但是我们在学习爬虫阶段编写的爬虫程序可以暂时先忽略robots协议。
Allow:允许的
Disallow:不允许的
User-agent: Baiduspider
Allow: /article
Allow: /oshtml
Allow: /ershou
Allow: /$
Disallow: /product/
Disallow: /
User-Agent: Googlebot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Allow: /ershou
Allow: /$
Disallow: /
User-agent: Bingbot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Allow: /ershou
Allow: /$
Disallow: /
User-Agent: 360Spider
Allow: /article
Allow: /oshtml
Allow: /ershou
Disallow: /
User-Agent: Yisouspider
Allow: /article
Allow: /oshtml
Allow: /ershou
Disallow: /
User-Agent: Sogouspider
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /ershou
Disallow: /
User-Agent: Yahoo! Slurp
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Allow: /ershou
Allow: /$
Disallow: /
User-Agent: *
Disallow: /
2.2 反爬虫
门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。
2.3 反反爬虫
爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。
3.增量式爬虫
通过爬虫程序监测某网站数据更新的情况,以便可以爬取到该网站更新出的新数据。
二 爬虫的基本流程
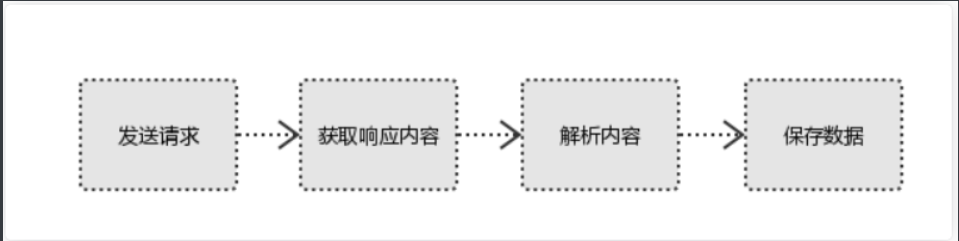
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以b的方式写入文件
4、保存数据
数据库
文件
三 请求与响应
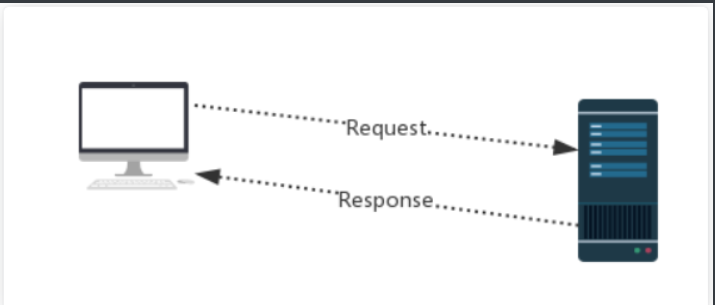
#http协议:
http://www.cnblogs.com/linhaifeng/articles/8243379.html
#Request:
用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
#Response:
服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
#ps:
浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
四 requests
#1、请求方式:
常用的请求方式:GET,POST
其他请求方式:HEAD,PUT,DELETE,OPTHONS
ps:用浏览器演示get与post的区别,(用登录演示post)
post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
post请求的参数放在请求体内:
可用浏览器查看,存放于form data内
get请求的参数直接放在url后
#2、请求url
url全称统一资源定位符,如一个网页文档,一张图片
一个视频等都可以用url唯一来确定
url编码
https://www.baidu.com/s?wd=图片
图片会被编码(看示例代码)
网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
#3、请求头
User-agent:请求头中如果没有user-agent客户端配置,
服务端可能将你当做一个非法用户
host
cookies:cookie用来保存登录信息
一般做爬虫都会加上请求头
#4、请求体
如果是get方式,请求体没有内容
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五 response
#1、响应状态
200:代表成功
301:代表跳转
404:文件不存在
403:权限
502:服务器错误
#2、Respone header
set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来
#3、preview就是网页源代码
最主要的部分,包含了请求资源的内容
如网页html,图片
二进制数据等
六 案例
1.爬取搜狗首页的源码数据
import requests #导入requests模块
url = "https://www.sogou.com/" #请求路径url
response = requests.get(url=url) #发送请求
sougou_text = response.text #获取响应数据 返回的是 unicode 型的文本数据
with open ('sougou.html','w',encoding='utf-8') as f: #持久化存储
f.write(sougou_text)
2.基于搜狗编写简单的网页采集
import requests
search = input('输入要搜索的内容:') #会自动生成一个input框
url="https://www.sogou.com/web" #请求路径
params={
'query':search #存储的就是动态的请求参数
#一定需要将params作用到请求中
#params参数表示的是对请求url参数的封装
}
# headers参数是用来实现UA伪装
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.get(url=url,params=params,headers=headers) #发起请求
response.encoding='utf-8' ##手动修改响应数据的编码
respones_text = response.text #获取响应对象
filename = search+'.html' #注意这个html 是 .html,不加这个点只会得到html字符型的数据
with open(filename,'w',encoding='utf-8') as f:#持久化存储
f.write(respones_text)
print(search+'获取成功')
3.爬取豆瓣电影的电影详情数据
