Spark1——介绍
1、Spark是什么
Spark是一个用来实现快速而通用的集群计算的平台。
2、Spark是一个大一统的软件栈
Spark项目包含多个紧密集成的组件。首先Spark的核心是一个对由很多计算任务组成的、运行在多个工作机器或者是一个计算集群上的应用进行调度、分发以及监控的计算引擎。
Spark的个组件如下图所示:
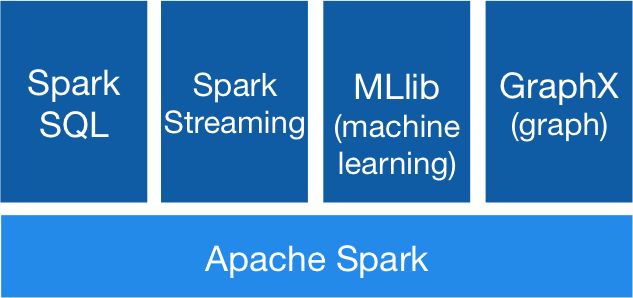
- Apache Spark 也就是Spark的核心部分,也称为Spark Core,这个部分实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互模块,还包含了对弹性分布式数据集(RDD)的API定义。
- Spark SQL是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL或者HQL来查询数据。
- Spark Streaming 是Spark提供的对实时数据进行流式计算的组件。比如生产环境中的网页服务器日志,或是网络服务中用户提交的状态更新组成的消息队列,都是消息流
- MLlib这是一个包含了常见机器学习功能的程序库,包括分类、回归、聚类、协同过滤等
- GraphX是用来操作图的程序库,可以进行并行的图计算。
3、Spark的核心概念
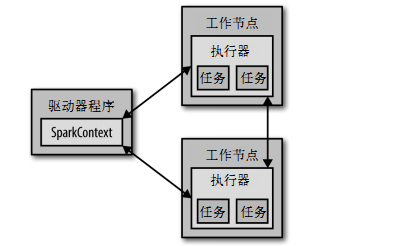
从上层来看,每个Spark应用都由一个驱动器程序来发起集群上的并行操作。驱动器程序包含应用的main函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作。
驱动器程序通过一个SparkContext对象来访问Spark。这个对象代表对计算集群的一个连接,当Spark shell启动时已自动创建了一个SparkContext对象。
- val textFile = sc.textFile("hdfs://...")
- val counts = textFile.flatMap(line => line.split(" "))
- .map(word => (word, ))
- .reduceByKey(_ + _)
- counts.saveAsTextFile("hdfs://...")
这里的sc变量,就是自动创建的SparkContext对象。通过它就可以来创建RDD,调用sc.textFile()来创建一个代表文件各行文本的RDD。
通过RDD我们就可以在这些行上进行各种操作,通常驱动器程序要管理多个执行器节点。比如,如果我们在集群上运行输出操作,那么不同的节点就会统计文件不同部分的行数。
4、初始化SparlContext
一旦完成了应用与Spark的连接,接下来就需要在程序中导入Spark包并创建SparkContext.我们可以通过先创建一个SparkConf对象来配置应用,然后基于这个SparkConf来创建一个Sparktext对象。
- val conf = new SparkConf().setAppName("wordcount").setMaster("local")
- val sc = new SparkContext(conf)
这里创建了SparkContext的最基础的方法,只需要传递两个参数:
- 应用名:这里使用的是"wordcount ",当连接到一个集群的时候,这个值可以帮助我们在集群管理器的用户界面中找到你的应用,这是这个程序运行后的集群管理器的截图

- 集群URL:告诉Spark如何连接到集群上,这里使用的是local,这个特殊的值可以让Spark运行在单机单线程上而无需连接到集群上
Spark1——介绍的更多相关文章
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- spark1.4.1 启动过程
今天稍微没那么忙了,趁着这个时间,准备把spark的启动过程总结一下(),分享给大家.现在使用的spark1.4.1版本 当然前提是你已经把spark环境搭建好了. 1.我们启动spark的时候一般会 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- spark1.2.0安装
standalone 安装SCALA 下载.解压.加入环境变量 安装spark1.2.0 下载.解压.加入环境变量 tar zxvf spark--bin-.tgz export SPARK_HOME ...