import requests
start = input('请输入开始数据')
limit = input('请输入数据个数')
url="https://movie.douban.com/j/chart/top_list"
parmas={
'type': '5',
'interval_id' :'100:90',
'action': '',
'start': start,
'limit': limit,
}
'''
data={
'on': 'true',
'page': '1',
'pageSize':'15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn':'',
}
'''
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
response = requests.get(url=url,params=params,headers=headers) #post请求的格式为:requests.post(url=url,headers=headers,data=data)
movie_list = response.json() #把响应的格式进行转换
f = open('dbmovie.txt','w',encoding='utf-8')
for dict in movie_list: #循环,字典格式数据
title = dict['title']
score = dict['score']
f.write(title+':'+ score+'\n')
print(title,'获取成功')
f.close()
4.获取斗图网的一张图片
方式一:
斗图网:http://www.doutula.com/
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
url = 'http://ww4.sinaimg.cn/large/6af89bc8gw1f8op8nin2ug206t05k7s0.gif' # 图片的地址链接
image = requests.get(url=url,headers=headers).content # content,因为返回图片的数据类型是bytes类型,所以用content,类似于图片,音频,视频类的数据用content解码
with open('./img.jpg','wb') as f:
f.write(image)
方式二:
from urllib import request # 导入urllib
url = 'http://ww4.sinaimg.cn/large/6af89bc8gw1f8op8nin2ug206t05k7s0.gif'
request.urlretrieve(url,'./image2.jpg') # urlretrieve需要的参数,url和存储
# urllib把发送请求和持久化存储封装,urllib是一个请求模块,比较老
# 不可以使用UA伪装
python爬虫--爬虫介绍的更多相关文章
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍 Requests请求 Requests请求就是我们在爬虫文件写的Requests() ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- 网络爬虫简单介绍(python)
一.简介 爬虫就是利用代码大量的将网页前端代码下载下来使用的一种程序,一般来说常见的目的为下: 1.商业分析使用:很多大数据公司都会从利用爬虫来进行数据分析与处理,比如说要了解广州当地二手房的均价走势 ...
- python爬虫:爬虫的简单介绍及requests模块的简单使用
python爬虫:爬虫的简单介绍及requests模块的简单使用 一点点的建议: (学习爬虫前建议先去了解一下前端的知识,不要求很熟悉,差不多入门即可学习爬虫,如果有不了解的,我也会补充个一些小知识. ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
随机推荐
- 解构ffmpeg(一)
ffmpeg应用程序项目将其核心库libav*的使用或编程抽象成FilterGraph,InputFile,OutputFile,InputStream,OutputStream,InputFilte ...
- Swoft 源码剖析 - Swoole和Swoft的那些事 (Http/Rpc服务篇)
前言 Swoft在PHPer圈中是一个门槛较高的Web框架,不仅仅由于框架本身带来了很多新概念和前沿的设计,还在于Swoft是一个基于Swoole的框架.Swoole在PHPer圈内学习成本最高的工具 ...
- call() 、 apply() 、bind()方法的作用和区别!
从一开始,我是在书上看到关于bind().call() 和 apply(), 不过长久以来,在工作中与网上接触到了很多关于这三个方法的使用场景,对这三个方法也算是比较熟悉了.所以把他们的作用和区别简单 ...
- 从零开始手写 spring ioc 框架,深入学习 spring 源码
IoC Ioc 是一款 spring ioc 核心功能简化实现版本,便于学习和理解原理. 创作目的 使用 spring 很长时间,对于 spring 使用非常频繁,实际上对于源码一直没有静下心来学习过 ...
- 2019 牛客网 第七场 H pair
题目链接:https://ac.nowcoder.com/acm/contest/887/H 题意: 给定A,B,C问在[1,A]和[1,B]中有多少对x,y满足x&y>C或者x^y ...
- day20191001国庆默写
day20191001国庆默写恢复 重在理解,而不是死记硬背.认真专心看6遍,做6遍. 学会码字,每天码字二小时.持之以恒. 任重道远,出发,走多少算多少.100分的试卷,会做20分也比一个努力也没有 ...
- 原生线程池这么强大,Tomcat 为何还需扩展线程池?
前言 Tomcat/Jetty 是目前比较流行的 Web 容器,两者接受请求之后都会转交给线程池处理,这样可以有效提高处理的能力与并发度.JDK 提高完整线程池实现,但是 Tomcat/Jetty 都 ...
- C语言博客作业11
一.本周教学内容&目标 第5章 函数 要求学生掌握各种类型函数的定义.调用和申明,熟悉变量的作用域.生存周期和存储类型. 二.本周作业头 这个作业属于那个课程 C语言程序设计II 这个作业要求 ...
- python中的局部变量和全局变量
- 链式栈-C语言实现
相对于顺序栈的空间有限,链式栈的操作则更加灵活 #include<stdio.h> #include<malloc.h> typedef int SElemType; //元素 ...