- DIP开放计算平台介绍
随着平台业务的发展,依赖于Portal(Web)构建的服务架构已逐渐不能满足现有的一些复杂需求(如:使用Hive SQL无法完成计算逻辑),而且对于一些具备编程能力的程序员或数据分析师而言,能够自主控 ...
- spark1.3.1使用基础教程
spark可以通过交互式命令行及编程两种方式来进行调用: 前者支持scala与python 后者支持scala.python与java 本文参考https://spark.apache.org/doc ...
- 安装spark1.3.1单机环境
本文介绍安装spark单机环境的方法,可用于测试及开发.主要分成以下4部分: (1)环境准备 (2)安装scala (3)安装spark (4)验证安装情况 1.环境准备 (1)配套软件版本要求:Sp ...
- Spark1.0.0 学习路径
2014-05-30 Spark1.0.0 Relaease 经过11次RC后最终公布.尽管还有不少bug,还是非常令人振奋. 作为一个骨灰级的老IT,经过非常成一段时间的消沉,再次被点燃 ...
- Spark1.3.0安装
之前在用Hadoop写ML算法的时候就隐约感觉Hadoop实在是不适合ML这些比较复杂的算法.记得当时写完kmeans后,发现每个job完成后都需要将结果放在HDFS中,然后下次迭代的时候再从文件中读 ...
随机推荐
- django基础知识之自连接:
自连接 对于地区信息,属于一对多关系,使用一张表,存储所有的信息 类似的表结构还应用于分类信息,可以实现无限级分类 新建模型AreaInfo,生成迁移 class AreaInfo(models.Mo ...
- spring的context:exclude-filter 与 context:include-filter
1 在主容器中(applicationContext.xml),将Controller的注解打消掉 <context:component-scan base-package="com& ...
- python进阶--字典排序
zip()函数 sorted() 要求对字典中,按值的大小排序 解决方案: 利用zip函数 zip函数介绍: zip函数可以将可迭代对象打包成一个个元组,在python3中返回一个对象,在python ...
- Mac上Ultra Edit的激活
2016-11-20 增加16.10.0.22破解 去官网下载原载,先运行一次,再在终端里执行下面代码就可以破解完成!printf '\x31\xC0\xFF\xC0\xC3\x90' | dd se ...
- 【题解】埃及分数-C++
Description 在古埃及,人们使用单位分数的和(形如1/a的, a是自然数)表示一切有理数. 如:2/3=1/2+1/6,但不允许2/3=1/3+1/3,因为加数中有相同的. 对于一个分数a/ ...
- Java调用方法参数究竟是传值还是传址?
之前阅读<Head First Java>的时候,记得里面有提到过,Java在调用方法,传递参数的时候,采用的是pass-by-copy的方法,传递一份内容的拷贝,即传值.举一个最简单的例 ...
- map全局缓存demo
import java.util.Map; import java.util.concurrent.ConcurrentHashMap; import org.apache.log4j.Logger; ...
- python课堂整理21---初识装饰器
一.装饰器: 本质就是函数,功能:为其他函数添加附加功能 原则: 1.不能修改被装饰函数的源代码 2.不能修改被修饰函数的调用方式 一个简单的装饰器 import time def timmer(fu ...
- C++ 八数码问题宽搜
C++ 八数码问题宽搜 题目描述 样例输入 (none) 样例输出 H--F--A AC代码 #include <iostream> #include <stdio.h> #i ...
- .NET开发框架(八)-服务器集群之网络负载平衡演示(视频)
(有声视频-服务器集群之负载平衡-NLB演示) 观看NLB视频的童鞋,都会继续观看IIS的负载平衡教程,点击>> 本文以[图文+视频],讲解Windows服务器集群的网络负载平衡NLB的作 ...